(开集检测系列)Localized Vision-Language Matching for Open-vocabulary Object Detection
使用单流和双流方式学习丰富的object语义,然后迁移到只需要单流的开集检测任务上
开集检测网络可以理解为: 类无关的视觉proposal提取+语义丰富的image embedding-text embedding空间的投射+多模态预训练模型分类器的生成;主要是学习第一和第二部分,第三部分用已有的CLIP等模型
1、动机
- 1、开集检测需要引入image-caption数据
- 2、开放检测capture信息的粒度和image-region特征的粒度需要一致,需要region-text细粒度的对齐
2、方法
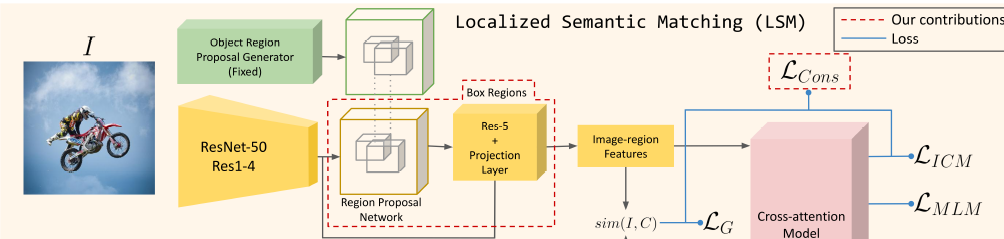
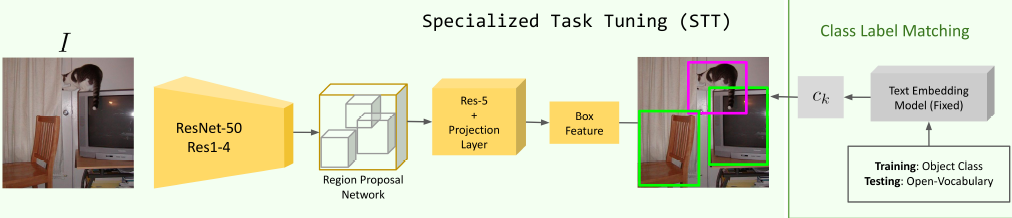
分2阶段,Localized Semantic Matching(LSM)和 Specialized Task Tuning(STT),LSM通过image-region和caption中的word匹配来学到object的语义,STT使用object annotations针对目标检测任务学习视觉特征。 可以理解为LSM通过image-region和word细粒度的对齐 学习语义的视觉特征提取 和RPN Proposal提取模型 及 语义丰富的image embedding-text embedding空间的投射; STT针对目标检测任务就有box的数据对视觉特征提取部分网络层和RPN网络的微调

数据集
- 1、bounding box annotations:COCO Objects 2017
- 2、image-caption pairs:COCO Captions
2.1 LSM
主要步骤:
- 1、使用COCO base数据训练generic object proposal OLN网络,用于LSM训练数据提取伪bbox,推理的时候用阈值0.7过滤
- 2、检测模型:FastRNN(backbone:ResNet50)+ 文本embeding使用BERT base-uncased model+muti-model(6layer+8head 从头开始训)
2.2 STT
-
1、Faster RCNN+BERT embedding module; Faster RCNN其中和投影层从LSM迁移,backbone layer1-2和投影层固定,
-
2.3 loss
LSM:
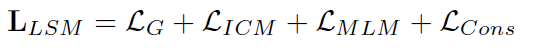
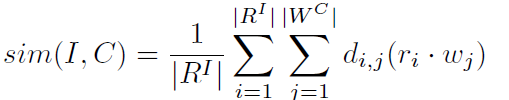
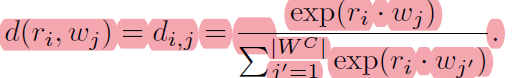
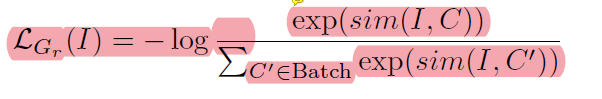
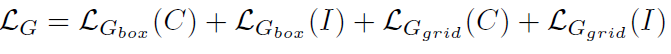
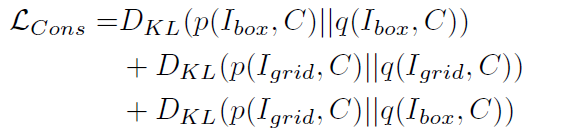
STT:
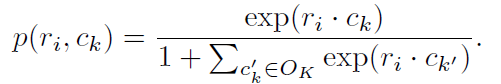
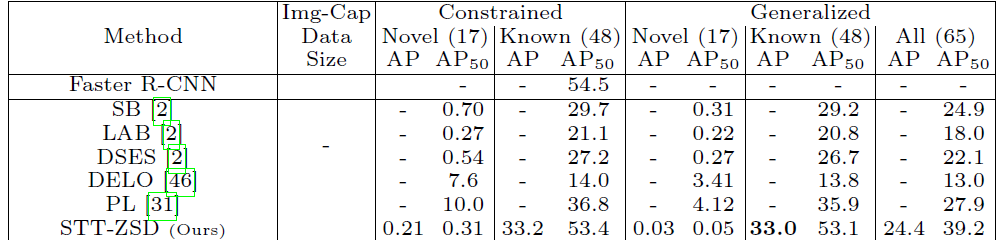
2、实验


 浙公网安备 33010602011771号
浙公网安备 33010602011771号