深度对比学习和度量学习中的损失函数
0、对比学习和度量学习
相同点:
- 1.度量学习和对比学习的思想是一样的,都是去拉近相似的样本,推开不相似的样本。
不同点: - 1.对比学习是无监督或者自监督学习方法,而度量学习一般为有监督学习方法
- 2.对比学习为单正例多负例的形式,因为是无监督,数据是充足的,也就可以找到无穷的负例,但如何构造有效正例才是重点;度量学习多为二元组或三元组的形式,如常见的 Triplet 形式(anchor,positive,negative),Hard Negative 的挖掘对最终效果有较大的影响
1、对比loss/Contrastive Loss
1.1、经典对比loss
经典的Contrastive Loss来自于LeCun的文章:Dimensionality Reduction by Learning an Invariant Mapping
基本思想:对于positive pair,输出特征向量间距离要尽量小;对于negative pair,输出特征向量间距离要尽量大,但若 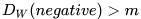 特征向量距离大于一定值,则不处理这种easy negative pair
特征向量距离大于一定值,则不处理这种easy negative pair
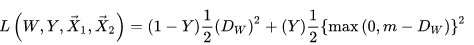
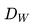 表示输入pair得到的特征向量间欧式距离;输入pair属于同一类时 Y=0 ,不同类时 Y=1 。
表示输入pair得到的特征向量间欧式距离;输入pair属于同一类时 Y=0 ,不同类时 Y=1 。
1.2、InfoNCE loss
1.2.1 NCE loss
NCE(noise contrastive estimation)核心思想是将多分类问题转化成二分类问题,一个类是数据类别 data sample,另一个类是噪声类别 noisy sample,通过学习数据样本和噪声样本之间的区别,将数据样本去和噪声样本做对比,也就是“噪声对比(noise contrastive)”,从而发现数据中的一些特性。但是,如果把整个数据集剩下的数据都当作负样本(即噪声样本),虽然解决了类别多的问题,计算复杂度还是没有降下来,解决办法就是做负样本采样来计算loss,这就是estimation的含义,也就是说它只是估计和近似。一般来说,负样本选取的越多,就越接近整个数据集,效果自然会更好
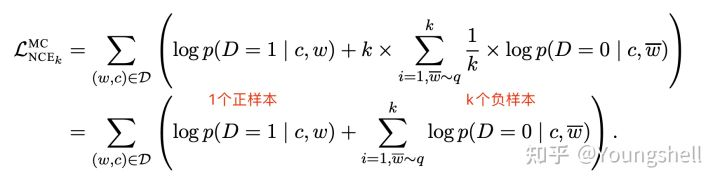
1.2.2 InfoNCE loss
Info NCE loss是NCE的一个简单变体,它认为如果你只把问题看作是一个二分类,只有数据样本和噪声样本的话,可能对模型学习不友好,因为很多噪声样本可能本就不是一个类,因此还是把它看成一个多分类问题比较合理
基本思想:一个编码好的query(一个特征),以及一系列编码好的样本k0,k1,k2...看作是字典里的key。假设字典里只有一个key是跟query是匹配的,那么q和k+就互为正样本对,其余的key为q的负样本。当query和唯一的正样本k+相似,并且和其他所有负样本key都不相似的时候,这个loss的值应该比较低。反之,如果query和k+不相似,或者q和其他负样本的key相似了,那么loss就应该大,从而惩罚模型,促使模型进行参数更新
具体实现:k为类别个数,log 里面的分母叠加项是包括了分子项的。分子是正例对的相似度,分母是正例对+所有负例对的相似度,最小化 infoNCE loss,就是去最大化分子的同时最小化分母,也就是最大化正例对的相似度,最小化负例对的相似度
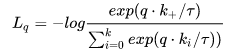
softmax+交叉熵实现:
softmax公式为: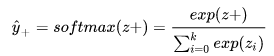
交叉熵为: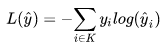
softmax+交叉熵为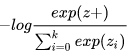
InfoNCE loss & softmax+交叉熵:qk是模型出来的logits,相当于上文softmax公式中的z,t是一个温度超参数,t 是个标量,假设我们忽略t,那么infoNCE loss其实就是cross entropy loss。唯一的区别是,1、在cross entropy loss里,k指代的是数据集里类别的数量,而在对比学习InfoNCE loss里,这个k指的是负样本的数量 2、同时1可以理解为entropy loss K 是分类类别数的大小,任务确定时是不变的,而infoNCE loss K 是 batch 的大小,是可变的,是第 i 个样本要和 batch 中的每个样本计算相似度,而 batch 里的每一个样本都会如此计算,因此上面公式只是样本 i 的 loss。 上式分母中的sum是在1个正样本和k个负样本上做的,从0到k,所以共k+1个样本,也就是字典里所有的key。恺明大佬在MoCo里提到,InfoNCE loss其实就是一个cross entropy loss,做的是一个k+1类的分类任务,目的就是想把q这个图片分到k+1这个类。
温度系数作用:InfoNCE loss公式中q * k相当于是logits,温度系数可以用来控制logits的分布形状;对于既定的logits分布的形状,当t值变大,则1/t就变小,qk/t则会使得原来logits分布里的数值都变小,且经过指数运算之后,就变得更小了,导致原来的logits分布变得更平滑。相反,如果t取得值小,1/t就变大,原来的logits分布里的数值就相应的变大,经过指数运算之后,就变得更大,使得这个分布变得更集中,更peak
如果温度系数设的越大,logits分布变得越平滑,那么对比损失会对所有的负样本一视同仁,导致模型学习没有轻重。如果温度系数设的过小,则模型会越关注特别困难的负样本,但其实那些负样本很可能是潜在的正样本,这样会导致模型很难收敛或者泛化能力差
总之,温度系数的作用就是它控制了模型对负样本的区分度
2、Triplet loss
2.1、经典Triplet loss
经典的Triplet Loss来自于FaceNet: A Unified Embedding for Face Recognition and Clustering [1],提出的目的是使网络学到更好的人脸embdding,即同一个人的不同输入通过网络输出的 embdding 之间距离尽量小,不同人得到的 embdding 之间距离尽量大。同样的思想也可以应用在行人重识别等个体 identify 或细粒度分类任务中
基本思想:区别于 Contrastive loss 通过一对样本构造 Pairwise Ranking Loss,Triplet loss 通过一个三元组 [公式] 来构造损失函数;选择一个样本 embdding 作为 anchor,找到该样本的同类 embdding 作为 positive,找到不同于该样本类别的 embdding作为negative,目标函数是使得<anchor, positive>之间距离小于<anchor, negative> ,或者更进一步要求距离差距大于margin,
具体实现:即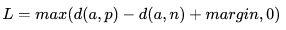
三元组的可能分布如下,Easy Triplets 显然不应加入训练,因为它的损失为0,加在loss里面会拉低loss的平均值。Hard Triplets 和 Semi-Hard Triplets 的选择则见仁见智,针对不同的任务需求,可以只选择Semi-Hard Triplets或者Hard Triplets,也可以两者混用
- Easy Triplets:d(a,n)>d(a,p)+margin 。负样本的距离已经大于正样本的距离,且满足间隔裕量margin。此时损失L为 0。
- Hard Triplets:d(a,n)<d(a,p) 。负样本的距离比正样本的距离还小,此时损失L大于margin。
- Semi-Hard Triplets:d(a,p)<d(a,n)<d(a,p)+margin 。负样本的距离虽比正样本大,但不满足间隔裕量margin。此时损失L大于0,但小于margin。
3、Center loss
3.1、经典Center loss
经典Center loss来自于ECCV 2016的一篇文章 A Discriminative Feature Learning Approach for Deep Face Recognition,目的也是使得网络学习的特征Discriminative,并且同样应用在人脸领域
下图为softmax分类,主要有2个问题:
- 1、因为每个类别占据一定角度,长条两端的特征向量距离有可能特别大,类内不紧凑
- 2、接近原点的特征向量,类间距离可能很小,分不开
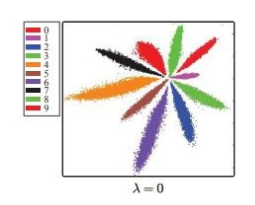
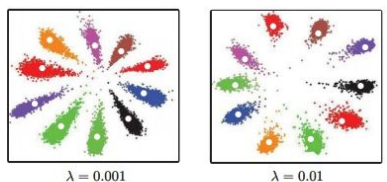
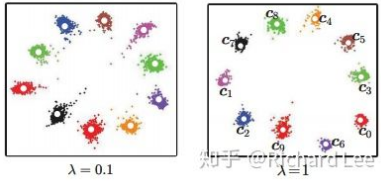
center loss效果,[公式] 控制中心化的程度
具体实现:- 1、计算 mini-batch 中每个样本与相应类别中心的距离之和,最终的损失函数由 softmax loss 和 center loss 共同组成,m表示 mini-batch 大小, n表示类别数

- 2、梯度计算及center更新, m表示 mini-batch 大小,n表示类别数,
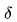 表示0-1条件函数
表示0-1条件函数
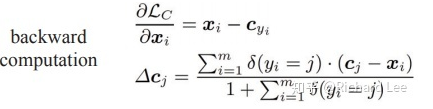
- 3、理论上,每次参数更新后,都要将整个训练集前向传播一遍得到所有特征向量,然后对每个类别求平均,从而计算新的 center [公式] ,不过计算量过大,实际上是操作不了的。文章提出的方法是,在每个mini-batch中计算类别中心,并通过一个学习率a来调整当前的类别中心
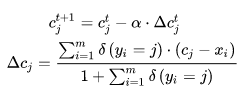
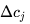 其实就是当前mini-batch, j类样本与中心 Cj的误差(逐元素相减)的平均值,作为此次迭代类别中心 [公式] 的修改量
其实就是当前mini-batch, j类样本与中心 Cj的误差(逐元素相减)的平均值,作为此次迭代类别中心 [公式] 的修改量
- 1、计算 mini-batch 中每个样本与相应类别中心的距离之和,最终的损失函数由 softmax loss 和 center loss 共同组成,m表示 mini-batch 大小, n表示类别数

 浙公网安备 33010602011771号
浙公网安备 33010602011771号