归一化
输入数据归一化和特征归一化,两者有一定相似性
输入归一化
- 输入归一化和标准化为什么输入数据需要归一化?
- 排除量纲影响
- 避免异常值引起的网络无法收敛或数值问题
- 激活函数用sigmoid时,避免神经元饱和
- 零中心可以提高训练效率,少走“之”字(输入全为正时,与第一层相连的权重只能全为正或负)
- 防止梯度爆炸或消失。因为梯度公式里面有一项就是上一层输入,将输入控制在一个合理的区间可以防止梯度爆炸或消失。
2.归一化类型
+1. Rescaling / 归一化 (min-max normalization)
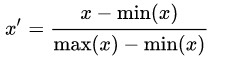
这里是归一化为[0,1],稍微改一下也可以是[-1,1]。
+2. Mean normalization / 平均归一化 归一化到[-0.5,0.5]
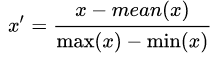
+3. Standardization / 标准化 (Z-score normalization)
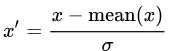
+4. Scaling to unit length / 单位化
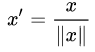
特征归一化
1、为什么feature map也需要归一化?
- Internal Covariate Shift。论文的基本思想,在网络的训练过程中,由于参数的更新,深层网络的输入分布不断变化,深层网络疲于适应这种变化导致网络收敛缓慢。
- 从sigmoid的角度,将输入拉回不饱和区,防止梯度消失。不过已经没人用sigmoid作为激活函数了。
- 和输出归一化一样,更有可能的原因是稳定的分布防止梯度爆炸或消失
2.实际使用中起到的作用(实验中确实能明显体会到) - 加速收敛。
- 对参数初始化和学习率设置更鲁棒。
3.归一化类型
Batch Normalization [N,H,W]:在batch的维度上归一化,每个channel分别进行。
Layer Normalization [C,H,W]:归一化每个batch上的所有特征。
Instance Normalization [H,W]:归一化每个batch中的单个特征。
Group Normalization [C//G,H,W]:取LN和IN的折中,将C分为G组,每组分别norm。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号