GPU, 单机单卡, 多机多卡
单机单卡
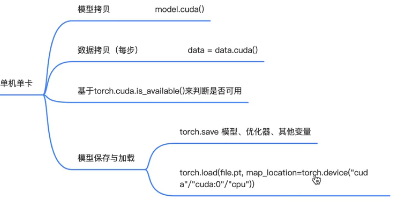
1.判断卡存在
torch.cuda.is_available()
2.数据拷贝到GPU
data.cuda()
3.模型拷贝到GPU
model.cuda()
4.加载的时候,需要map_location参数设置加载到哪个GPU
torch.load(path, map_location= torch.device("cuda:0")) #可以是cpu,cuda, cuda:idx
单机多卡
方法一:torch.nn.DataParallel(单进程效率慢)
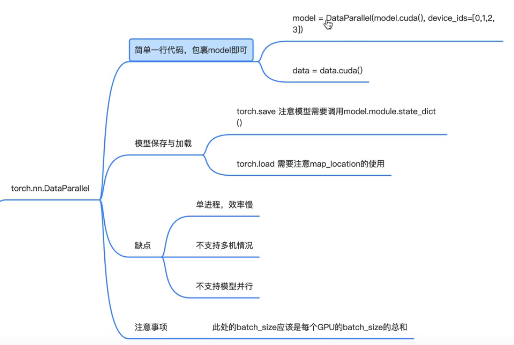
1.只需要加1行model=torch.nn.DataParallel(model.cuda(), device_ids=[0,1,2,3])
2.需要主要模型保存的时候需要是 torch.save(model.modules.state_dict()),单卡是torch.save(model.state_dict())
3.加载的时候,torch.load需要map_location参数设置加载到哪个GPU(同单GPU)
4.注意Batch_size为所有GPU的Batch_size总和
方法二:torch.nn.parallel.DistributedDataParallel(多进程多卡)
1、初始化进程组 torch.distributed.init_process_group("nccl",world_size=n_gpu,rank=args.local_rank) # 第一参数nccl为GPU通信方式, world_size为当前机器GPU个数,rank为当前进程在哪个PGU上
2、设置进程使用第几张卡 torch.cuda.set_device(args.local_rank)
3.对模型进行包裹 model=torch.nn.DistributedDataParallel(model.cuda(args.local_rank), device_ids=[args.local_rank]), 这里device_ids传入一张卡即可,因为是多进程多卡,一个进程一个卡
4、将数据分配到不同的GPU train_sampler = torch.util.data.distributed.DistributedSampler(train_dataset) # train_dataset为Dataset()
5.将train_sampler传入到DataLoader中,不需要传入shuffle=True,因为shuffle和sampler互斥 data_dataloader = DataLoader(..., sampler=train_sampler)
6.数据拷贝到GPU data = data.cuda(args.local_rank)
注意:
7.在每个epoch开始时候,需要调用train_sampler.set_epoch(epoch)使得数据充分打乱,要不然每个epoch返回数据是相同的
8.模型保存 torch.save在local_rank=0的位置保存,torch.save(model.modules.state_dict())
9.加载的时候,torch.load需要map_location参数设置加载到哪个GPU(同单GPU)
10.执行命令的时候需加入-m torch.distributed.launch参数,nproc_per_node执行进程个数/GPU个数,launch会像train.py传入args.local_rank,local_rank从0到n_gpus - 1个索引
python -m torch.distributed.launch --nproc_per_node=n_gpus train.py
11、launch会像train.py传入args.local_rank,local_rank从0到n_gpus - 1个索引,train.py需要接受local_rank的参数
12.注意Batch_size为每个GPU的Batch_size
多机多卡
1、代码编写和单机多卡的DDP一致
2、执行的时候需要在多个机器上执行命令(以2个节点为例,每个节点n_gpus 个GPU),--nnodes有几个机器, --node-rank当前机器是第几个
python -m torch.distributed.launch --nproc_per_node=n_gpus train.py --nnodes=2 --node-rank=0 --master_addr="主节点IP" --master_port="主节点端口" train.py
python -m torch.distributed.launch --nproc_per_node=n_gpus train.py --nnodes=2 --node-rank=1 --master_addr="主节点IP" --master_port="主节点端口" train.py

 浙公网安备 33010602011771号
浙公网安备 33010602011771号