Yolo4
1、余弦退火https://arxiv.org/pdf/1812.01187.pdf
Learning rate adjustment is crucial to the training. After the learning rate warmup described in Section 3.1, we typically steadily decrease the value from the initial learning rate. The widely used strategy is exponentially decaying the learning rate. He et al. [9] decreases rate at 0.1 for every 30 epochs, we call it “step decay”. Szegedy et al. [26] decreases rate at 0.94 for every two epochs.
In contrast to it, Loshchilov et al. [18] propose a cosine annealing strategy. An simplified version is decreasing the learning rate from the initial value to 0 by following the cosine function. Assume the total number of batches is T (the warmup stage is ignored), then at batch t, the learning rate ηt is computed as:
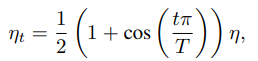
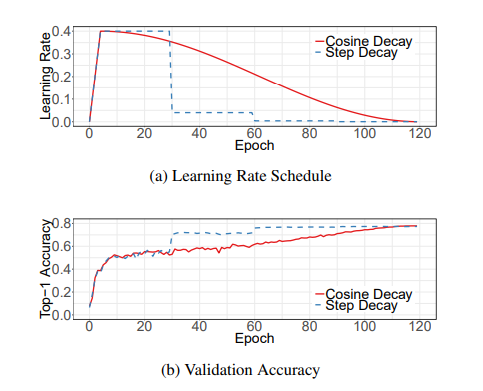
where η is the initial learning rate. We call this scheduling as “cosine” decay。The comparison between step decay and cosine decay are illustrated in Figure 3a. As can be seen, the cosine decay decreases the learning rate slowly at the beginning, and then becomes almost linear decreasing in the middle, and slows down again at the end. Compared to the step decay, the cosine decay starts to decay the learning since the beginning but remains large until step decay reduces the learning rate by 10x, which potentially improves the training progress.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号