XML解析之xpath的使用
使用dom4j查询标签较多的xml文件时,需要不断的嵌套for循环。
基于dom4j,使用xpath可以简化查询
在dom4j里面提供了两个方法,用来支持xpath
List<Node> selectNodes("xpath表达式"),用来获取多个节点Node selectSingleNode("xpath表达式"),用来获取一个节点
XML文件:

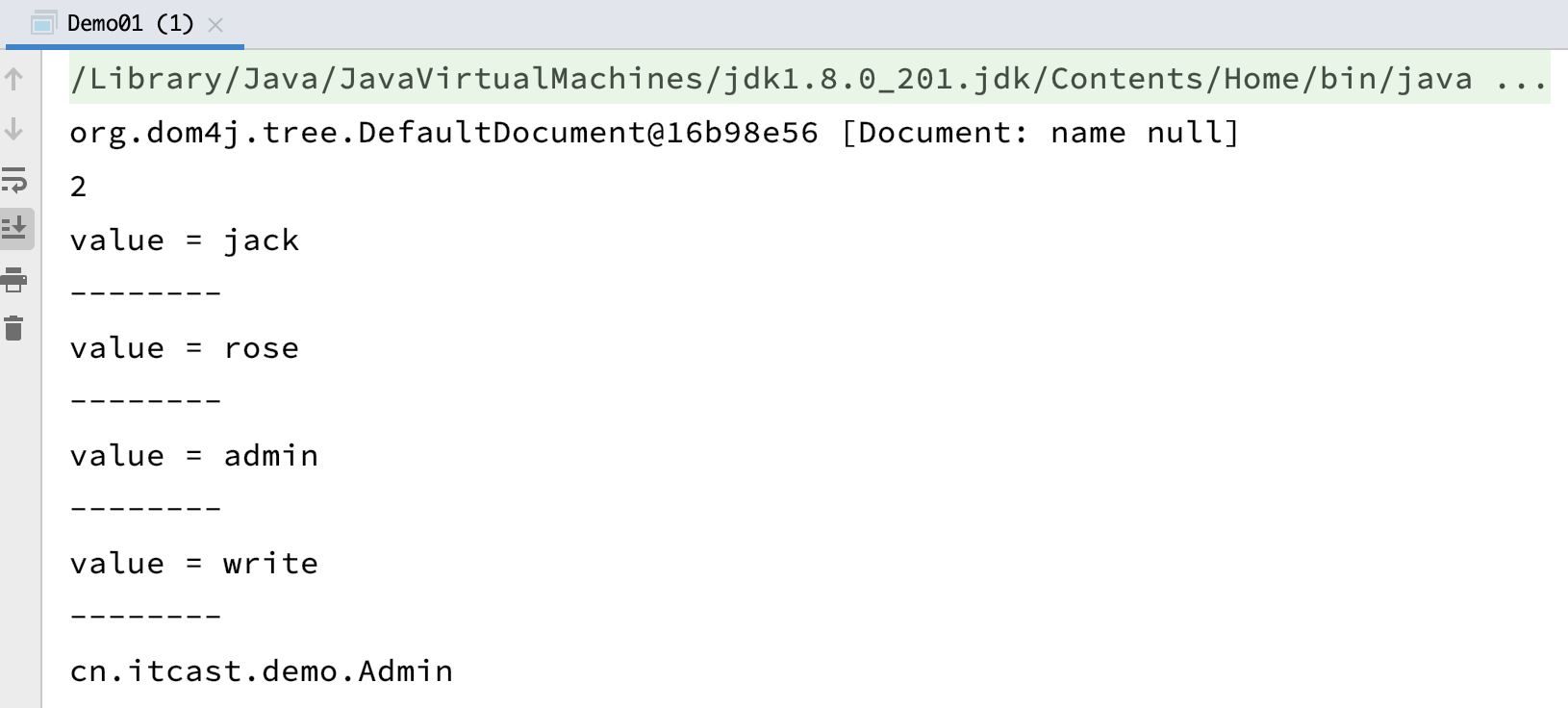
public class Demo01 { public static void main(String[] args) throws FileNotFoundException, DocumentException { SAXReader saxReader = new SAXReader(); Document document = saxReader.read(new FileInputStream("XML/src/beans.xml")); System.out.println(document); //org.dom4j.tree.DefaultDocument@16b98e56 [Document: name null] //获取bean标签集合 List<Node> bean = document.selectNodes("//bean"); System.out.println(bean.size()); //2 有两个bean标签元素 //查询所有property标签中Value属性的值 List<Element> props = document.selectNodes("//property"); for (Element prop : props) { String value = prop.attributeValue("value"); System.out.println("value = " + value); System.out.println("--------"); } //查询id=002的元素className的值 Element ele = (Element)document.selectSingleNode("//bean[@id='002']"); String className = ele.attributeValue("className"); System.out.println(className); //cn.itcast.demo.Admin /* 获取到xml文件中的类名,就可以使用反射来进行一些操作了。 */ } }
运行结果:
学习的博客多用于在笔记中,防止笔记过于臃肿,所以将样例及运行结果放在博客中,后以超链接的形式记录在笔记中,所以有些博文过于单薄。如果有小伙伴遇到问题欢迎评论,看到就会回复,学渣一枚,加油努力。
