基于深度学习的开源中文知识图谱抽取工具-DeepKE
目录
介绍
代码地址: https://github.com/zjunlp/DeepKE,开源知识图谱出色的工作,欢迎
star和fork下项目参考论文:
Document-level Relation Extraction as Semantic Segmentation
KnowPrompt: Knowledge-aware Prompt-tuning with Synergistic Optimization for Relation Extraction
LightNER: A Lightweight Generative Framework with Prompt-guided Attention for Low-resource NER
DeepKE 是一个支持低资源、长篇章的开源知识抽取工具,支持命名实体识别、关系抽取、属性抽取等任务。DeepKE底层为pytorch,兼容huggingface transformer库。
DeepKE目前支持3类抽取任务:实体识别、关系抽取和属性抽取,同时支持三种不同的场景设定,分别是
- 常规的全监督设定:标准的机器学习范式,通过喂入一定量的数据去训练一个模型,然后再测试效果。
- 低资源少样本设定:快速的让一个任务冷启动,通过喂入一些少量的样本,学得一个模型
- 篇章级长文档设定:在真实的场景下,比如说医疗、金融等领域,在进行信息抽取的文档长度是十分长的,而且文档中包含了诸多句子,句子与句子之间的信息聚合,即跨句识别。
DeepKE一直在动态维护与更新,未来肯定会支持更多任务和场景。
DeepKE结构
目录结构
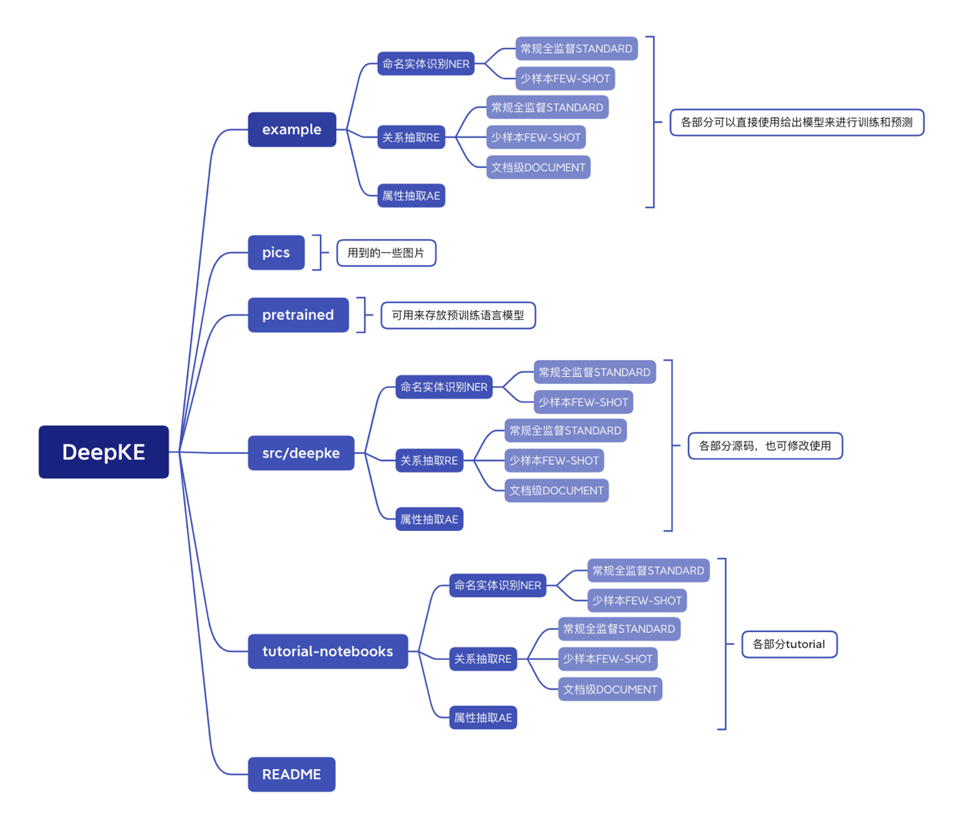
DeepKE的目录结构如图所示,主要分为三部分,最上面的example文件夹中包含了模型进行训练和预测的框架代码,pics文件夹主要是用到的一些图片,pretrained文件夹用来存放预训练语言模型,中间src/DeepKE文件夹中包含了所有任务的源代码,最后在tutorial-notebook中包含了每个任务的jupyter notebook,初学者可以通过学习notebook了解模型的技术细节,比如如何在实现的关系抽取、实体识别以及属性抽取。
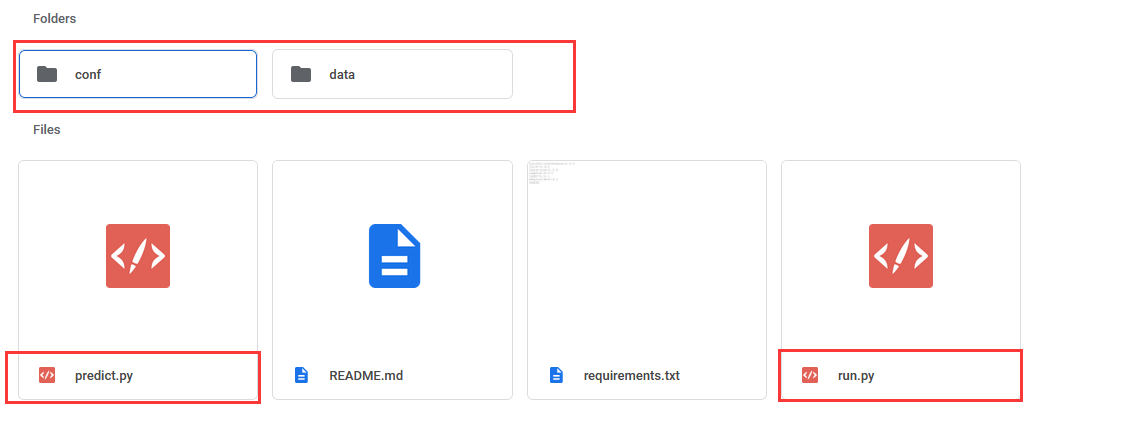
DeepKE采用统一目录结构,每一个子任务模块下的目录如上图所示,包含了conf文件夹存储参数配置文件、data文件夹存储训练数据、run.py 和predict.py进行模型训练和预测。
模型结构
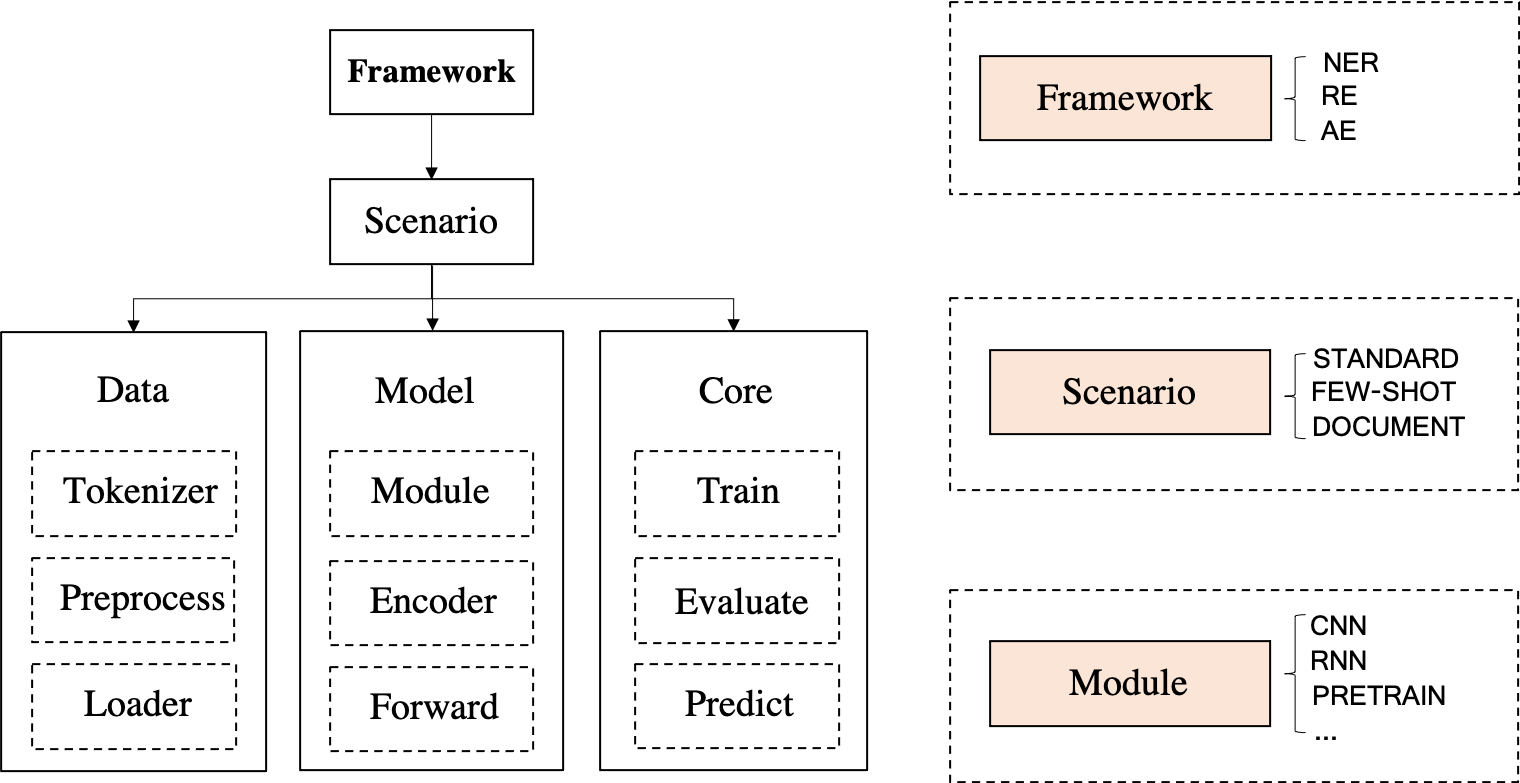
DeepKE为三个知识抽取功能(命名实体识别、关系抽取和属性抽取)设计了一个统一的框架- 可以在不同场景下实现不同功能。比如,可以在标准全监督、低资源少样本和文档级设定下进行关系抽取
- 每一个应用场景由三个部分组成:
Data部分包含Tokenizer、Preprocessor和Loader,Model部分包含Module、Encoder和Forwarder,Core部分包含Training、Evaluation和Prediction。
代码复现
环境配置
Step 0:华为云ModelArts新建与配置notebook,配置如下:

进入notebook并建立Terminal执行一下命令安装并使用DeepKE。
Step 1:下载代码 git clone https://github.com/zjunlp/DeepKE.git
Step 2:使用anaconda创建虚拟环境,进入虚拟环境(提供Dockerfile源码可自行创建镜像,位于docker文件夹中)
conda create -n DeepKE python=3.8
conda activate DeepKE
DeepKE可通过两种方法来安装:
-
基于pip安装,直接使用
pip install DeepKE -
基于源码安装
python setup.py install python setup.py develop
其他问题:
在conf文件夹下使用了一个统一的yaml格式的文件进行参数的配置,可以很方便的修改参数。对于数据来说,只需要在data文件夹下替换成相同格式的数据就可以直接使用
如何模型调参?
训练以及预测所用到的参数在
conf文件夹下,可修改使用如何使用不同数据?
数据存放在
data文件夹下,可替换成同格式的数据直接使用
关系抽取RE
关系抽取(Relation Extraction, RE)是从非结构化的文本中提取未知关系事实,是自然语言处理领域非常重要的一项任务。
文档级DOCUMENT
原理
目前大多数研究关系抽取方法主要将注意力集中于抽取单个实体对在某个句子内反映的关系,但在实际场景中,它们有许多关系事实是蕴含在文档中不同句子的实体对中的,且文档中的多个实体之间,往往存在复杂的相互关系。事实上,根据从维基百科采样的人工标注数据的统计表明,至少 40% 的实体关系事实只能从多个句子联合获取。因此,研究文档级关系抽取具有很高的应用价值。文档级关系抽取主要面临以下三个挑战:
-
相同关系会出现在多个句子。在文档级关系抽取中,单一关系可能出现在多个输入的句子中,因此模型需要依赖多个句子进行关系推断。
-
相同实体会具有多个指称。在复杂的文档中,同一个实体具有各种各样的指称,因此模型需要聚合不同的指称来学习实体表示。
-
不同三元组之间需要信息交互。文档包含多个实体关系三元组,不同的实体关系三元组之间存在逻辑关联,因此模型需要捕捉同一篇文档中三元组之间的信息交互。
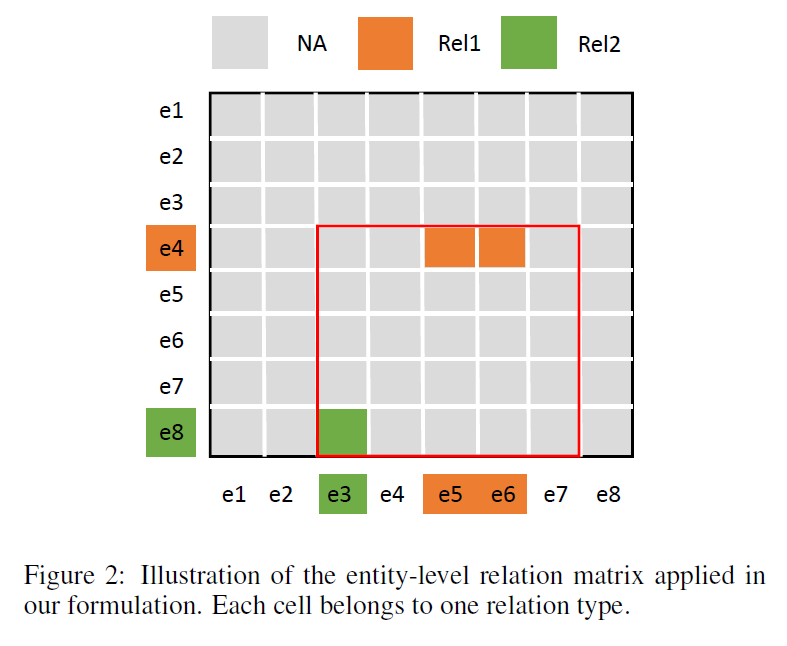
DocuNet模型反思了一下文档级别关系抽取这个问题,本质是再干什么样的事情,如这张图所示, 文档级关系抽取本质上是它是再对一个实体的一个实体与实体矩阵做一个矩阵填充,也就是判断每个实体与实体之间到底存不存在一个关系,需要对其进行一个分类,然后这里的这个填充实体矩阵那个事情,其实有点像计算机视觉里边的一个语义分割的过程,每个实体与实体之间的这个中间这个小方块其实就是一个像素点,然后很直觉的就能想到可以以用这种卷积的操作(上采样,下采样)来去建模实体实体之间三元组之间的这种复杂的这种相互的关联信息。 DocuNet模型首次将文档级关系抽取任务类比于计算机视觉中的语义分割任务,利用编码器模块捕获实体的上下文信息,并采用U-shaped分割模块在image-style特征图上捕获三元组之间的全局相互依赖性,通过预测实体级关系矩阵来捕获local和global信息以增强文档级关系抽取效果,模型的框架图:
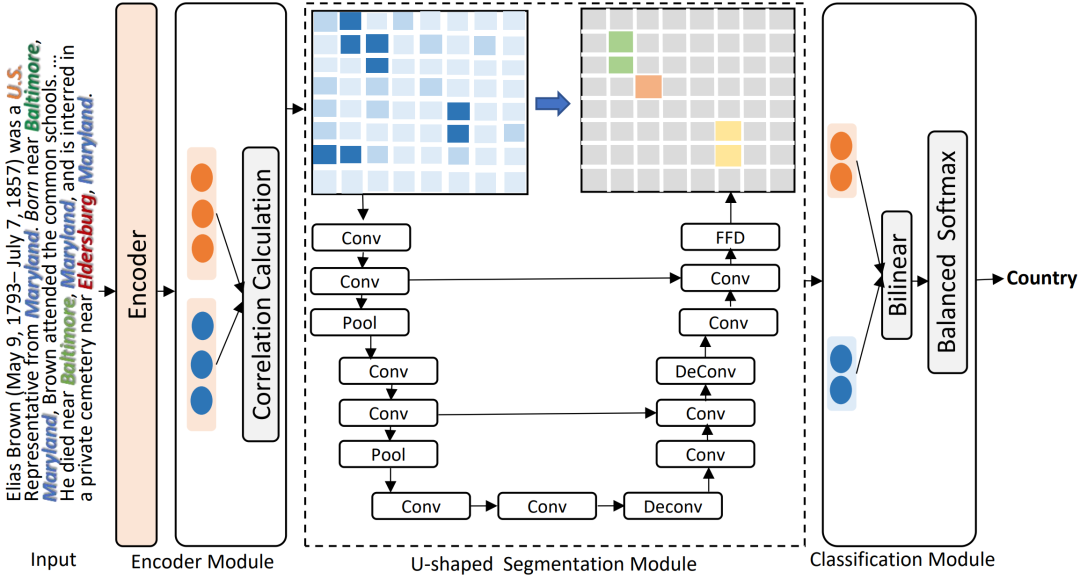
-
Encoder Module 将
triple抽取视为sequence-to-sequence的任务,以更好地对实体和关系之间的交叉依赖进行建模。将输入文本和输出三元组定义为源和目标序列,主要借助transormer、bert这种自身的注意力机制捕获实体对上下文信息的一个感知。源序列仅由输入句子的标记组成,例如“[CLS] The United States President Trump was raised in the borough of Queens ...[SEP]”。连接由特殊标记 ”< e >” 和 ”< /e >”分隔的每个实体/关系的三元组作为目标序列。\[\begin{gathered} H=\left[h_{1}, h_{2}, \ldots, h_{L}\right]=\operatorname{Encoder}\left(\left[x_{1}, x_{2}, \ldots, x_{L}\right]\right) \\ \mathbf{e}_{i}=\log \sum_{j=1}^{N_{e_{i}}} \exp \left(\mathbf{m}_{\mathbf{j}}\right) \\ \mathbf{F}\left(e_{s}, e_{o}\right)=W_{2} H a^{(s, o)} \\ a^{(s, o)}=\operatorname{softmax}\left(\sum_{i=1}^{K} A_{i}^{s} \cdot A_{i}^{o}\right) \\ \mathbf{F}\left(e_{s}, e_{o}\right)=\left[e_{s} \odot e_{o} ; \cos \left(e_{s}, e_{o}\right) ; e_{s} W_{1} e_{o}\right) \end{gathered} \]对于具体公式来说,
- 第一个公式表示采用
BERT等预训练模型作为编码器获取实体与关系的嵌入embedding,即每一个单词得向量表示。 - 第二个公式因为有些文件的长度超过
512,于是利用动态窗口对整个文件进行编码。对不同窗口的重叠标记的嵌入进行平均,以获得最终的表示,文中采用的方法为最大池的平滑版本:logsumexp pooling,以获得最后的实体嵌入\(e_i\)。这种池化操作好处是积累了实体在文件中所有出现位置的信号。 - 需要根据实体与实体之间的相关性来计算实体层面的关系矩阵,对于矩阵中的每个实体,两两之间的相关性由一维特征向量 \(F\left(e_{s}, e_{o}\right)\) 捕获,文章提出两种计算相关性的策略:
- 第三个公式和第四个公式:基于实体感知的注意力机制和仿生变换的策略来获得特相关性征向量,其中 \(a^{(s, o)}\)表示 实体感知注意力的注意力权重,
H是文档嵌入,k是transformer模型头部的数量 - 第五个公式: 基于相似性和背景的方法策略,主要指标为元素相似性、余弦相似性和双线性相似性。
- 第三个公式和第四个公式:基于实体感知的注意力机制和仿生变换的策略来获得特相关性征向量,其中 \(a^{(s, o)}\)表示 实体感知注意力的注意力权重,
- 第一个公式表示采用
-
U-shaped Segmentation Module三元组之间存在局部语义依赖,语义分割中的
CNN可以促进感受野中实体对之间的局部信息交换,类似于隐性推理。文档级 关系抽取还需要全局信息来推断三元组之间的关系,语义分割模块中的下采样和上采样可以扩大当前实体pair对嵌入 \(F\left(e_{s}, e_{o}\right)\) 的感受野,在一定程度上能够增强全局隐式推理:\[\mathbf{Y}=U\left(W_{3} \mathbf{F}\right) \]具体公式来看,输入为实体级关系矩阵 \(F \in R^{N^{*} N^{*} D}\) ,可以看作为
D-channel图像,将文档级关系预测公式化为像素级掩码,U代表计算机视觉中一个著名的语义分割模型U-Net,其中 \(N\) 是从所有数据集样本中统计出的最大实体数。 -
Classification Module给定实体
pair的特征表示\(e_s\)和\(e_o\)和实体级关系矩阵Y,使用前馈神经网络将它们映射到隐藏表示z,就是下面的第一个和第二个公式。然后,通过双线性函数获得实体pair之间关系预测的概率表示:\[\begin{gathered} z_{s}=\tanh \left(W_{s} \mathbf{e}_{\mathbf{s}}+Y_{s, o}\right), \\ z_{o}=\tanh \left(W_{o} \mathbf{e}_{\mathbf{o}}+Y_{s, o}\right), \\ \mathrm{P}\left(r \mid e_{s}, e_{o}\right)=\sigma\left(z_{s} W_{r} z_{o}+b_{r}\right), \end{gathered} \]由于观察到 关系抽取存在不平衡关系分布(即许多实体对具有 NA 的关系),引入了一种平衡的
softmax方法进行训练,具体来说,我们引入一个额外的类别0,希望目标类别的得分都大于s0,而非目标类别的得分都小于s0。形式上:\[L=\log \left(e^{s_{0}}+\sum_{i \in \Omega_{n e g}} e^{s_{i}}\right)+\log \left(e^{-s_{0}}+\sum_{j \in \Omega_{p o s}} e^{-s_{j}}\right) \]为简单起见,文中将阈值设为0,即最后一个公式:
\[L=\log \left(1+\sum_{i \in \Omega_{n e g}} e^{s_{i}}\right)+\log \left(1+\sum_{j \in \Omega_{p o s}} e^{-s_{j}}\right) \]
实验
数据集
本次实践使用的数据集是DocRED,DocRED 是一个比较新的大规模的众包数据集。其原始语料主要基于维基百科,包含了 3053 份文章,其中大约存在 7% 的实体,DocRED 还提供了公开的 leaderboard,用户可将模型预测的结果上传,评估文档级关系抽取的各种性能。
打开terminal下载数据集,注意文件位置example/re/document
cd example/re/document
wget 120.27.214.45/Data/re/document/data.tar.gz
tar -xzvf data.tar.gz
数据文件夹./data/的结构如下:
.
├── dev.json # 验证集
├── rel_info.json # 关系集
├── rel2id.json # 关系标签到ID的映射
├── test.json # 测试集
└── train_annotated.json # 训练集
数据文件的格式在数据集DocRED中的描述如下:
Data Format:
{
'title',
'sents': [
[word in sent 0],
[word in sent 1]
]
'vertexSet': [
[
{ 'name': mention_name,
'sent_id': mention in which sentence,
'pos': postion of mention in a sentence,
'type': NER_type}
{anthor mention}
],
[anthoer entity]
]
'labels': [
{
'h': idx of head entity in vertexSet,
't': idx of tail entity in vertexSet,
'r': relation,
'evidence': evidence sentences' id
}
]
}
模型训练
- 数据集和参数配置可以分别进入
data和conf文件夹中修改 - 如需从上次训练的模型开始训练:设置
conf/train.yaml中的train_from_saved_model为上次保存模型的路径即可从上次训练的模型开始训练,每次训练的日志默认保存在根目录,可用log_dir来配置;
python run.py
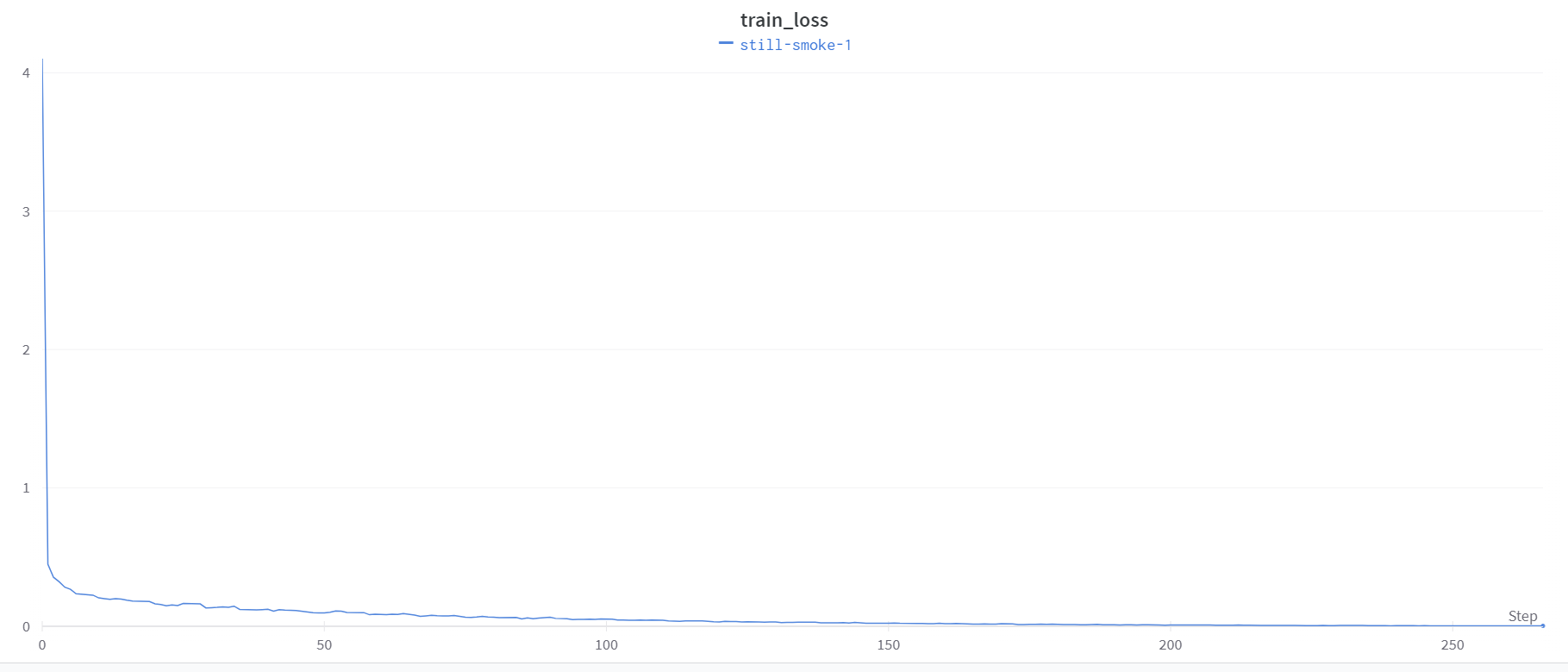
训练完成结果截图: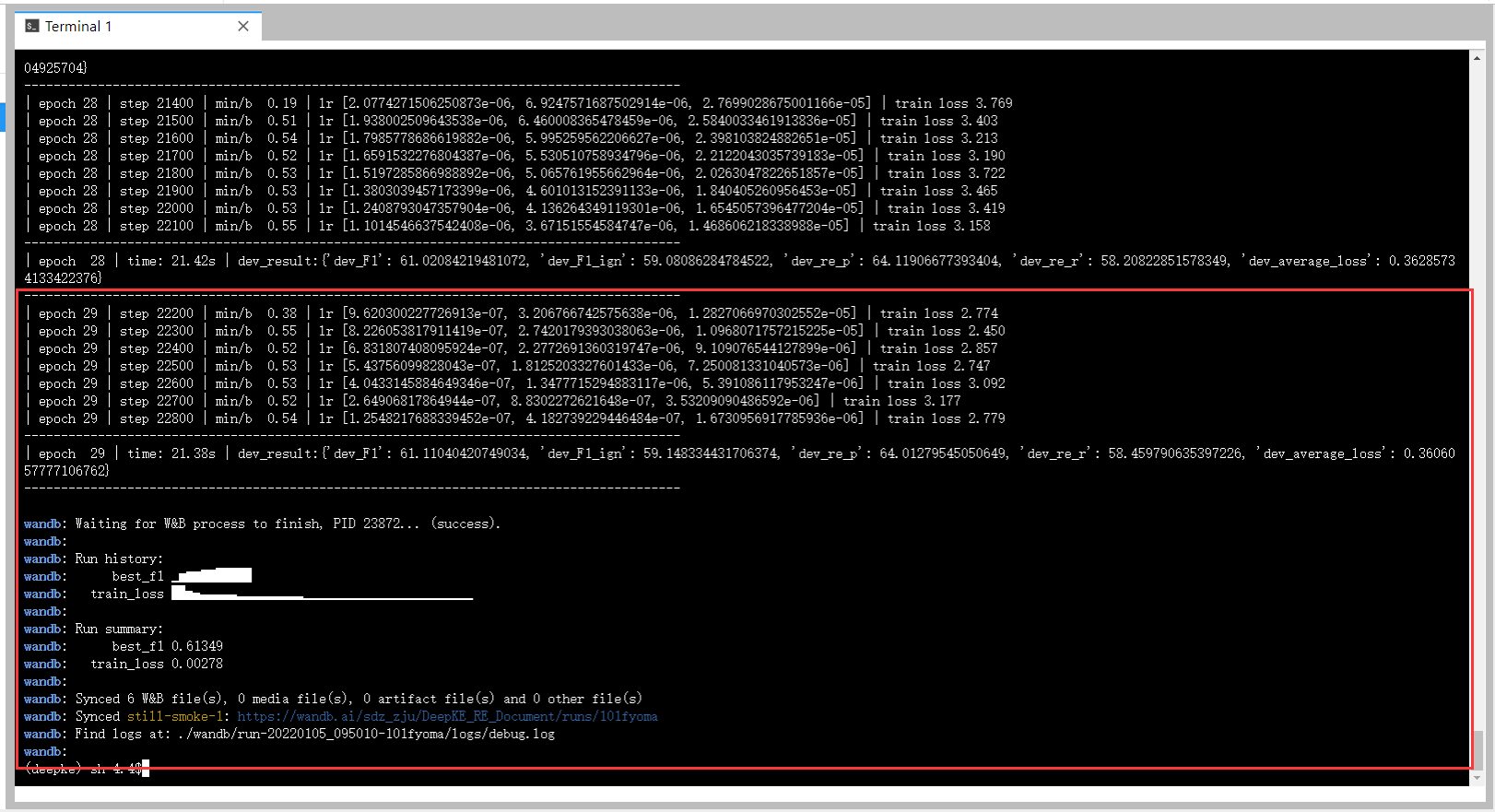
wandb全面支持参数的日志记录。
- 统一的dashboard,记录所有训练结果
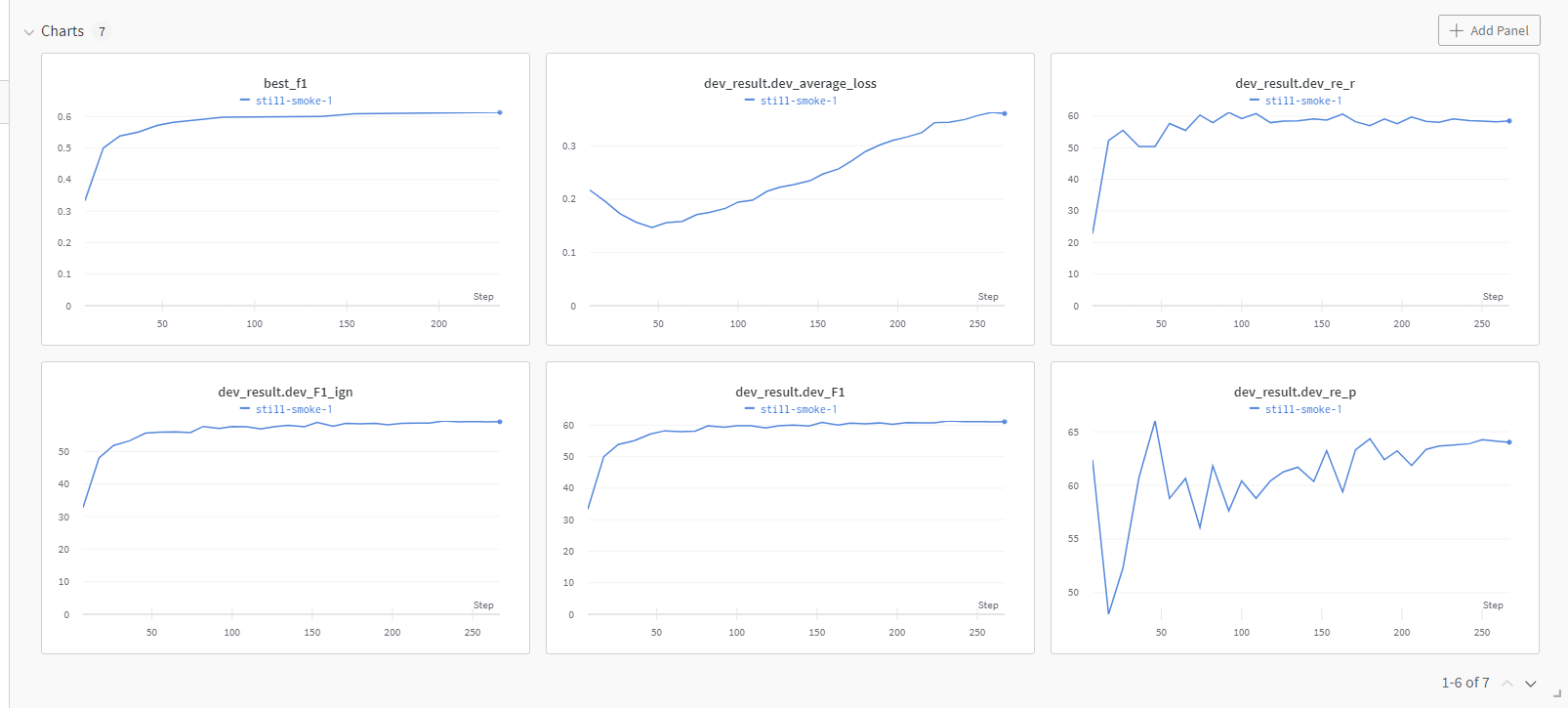
-
智能超参搜索,可视化结果
-
表格化数据,轻松到处csv文件分析
-
超参记录和模型文件保存
模型预测
python predict.py
预测结果截图:
result.json内容展示

主要代码解释·
获取数据:
Dataset = ReadDataset(cfg, cfg.dataset, tokenizer, cfg.max_seq_length)
train_file = os.path.join(cfg.data_dir, cfg.train_file)
dev_file = os.path.join(cfg.data_dir, cfg.dev_file)
test_file = os.path.join(cfg.data_dir, cfg.test_file)
train_features = Dataset.read(train_file)
dev_features = Dataset.read(dev_file)
test_features = Dataset.read(test_file)
训练:
train(cfg, model, train_features, dev_features, test_features)
模型预测输出:
model.load_state_dict(torch.load(cfg.load_path)['checkpoint'])
model.to(device)
T_features = test_features # Testing on the test set
#T_score, T_output = evaluate(cfg, model, T_features, tag="test")
pred = report(cfg, model, T_features)
with open("./result.json", "w") as fh:
json.dump(pred, fh)
少样本FEW-SHOT
原理
低资源的关系抽取任务是一个非常具有挑战的任务,随着标注样本数量的减少,模型的性能会显著下降。DeepKE中内嵌了一个基于KnowPrompt的低资源关系抽取算法,可以优于传统的finetuning的效果,其核心思想将分类任务转化为一种插入文字片(模板)的遮掩语言模型问题。具体为:DeepKE中的低资源(Few-shot)关系抽取是基于Pre-train, Prompt, Predict范式,在之前的BERT架构中的Attention和Cross-attention部分引入了Prompt参数,之后对参数进行Fine-tuning,这种方法在低资源场景下表现良好。该方法中的Prompt-tuning原理如下图所示:
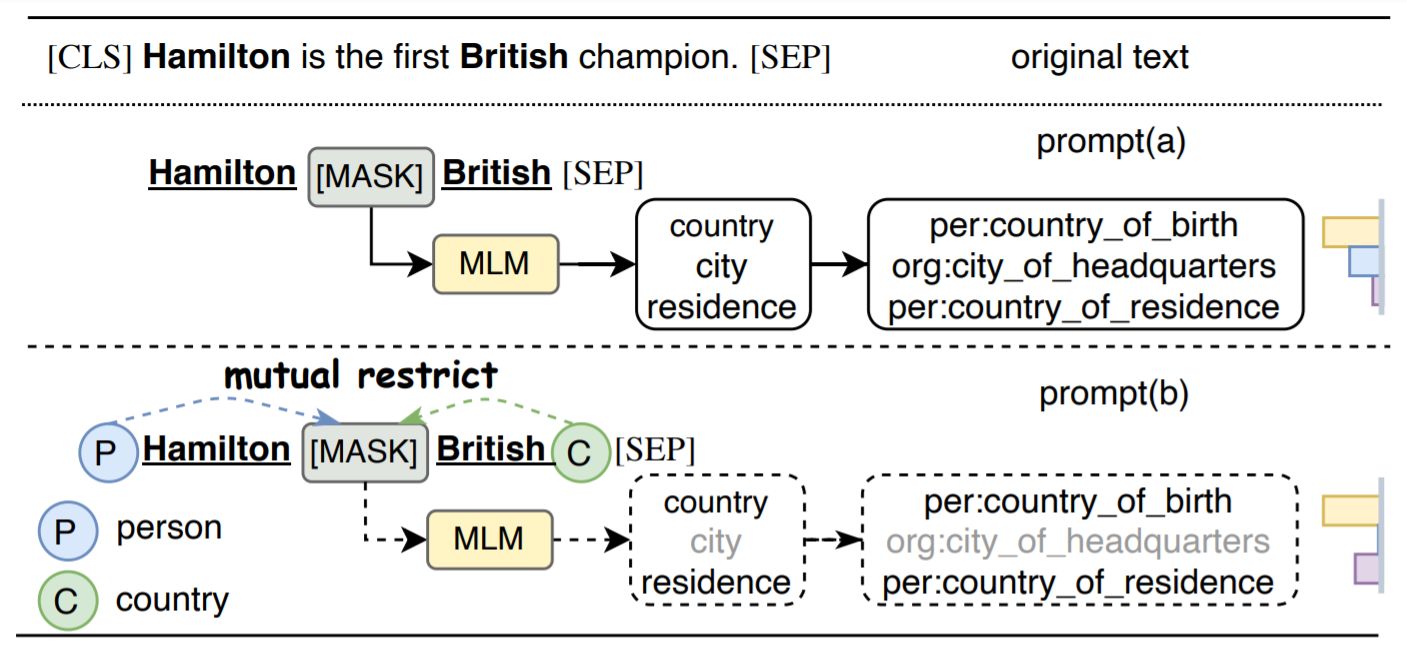
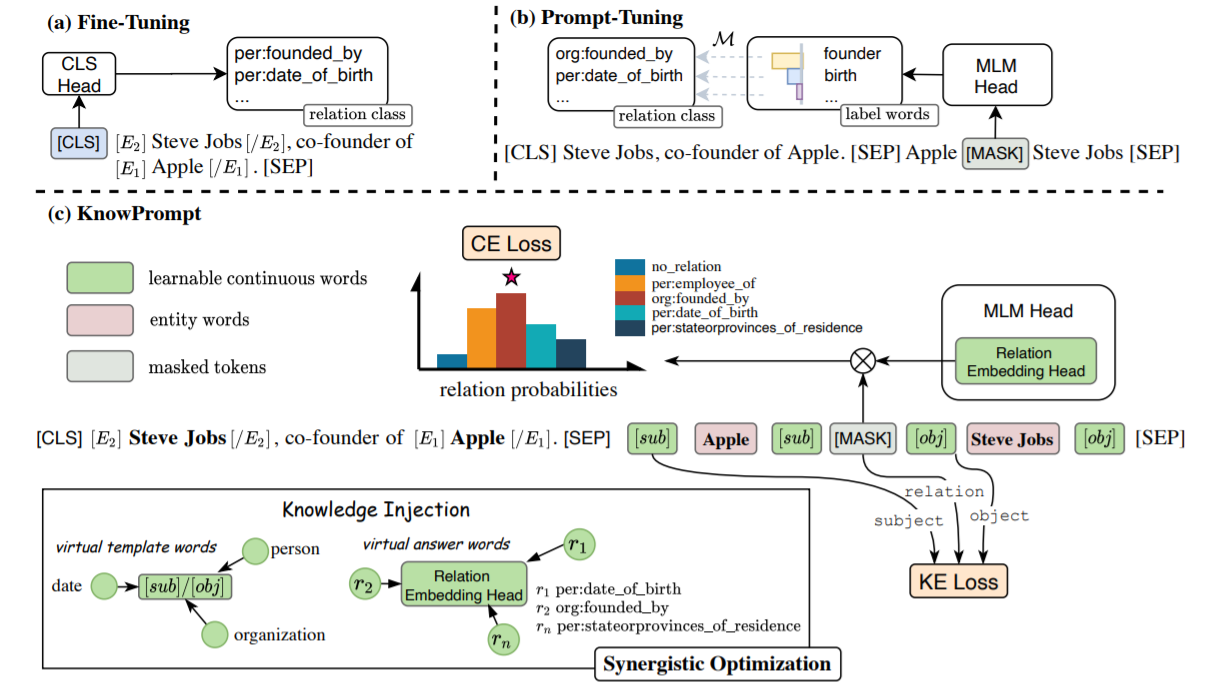
DeepKE使用了协同优化的知识感知提示调整方法Knowledge-aware Prompt-tuning(KnowPrompt)。具体来说,使用可学习的虚拟模板词和答案词将实体和关系知识注入到提示结构中,并利用知识约束协同优化它们的表示。Fine-tuning(图 a)、Prompt-tuning(图 b)和此处的 KnowPrompt(图 c)方法的模型架构如下图。Prompt中的答案词是指虚拟答案词。
实验
数据集
本次实践使用的数据集是SEMEVAL,SEMEVAL数据集来自于2010年的国际语义评测大会中Task 8:"Multi-Way Classification of Semantic Relations Between Pairs of Nominals",从官网下载的数据文件夹
进入DeepKE/example/re/few-shot,下载数据集
cd /home/ma-user/work/DeepKE/example/re/few-shot
wget 120.27.214.45/Data/re/few_shot/data.tar.gz
tar -xzvf data.tar.gz
数据文件夹./data/的结构如下:
.
├── rel2id.json # 关系标签到ID的映射
├── temp.txt # 关系标签处理
├── test.txt # 测试集
├── train.txt # 训练集
└── val.txt # 验证集
数据文件的格式在数据集SEMEVAL中的描述如下:
Data Format:
{
'token': [tokens in a sentence],
"h": {
"name": mention_name,
"pos" : [postion of mention in a sentence]
},
"t": {
"name": mention_name,
"pos" : [postion of mention in a sentence]
},
"relation": relation
}
模型训练
数据集和参数配置可以分别进入data和conf文件夹中修改
设置conf中train_from_saved_model为上次保存模型的路径即可从上次训练的模型开始训练
python run.py
训练完成结果截图:
wandb全面支持参数的日志记录
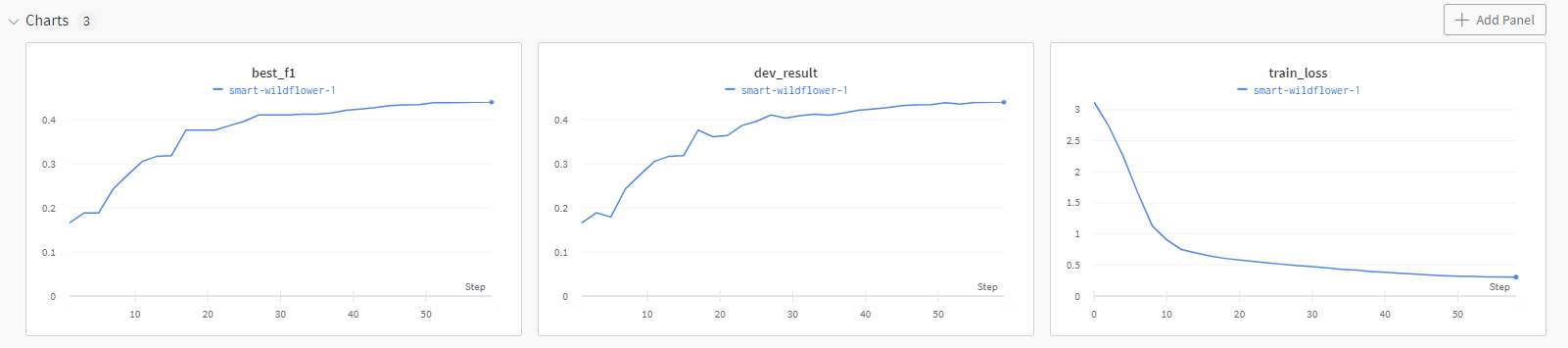
超参记录和模型文件保存
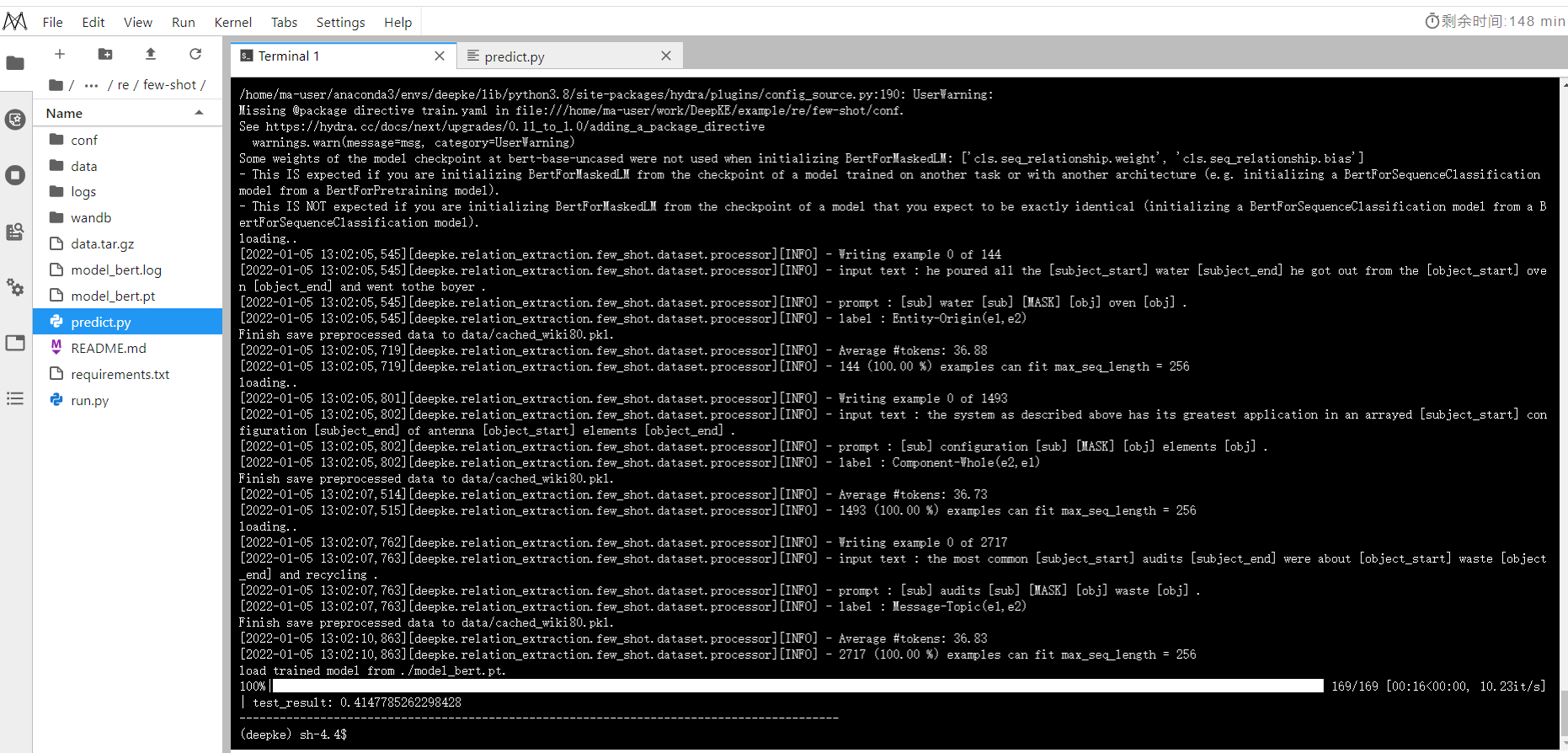
模型预测
python predict.py
模型预测结果截图:
代码解释
选择使用设备、获取数据并选择模型的相关代码
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
data = REDataset(cfg)
data_config = data.get_data_config()
config = AutoConfig.from_pretrained(cfg.model_name_or_path)
config.num_labels = data_config["num_labels"]
model = AutoModelForMaskedLM.from_pretrained(cfg.model_name_or_path, config=config)
# if torch.cuda.device_count() > 1:
# print("Let's use", torch.cuda.device_count(), "GPUs!")
# model = torch.nn.DataParallel(model, device_ids = list(range(torch.cuda.device_count())))
model.to(device)
lit_model = BertLitModel(args=cfg, model=model, device=device,tokenizer=data.tokenizer)
模型进行训练相关代码。
for epoch in range(cfg.num_train_epochs):
model.train()
num_batch = len(data.train_dataloader())
total_loss = 0
log_loss = 0
for index, train_batch in enumerate(tqdm(data.train_dataloader())):
loss = lit_model.training_step(train_batch, index)
total_loss += loss.item()
log_loss += loss.item()
loss.backward()
optimizer.step()
scheduler.step()
optimizer.zero_grad()
if log_step > 0 and (index+1) % log_step == 0:
cur_loss = log_loss / log_step
logging(cfg.log_dir,
'| epoch {:2d} | step {:4d} | lr {} | train loss {:5.3f}'.format(
epoch, (index+1), scheduler.get_last_lr(), cur_loss * 1000)
, print_=False)
log_loss = 0
avrg_loss = total_loss / num_batch
wandb.log({
"train_loss": avrg_loss
})
logging(cfg.log_dir,
'| epoch {:2d} | train loss {:5.3f}'.format(
epoch, avrg_loss * 1000))
model.eval()
with torch.no_grad():
val_loss = []
for val_index, val_batch in enumerate(tqdm(data.val_dataloader())):
loss = lit_model.validation_step(val_batch, val_index)
val_loss.append(loss)
f1, best, best_f1 = lit_model.validation_epoch_end(val_loss)
logging(cfg.log_dir,'-' * 89)
logging(cfg.log_dir,
'| epoch {:2d} | dev_result: {}'.format(epoch, f1))
logging(cfg.log_dir,'-' * 89)
logging(cfg.log_dir,
'| best_f1: {}'.format(best_f1))
logging(cfg.log_dir,'-' * 89)
wandb.log({
"dev_result": f1,
"best_f1":best_f1
})
if cfg.save_path != "" and best != -1:
save_path = cfg.save_path
torch.save({
'epoch': epoch,
'checkpoint': model.state_dict(),
'best_f1': best_f1,
'optimizer': optimizer.state_dict()
}, save_path
, _use_new_zipfile_serialization=False)
logging(cfg.log_dir,
'| successfully save model at: {}'.format(save_path))
logging(cfg.log_dir,'-' * 89)
模型进行验证、预测输出
def test(cfg, model, lit_model, data):
model.eval()
with torch.no_grad():
test_loss = []
for test_index, test_batch in enumerate(tqdm(data.test_dataloader())):
loss = lit_model.test_step(test_batch, test_index)
test_loss.append(loss)
f1 = lit_model.test_epoch_end(test_loss)
logging(cfg.log_dir,
'| test_result: {}'.format(f1))
logging(cfg.log_dir,'-' * 89)
test(cfg, model, lit_model, data)
常规全监督STANDARD
原理
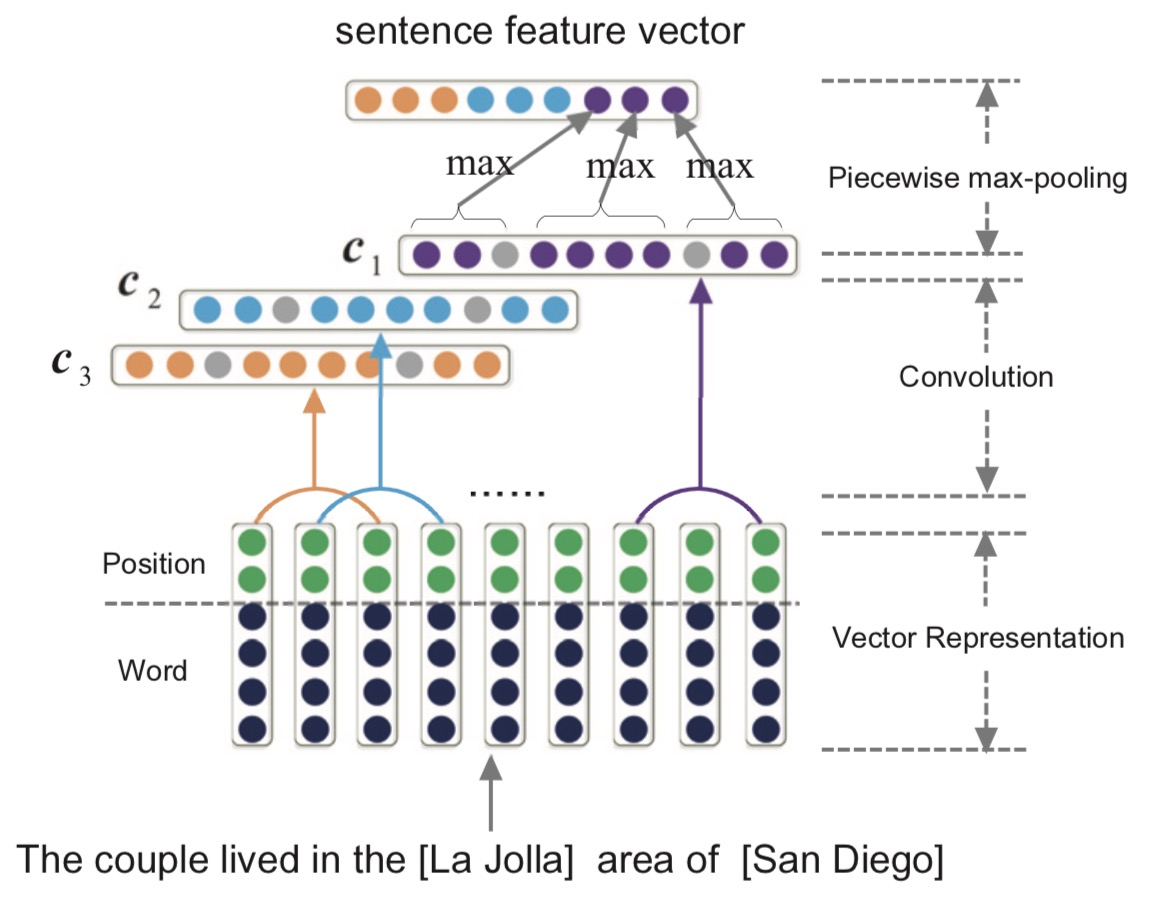
Deepke实现了大量的传统关系抽取模型,如基于pcnn、bilstm、transformer、gcn、以及预训练语言模型的方法。可以通过超参数的选择来灵活使用各种模型来进行关系抽取。本试验主要使用pcnn模型来提取关系,其思想是在关系抽取任务中引入远程监督学习的方法,尤其是针对远程监督中的标记噪声问题,使用分段的CNN(Piecewise CNN,简写为PCNN)抽取句子特征向量表示的同时,考虑到同一个Bag 中句子表达关系的不同重要性,引入了句子级别的Attention 机制。
句子信息主要包括词嵌入和位置嵌入,句子特征向量表示: PCNN 与CNN 模型抽取句子特征向量方法相同,组合词和词相对位置的embedding 表示输入CNN 模型进行卷积。不同的是在池化部分,使用分段池化取代前面的最大值池化操作。分段池化根据句子中两个实体的位置将句子分为三个片段,再分别进行池化操作,这样能捕捉句子中的结构信息以及更加细粒度的特征。经过卷积层后,根据头尾位置分为三段进行最大池化,然后通过全连接层,可以得到句子的关系信息获得。
实验
数据集
进入DeepKE/example/re/standard,下载数据集
wget 120.27.214.45/Data/re/standard/data.tar.gz
tar -xzvf data.tar.gz
| sentence | relation | head | tail |
|---|---|---|---|
| 孔正锡在2005年以一部温馨的爱情电影《长腿叔叔》敲开电影界大门。 | 导演 | 长腿叔叔 | 孔正锡 |
| 《伤心的树》是吴宗宪的音乐作品,收录在《你比从前快乐》专辑中。 | 所属专辑 | 伤心的树 | 你比从前快乐 |
| 2000年8月,「天坛大佛」荣获「香港十大杰出工程项目」第四名。 | 所在城市 | 天坛大佛 | 香港 |
在 data 文件夹下存放训练数据。训练文件主要有四个文件。
train.csv:包含6个训练三元组,每行代表一个三元组,按句子、关系、头实体和尾实体排序,用,分隔。valid.csv:包含3个验证三元组,每行代表一个三元组,按句子、关系、头实体和尾实体排序,用,分隔。test.csv:包含3个测试三元组,每行代表一个三元组,按句子、关系、头实体和尾实体排序,用,分隔。relation.csv:包含4个关系三元组,每行代表一个三元组,按句子、关系、头实体和尾实体排序,用,分隔。
模型训练
数据集和参数配置可以分别进入data和conf文件夹中修改
python run.py
运行结果
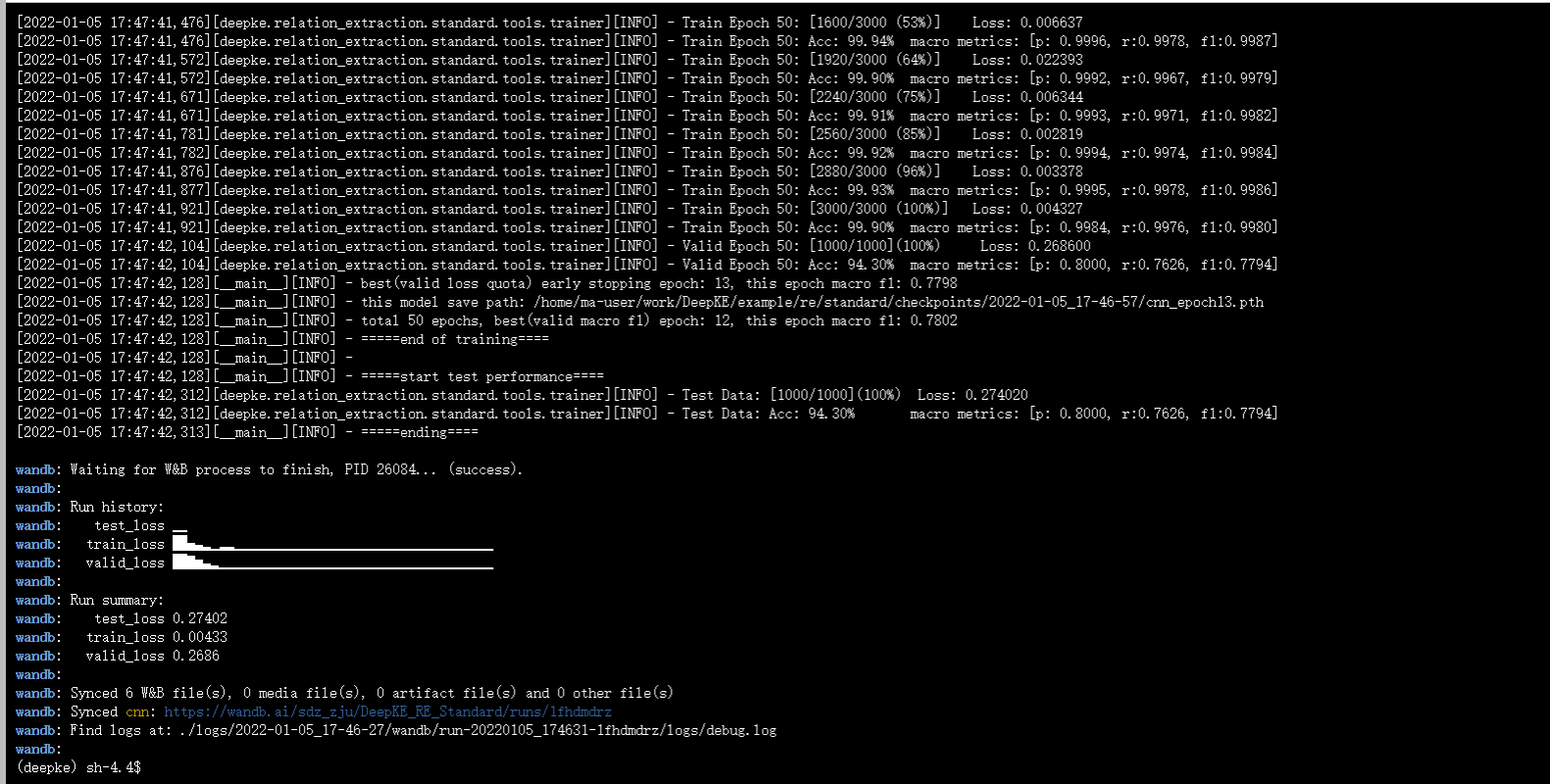
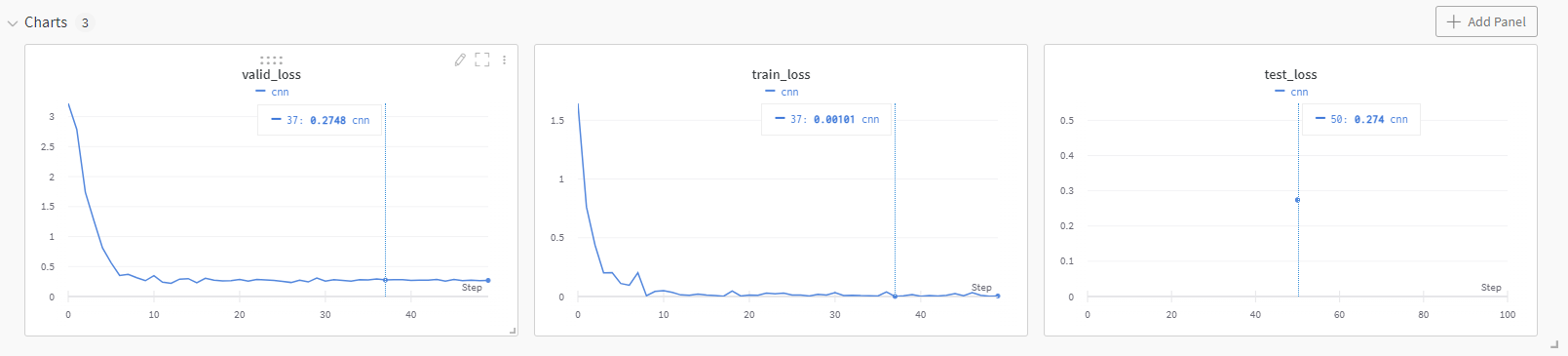
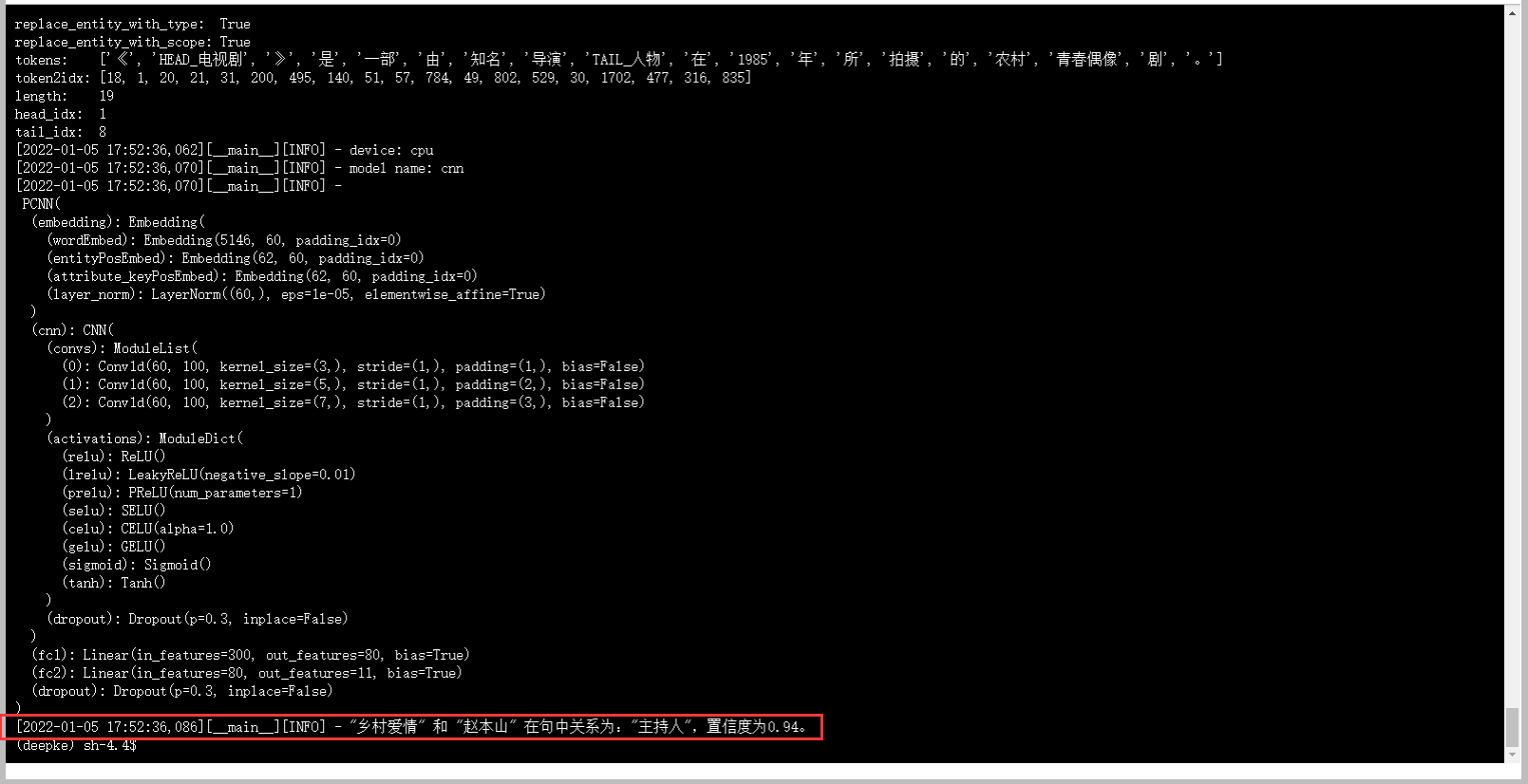
模型预测
修改DeepKE/example/re/standard/conf/predict.yaml
# 自定义模型存储的路径
fp: '/home/ma-user/work/DeepKE/example/re/standard/checkpoints/2022-01-05_17-47-42/cnn_epoch50.pth'
python predict.py
运行结果
代码解释
可选用的模型,设定是否使用GPU,以及指定使用GPU的编号
__Model__ = {
'cnn': models.PCNN,
'rnn': models.BiLSTM,
'transformer': models.Transformer,
'gcn': models.GCN,
'capsule': models.Capsule,
'lm': models.LM,
}
# device
if cfg.use_gpu and torch.cuda.is_available():
device = torch.device('cuda', cfg.gpu_id)
else:
device = torch.device('cpu')
logger.info(f'device: {device}')
数据进行处理并获取
# 如果不修改预处理的过程,这一步最好注释掉,不用每次运行都预处理数据一次
if cfg.preprocess:
preprocess(cfg)
train_data_path = os.path.join(cfg.cwd, cfg.out_path, 'train.pkl')
valid_data_path = os.path.join(cfg.cwd, cfg.out_path, 'valid.pkl')
test_data_path = os.path.join(cfg.cwd, cfg.out_path, 'test.pkl')
vocab_path = os.path.join(cfg.cwd, cfg.out_path, 'vocab.pkl')
if cfg.model_name == 'lm':
vocab_size = None
else:
vocab = load_pkl(vocab_path)
vocab_size = vocab.count
cfg.vocab_size = vocab_size
train_dataset = CustomDataset(train_data_path)
valid_dataset = CustomDataset(valid_data_path)
test_dataset = CustomDataset(test_data_path)
train_dataloader = DataLoader(train_dataset, batch_size=cfg.batch_size, shuffle=True, collate_fn=collate_fn(cfg))
valid_dataloader = DataLoader(valid_dataset, batch_size=cfg.batch_size, shuffle=True, collate_fn=collate_fn(cfg))
test_dataloader = DataLoader(test_dataset, batch_size=cfg.batch_size, shuffle=True, collate_fn=collate_fn(cfg))
选择使用的优化器等
optimizer = optim.Adam(model.parameters(), lr=cfg.learning_rate, weight_decay=cfg.weight_decay)
scheduler = optim.lr_scheduler.ReduceLROnPlateau(optimizer, factor=cfg.lr_factor, patience=cfg.lr_patience)
criterion = nn.CrossEntropyLoss()
进行训练
for epoch in range(1, cfg.epoch + 1):
manual_seed(cfg.seed + epoch)
train_loss = train(epoch, model, train_dataloader, optimizer, criterion, device, writer, cfg)
valid_f1, valid_loss = validate(epoch, model, valid_dataloader, criterion, device, cfg)
scheduler.step(valid_loss)
model_path = model.save(epoch, cfg)
# logger.info(model_path)
train_losses.append(train_loss)
valid_losses.append(valid_loss)
wandb.log({
"train_loss":train_loss,
"valid_loss":valid_loss
})
if best_f1 < valid_f1:
best_f1 = valid_f1
best_epoch = epoch
# 使用 valid loss 做 early stopping 的判断标准
if es_loss > valid_loss:
es_loss = valid_loss
es_f1 = valid_f1
es_epoch = epoch
es_patience = 0
es_path = model_path
else:
es_patience += 1
if es_patience >= cfg.early_stopping_patience:
best_es_epoch = es_epoch
best_es_f1 = es_f1
best_es_path = es_path
进行验证
_ , test_loss = validate(-1, model, test_dataloader, criterion, device, cfg)
进行预测,看到deepke通过argmax来选出概率最大标签并做出最终预测。
with torch.no_grad():
y_pred = model(x)
y_pred = torch.softmax(y_pred, dim=-1)[0]
prob = y_pred.max().item()
prob_rel = list(rels.keys())[y_pred.argmax().item()]
logger.info(f"\"{data[0]['head']}\" 和 \"{data[0]['tail']}\" 在句中关系为:\"{prob_rel}\",置信度为{prob:.2f}。")
命名实体识别NER
命名实体识别(也称为命名实体识别、实体分块和实体提取)是信息提取的一个子任务,旨在将非结构化文本中识别出实体和其类型,例如人名 、组织、地点、医疗代码、时间表达、数量、货币价值、百分比等。
少样本FEW-SHOT
原理
低资源的实体识别任务是一个非常具有挑战的任务,随着标注样本数量的减少,模型的性能会显著下降。我们在DeepKE中内嵌了一个基于prompt的低资源实体识别算法,可以优于传统的finetuning的效果。
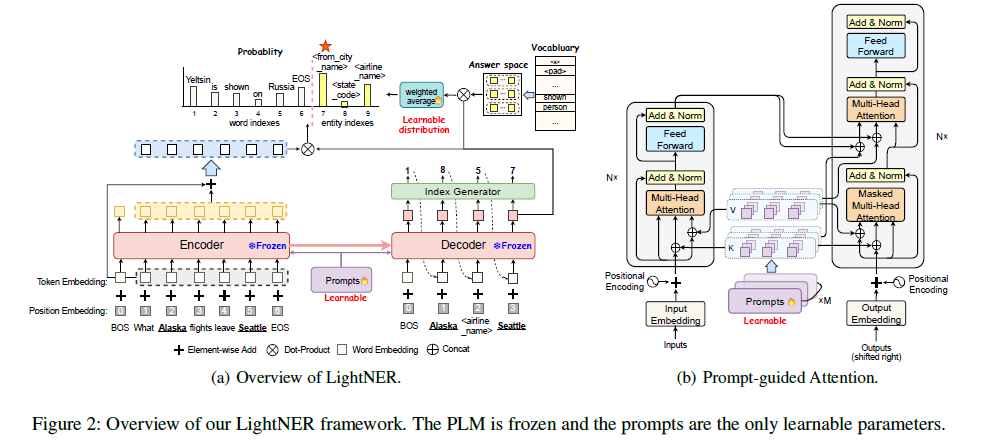
具体模型为LightNER:一个轻量级的生成框架,用于低资源的NER与提示引导的注意。具体来说,模型没有通过训练特定标签的输出层来处理序列标签,而是将NER任务重新表述为一个生成问题,并为提示学习构建一个语义感知的答案空间。因此可以在不修改网络结构的情况下直接利用任何新的或复杂的实体类型,并且可以推广到低资源的领域。此外模型设计了提示引导的注意,将连续的提示纳入生成框架中的自我注意层,以引导注意的焦点,该层明确地将LM的条件放在提示上,这对PLM来说是灵活和可插入的。
实验
数据集
进入DeepKE/example/ner/few-shot,下载数据集
wget 120.27.214.45/Data/ner/few_shot/data.tar.gz
tar -xzvf data.tar.gz
在 data 文件夹下存放训练数据。包含conll2003,mit-movie,mit-restaurant和atis等数据集。在资源丰富的场景中,我们使用数据集 CoNLL-2003,专注于与人员、位置、组织和杂项实体名称相关的四种命名实体。在低资源场景中,使用数据集 ATIS、MIT Restaurant 和 MIT Movie,每个数据集都被预处理成 conll 格式和采样的 k-shot 数据进行训练。
conll2003包含以下数据:
train.txt:存放训练数据集dev.txt:存放验证数据集test.txt:存放测试数据集indomain-train.txt:存放indomain数据集
mit-movie, mit-restaurant和atis包含以下数据:
k-shot-train.txt:k=[10, 20, 50, 100, 200, 500],存放训练数据集test.txt:存放测试数据集
模型训练
模型加载和保存位置以及配置可以在conf文件夹中修改
训练conll2003:
-
要修改
conf/train/conll.yaml中的模型保存路径 -
在
run.py中修改所使用的GPU idos.environ["CUDA_DEVICE_ORDER"]="PCI_BUS_ID" os.environ["CUDA_VISIBLE_DEVICES"]='0' -
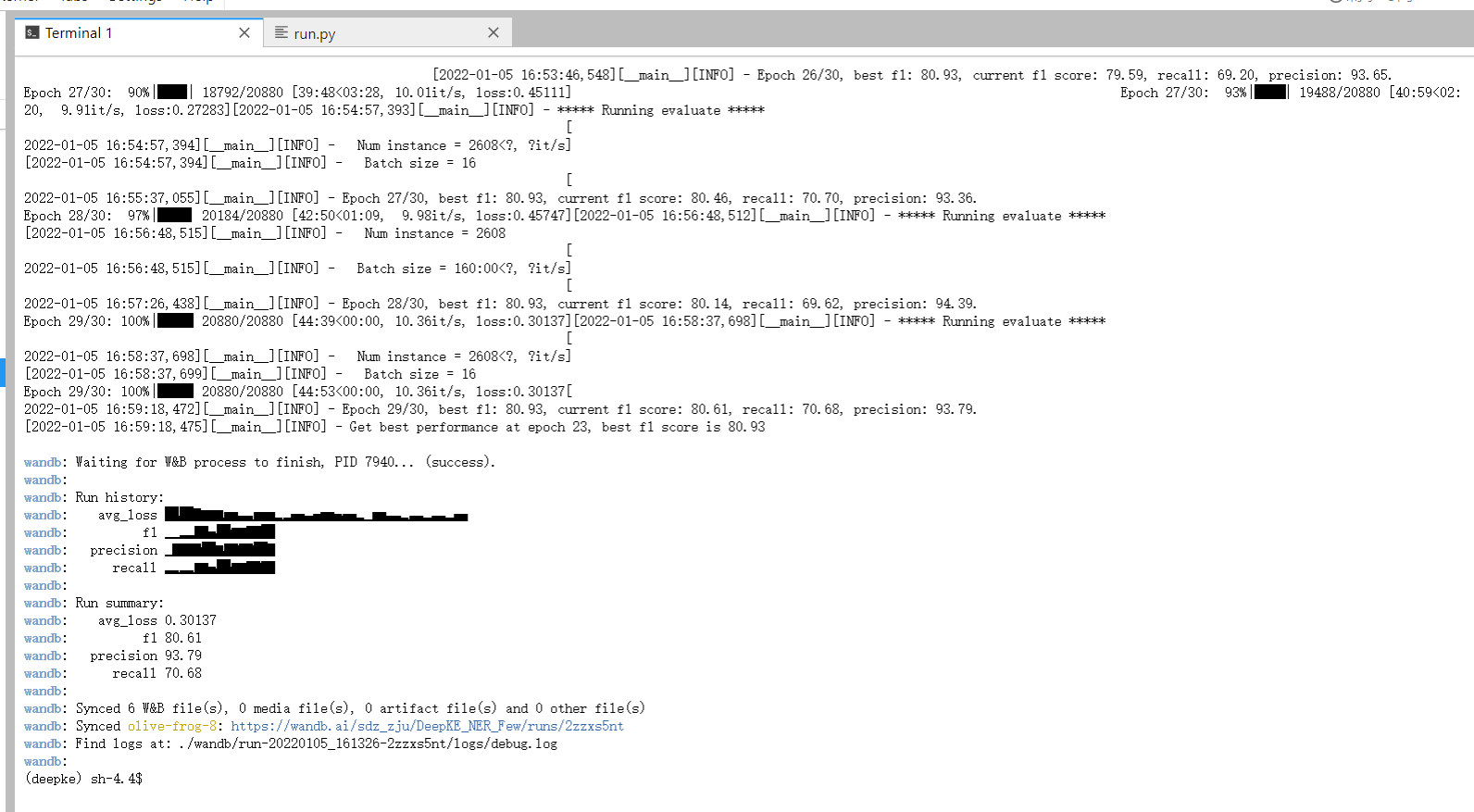
运行:
python run.py运行结果截图:
进行few-shot训练:
-
修改对应配置文件
conf/train/few_shot.yaml中的模型保存路径,若要加载模型,修改few_shot.yaml中的load_path) -
在
run.py中修改所使用的GPU idos.environ["CUDA_DEVICE_ORDER"]="PCI_BUS_ID" os.environ["CUDA_VISIBLE_DEVICES"]='0' -
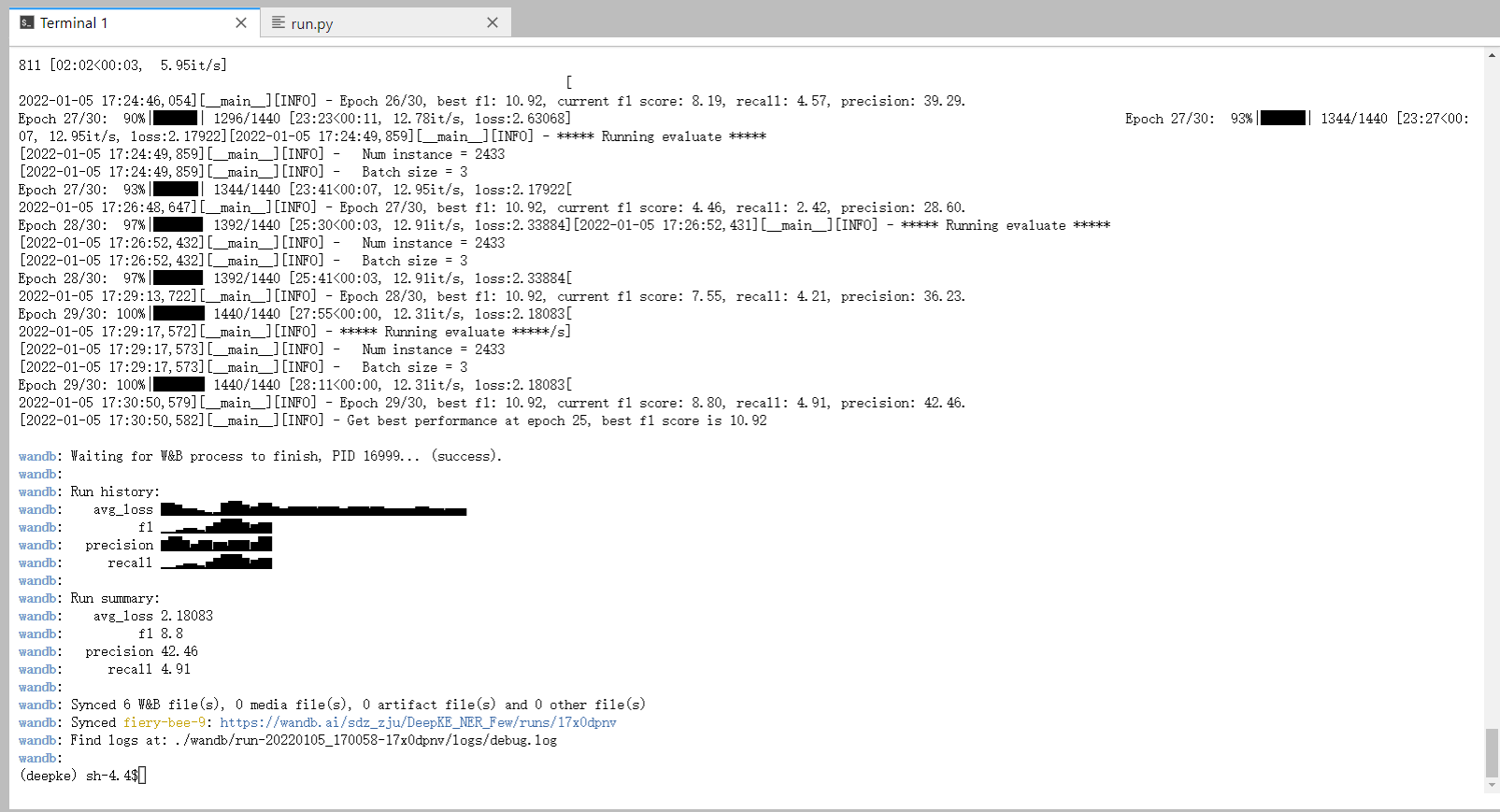
运行:
python run.py +train=few_shot运行结果截图:
每次训练的日志保存在
logs文件夹内,模型结果保存目录可以自定义。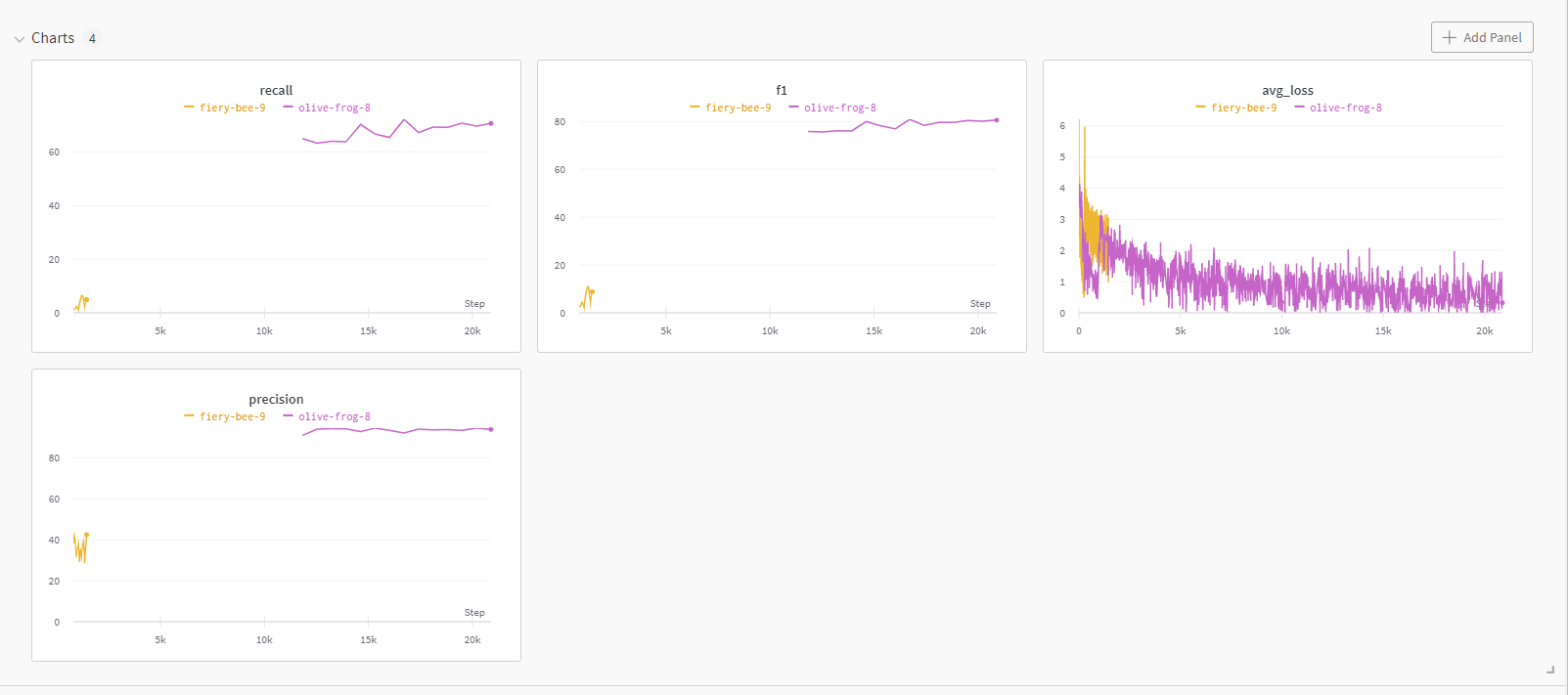
预测与保存
需要避免的坑
-
在
config.yaml中加入- predict -
在
predict.yaml中修改load_path为模型路径以及write_path为预测结果保存路径。DeepKE/example/ner/few-shot/conf/predict.yamlcwd: ??? seed: 1 bart_name: "facebook/bart-large" dataset_name: conll2003 device: cuda num_epochs: 30 batch_size: 16 learning_rate: 2e-5 warmup_ratio: 0.01 eval_begin_epoch: 16 src_seq_ratio: 0.6 tgt_max_len: 10 num_beams: 1 length_penalty: 1 use_prompt: True prompt_len: 10 prompt_dim: 800 freeze_plm: True learn_weights: True notes: '' save_path: checkpoint # 模型保存路径 load_path: /home/ma-user/work/DeepKE/example/ner/few-shot/outputs/2022-01-05/16-13-28/checkpoint/conll2003_16_2e-05/best_model.pth # 模型加载路径,不能为空 write_path: /home/ma-user/work/DeepKE/example/ner/few-shot/data/conll2003/predict.txt -
在
data/conll2003目录下创建文件predict.txt,否则后面运行predict.txt会报错找不到目
标文件进行写入。
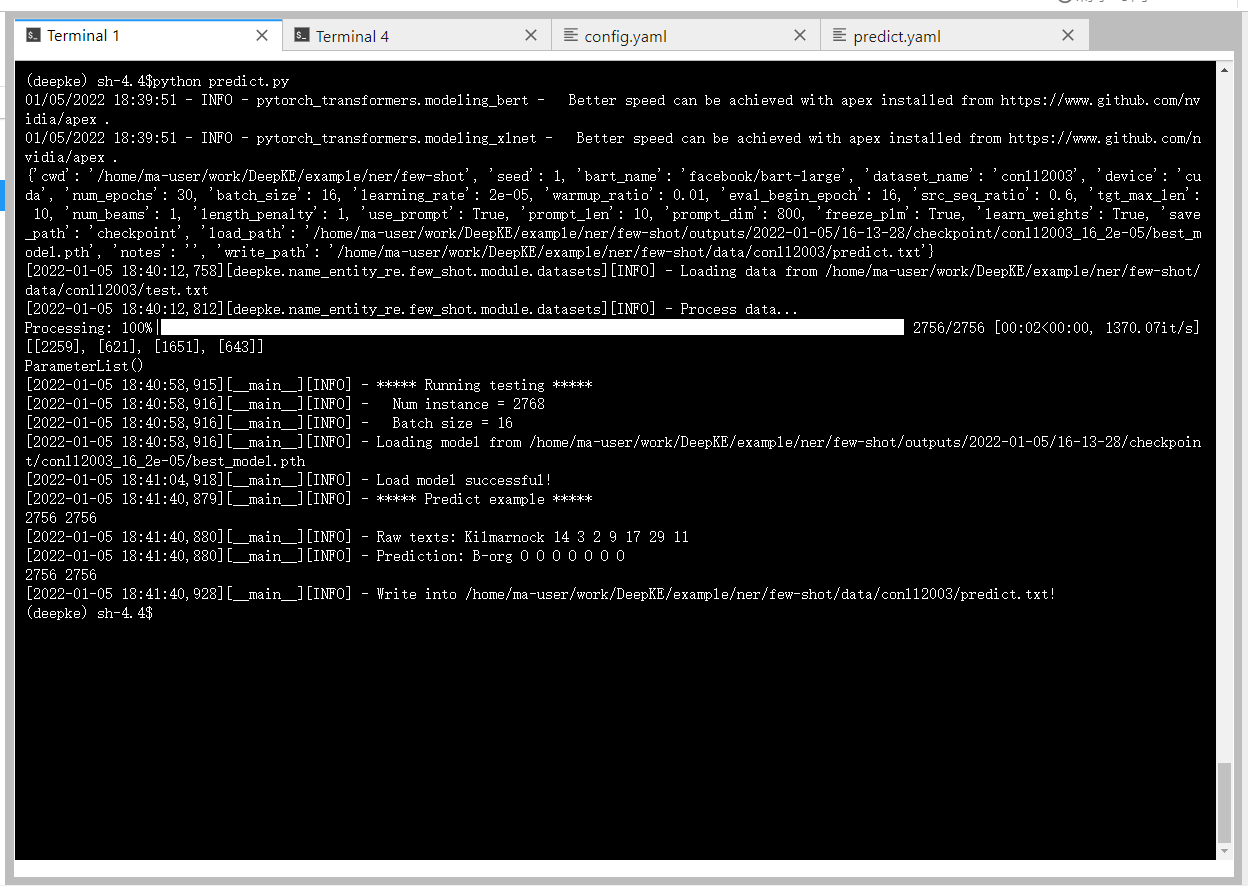
python predict.py
运行结果截图:
代码解释
在低资源ner中,我们针对不同数据集的路径,不同的数据处理方式和标签映射
DATA_PROCESS = {
'conll2003': ConllNERProcessor,
'mit-movie': ConllNERProcessor,
'mit-restaurant': ConllNERProcessor,
'atis': ConllNERProcessor
}
DATA_PATH = {
'conll2003': {'train': 'data/conll2003/train.txt',
'dev': 'data/conll2003/dev.txt',
'test': 'data/conll2003/test.txt'},
'mit-movie': {'train': 'data/mit-movie/20-shot-train.txt',
'dev': 'data/mit-movie/test.txt'},
'mit-restaurant': {'train': 'data/mit-restaurant/10-shot-train.txt',
'dev': 'data/mit-restaurant/test.txt'},
'atis': {'train': 'data/atis/20-shot-train.txt',
'dev': 'data/atis/test.txt'}
}
MAPPING = {
'conll2003': {'loc': '<<location>>',
'per': '<<person>>',
'org': '<<organization>>',
'misc': '<<others>>'},
'mit-movie': mit_movie_mapping,
'mit-restaurant': mit_restaurant_mapping,
'atis': atis_mapping
}
DeepKE通过并行的方式处理数据,并定义模型、计算指标及损失函数,可以看到使用一种基于seq2seq的方式实现实体识别,可以适用于抽取各种常规和嵌套的实体。
获取并处理数据
process = data_process(data_path=data_path, mapping=mapping, bart_name=cfg.bart_name, learn_weights=cfg.learn_weights)
train_dataset = dataset_class(data_processor=process, mode='train')
train_dataloader = DataLoader(train_dataset, collate_fn=train_dataset.collate_fn, batch_size=cfg.batch_size, num_workers=4)
dev_dataset = dataset_class(data_processor=process, mode='dev')
dev_dataloader = DataLoader(dev_dataset, collate_fn=dev_dataset.collate_fn, batch_size=cfg.batch_size, num_workers=4)
label_ids = list(process.mapping2id.values())
定义模型、计算指标及损失函数
prompt_model = PromptBartModel(tokenizer=process.tokenizer, label_ids=label_ids, args=cfg)
model = PromptGeneratorModel(prompt_model=prompt_model, bos_token_id=0,
eos_token_id=1,
max_length=cfg.tgt_max_len, max_len_a=cfg.src_seq_ratio,num_beams=cfg.num_beams, do_sample=False,
repetition_penalty=1, length_penalty=cfg.length_penalty, pad_token_id=1,
restricter=None)
metrics = Seq2SeqSpanMetric(eos_token_id=1, num_labels=len(label_ids), target_type='word')
loss = get_loss
模型训练
trainer = Trainer(train_data=train_dataloader, dev_data=dev_dataloader, test_data=None, model=model, args=cfg, logger=logger, loss=loss,
metrics=metrics, writer=writer)
trainer.train()
模型预测
trainer = Trainer(train_data=None, dev_data=None, test_data=test_dataloader, model=model, process=process, args=cfg, logger=logger,
loss=None, metrics=None, writer=writer)
trainer.predict()
常规全监督STANDARD
原理
本实验采用 BERT 来进行识别命名实体,BERT是一种以Transformers为主要框架的双向编码表征模型。BERT源码可以从google-research的github中获取源码地址,
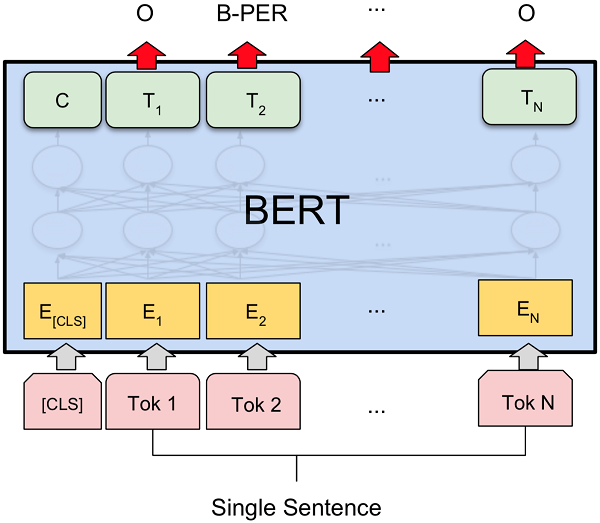
实验
实验环境平台为Google Colab,在谷歌云端硬盘新建DeepKE文件夹,为后续将下载好的数据、模型和日志文件保存到自己谷歌云端硬盘做准备,在DeepKE文件夹新建Standard Fully Supervised NER.ipynb文件,然后再用Google colab打开,然后再Standard Fully Supervised NER.ipynb.ipynb文件加载谷歌云端硬盘。
from google.colab import drive
drive.mount('/content/drive')
将DeepKE文件夹路径环境变为当下路径。
import os
path = '/content/drive/MyDrive/OpenUE'
os.chdir(path)
!ls
安装DeepKE与git拉取DeepKE模型最新代码。
!pip install DeepKE
!git clone https://github.com/zjunlp/DeepKE.git
本实验采用 NER 的专门数据集人民日报数据集,专注于与人员 (PER)、位置 (LOC) 和组织 (ORG) 相关的命名实体类型。
| Word | Named entity tag |
|---|---|
| 早 | O |
| 在 | O |
| 1 | O |
| 9 | O |
| 7 | O |
| 5 | O |
| 年 | O |
| , | O |
| 张 | B-PER |
| 鸿 | I-PER |
| 飞 | I-PER |
| 就 | O |
| 有 | O |
| 《 | O |
| 草 | O |
| 原 | O |
| 新 | O |
| 医 | O |
| 》 | O |
| 赴 | O |
| 法 | B-LOC |
| 展 | O |
| 览 | O |
| , | O |
| 为 | O |
| 我 | O |
| 国 | O |
| 驻 | B-ORG |
| 法 | I-ORG |
| 使 | I-ORG |
| 馆 | I-ORG |
| 收 | O |
| 藏 | O |
| 。 | O |
- 训练数据集
train.txt:包含20,864个句子,包括979,180个命名实体标签。 - 验证数据集
valid.txt:包含2,318个句子,包括109,870个命名实体标签。 - 测试数据集
test.txt:包含4636个句子,包括219197个命名实体标签。
数据集下载:
!wget 120.27.214.45/Data/ner/standard/data.tar.gz
!tar -xzvf data.tar.gz
!head -n 10 data/test.txt
输出:
我 O
们 O
变 O
而 O
以 O
书 O
会 O
友 O
, O
以 O
书 O
结 O
缘 O
, O
把 O
欧 B-LOC
美 B-LOC
、 O
港 B-LOC
台 B-LOC
导入必要的包:
from __future__ import absolute_import, division, print_function
import csv
import json
import logging
import os
import random
import sys
import numpy as np
import torch
import torch.nn.functional as F
from pytorch_transformers import (WEIGHTS_NAME, AdamW, BertConfig, BertForTokenClassification, BertTokenizer, WarmupLinearSchedule)
from torch import nn
from torch.utils.data import (DataLoader, RandomSampler, SequentialSampler, TensorDataset)
from torch.utils.data.distributed import DistributedSampler
from tqdm import tqdm, trange
from seqeval.metrics import classification_report
import hydra
from hydra import utils
from DeepKE.name_entity_re.standard import *
logging.basicConfig(format = '%(asctime)s - %(levelname)s - %(name)s - %(message)s',
datefmt = '%m/%d/%Y %H:%M:%S',
level = logging.INFO)
logger = logging.getLogger(__name__)
配置模型参数:
class Config(object):
data_dir = "data/" # The input data dir
bert_model = "bert-base-chinese"
task_name = "ner"
output_dir = "checkpoints"
max_seq_length = 128
do_train = True # Fine-tune or not
do_eval = True # Evaluate or not
eval_on = "dev"
do_lower_case = True
train_batch_size = 32
eval_batch_size = 8
learning_rate = 5e-5
num_train_epochs = 1 # The number of training epochs
warmup_proportion = 0.1
weight_decay = 0.01
adam_epsilon = 1e-8
max_grad_norm = 1.0
use_gpu = True # Use gpu or not
gpu_id = 0 # Which gpu to be used
local_rank = -1
seed = 42
gradient_accumulation_steps = 1
fp16 = False
fp16_opt_level = "01"
loss_scale = 0.0
text = "秦始皇兵马俑位于陕西省西安市,1961年被国务院公布为第一批全国重点文物保护单位,是世界八大奇迹之一。"
cfg = Config()
设定是否使用GPU,以及指定使用GPU的编号,并设置随机种子,设计随机数种子,在配置文件固定好,保证复现结果的一致性,易于代码实验结果复现。
# Use gpu or not
if cfg.use_gpu and torch.cuda.is_available():
device = torch.device('cuda', cfg.gpu_id)
else:
device = torch.device('cpu')
if cfg.gradient_accumulation_steps < 1:
raise ValueError("Invalid gradient_accumulation_steps parameter: {}, should be >= 1".format(cfg.gradient_accumulation_steps))
cfg.train_batch_size = cfg.train_batch_size // cfg.gradient_accumulation_steps
random.seed(cfg.seed)
np.random.seed(cfg.seed)
torch.manual_seed(cfg.seed)
if not cfg.do_train and not cfg.do_eval:
raise ValueError("At least one of `do_train` or `do_eval` must be True.")
建立模型保存的文件夹以及对数据进行的预处理,对于ner任务采用NerProcessor()函数处理不同类型的数据。
# Checkpoints
if os.path.exists(cfg.output_dir) and os.listdir(cfg.output_dir) and cfg.do_train:
raise ValueError("Output directory ({}) already exists and is not empty.".format(cfg.output_dir))
if not os.path.exists(cfg.output_dir):
os.makedirs(cfg.output_dir)
# Preprocess the input dataset
processor = NerProcessor()
label_list = processor.get_labels()
num_labels = len(label_list) + 1
模型准备
# Prepare the model
tokenizer = BertTokenizer.from_pretrained(cfg.bert_model, do_lower_case=cfg.do_lower_case)
train_examples = None
num_train_optimization_steps = 0
if cfg.do_train:
train_examples = processor.get_train_examples(cfg.data_dir)
num_train_optimization_steps = int(len(train_examples) / cfg.train_batch_size / cfg.gradient_accumulation_steps) * cfg.num_train_epochs
config = BertConfig.from_pretrained(cfg.bert_model, num_labels=num_labels, finetuning_task=cfg.task_name)
model = TrainNer.from_pretrained(cfg.bert_model,from_tf = False,config = config)
model.to(device)
param_optimizer = list(model.named_parameters())
no_decay = ['bias','LayerNorm.weight']
optimizer_grouped_parameters = [
{'params': [p for n, p in param_optimizer if not any(nd in n for nd in no_decay)], 'weight_decay': cfg.weight_decay},
{'params': [p for n, p in param_optimizer if any(nd in n for nd in no_decay)], 'weight_decay': 0.0}
]
warmup_steps = int(cfg.warmup_proportion * num_train_optimization_steps)
optimizer = AdamW(optimizer_grouped_parameters, lr=cfg.learning_rate, eps=cfg.adam_epsilon)
scheduler = WarmupLinearSchedule(optimizer, warmup_steps=warmup_steps, t_total=num_train_optimization_steps)
global_step = 0
nb_tr_steps = 0
tr_loss = 0
label_map = {i : label for i, label in enumerate(label_list,1)}
class TrainNer(BertForTokenClassification):
def forward(self, input_ids, token_type_ids=None, attention_mask=None, labels=None,valid_ids=None,attention_mask_label=None):
sequence_output = self.bert(input_ids, token_type_ids, attention_mask,head_mask=None)[0]
batch_size,max_len,feat_dim = sequence_output.shape
valid_output = torch.zeros(batch_size,max_len,feat_dim,dtype=torch.float32,device=0) #device: if use gpu, device=cfg.gpu_id else device='cpu'
for i in range(batch_size):
jj = -1
for j in range(max_len):
if valid_ids[i][j].item() == 1:
jj += 1
valid_output[i][jj] = sequence_output[i][j]
sequence_output = self.dropout(valid_output)
logits = self.classifier(sequence_output)
if labels is not None:
loss_fct = nn.CrossEntropyLoss(ignore_index=0)
if attention_mask_label is not None:
active_loss = attention_mask_label.view(-1) == 1
active_logits = logits.view(-1, self.num_labels)[active_loss]
active_labels = labels.view(-1)[active_loss]
loss = loss_fct(active_logits, active_labels)
else:
loss = loss_fct(logits.view(-1, self.num_labels), labels.view(-1))
return loss
else:
return logits
输出:

在模型的训练过程中,通过加载预训练模型来实现实体识别,这里可以使用不同类型的预训练模型,本实验采用bert实现。 整个训练的流程核心代码 如下所示。
if cfg.do_train:
train_features = convert_examples_to_features(train_examples, label_list, cfg.max_seq_length, tokenizer)
all_input_ids = torch.tensor([f.input_ids for f in train_features], dtype=torch.long)
all_input_mask = torch.tensor([f.input_mask for f in train_features], dtype=torch.long)
all_segment_ids = torch.tensor([f.segment_ids for f in train_features], dtype=torch.long)
all_label_ids = torch.tensor([f.label_id for f in train_features], dtype=torch.long)
all_valid_ids = torch.tensor([f.valid_ids for f in train_features], dtype=torch.long)
all_lmask_ids = torch.tensor([f.label_mask for f in train_features], dtype=torch.long)
train_data = TensorDataset(all_input_ids, all_input_mask, all_segment_ids, all_label_ids,all_valid_ids,all_lmask_ids)
train_sampler = RandomSampler(train_data)
train_dataloader = DataLoader(train_data, sampler=train_sampler, batch_size=cfg.train_batch_size)
model.train()
for _ in trange(int(cfg.num_train_epochs), desc="Epoch"):
tr_loss = 0
nb_tr_examples, nb_tr_steps = 0, 0
for step, batch in enumerate(tqdm(train_dataloader, desc="Iteration")):
batch = tuple(t.to(device) for t in batch)
input_ids, input_mask, segment_ids, label_ids, valid_ids,l_mask = batch
loss = model(input_ids, segment_ids, input_mask, label_ids,valid_ids,l_mask)
if cfg.gradient_accumulation_steps > 1:
loss = loss / cfg.gradient_accumulation_steps
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), cfg.max_grad_norm)
tr_loss += loss.item()
nb_tr_examples += input_ids.size(0)
nb_tr_steps += 1
if (step + 1) % cfg.gradient_accumulation_steps == 0:
optimizer.step()
scheduler.step() # Update learning rate schedule
model.zero_grad()
global_step += 1
# Save a trained model and the associated configuration
model_to_save = model.module if hasattr(model, 'module') else model # Only save the model it-self
model_to_save.save_pretrained(cfg.output_dir)
tokenizer.save_pretrained(cfg.output_dir)
label_map = {i : label for i, label in enumerate(label_list,1)}
model_config = {"bert_model":cfg.bert_model,"do_lower":cfg.do_lower_case, "max_seq_length":cfg.max_seq_length,"num_labels":len(label_list)+1,"label_map":label_map}
json.dump(model_config,open(os.path.join(cfg.output_dir,"model_config.json"),"w"))
# Load a trained model and config that you have fine-tuned
else:
# Load a trained model and vocabulary that you have fine-tuned
model = TrainNer.from_pretrained(cfg.output_dir)
tokenizer = BertTokenizer.from_pretrained(cfg.output_dir, do_lower_case=cfg.do_lower_case)
model.to(device)
输出:

在训练完成后,需要通过对标签进行预测和解码,来实现模型的测试和验证。
if cfg.do_eval:
if cfg.eval_on == "dev":
eval_examples = processor.get_dev_examples(cfg.data_dir)
elif cfg.eval_on == "test":
eval_examples = processor.get_test_examples(cfg.data_dir)
else:
raise ValueError("eval on dev or test set only")
eval_features = convert_examples_to_features(eval_examples, label_list, cfg.max_seq_length, tokenizer)
all_input_ids = torch.tensor([f.input_ids for f in eval_features], dtype=torch.long)
all_input_mask = torch.tensor([f.input_mask for f in eval_features], dtype=torch.long)
all_segment_ids = torch.tensor([f.segment_ids for f in eval_features], dtype=torch.long)
all_label_ids = torch.tensor([f.label_id for f in eval_features], dtype=torch.long)
all_valid_ids = torch.tensor([f.valid_ids for f in eval_features], dtype=torch.long)
all_lmask_ids = torch.tensor([f.label_mask for f in eval_features], dtype=torch.long)
eval_data = TensorDataset(all_input_ids, all_input_mask, all_segment_ids, all_label_ids,all_valid_ids,all_lmask_ids)
# Run prediction for full data
eval_sampler = SequentialSampler(eval_data)
eval_dataloader = DataLoader(eval_data, sampler=eval_sampler, batch_size=cfg.eval_batch_size)
model.eval()
eval_loss, eval_accuracy = 0, 0
nb_eval_steps, nb_eval_examples = 0, 0
y_true = []
y_pred = []
label_map = {i : label for i, label in enumerate(label_list,1)}
for input_ids, input_mask, segment_ids, label_ids,valid_ids,l_mask in tqdm(eval_dataloader, desc="Evaluating"):
input_ids = input_ids.to(device)
input_mask = input_mask.to(device)
segment_ids = segment_ids.to(device)
valid_ids = valid_ids.to(device)
label_ids = label_ids.to(device)
l_mask = l_mask.to(device)
with torch.no_grad():
logits = model(input_ids, segment_ids, input_mask,valid_ids=valid_ids,attention_mask_label=l_mask)
logits = torch.argmax(F.log_softmax(logits,dim=2),dim=2)
logits = logits.detach().cpu().numpy()
label_ids = label_ids.to('cpu').numpy()
input_mask = input_mask.to('cpu').numpy()
for i, label in enumerate(label_ids):
temp_1 = []
temp_2 = []
for j,m in enumerate(label):
if j == 0:
continue
elif label_ids[i][j] == len(label_map):
y_true.append(temp_1)
y_pred.append(temp_2)
break
else:
temp_1.append(label_map[label_ids[i][j]])
temp_2.append(label_map[logits[i][j]])
report = classification_report(y_true, y_pred,digits=4)
logger.info("\n%s", report)
output_eval_file = os.path.join(cfg.output_dir, "eval_results.txt")
with open(output_eval_file, "w") as writer:
logger.info("***** Eval results *****")
logger.info("\n%s", report)
writer.write(report)
输出:

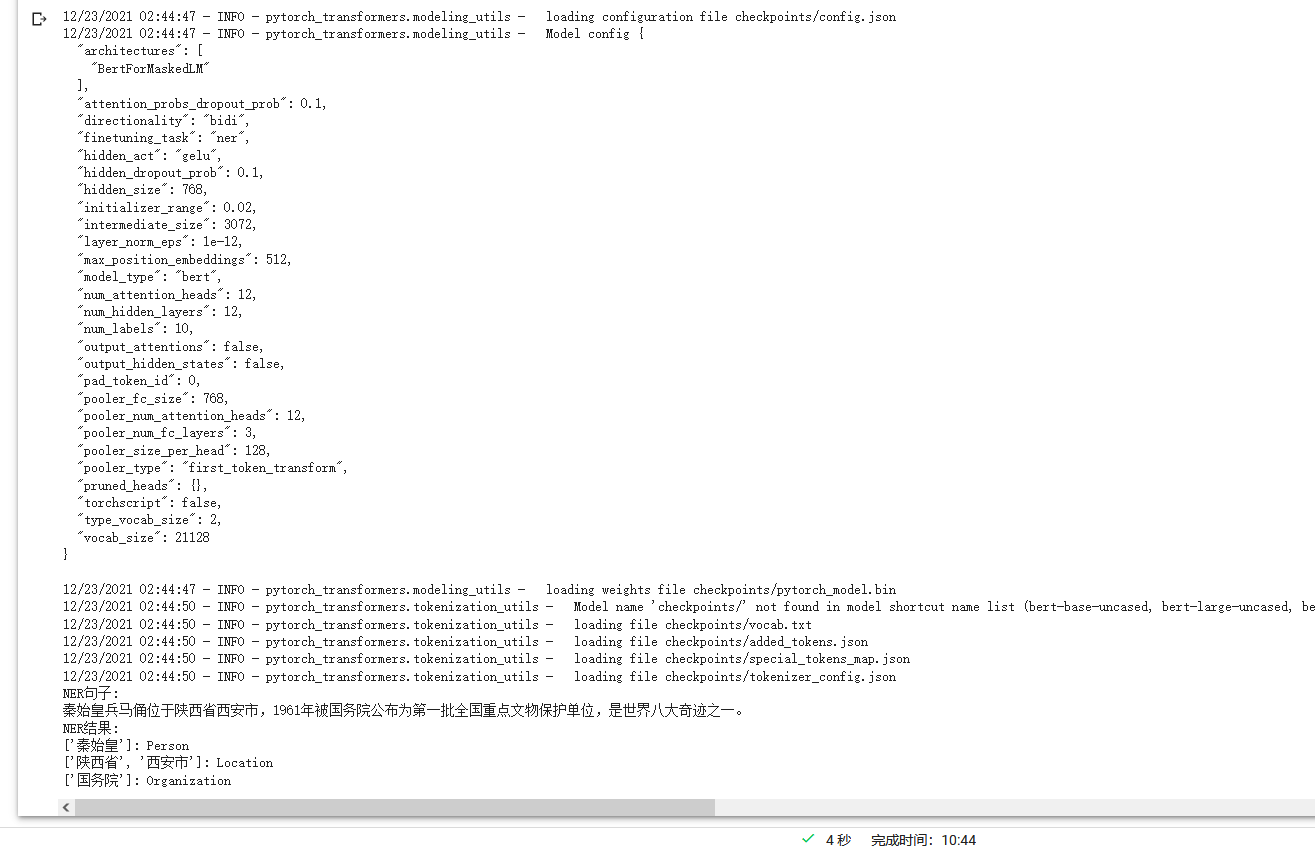
最终训练好的模型效果如下:
model = InferNer("checkpoints/")
text = cfg.text
print("NER句子:")
print(text)
print('NER结果:')
result = model.predict(text)
for k,v in result.items():
if v:
print(v,end=': ')
if k=='PER':
print('Person')
elif k=='LOC':
print('Location')
elif k=='ORG':
print('Organization')
属性抽取AE
常规全监督STANDARD
原理
使用 pretrain_language 模型来提取属性,具体模型流程为:句子经过BERT编码,原句可以获得丰富的语义信息。 得到的结果输入到双向LSTM中,输出结果可以得到句子的关系信息。
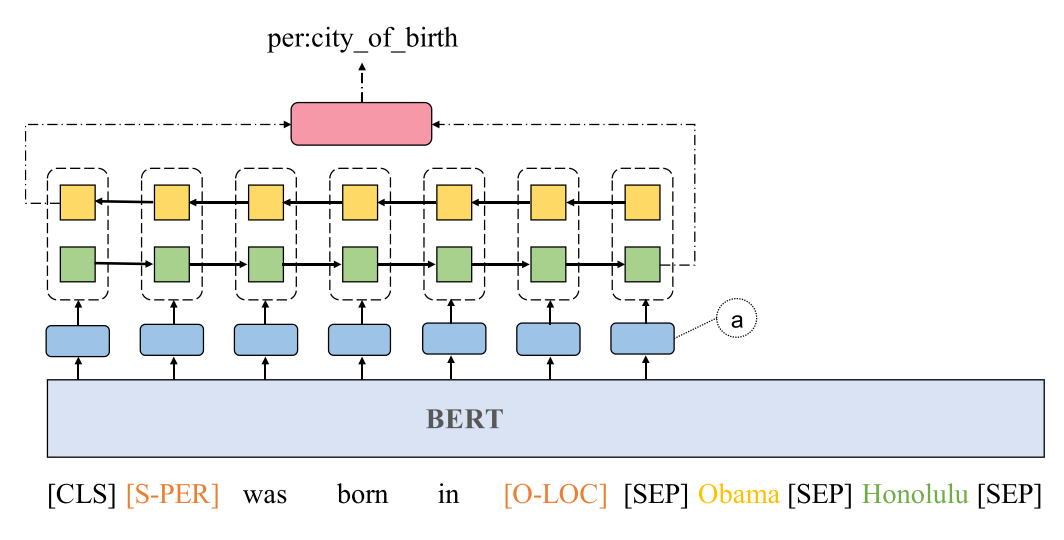
实验
数据集
进入DeepKE/example/ae/standard,下载数据集
wget 120.27.214.45/Data/ae/standard/data.tar.gz
tar -xzvf data.tar.gz
解压后data/origin 文件夹下存放来训练数据。训练文件主要有三个文件。
train.csv:存放训练数据集,包含6个训练三元组,每行代表一个三元组,按句子、属性、实体、实体的偏移量、属性值、属性值的偏移量排序,用,分隔valid.csv:存放验证数据集,包含2个训练三元组,每行代表一个三元组,按句子、属性、实体、实体的偏移量、属性值、属性值的偏移量排序,用,分隔。test.csv:存放测试数据集,包含2个训练三元组,每行代表一个三元组,按句子、属性、实体、实体的偏移量、属性值、属性值的偏移量排序,用,分隔。attribute.csv:存放属性种类,包含3个属性三元组,每行按属性、索引排序并用,分隔。
模型训练
数据集和参数配置可以分别进入data和conf文件夹中修改
设置 conf 中 train_from_saved_model 为上次保存模型的路径即可从上次训练的模型开始训练
python run.py
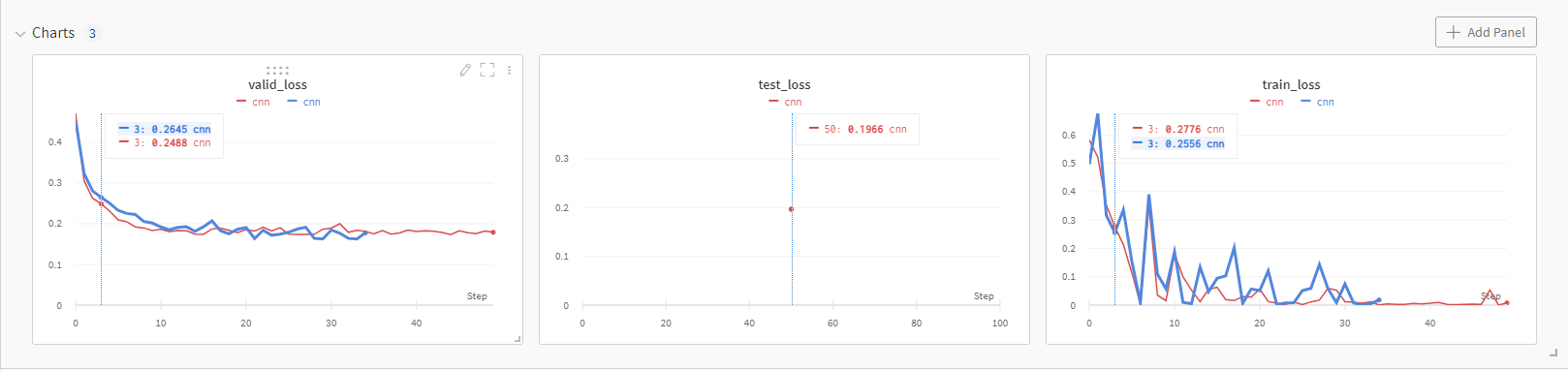
训练结果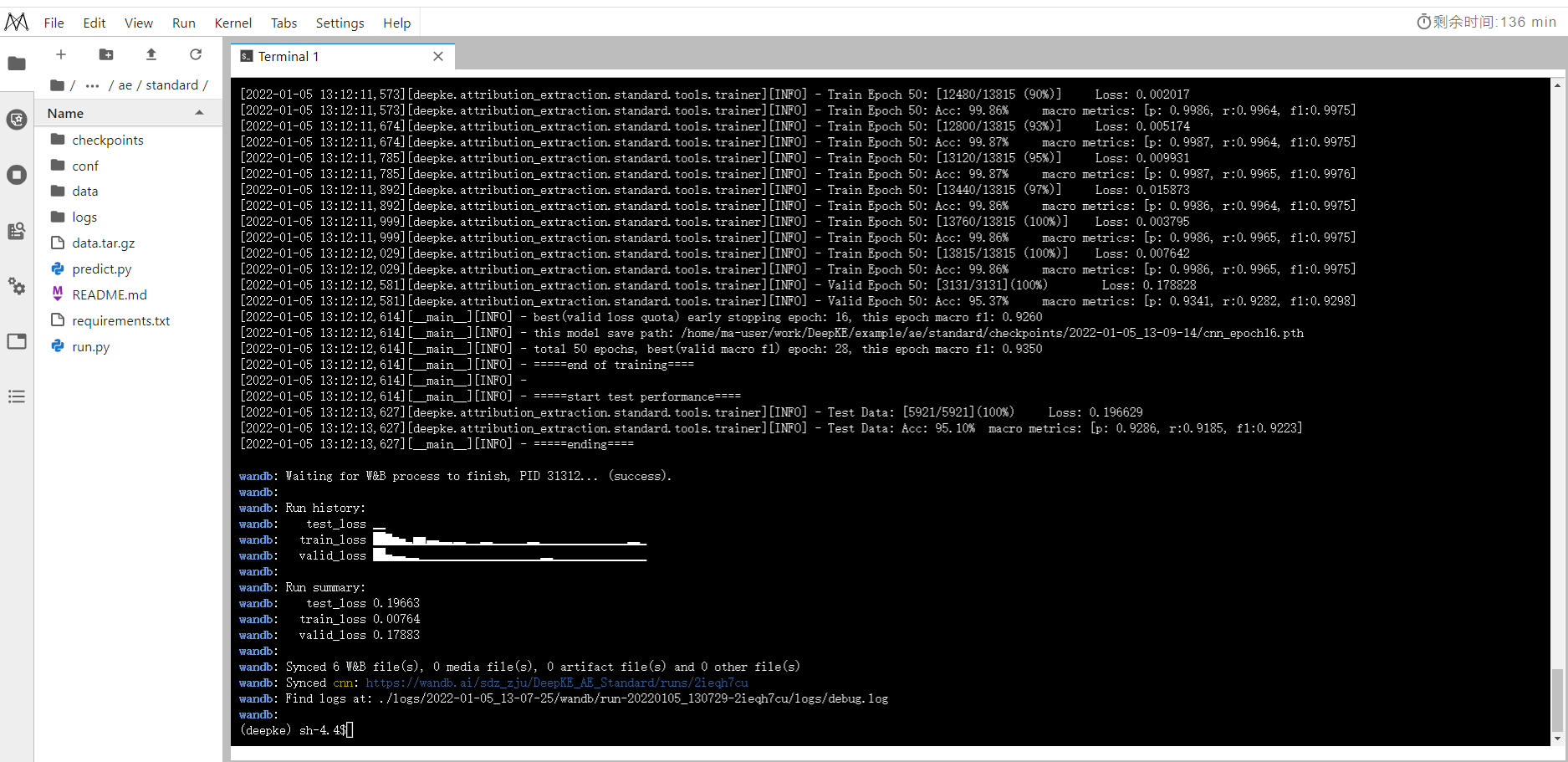
模型预测
修改模型预测配置文件:DeepKE/example/ae/standard/conf/predict.yaml
# 自定义模型存储的路径
fp: '/home/ma-user/work/DeepKE/example/ae/standard/checkpoints/2022-01-05_13-12-12/cnn_epoch50.pth'
python predict.py
预测结果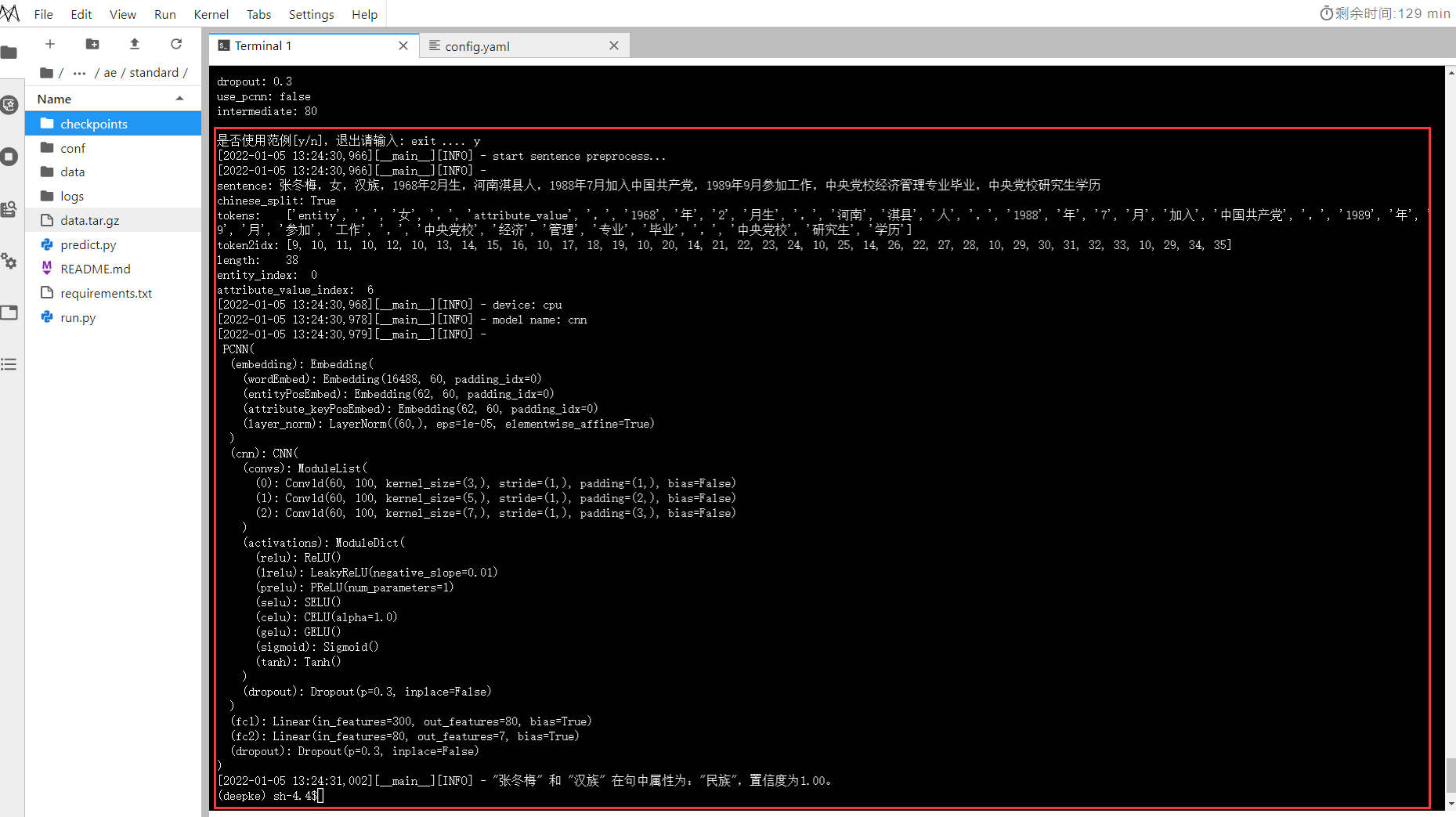
改进的地方
参考论文:Document-level Relation Extraction as Semantic Segmentation
文档级关系抽取的未来畅想:
一、设计文档实体结构相关的预训练。现有的 MLM 预训练目标并不能很好的建模实体及实体间的隐式关联,因此,一个能够显式建模实体及其包含的语义关系的预训练目标可以增强文档的实体的表达能力。目前已经有工作开始尝试基于对比学习设计更好的实体关系预训练模型。
二、减轻关系标签分布不平衡。文档级关系抽取中的关系存在明显的长尾分布,且大量的实体间不存在关系,因此类别分布不平衡在一定程度上影响模型效果。已经有工作针对这一问题提出了动态阈值的方法,然而对于长尾部分的关系仍然缺乏较好的模型进行抽取。
三、引入外部知识。语言模型缺乏对实体知识的认知,先前的工作表明注入实体等事实类型知识可以显著提升知识敏感的任务性能,AAAI2021 上有个工作提出了一个注入 Probase 知识库的关系抽取模型,然而知识库存在稀疏性和噪音,更加高效可靠的知识注入方法仍然值得研究。
四、设计更好的实体交互模型。目前关系抽取中仅考虑实体对之间的一阶交互,缺乏对多个实体对之间的高阶交互建模。尽管基于文档图的模型在一定程度上使得模型得学习了实体与实体之间的交互信息,然而对于实体图中相聚较远的节点,实体之间缺乏足够的信息流通,制约模型的逻辑推理能力。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号