MIT 6.824 Lab4 Sharded KeyValue Service
实验背景与目的
官网:6.824 Lab 4: Sharded Key/Value Service
在Lab2和Lab3,实现了基于单RAFT(单一集群)的多节点间数据一致性、支持增删查改、数据同步和快照保存的KV数据库。但忽视了集群负载问题,随着数据增长到一定程度时,所有的数据请求都集中在leader上,增加集群压力,延长请求响应时。
Lab4的内容就是将数据按照某种方式分开存储到不同的RAFT集群(Group)上,分片(shard)的策略有很多,比如:所有以a开头的键是一个分片,所有以b开头的键是一个分片。保证相应数据请求引流到对应的集群,降低单一集群的压力,提供更为高效、更为健壮的服务。
整体架构如下图:
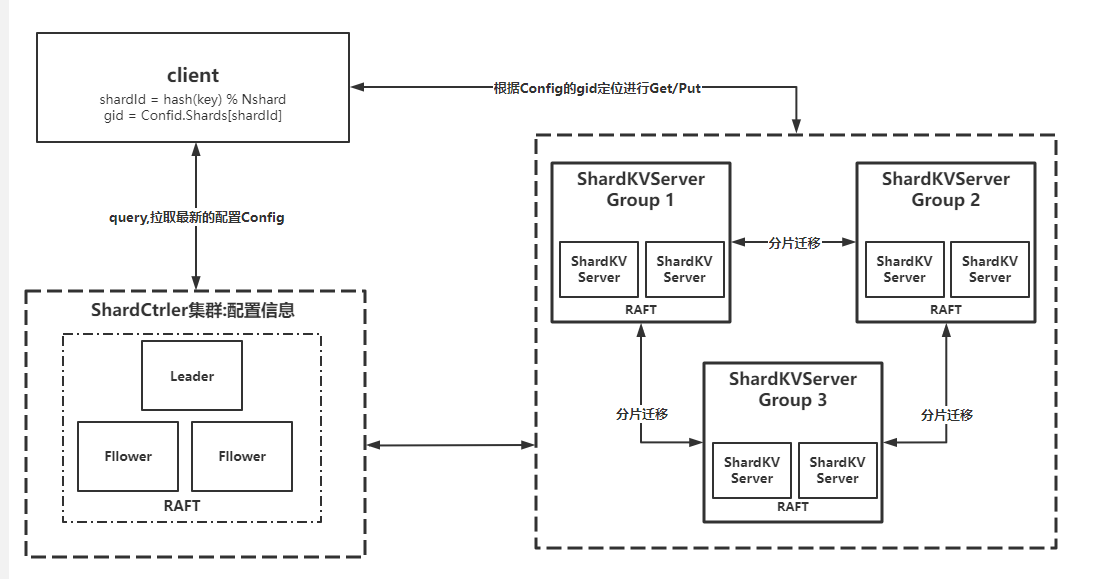
-
具体的
lab4要实现一个支持multi-raft分片 、分片数据动态迁移的线性一致性分布式KV存储服务。 -
shard表示互不相交并且组成完整数据库的每一个数据库子集。group表示server的集合,包含一个或多个server。一个shard只可属于一个group,一个group可包含(管理)多个shard。 -
lab4A实现ShardCtrler服务,作用:提供高可用的集群配置管理服务,实现分片的负载均衡,并尽可能少地移动分片。记录了每组(Group)ShardKVServer的集群信息和每个分片(shard)服务于哪组(Group)ShardKVServer。具体实现通过Raft维护 一个Configs数组,单个config具体内容如下:Num:config number,Num=0表示configuration无效,边界条件。Shards:shard -> gid,分片位置信息,Shards[3]=2,说明分片序号为3的分片负贵的集群是Group2(gid=2)Groups:gid -> servers[],集群成员信息,Group[3]=['server1','server2'],说明gid = 3的集群Group3包含两台名称为server1 & server2的机器
-
lab4B实现ShardKVServer服务,ShardKVServer则需要实现所有分片的读写任务,相比于MIT 6.824 Lab3 RaftKV的提供基础的读写服务,还需要功能和难点为配置更新,分片数据迁移,分片数据清理,空日志检测。
Lab 4A
介绍
lab4系列除了构建一个 键值存储系统,还需要将系统按键 分片(shard) 或对一组副本进行分区;分片的策略有很多,比如:所有以 “a” 开头的键是一个分片,所有以 “b” 开头的键是一个分片,等等
为什么需要分片?从性能考虑,每个副本只处理一部分分片的 put 和 get,并且这些副本之间是支持并行操作的;因此,系统的总吞吐量和副本的数量成比例增加
shard kv 系统组成
分片键值对存储系统将由两个组件组成;首先是一组副本,每个副本负责处理分片的一部分。一个副本由使用 raft 副本组分片的服务器组成。
第二个组件是 分片控制器,分片控制器决定哪个副本组对应服务哪个分片,即管理配置信息。配置随时间变化,客户端咨询 分片控制器,寻找对应 key 的副本组,而 副本组会请求控制器,以找到需要装载的分片。分片控制器是单例,采用 raft 实现容错。
shard kv 系统功能
分片存储系统必须能在多个副本组之间转移分片,需要支持该功能的原因是:一某些组的负载可能会比其他组重,移动分片来实现负载均衡;二是某些组可能会加入或退出系统,又或者增加新的组以增加分片容量,或将已有的副本组下线修复实验挑战
处理重新配置功能,即将分片重新分配给副本组。在一个副本组中,所有组成员必须就客户端的请求在进行重新配置时达成一致。如,请求在重配置的同时到达,重配置导致副本组不再对持有该键的分片负责。所以组中的所有副本服务器必须就请求在重配置前还是后达成一致,如果在重配置前,则请求生效,分片的新所有者需要看到生效效果。否则,请求无法生效,客户端必须在新所有者处重新请求。推荐的方法是,让每个副本组使用
raft,不仅记录请求的序列,还记录重配置的序列;需要确保在任何时间最多只有一个副本组为所有分片提供服务。重配置还涉及到副本组之间的交互,如在配置编号10中,G1组负责分片S1,配置11中,G2组负责分配S1。在10到11 的配置变换过程中,G1和G2需要使用RPC将分片S1内容做迁移。
只有RPC可以用于客户端和服务器之间的交互。服务器的不同实例不允许共享Go变量或文件,逻辑上是物理分离的
重配置将分片分配给副本组,重配置不是 raft 集群成员变更,我们不需要实现 raft 集群成员变更
实验提示
- 从一个简化的
kvraft服务器副本开始- 实现对分片控制器的rpc的重复客户端请求检测。
shardctrler的测试没有测试这个,但是shardkv测试稍后会在一个不可靠的网络上使用shardctrler;如果shardctrler没有过滤掉重复的rpc,那么将不能通过
对于golang的map:map的迭代顺序是不确定的,其次,且map是引用对象,需要用深拷贝做复制.go test -race很好用
lab4A实现ShardCtrler服务,作用:提供高可用的集群配置管理服务,记录了每组(Group)ShardKVServer的集群信息和每个分片(shard)服务于哪组(Group)ShardKVServer。具体实现通过Raft维护 一个Configs数组,具体内容如下:
Num:config numberShards:shard -> gid,分片位置信息,Shards[3]=2,说明分片序号为3的分片负责的集群是Group2(gid=2)Groups:gid -> servers[],集群成员信息,Group[3]=['server1','server2'],说明gid = 3的集群Group3包含两台名称为server1 & server2的机器
代码实现基本与Lab3 类似,可以直接照抄复制MIT 6.824 Lab3 RaftKV,且不需要实现快照服务,具体根据实现 Join, Leave, Move, Query 服务。
Query: 查询最新的Config信息。Move将数据库子集Shard分配给GID的Group。Join: 新加入的Group信息,要求在每一个group平衡分布shard,即任意两个group之间的shard数目相差不能为1,具体实现每一次找出含有shard数目最多的和最少的,最多的给最少的一个,循环直到满足条件为止。坑为:GID = 0是无效配置,一开始所有分片分配给GID=0,需要优先分配;map的迭代时无序的,不确定顺序的话,同一个命令在不同节点上计算出来的新配置不一致,按sort排序之后遍历即可。且map是引用对象,需要用深拷贝做复制。Leave: 移除Group,同样别忘记实现均衡,将移除的Group的shard每一次分配给数目最小的Group就行,如果全部删除,别忘记将shard置为无效的0。
其他代码与MIT 6.824 Lab3 RaftKV完全一致,关键代码实现:
func (mcf *MemoryConfig) Query(num int) (Config, Err) {
// 如果该数字为 -1 或大于已知的最大配置数字,则 shardctrler 应回复最新配置。
if num < 0 || num >= len(mcf.Configs) {
return mcf.Configs[len(mcf.Configs)-1], OK
}
return mcf.Configs[num], OK
}
func (mcf *MemoryConfig) Move(shard int, gid int) Err {
lastConfig := mcf.Configs[len(mcf.Configs)-1]
newConfig := Config{len(mcf.Configs), lastConfig.Shards, deepCopy(lastConfig.Groups)}
newConfig.Shards[shard] = gid
mcf.Configs = append(mcf.Configs, newConfig)
return OK
}
func (mcf *MemoryConfig) Join(groups map[int][]string) Err {
lastConfig := mcf.Configs[len(mcf.Configs)-1]
newConfig := Config{len(mcf.Configs), lastConfig.Shards, deepCopy(lastConfig.Groups)}
for gid, servers := range groups {
if _, ok := newConfig.Groups[gid]; !ok {
newServers := make([]string, len(servers))
copy(newServers, servers)
newConfig.Groups[gid] = newServers
}
}
// balance
g2s := groupToShards(newConfig)
for {
s, t := getMaxNumShardByGid(g2s), getMinNumShardByGid(g2s)
if s != 0 && len(g2s[s])-len(g2s[t]) <= 1 {
break
}
g2s[t] = append(g2s[t], g2s[s][0])
g2s[s] = g2s[s][1:]
}
var newShards [NShards]int
for gid, shards := range g2s {
for _, shardId := range shards {
newShards[shardId] = gid
}
}
newConfig.Shards = newShards
mcf.Configs = append(mcf.Configs, newConfig)
return OK
}
func (mcf *MemoryConfig) Leave(gids []int) Err {
lastConfig := mcf.Configs[len(mcf.Configs)-1]
newConfig := Config{len(mcf.Configs), lastConfig.Shards, deepCopy(lastConfig.Groups)}
g2s := groupToShards(newConfig)
noUsedShards := make([]int, 0)
for _, gid := range gids {
if _, ok := newConfig.Groups[gid]; ok {
delete(newConfig.Groups, gid)
}
if shards, ok := g2s[gid]; ok {
noUsedShards = append(noUsedShards, shards...)
delete(g2s, gid)
}
}
var newShards [NShards]int
if len(newConfig.Groups) > 0 {
for _, shardId := range noUsedShards {
t := getMinNumShardByGid(g2s)
g2s[t] = append(g2s[t], shardId)
}
for gid, shards := range g2s {
for _, shardId := range shards {
newShards[shardId] = gid
}
}
}
newConfig.Shards = newShards
mcf.Configs = append(mcf.Configs, newConfig)
return OK
}
func getMinNumShardByGid(g2s map[int][]int) int {
// 不固定顺序的话,可能会导致两次的config不同
gids := make([]int, 0)
for key := range g2s {
gids = append(gids, key)
}
sort.Ints(gids)
min, index := NShards+1, -1
for _, gid := range gids {
if gid != 0 && len(g2s[gid]) < min {
min = len(g2s[gid])
index = gid
}
}
return index
}
func getMaxNumShardByGid(g2s map[int][]int) int {
// GID = 0 是无效配置,一开始所有分片分配给GID=0
if shards, ok := g2s[0]; ok && len(shards) > 0 {
return 0
}
gids := make([]int, 0)
for key := range g2s {
gids = append(gids, key)
}
sort.Ints(gids)
max, index := -1, -1
for _, gid := range gids {
if len(g2s[gid]) > max {
max = len(g2s[gid])
index = gid
}
}
return index
}
func groupToShards(config Config) map[int][]int {
g2s := make(map[int][]int)
for gid := range config.Groups {
g2s[gid] = make([]int, 0)
}
for shardId, gid := range config.Shards {
g2s[gid] = append(g2s[gid], shardId)
}
return g2s
}
func deepCopy(groups map[int][]string) map[int][]string {
newGroups := make(map[int][]string)
for gid, servers := range groups {
newServers := make([]string, len(servers))
copy(newServers, servers)
newGroups[gid] = newServers
}
return newGroups
}
Lab 4B
实验提示
服务器不需要调用分片控制器的
Join(),tester才会去调用;服务器将需要定期轮询 shardctrler 以监听新的配置。预期大约每100毫秒轮询一次;可以更频繁,但过少可能会导致 bug。
服务器需要互相发送rpc,以便在配置更改期间传输分片。shardctrler的Config结构包含服务器名,一个 Server 需要一个labrpc.ClientEnd,以便发送RPC。使用make_end()函数传给StartServer()函数将服务器名转换为ClientEnd。shardkv /client.go需要实现这些逻辑。
在server.go中添加代码去周期性从 shardctrler 拉取最新的配置,并且当请求分片不属于自身时,拒绝请求
当被请求到错误分片时,需要返回ErrWrongGroup给客户端,并确保Get, Put, Append在面临并发重配置时能正确作出决定
重配置需要按流程执行唯一一次
labgob 的提示错误不能忽视,它可能导致实验不过
分片重分配的请求也需要做重复请求检测
若客户端收到ErrWrongGroup,是否更改请求序列号?若服务器执行请求时返回ErrWrongGroup,是否更新客户端信息?
当服务器转移到新配置后,它可以继续存储它不再负责的分片(生产环境中这是不允许的),但这个可以简化实现
当 G1 在配置变更时需要来自 G2 的分片数据,G2 处理日志条目的哪个时间点将分片发送给 G1 是最好的?
你可以在整个 rpc 请求或回复中发送整个 map,这可以简化分片传输
map 是引用类型,所以在发送 map 的时候,建议先拷贝一次,避免 data race(在 labrpc 框架下,接收 map 时也需要拷贝)
在配置更改期间,一对组可能需要互相传送分片,这可能会发生死锁
challenge
如果想达到生产环境系统级别,如下两个挑战是需要实现的
challenge1:Garbage collection of state
当一个副本组失去一个分片的所有权时,副本组需要删除该分片数据。但这给迁移带来一些问题,考虑两个组G1 和 G2,并且新配置C 将分片从 G1 移动到 G2,若 G1 在转换配置到C时删除了数据库中的分片,当G2 转换到C时,如何获取 G1 的数据实验要求
使每个副本组保留旧分片的时长不再是无限时长,即使副本组(如上面的G1)中的所有服务器崩溃并恢复正常,解决方案也必须工作。如果您通过TestChallenge1Delete,您就完成了这个挑战。解决方案
分片迁移成功之后,立马进行分片GC了,GC完毕后再进入到配置更新阶段。chanllenge2:Client requests during configuration changes
配置更改期间最简单的方式是禁止所有客户端操作直到转换完成,虽然简单但是不满足于生产环境要求,这将导致客户端长时间停滞,最好可以继续为不受当前配置更改的分片提供服务上述优化还能更好,若 G3 在过渡到配置C时,需要来自G1 的分片S1 和 G2 的分片S2。希望 G3 能在收到其中一个分片后可以立即开始接收针对该分片的请求。如G1宕机了,G3在收到G2的分片数据后,可以立即为 S2 分片提供服务,而不需要等待 C 配置转换完全完成
实验要求
修改您的解决方案,以便在配置更改期间继续执行不受影响的分片中的 key 的客户端操作。当您通过TestChallenge2Unaffected测试时,您已经完成了这个挑战。修改您的解决方案,在配置转换进行中,副本组也可以立即开始提供分片服务。当您通过
TestChallenge2Partial测试时,您已经完成了这个挑战。解决方案
分片迁移以group为单位,这样即使一个group挂了,也不会影响到另一个group中的分片迁移。
本实验设计方案主要参考:https://github.com/OneSizeFitsQuorum/MIT6.824-2021/blob/master/docs/lab4.md(这个大佬真的顶,设计方案优秀,代码逻辑清晰,膜拜。)
上面的实验ShardCtrler 集群组实现了配置更新,分片均匀分配等任务,ShardKVServer则需要承载所有分片的读写任务,相比于MIT 6.824 Lab3 RaftKV的提供基础的读写服务,还需要功能为配置更新,分片数据迁移,分片数据清理,空日志检测。
客户端Clerk
主要实现为请求逻辑:
- 使用
key2shard()去找到一个key对应哪个分片Shard; - 根据
Shard从当前配置config中获取的gid; - 根据
gid从当前配置config中获取group信息; - 在
group循环查找leaderId,直到返回请求成功、ErrWrongGroup或整个 group 都遍历请求过; Query最新的配置,回到步骤1循环重复;
func MakeClerk(ctrlers []*labrpc.ClientEnd, makeEnd func(string) *labrpc.ClientEnd) *Clerk {
ck := &Clerk{
sm: shardctrler.MakeClerk(ctrlers),
makeEnd: makeEnd,
leaderIds: make(map[int]int),
clientId: nrand(),
commandId: 0,
}
ck.config = ck.sm.Query(-1)
return ck
}
func (ck *Clerk) Get(key string) string {
return ck.Command(&CommandRequest{Key: key, Op: OpGet})
}
func (ck *Clerk) Put(key string, value string) {
ck.Command(&CommandRequest{Key: key, Value: value, Op: OpPut})
}
func (ck *Clerk) Append(key string, value string) {
ck.Command(&CommandRequest{Key: key, Value: value, Op: OpAppend})
}
func (ck *Clerk) Command(request *CommandRequest) string {
request.ClientId, request.CommandId = ck.clientId, ck.commandId
for {
shard := key2shard(request.Key)
gid := ck.config.Shards[shard]
if servers, ok := ck.config.Groups[gid]; ok {
if _, ok = ck.leaderIds[gid]; !ok {
ck.leaderIds[gid] = 0
}
oldLeaderId := ck.leaderIds[gid]
newLeaderId := oldLeaderId
for {
var response CommandResponse
ok := ck.makeEnd(servers[newLeaderId]).Call("ShardKV.Command", request, &response)
if ok && (response.Err == OK || response.Err == ErrNoKey) {
ck.commandId++
return response.Value
} else if ok && response.Err == ErrWrongGroup {
break
} else {
newLeaderId = (newLeaderId + 1) % len(servers)
if newLeaderId == oldLeaderId {
break
}
continue
}
}
}
time.Sleep(100 * time.Millisecond)
// 获取最新配置
ck.config = ck.sm.Query(-1)
}
}
服务端Server
首先明确整体系统的运行方式:
- 客户端首先和
ShardCtrler交互,获取最新的配置,根据最新配置找到对应key的shard,请求该shard的group。 - 服务端
ShardKVServer会创建多个raft组来承载所有分片的读写任务。 - 服务端
ShardKVServer需要定期和ShardCtrler交互,保证更新到最新配置(monitor)。 - 服务端
ShardKVServer需要根据最新配置完成配置更新,分片数据迁移,分片数据清理,空日志检测等功能。
结构
首先ShardKVServer 给出结构体,相比于MIT 6.824 Lab3 RaftKV的多了currentConfig和lastConfig数据,这样其他协程便能够通过其计算需要需要向谁拉取分片或者需要让谁去删分片。
启动了五个协程:apply 协程,配置更新协程,数据迁移协程,数据清理协程,空日志检测协程来实现功能。四个协程都需要 leader 来执行,因此抽象出了一个简单地周期执行函数 Monitor。
type ShardKV struct {
mu sync.RWMutex
dead int32
rf *raft.Raft
applyCh chan raft.ApplyMsg
makeEnd func(string) *labrpc.ClientEnd
gid int
sc *shardctrler.Clerk
maxRaftState int // snapshot if log grows this big
lastApplied int // record the lastApplied to prevent stateMachine from rollback
lastConfig shardctrler.Config
currentConfig shardctrler.Config
stateMachines map[int]*Shard // 服务器数据存储(key,value)
lastOperations map[int64]OperationContext // 客户端id最后的命令id和回复内容 (clientId,{最后的commdId,最后的LastReply})
notifyChans map[int]chan *CommandResponse // Leader回复给客户端的响应(日志Index, CommandReply)
}
func StartServer(servers []*labrpc.ClientEnd, me int, persister *raft.Persister, maxRaftState int, gid int, ctrlers []*labrpc.ClientEnd, makeEnd func(string) *labrpc.ClientEnd) *ShardKV {
// call labgob.Register on structures you want
// Go's RPC library to marshall/unmarshall.
labgob.Register(Command{})
labgob.Register(CommandRequest{})
labgob.Register(shardctrler.Config{})
labgob.Register(ShardOperationResponse{})
labgob.Register(ShardOperationRequest{})
applyCh := make(chan raft.ApplyMsg)
kv := &ShardKV{
dead: 0,
rf: raft.Make(servers, me, persister, applyCh),
applyCh: applyCh,
makeEnd: makeEnd,
gid: gid,
sc: shardctrler.MakeClerk(ctrlers),
lastApplied: 0,
maxRaftState: maxRaftState,
currentConfig: shardctrler.DefaultConfig(),
lastConfig: shardctrler.DefaultConfig(),
stateMachines: make(map[int]*Shard),
lastOperations: make(map[int64]OperationContext),
notifyChans: make(map[int]chan *CommandResponse),
}
kv.restoreSnapshot(persister.ReadSnapshot())
// 将 committed logs 应用到 stateMachine
go kv.applier()
// 开启协程获取最新配置
go kv.Monitor(kv.configureAction, ConfigureMonitorTimeout)
// 开启协程拉取相关分片
go kv.Monitor(kv.migrationAction, MigrationMonitorTimeout)
// 开启协程 删除远程组中无用的分片
go kv.Monitor(kv.gcAction, GCMonitorTimeout)
// 开启协程在当前term中附加空条目来提高 commitIndex 以避免活锁
go kv.Monitor(kv.checkEntryInCurrentTermAction, EmptyEntryDetectorTimeout)
DPrintf("{Node %v}{Group %v} has started", kv.rf.Me(), kv.gid)
return kv
}
// applier协程:将提交的日志应用到 stateMachine,并实现快照
func (kv *ShardKV) applier() {
for kv.killed() == false {
select {
case message := <-kv.applyCh:
if message.CommandValid {
kv.mu.Lock()
if message.CommandIndex <= kv.lastApplied {
kv.mu.Unlock()
continue
}
kv.lastApplied = message.CommandIndex
var response *CommandResponse
command := message.Command.(Command)
switch command.Op {
case Operation:
operation := command.Data.(CommandRequest)
response = kv.applyOperation(&message, &operation)
case Configuration:
nextConfig := command.Data.(shardctrler.Config)
response = kv.applyConfiguration(&nextConfig)
case InsertShards:
shardsInfo := command.Data.(ShardOperationResponse)
response = kv.applyInsertShards(&shardsInfo)
case DeleteShards:
shardsInfo := command.Data.(ShardOperationRequest)
response = kv.applyDeleteShards(&shardsInfo)
case EmptyEntry:
response = kv.applyEmptyEntry()
}
if currentTerm, isLeader := kv.rf.GetState(); isLeader && message.CommandTerm == currentTerm {
ch := kv.getNotifyChan(message.CommandIndex)
ch <- response
}
needSnapshot := kv.needSnapshot()
if needSnapshot {
kv.takeSnapshot(message.CommandIndex)
}
kv.mu.Unlock()
} else if message.SnapshotValid {
kv.mu.Lock()
if kv.rf.CondInstallSnapshot(message.SnapshotTerm, message.SnapshotIndex, message.Snapshot) {
kv.restoreSnapshot(message.Snapshot)
kv.lastApplied = message.SnapshotIndex
}
kv.mu.Unlock()
} else {
panic(fmt.Sprintf("unexpected Message %v", message))
}
}
}
}
相比于MIT 6.824 Lab3 RaftKV需要维护分片Shard的状态变量来完成该实验,原因如下:
- 这样可以防止分片
Shard中间状态被覆盖,从而导致任务被丢弃。只有所有分片Shard的状态都为默认状态才能拉取最新配置。 - 实验
challenge2限制,challenge2不仅要求apply协程不被阻塞,还要求配置的更新和分片的状态变化彼此独立。即需要不同raft组所属的分片数据独立起来,分别提交多条raft日志来维护状态,因此需要维护状态变量。 - 必须使用单独的协程异步根据分片的状态来进行分片的迁移和清理等任务。如果不采用上述方案,
apply协程更新配置的时候由leader异步启动对应的协程,让其独立的根据raft组为粒度拉取数据?让设想这样一个场景:leader apply 了新配置后便挂了,然后此时 follower 也 apply 了该配置但并不会启动该任务,在该raft组的新leader选出来后,该任务已经无法被执行了。所有apply配置的时候只应该更新shard的状态。
每个分片共有 4 种状态:
Serving:分片的默认状态,如果当前raft组在当前config下负责管理此分片,则该分片可以提供读写服务,否则该分片暂不可以提供读写服务,但不会阻塞配置更新协程拉取新配置。Pulling:表示当前raft组在当前config下负责管理此分片,暂不可以提供读写服务,需要当前raft组从上一个配置该分片所属raft组拉数据过来之后才可以提供读写服务,系统会有一个分片迁移协程检测所有分片的Pulling状态,接着以raft组为单位去对应raft组拉取数据,接着尝试重放该分片的所有数据到本地并将分片状态置为Serving,以继续提供服务。BePulling:表示当前raft组在当前config下不负责管理此分片,不可以提供读写服务,但当前raft组在上一个config时复制管理此分片,因此当前config下负责管理此分片的raft组拉取完数据后会向本raft组发送分片清理的rpc,接着本raft组将数据清空并重置为serving状态即可。GCing:表示当前raft组在当前config下负责管理此分片,可以提供读写服务,但需要清理掉上一个配置该分片所属raft组的数据。系统会有一个分片清理协程检测所有分片的GCing状态,接着以raft组为单位去对应raft组删除数据,一旦远程raft组删除数据成功,则本地会尝试将相关分片的状态置为Serving。
type ShardStatus uint8
const (
Serving ShardStatus = iota
Pulling
BePulling
GCing
)
type Shard struct {
KV map[string]string
Status ShardStatus
}
func NewShard() *Shard {
return &Shard{make(map[string]string), Serving}
}
func (shard *Shard) Get(key string) (string, Err) {
if value, ok := shard.KV[key]; ok {
return value, OK
}
return "", ErrNoKey
}
func (shard *Shard) Put(key, value string) Err {
shard.KV[key] = value
return OK
}
func (shard *Shard) Append(key, value string) Err {
shard.KV[key] += value
return OK
}
func (shard *Shard) deepCopy() map[string]string {
newShard := make(map[string]string)
for k, v := range shard.KV {
newShard[k] = v
}
return newShard
}
日志类型
在 lab3 中,客户端的请求会被包装成一个 Op 传给 Raft 层,则在 lab4 中,不难想到,Servers 之间的交互,也可以看做是包装成 Op 传给 Raft 层;定义了五种类型的日志:
-
Operation:客户端传来的读写操作日志,有Put,Get,Append等请求。 -
Configuration:配置更新日志,包含一个配置。 -
InsertShards:分片更新日志,包含至少一个分片的数据和配置版本。 -
DeleteShards:分片删除日志,包含至少一个分片的 id 和配置版本。 -
EmptyEntry:空日志,Data为空,使得状态机达到最新。
type Command struct {
Op CommandType
Data interface{}
}
func (command Command) String() string {
return fmt.Sprintf("{Type:%v,Data:%v}", command.Op, command.Data)
}
func NewOperationCommand(request *CommandRequest) Command {
return Command{Operation, *request}
}
func NewConfigurationCommand(config *shardctrler.Config) Command {
return Command{Configuration, *config}
}
func NewInsertShardsCommand(response *ShardOperationResponse) Command {
return Command{InsertShards, *response}
}
func NewDeleteShardsCommand(request *ShardOperationRequest) Command {
return Command{DeleteShards, *request}
}
func NewEmptyEntryCommand() Command {
return Command{EmptyEntry, nil}
}
type CommandType uint8
const (
Operation CommandType = iota
Configuration
InsertShards
DeleteShards
EmptyEntry
)
读写服务
读写操作的基本逻辑相比于MIT 6.824 Lab3 RaftKV基本一致,需要增加分片状态判断。根据上述定义,分片的状态为 Serving 或 GCing,当前 raft 组在当前 config 下负责管理此分片,本 raft 组才可以为该分片提供读写服务,否则返回 ErrWrongGroup 让客户端重新拉取最新的 config 并重试即可。
canServe 的判断需要在向 raft 提交前和 apply 时都检测一遍以保证正确性并尽可能提升性能。
// 检查该raft group 目前是否可以服务该shard
func (kv *ShardKV) canServe(shardID int) bool {
return kv.currentConfig.Shards[shardID] == kv.gid && (kv.stateMachines[shardID].Status == Serving || kv.stateMachines[shardID].Status == GCing)
}
func (kv *ShardKV) Command(request *CommandRequest, response *CommandResponse) {
kv.mu.RLock()
if request.Op != OpGet && kv.isDuplicateRequest(request.ClientId, request.CommandId) {
lastResponse := kv.lastOperations[request.ClientId].LastResponse
response.Value, response.Err = lastResponse.Value, lastResponse.Err
kv.mu.RUnlock()
return
}
// 如果当前分片无法提供服务,则返回 ErrWrongGroup 让客户端获取最新配置,
if !kv.canServe(key2shard(request.Key)) {
response.Err = ErrWrongGroup
kv.mu.RUnlock()
return
}
kv.mu.RUnlock()
kv.Execute(NewOperationCommand(request), response)
}
func (kv *ShardKV) Execute(command Command, response *CommandResponse) {
// 不持有锁以提高吞吐量
// 当 KVServer 持有锁进行快照时,底层 raft 仍然可以提交 raft 日志
index, _, isLeader := kv.rf.Start(command)
if !isLeader {
response.Err = ErrWrongLeader
return
}
//defer DPrintf("{Node %v}{Group %v} processes Command %v with CommandResponse %v", kv.rf.Me(), kv.gid, command, response)
kv.mu.Lock()
ch := kv.getNotifyChan(index)
kv.mu.Unlock()
select {
case result := <-ch:
response.Value, response.Err = result.Value, result.Err
case <-time.After(ExecuteTimeout):
response.Err = ErrTimeout
}
// 释放 notifyChan 以减少内存占用
// 异步为了提高吞吐量,这里不需要阻塞客户端请求
go func() {
kv.mu.Lock()
kv.removeOutdatedNotifyChan(index)
kv.mu.Unlock()
}()
}
func (kv *ShardKV) applyOperation(message *raft.ApplyMsg, operation *CommandRequest) *CommandResponse {
var response *CommandResponse
shardID := key2shard(operation.Key)
if kv.canServe(shardID) {
if operation.Op != OpGet && kv.isDuplicateRequest(operation.ClientId, operation.CommandId) {
DPrintf("{Node %v}{Group %v} doesn't apply duplicated message %v to stateMachine because maxAppliedCommandId is %v for client %v", kv.rf.Me(), kv.gid, message, kv.lastOperations[operation.ClientId], operation.ClientId)
return kv.lastOperations[operation.ClientId].LastResponse
} else {
response = kv.applyLogToStateMachines(operation, shardID)
if operation.Op != OpGet {
kv.lastOperations[operation.ClientId] = OperationContext{operation.CommandId, response}
}
return response
}
}
return &CommandResponse{ErrWrongGroup, ""}
}
接下来就只能瞻仰大佬的思路,目前的想法是先照着大佬实现pull方案实现,且网上大部分方案是pull,但我感觉push方案稍微优异点,因为push模式可以在发送方在收到接收方应用成功reply的时候就,发送方可以直接进行GC,等我按照大佬思路实现完pull方案,汲取到经验之后,就实现push方案。
配置更新
配置更新协程负责定时检测所有分片的状态,一旦存在至少一个分片的状态不为默认状态,则预示其他协程仍然还没有完成任务,那么此时需要阻塞新配置的拉取和提交。
在 apply 配置更新日志时需要保证幂等性:
- 不同版本的配置更新日志:
apply时仅可逐步递增的去更新配置,否则返回失败。 - 相同版本的配置更新日志:由于配置更新日志仅由配置更新协程提交,而配置更新协程只有检测到比本地更大地配置时才会提交配置更新日志,所以该情形不会出现。
func (kv *ShardKV) configureAction() {
canPerformNextConfig := true
kv.mu.RLock()
for _, shard := range kv.stateMachines {
if shard.Status != Serving {
canPerformNextConfig = false
DPrintf("{Node %v}{Group %v} will not try to fetch latest configuration because shards status are %v when currentConfig is %v", kv.rf.Me(), kv.gid, kv.getShardStatus(), kv.currentConfig)
break
}
}
currentConfigNum := kv.currentConfig.Num
kv.mu.RUnlock()
if canPerformNextConfig {
nextConfig := kv.sc.Query(currentConfigNum + 1)
if nextConfig.Num == currentConfigNum+1 {
DPrintf("{Node %v}{Group %v} fetches latest configuration %v when currentConfigNum is %v", kv.rf.Me(), kv.gid, nextConfig, currentConfigNum)
kv.Execute(NewConfigurationCommand(&nextConfig), &CommandResponse{})
}
}
}
func (kv *ShardKV) applyConfiguration(nextConfig *shardctrler.Config) *CommandResponse {
if nextConfig.Num == kv.currentConfig.Num+1 {
DPrintf("{Node %v}{Group %v} updates currentConfig from %v to %v", kv.rf.Me(), kv.gid, kv.currentConfig, nextConfig)
kv.updateShardStatus(nextConfig)
kv.lastConfig = kv.currentConfig
kv.currentConfig = *nextConfig
return &CommandResponse{OK, ""}
}
DPrintf("{Node %v}{Group %v} rejects outdated config %v when currentConfig is %v", kv.rf.Me(), kv.gid, nextConfig, kv.currentConfig)
return &CommandResponse{ErrOutDated, ""}
}
分片迁移
分片迁移协程负责定时检测分片的 Pulling 状态,利用 lastConfig 计算出对应 raft 组的 gid 和要拉取的分片,然后并行地去拉取数据。
注意这里使用了 waitGroup 来保证所有独立地任务完成后才会进行下一次任务。此外 wg.Wait() 一定要在释放读锁之后,否则无法满足 challenge2 的要求。
在拉取分片的 handler 中,首先仅可由 leader 处理该请求,其次如果发现请求中的配置版本大于本地的版本,那说明请求拉取的是未来的数据,则返回 ErrNotReady 让其稍后重试,否则将分片数据和去重表都深度拷贝到 response 即可。
在 apply 分片更新日志时需要保证幂等性:
- 不同版本的配置更新日志:仅可执行与当前配置版本相同地分片更新日志,否则返回 ErrOutDated。
- 相同版本的配置更新日志:仅在对应分片状态为
Pulling时为第一次应用,此时覆盖状态机即可并修改状态为GCing,以让分片清理协程检测到GCing状态并尝试删除远端的分片。否则说明已经应用过,直接break即可。
func (kv *ShardKV) migrationAction() {
kv.mu.RLock()
gid2shardIDs := kv.getShardIDsByStatus(Pulling)
var wg sync.WaitGroup
for gid, shardIDs := range gid2shardIDs {
DPrintf("{Node %v}{Group %v} starts a PullTask to get shards %v from group %v when config is %v", kv.rf.Me(), kv.gid, shardIDs, gid, kv.currentConfig)
wg.Add(1)
go func(servers []string, configNum int, shardIDs []int) {
defer wg.Done()
pullTaskRequest := ShardOperationRequest{configNum, shardIDs}
for _, server := range servers {
var pullTaskResponse ShardOperationResponse
srv := kv.makeEnd(server)
if srv.Call("ShardKV.GetShardsData", &pullTaskRequest, &pullTaskResponse) && pullTaskResponse.Err == OK {
DPrintf("{Node %v}{Group %v} gets a PullTaskResponse %v and tries to commit it when currentConfigNum is %v", kv.rf.Me(), kv.gid, pullTaskResponse, configNum)
kv.Execute(NewInsertShardsCommand(&pullTaskResponse), &CommandResponse{})
}
}
}(kv.lastConfig.Groups[gid], kv.currentConfig.Num, shardIDs)
}
kv.mu.RUnlock()
wg.Wait()
}
func (kv *ShardKV) GetShardsData(request *ShardOperationRequest, response *ShardOperationResponse) {
// only pull shards from leader
if _, isLeader := kv.rf.GetState(); !isLeader {
response.Err = ErrWrongLeader
return
}
kv.mu.RLock()
defer kv.mu.RUnlock()
defer DPrintf("{Node %v}{Group %v} processes PullTaskRequest %v with response %v", kv.rf.Me(), kv.gid, request, response)
if kv.currentConfig.Num < request.ConfigNum {
response.Err = ErrNotReady
return
}
response.Shards = make(map[int]map[string]string)
for _, shardID := range request.ShardIDs {
response.Shards[shardID] = kv.stateMachines[shardID].deepCopy()
}
response.LastOperations = make(map[int64]OperationContext)
for clientID, operation := range kv.lastOperations {
response.LastOperations[clientID] = operation.deepCopy()
}
response.ConfigNum, response.Err = request.ConfigNum, OK
}
func (kv *ShardKV) applyInsertShards(shardsInfo *ShardOperationResponse) *CommandResponse {
if shardsInfo.ConfigNum == kv.currentConfig.Num {
DPrintf("{Node %v}{Group %v} accepts shards insertion %v when currentConfig is %v", kv.rf.Me(), kv.gid, shardsInfo, kv.currentConfig)
for shardId, shardData := range shardsInfo.Shards {
shard := kv.stateMachines[shardId]
if shard.Status == Pulling {
for key, value := range shardData {
shard.KV[key] = value
}
shard.Status = GCing
} else {
DPrintf("{Node %v}{Group %v} encounters duplicated shards insertion %v when currentConfig is %v", kv.rf.Me(), kv.gid, shardsInfo, kv.currentConfig)
break
}
}
for clientId, operationContext := range shardsInfo.LastOperations {
if lastOperation, ok := kv.lastOperations[clientId]; !ok || lastOperation.MaxAppliedCommandId < operationContext.MaxAppliedCommandId {
kv.lastOperations[clientId] = operationContext
}
}
return &CommandResponse{OK, ""}
}
DPrintf("{Node %v}{Group %v} rejects outdated shards insertion %v when currentConfig is %v", kv.rf.Me(), kv.gid, shardsInfo, kv.currentConfig)
return &CommandResponse{ErrOutDated, ""}
}
分片清理
分片清理协程负责定时检测分片的 GCing 状态,利用 lastConfig 计算出对应 raft 组的 gid 和要拉取的分片,然后并行地去删除分片。
注意这里使用了 waitGroup 来保证所有独立地任务完成后才会进行下一次任务。此外 wg.Wait() 一定要在释放读锁之后,否则无法满足 challenge2 的要求。
在删除分片的 handler 中,首先仅可由 leader 处理该请求,其次如果发现请求中的配置版本小于本地的版本,那说明该请求已经执行过,否则本地的 config 也无法增大,此时直接返回 OK 即可,否则在本地提交一个删除分片的日志。
在 apply 分片删除日志时需要保证幂等性:
- 不同版本的配置更新日志:仅可执行与当前配置版本相同地分片删除日志,否则已经删除过,直接返回 OK 即可。
- 相同版本的配置更新日志:如果分片状态为
GCing,说明是本raft组已成功删除远端raft组的数据,现需要更新分片状态为默认状态以支持配置的进一步更新;否则如果分片状态为BePulling,则说明本raft组第一次删除该分片的数据,此时直接重置分片即可。否则说明该请求已经应用过,直接break返回 OK 即可。
func (kv *ShardKV) gcAction() {
kv.mu.RLock()
gid2shardIDs := kv.getShardIDsByStatus(GCing)
var wg sync.WaitGroup
for gid, shardIDs := range gid2shardIDs {
DPrintf("{Node %v}{Group %v} starts a GCTask to delete shards %v in group %v when config is %v", kv.rf.Me(), kv.gid, shardIDs, gid, kv.currentConfig)
wg.Add(1)
go func(servers []string, configNum int, shardIDs []int) {
defer wg.Done()
gcTaskRequest := ShardOperationRequest{configNum, shardIDs}
for _, server := range servers {
var gcTaskResponse ShardOperationResponse
srv := kv.makeEnd(server)
if srv.Call("ShardKV.DeleteShardsData", &gcTaskRequest, &gcTaskResponse) && gcTaskResponse.Err == OK {
DPrintf("{Node %v}{Group %v} deletes shards %v in remote group successfully when currentConfigNum is %v", kv.rf.Me(), kv.gid, shardIDs, configNum)
kv.Execute(NewDeleteShardsCommand(&gcTaskRequest), &CommandResponse{})
}
}
}(kv.lastConfig.Groups[gid], kv.currentConfig.Num, shardIDs)
}
kv.mu.RUnlock()
wg.Wait()
}
func (kv *ShardKV) DeleteShardsData(request *ShardOperationRequest, response *ShardOperationResponse) {
// only delete shards when role is leader
if _, isLeader := kv.rf.GetState(); !isLeader {
response.Err = ErrWrongLeader
return
}
defer DPrintf("{Node %v}{Group %v} processes GCTaskRequest %v with response %v", kv.rf.Me(), kv.gid, request, response)
kv.mu.RLock()
if kv.currentConfig.Num > request.ConfigNum {
DPrintf("{Node %v}{Group %v}'s encounters duplicated shards deletion %v when currentConfig is %v", kv.rf.Me(), kv.gid, request, kv.currentConfig)
response.Err = OK
kv.mu.RUnlock()
return
}
kv.mu.RUnlock()
var commandResponse CommandResponse
kv.Execute(NewDeleteShardsCommand(request), &commandResponse)
response.Err = commandResponse.Err
}
func (kv *ShardKV) applyDeleteShards(shardsInfo *ShardOperationRequest) *CommandResponse {
if shardsInfo.ConfigNum == kv.currentConfig.Num {
DPrintf("{Node %v}{Group %v}'s shards status are %v before accepting shards deletion %v when currentConfig is %v", kv.rf.Me(), kv.gid, kv.getShardStatus(), shardsInfo, kv.currentConfig)
for _, shardId := range shardsInfo.ShardIDs {
shard := kv.stateMachines[shardId]
if shard.Status == GCing {
shard.Status = Serving
} else if shard.Status == BePulling {
kv.stateMachines[shardId] = NewShard()
} else {
DPrintf("{Node %v}{Group %v} encounters duplicated shards deletion %v when currentConfig is %v", kv.rf.Me(), kv.gid, shardsInfo, kv.currentConfig)
break
}
}
DPrintf("{Node %v}{Group %v}'s shards status are %v after accepting shards deletion %v when currentConfig is %v", kv.rf.Me(), kv.gid, kv.getShardStatus(), shardsInfo, kv.currentConfig)
return &CommandResponse{OK, ""}
}
DPrintf("{Node %v}{Group %v}'s encounters duplicated shards deletion %v when currentConfig is %v", kv.rf.Me(), kv.gid, shardsInfo, kv.currentConfig)
return &CommandResponse{OK, ""}
}
空日志检测
分片清理协程负责定时检测 raft 层的 leader 是否拥有当前 term 的日志,如果没有则提交一条空日志,这使得新 leader 的状态机能够迅速达到最新状态,从而避免多 raft 组间的活锁状态。
func (kv *ShardKV) checkEntryInCurrentTermAction() {
if !kv.rf.HasLogInCurrentTerm() {
kv.Execute(NewEmptyEntryCommand(), &CommandResponse{})
}
}
func (kv *ShardKV) applyEmptyEntry() *CommandResponse {
return &CommandResponse{OK, ""}
}
