MIT6.824 Lab2 RAFT 介绍与实现
学习材料
官网简单介绍:https://raft.github.io/
可视化学习:http://thesecretlivesofdata.com/raft/
论文:https://pdos.csail.mit.edu/6.824/papers/raft-extended.pdf
作者Diego Ongaro讲解视频:https://www.youtube.com/watch?v=vYp4LYbnnW8
MIT 6.824 - Raft学生指南(中英对照):https://mp.weixin.qq.com/s/blCp4KCY1OKiU2ljLSGr0Q
RAFT 介绍
Raft是一种分布共识算法,分布公式算法的目的是在多个机器上维持相同状态。它提供了和 Paxos 算法相同的功能和性能,但是它的算法结构和 Paxos 不同,使得 Raft 算法更加容易理解并且更容易构建实际的系统。
Raft通过维持操作记录结构保证一致性,即保证 log 完全相同地复制到多台服务器上。
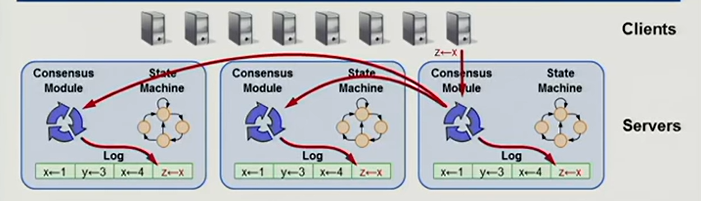
只要每台服务器的日志相同,那么,在不同服务器上的状态机以相同顺序从日志中执行相同的命令,将会产生相同的结果。共识算法的工作就是管理这些日志。
接下来,将从RAFT四部分:领导者选举、日志同步和心跳维持、持久化、日志压缩和快照(2021MIT6.824 Lab2实验内容)进行介绍。
实验代码参考https://github.com/LebronAl/MIT6.824-2021/blob/master/docs/lab2.md,虽然自己手写了一份,卡在了lab2B上,只能靠运气通过测试,所以百度看到这份代码,感觉设计的十分棒,对go语言应用的高级,所以重新参考学习一下。
原作者给的建议:
有关 go 实现 raft 的种种坑,可以首先参考 6.824 课程对 locking 和 structure 的描述,然后再参考 6.824 TA 的 guidance 。写之前一定要看看这三篇博客,否则很容易被 bug 包围。
官方的整体架构
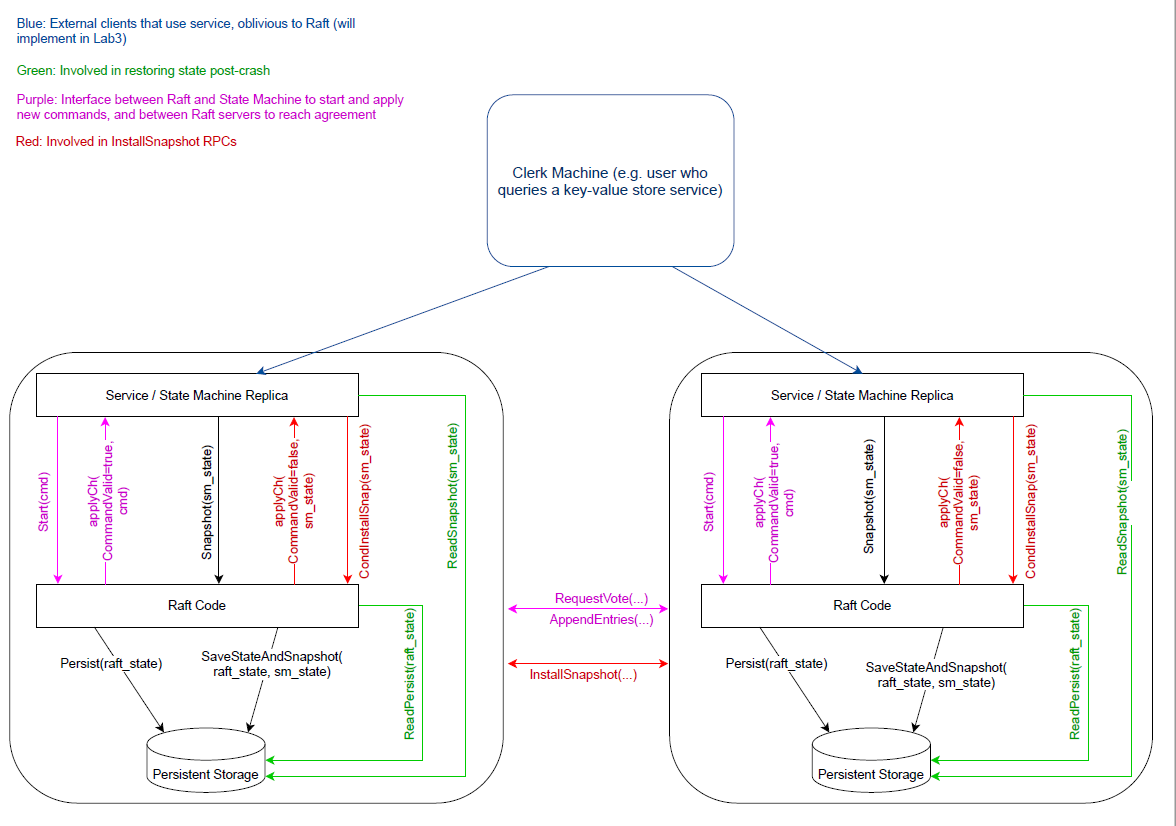
原论文的图片必须要遵守的,MUST,每一条代码都要遵守!

lab 2A 领导者选举
领导者选举是集群的第一步。一个集群的节点个数往往是奇数,如 3、5 等,这样就避免了选举时会发生脑裂(出现了多个领导者)的情况。
服务器状态
服务器在任意时间只能处于以下三种状态之一:
- Leader:处理所有客户端请求、日志同步、心跳维持领导权。同一时刻最多只能有一个可行的 Leader
- Follower:所有服务器的初始状态,功能为:追随领导者,接收领导者日志并实时同步,特性:完全被动的(不发送 RPC,只响应收到的 RPC)
- Candidate:用来选举新的 Leader,处于 Leader 和 Follower 之间的暂时状态,如Follower 一定时间内未收到来自Leader的心跳包,Follower会自动切换为Candidate,并开始选举操作,向集群中的其它节点发送投票请求,待收到半数以上的选票时,协调者升级成为领导者。;
系统正常运行时,只有一个 Leader,其余都是 Followers。Leader拥有绝对的领导力,不断向Followers同步日志且发送心跳状态。
首先要参考论文定义Raft结构,有些结构在2A领导者选举中用不到:

type Raft struct {
mu sync.RWMutex // Lock to protect shared access to this peer's state, 锁
peers []*labrpc.ClientEnd // RPC end points of all peers, 集群消息
persister *Persister // Object to hold this peer's persisted state,持久化
me int // this peer's index into peers[], 当前节点id
dead int32 // set by Kill(),是否死亡,1表示死亡,0表示还活着
// 2A
state NodeState // 节点状态
currentTerm int // 当前任期
votedFor int // 给谁投过票
electionTimer *time.Timer // 选举时间
heartbeatTimer *time.Timer // 心跳时间
// 2B
logs []Entry // the first entry is a dummy entry which contains LastSnapshotTerm, LastSnapshotIndex and nil Command
commitIndex int // 已提交日志序号
lastApplied int // 已应用日志序号
nextIndex []int // 下一个待发送日志序号,leader 特有
matchIndex []int // 已同步日志序号,leader 特有
applyCh chan ApplyMsg
applyCond *sync.Cond // used to wakeup applier goroutine after committing new entries
replicatorCond []*sync.Cond // used to signal replicator goroutine to batch replicating entries
}
「任期」是Raft算法中一个非常重要的概念,你可以将其理解为「逻辑时钟」,每一个节点在初始化时,状态为追随者,任期为0,当一定时间内未收到领导者日志后,会自动成为协调者,并给自己投票,且任期+1
启动
-
集群所有节点初始状态均为Follower
-
Follower 被动地接受 Leader 或 Candidate 的 RPC;
-
所以,如果 Leader 想要保持权威,必须向集群中的其它节点发送心跳包(空的
AppendEntries RPC); -
等待选举超时(
electionTimeout,一般在 100~500ms)后,Follower 没有收到任何 RPC:-
Follower 认为集群中没有 Leader
-
开始新的一轮选举
-
func Make(peers []*labrpc.ClientEnd, me int,
persister *Persister, applyCh chan ApplyMsg) *Raft {
rf := &Raft{
peers: peers,
persister: persister,
me: me,
dead: 0,
applyCh: applyCh,
replicatorCond: make([]*sync.Cond, len(peers)),
state: StateFollower,
currentTerm: 0,
votedFor: -1,
logs: make([]Entry, 1),
nextIndex: make([]int, len(peers)),
matchIndex: make([]int, len(peers)),
heartbeatTimer: time.NewTimer(StableHeartbeatTimeout()),
electionTimer: time.NewTimer(RandomizedElectionTimeout()),
}
// initialize from state persisted before a crash
rf.readPersist(persister.ReadRaftState())
// 需要开共len(peer) - 1 个线程replicator,分别管理对应 peer 的复制状态
rf.applyCond = sync.NewCond(&rf.mu)
lastLog := rf.getLastLog()
for i := 0; i < len(peers); i++ {
rf.matchIndex[i], rf.nextIndex[i] = 0, lastLog.Index+1
if i != rf.me {
rf.replicatorCond[i] = sync.NewCond(&sync.Mutex{})
// start replicator goroutine to replicate entries in batch
go rf.replicator(i)
}
}
// start ticker goroutine to start elections, 用来触发 heartbeat timeout 和 election timeout
go rf.ticker()
// start applier goroutine to push committed logs into applyCh exactly once, ,用来往 applyCh 中 push 提交的日志并保证 exactly once
go rf.applier()
return rf
}
集群开始的时候,所有节点均为Follower, 它们依靠ticker()成为Candidate。ticker 协程会定期收到两个 timer 的到期事件,如果是 election timer 到期,则发起一轮选举;如果是 heartbeat timer 到期且节点是 leader,则发起一轮心跳。
func (rf *Raft) ticker() {
for rf.killed() == false {
select {
case <-rf.electionTimer.C: // 进入候选者状态,进行选举
rf.mu.Lock()
rf.ChangeState(StateCandidate)
rf.currentTerm += 1
rf.StartElection()
rf.electionTimer.Reset(RandomizedElectionTimeout())
rf.mu.Unlock()
// 2A 可以先不实现
case <-rf.heartbeatTimer.C: // 领导者发送心跳维持领导力
rf.mu.Lock()
if rf.state == StateLeader {
rf.BroadcastHeartbeat(true)
rf.heartbeatTimer.Reset(StableHeartbeatTimeout())
}
rf.mu.Unlock()
}
}
}
选举与投票
当一个节点开始竞选:
- 增加自己的
currentTerm - 转为 Candidate 状态,其目标是获取超过半数节点的选票,让自己成为 Leader
- 先给自己投一票
- 并行地向集群中其它节点发送
RequestVote RPC索要选票,如果没有收到指定节点的响应,它会反复尝试,直到发生以下三种情况之一:- 获得超过半数的选票:成为 Leader,并向其它节点发送
AppendEntries心跳; - 收到来自 Leader 的 RPC:转为 Follower;
- 其它两种情况都没发生,没人能够获胜(
electionTimeout已过):增加currentTerm,开始新一轮选举;
- 获得超过半数的选票:成为 Leader,并向其它节点发送
Candidate 选举程序与投票统计
func (rf *Raft) StartElection() {
request := rf.genRequestVoteRequest()
DPrintf("{Node %v} starts election with RequestVoteRequest %v", rf.me, request)
// use Closure
grantedVotes := 1
rf.votedFor = rf.me
rf.persist()
for peer := range rf.peers {
if peer == rf.me {
continue
}
go func(peer int) {
response := new(RequestVoteResponse)
if rf.sendRequestVote(peer, request, response) {
rf.mu.Lock()
defer rf.mu.Unlock()
DPrintf("{Node %v} receives RequestVoteResponse %v from {Node %v} after sending RequestVoteRequest %v in term %v", rf.me, response, peer, request, rf.currentTerm)
if rf.currentTerm == request.Term && rf.state == StateCandidate {
if response.VoteGranted {
grantedVotes += 1
if grantedVotes > len(rf.peers)/2 {
DPrintf("{Node %v} receives majority votes in term %v", rf.me, rf.currentTerm)
rf.ChangeState(StateLeader)
rf.BroadcastHeartbeat(true)
}
} else if response.Term > rf.currentTerm {
DPrintf("{Node %v} finds a new leader {Node %v} with term %v and steps down in term %v", rf.me, peer, response.Term, rf.currentTerm)
rf.ChangeState(StateFollower)
rf.currentTerm, rf.votedFor = response.Term, -1
rf.persist()
}
}
}
}(peer)
}
}
-
发起投票需要异步进行,从而不阻塞ticker线程,这样candidate 再次 election timeout 之后才能自增 term 继续发起新一轮选举。
-
投票统计:可以在函数内定义一个变量并利用 go 的闭包来实现,也可以在结构体中维护一个 votes 变量来实现。为了 raft 结构体更干净,我选择了前者。
-
抛弃过期请求的回复:对于过期请求的回复,直接抛弃就行,不要做任何处理,这一点 guidance 里面也有介绍到
上面Candidate对除了自己本身之外的所有节点发起了投票请求RPC,看一下Follower投票接收实现

func (rf *Raft) RequestVote(request *RequestVoteRequest, response *RequestVoteResponse) {
rf.mu.Lock()
defer rf.mu.Unlock()
defer rf.persist()
defer DPrintf("{Node %v}'s state is {state %v,term %v,commitIndex %v,lastApplied %v,firstLog %v,lastLog %v} before processing requestVoteRequest %v and reply requestVoteResponse %v", rf.me, rf.state, rf.currentTerm, rf.commitIndex, rf.lastApplied, rf.getFirstLog(), rf.getLastLog(), request, response)
if request.Term < rf.currentTerm || (request.Term == rf.currentTerm && rf.votedFor != -1 && rf.votedFor != request.CandidateId) {
response.Term, response.VoteGranted = rf.currentTerm, false
return
}
if request.Term > rf.currentTerm {
rf.ChangeState(StateFollower)
rf.currentTerm, rf.votedFor = request.Term, -1
}
// 2A可以先不实现
if !rf.isLogUpToDate(request.LastLogTerm, request.LastLogIndex) {
response.Term, response.VoteGranted = rf.currentTerm, false
return
}
rf.votedFor = request.CandidateId
rf.electionTimer.Reset(RandomizedElectionTimeout())
response.Term, response.VoteGranted = rf.currentTerm, true
}
「任期」表示节点的逻辑时钟,任期高的节点拥有更高的话语权。在RequestVote这个函数中,如果请求者的任期小于当前节点任期,则拒绝投票;如果请求者任期大于当前节点人气,那么当前节点立马成为追随者。即任期大的节点对任期小的拥有绝对的话语权,一旦发现任期大的节点,立马成为其追随者。
注意,节点的选举随机时间和心跳时间的选择很重要
- 节点随机选择超时时间,通常在 [T, 2T] 之间(T =
electionTimeout) - 这样,节点不太可能再同时开始竞选,先竞选的节点有足够的时间来索要其他节点的选票
- T >> broadcast time(T 远大于广播时间)时效果更佳
const (
HeartbeatTimeout = 125
ElectionTimeout = 1000
)
func StableHeartbeatTimeout() time.Duration {
return time.Duration(HeartbeatTimeout) * time.Millisecond
}
func RandomizedElectionTimeout() time.Duration {
return time.Duration(ElectionTimeout+globalRand.Intn(ElectionTimeout)) * time.Millisecond
}
领导者选举主要工作可总结如下:
- 三个状态,三个状态之间的转换。
- 1个loop——ticker。
- 1个RPC请求和处理,用于投票。
另外,ticker会一直运行,直到节点被kill,因此集群领导者并非唯一,一旦领导者出现了宕机、网络故障等问题,其它节点都能第一时间感知,并迅速做出重新选举的反应,从而维持集群的正常运行,毕竟Raft集群一旦失去了领导者,就无法工作。
lab 2B 日志复制
日志结构
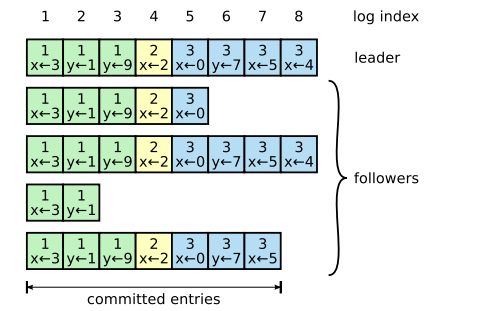
每个节点存储自己的日志副本(log[]),每条日志记录包含:
- 索引:该记录在日志中的位置
- 任期号:该记录首次被创建时的任期号
- 命令
type Entry struct {
Index int
Term int
Command interface{}
}
日志「已提交」与「已应用」概念:
已提交:真正的数据不变
已应用:真正的数据变化
已提交的日志被应用后才会生效
日志同步
日志同步是Leader独有的权利,Leader向Follower发送日志,Follower同步日志。
日志同步要解决如下两个问题:
- Leader发送心跳宣示自己的主权,Follower不会发起选举。
- Leader将自己的日志数据同步到Follower,达到数据备份的效果。
运行流程
-
客户端向 Leader 发送命令,希望该命令被所有状态机执行;
-
Leader 先将该命令追加到自己的日志中;
-
Leader 并行地向其它节点发送
AppendEntries RPC,等待响应; -
收到超过半数节点的响应,则认为新的日志记录是被提交的:
-
- Leader 将命令传给自己的状态机,然后向客户端返回响应
- 此外,一旦 Leader 知道一条记录被提交了,将在后续的
AppendEntries RPC中通知已经提交记录的 Followers - Follower 将已提交的命令传给自己的状态机
-
如果 Follower 宕机/超时:Leader 将反复尝试发送 RPC;
-
性能优化:Leader 不必等待每个 Follower 做出响应,只需要超过半数的成功响应(确保日志记录已经存储在超过半数的节点上)——一个很慢的节点不会使系统变慢,因为 Leader 不必等他;
同样地,日志同步也需要与其它节点进行沟通,对应论文中的AppendEntriesArgs RPC请求,如下图所示:

type AppendEntriesRequest struct {
Term int // leader 任期
LeaderId int // leader id
PrevLogIndex int // leader 中上一次同步的日志索引
PrevLogTerm int // leader 中上一次同步的日志任期
LeaderCommit int // 领导者的已知已提交的最高的日志条目的索引
Entries []Entry // 同步日志
}
func (request AppendEntriesRequest) String() string {
return fmt.Sprintf("{Term:%v,LeaderId:%v,PrevLogIndex:%v,PrevLogTerm:%v,LeaderCommit:%v,Entries:%v}", request.Term, request.LeaderId, request.PrevLogIndex, request.PrevLogTerm, request.LeaderCommit, request.Entries)
}
type AppendEntriesResponse struct {
Term int // 当前任期号,以便于候选人去更新自己的任期号
Success bool // 是否同步成功,true 为成功
ConflictIndex int // 冲突index
ConflictTerm int // 冲突Term
}
依靠论文图,给出具体实现,并加上了6.824的加速解决节点间日志冲突的优化(lab 2C 中有介绍优化方法)。
// Follwer 接收 Leader日志同步 处理
func (rf *Raft) AppendEntries(request *AppendEntriesRequest, response *AppendEntriesResponse) {
rf.mu.Lock()
defer rf.mu.Unlock()
defer rf.persist()
defer DPrintf("{Node %v}'s state is {state %v,term %v,commitIndex %v,lastApplied %v,firstLog %v,lastLog %v} before processing AppendEntriesRequest %v and reply AppendEntriesResponse %v", rf.me, rf.state, rf.currentTerm, rf.commitIndex, rf.lastApplied, rf.getFirstLog(), rf.getLastLog(), request, response)
if request.Term < rf.currentTerm {
response.Term, response.Success = rf.currentTerm, false
return
}
if request.Term > rf.currentTerm {
rf.currentTerm, rf.votedFor = request.Term, -1
}
rf.ChangeState(StateFollower)
rf.electionTimer.Reset(RandomizedElectionTimeout())
// 若leader安装了snapshot,会出现rf.log.getFirstLog() > PrevLogIndex的情况。
if request.PrevLogIndex < rf.getFirstLog().Index {
response.Term, response.Success = 0, false
DPrintf("{Node %v} receives unexpected AppendEntriesRequest %v from {Node %v} because prevLogIndex %v < firstLogIndex %v", rf.me, request, request.LeaderId, request.PrevLogIndex, rf.getFirstLog().Index)
return
}
// 判断PrevLog存不存在
if !rf.matchLog(request.PrevLogTerm, request.PrevLogIndex) {
response.Term, response.Success = rf.currentTerm, false
lastIndex := rf.getLastLog().Index
//1. Follower 的 log 不够新,prevLogIndex 已经超出 log 长度
if lastIndex < request.PrevLogIndex {
response.ConflictTerm, response.ConflictIndex = -1, lastIndex+1
// 2. Follower prevLogIndex 处存在 log
// 向主节点上报信息,加速下次复制日志
// 当PreLogTerm与当前日志的任期不匹配时,找出日志第一个不匹配任期的index
} else {
firstIndex := rf.getFirstLog().Index
response.ConflictTerm = rf.logs[request.PrevLogIndex-firstIndex].Term
index := request.PrevLogIndex - 1
for index >= firstIndex && rf.logs[index-firstIndex].Term == response.ConflictTerm {
index--
}
response.ConflictIndex = index
}
return
}
firstIndex := rf.getFirstLog().Index
for index, entry := range request.Entries {
if entry.Index-firstIndex >= len(rf.logs) || rf.logs[entry.Index-firstIndex].Term != entry.Term {
rf.logs = shrinkEntriesArray(append(rf.logs[:entry.Index-firstIndex], request.Entries[index:]...))
break
}
}
// 通知上层可以apply主节点已经commit的日志。
rf.advanceCommitIndexForFollower(request.LeaderCommit)
response.Term, response.Success = rf.currentTerm, true
}
对于复制模型,
对于复制模型,很直观的方式是:包装一个 BroadcastHeartbeat() 函数,其负责向所有 follower 发送一轮同步。不论是心跳超时还是上层服务传进来一个新 command,都去调一次这个函数来发起一轮同步。
以上方式是可以 work 的,我最开始的实现也是这样的,然而在测试过程中,我发现这种方式有很大的资源浪费。比如上层服务连续调用了几十次 Start() 函数,由于每一次调用 Start() 函数都会触发一轮日志同步,则最终导致发送了几十次日志同步。一方面,这些请求包含的 entries 基本都一样,甚至有 entry 连续出现在几十次 rpc 中,这样的实现多传输了一些数据,存在一定浪费;另一方面,每次发送 rpc 都不论是发送端还是接收端都需要若干次系统调用和内存拷贝,rpc 次数过多也会对 CPU 造成不必要的压力。总之,这种资源浪费的根本原因就在于:将日志同步的触发与上层服务提交新指令强绑定,从而导致发送了很多重复的 rpc。
为此,我参考了
sofajraft的日志复制实现 。每个 peer 在启动时会为除自己之外的每个 peer 都分配一个 replicator 协程。对于 follower 节点,该协程利用条件变量执行 wait 来避免耗费 cpu,并等待变成 leader 时再被唤醒;对于 leader 节点,该协程负责尽最大地努力去向对应 follower 发送日志使其同步,直到该节点不再是 leader 或者该 follower 节点的 matchIndex 大于等于本地的 lastIndex。这样的实现方式能够将日志同步的触发和上层服务提交新指令解耦,能够大幅度减少传输的数据量,rpc 次数和系统调用次数。由于 6.824 的测试能够展示测试过程中的传输 rpc 次数和数据量,因此我进行了前后的对比测试,结果显示:这样的实现方式相比直观方式的实现,不同测试数据传输量的减少倍数在 1-20 倍之间。当然,这样的实现也只是实现了粗粒度的 batching,并没有流量控制,而且也没有实现 pipeline,有兴趣的同学可以去了解
sofajraft,etcd或者tikv的实现,他们对于复制过程进行了更细粒度的控制。此外,虽然 leader 对于每一个节点都有一个 replicator 协程去同步日志,但其目前同时最多只能发送一个 rpc,而这个 rpc 很可能超时或丢失从而触发集群换主。因此,对于 heartbeat timeout 触发的 BroadcastHeartbeat,我们需要立即发出日志同步请求而不是让 replicator 去发。这也就是我的 BroadcastHeartbeat 函数有两种行为的真正原因。
这一块的代码我自认为抽象的还是比较优雅的,也算是对 go 异步编程的一个实践吧。
// 复制线程
func (rf *Raft) replicator(peer int) {
rf.replicatorCond[peer].L.Lock()
defer rf.replicatorCond[peer].L.Unlock()
for rf.killed() == false {
// 如果不需要为这个 peer 复制条目,只要释放 CPU 并等待其他 goroutine 的信号,如果服务添加了新的命令
// 如果这个peer需要复制条目,这个goroutine会多次调用replicateOneRound(peer)直到这个peer赶上,然后等待
for !rf.needReplicating(peer) {
rf.replicatorCond[peer].Wait()
}
// maybe a pipeline mechanism is better to trade-off the memory usage and catch up time
rf.replicateOneRound(peer)
}
}
// used by replicator goroutine to judge whether a peer needs replicating
func (rf *Raft) needReplicating(peer int) bool {
rf.mu.RLock()
defer rf.mu.RUnlock()
return rf.state == StateLeader && rf.matchIndex[peer] < rf.getLastLog().Index
}
// 心跳维持领导力
func (rf *Raft) BroadcastHeartbeat(isHeartBeat bool) {
for peer := range rf.peers {
if peer == rf.me {
continue
}
if isHeartBeat {
// need sending at once to maintain leadership
go rf.replicateOneRound(peer)
} else {
// just signal replicator goroutine to send entries in batch
rf.replicatorCond[peer].Signal()
}
}
}
// Leader 向Follwer 发送复制请求
func (rf *Raft) replicateOneRound(peer int) {
rf.mu.RLock()
if rf.state != StateLeader {
rf.mu.RUnlock()
return
}
prevLogIndex := rf.nextIndex[peer] - 1
if prevLogIndex < rf.getFirstLog().Index {
// only snapshot can catch up
request := rf.genInstallSnapshotRequest()
rf.mu.RUnlock()
response := new(InstallSnapshotResponse)
if rf.sendInstallSnapshot(peer, request, response) {
rf.mu.Lock()
rf.handleInstallSnapshotResponse(peer, request, response)
rf.mu.Unlock()
}
} else {
// just entries can catch up
request := rf.genAppendEntriesRequest(prevLogIndex)
rf.mu.RUnlock()
response := new(AppendEntriesResponse)
if rf.sendAppendEntries(peer, request, response) {
rf.mu.Lock()
rf.handleAppendEntriesResponse(peer, request, response)
rf.mu.Unlock()
}
}
}
// Leader处理Follower 日志复制响应
func (rf *Raft) handleAppendEntriesResponse(peer int, request *AppendEntriesRequest, response *AppendEntriesResponse) {
if rf.state == StateLeader && rf.currentTerm == request.Term {
if response.Success {
rf.matchIndex[peer] = request.PrevLogIndex + len(request.Entries)
rf.nextIndex[peer] = rf.matchIndex[peer] + 1
rf.advanceCommitIndexForLeader()
} else {
if response.Term > rf.currentTerm {
rf.ChangeState(StateFollower)
rf.currentTerm, rf.votedFor = response.Term, -1
rf.persist()
} else if response.Term == rf.currentTerm {
rf.nextIndex[peer] = response.ConflictIndex
if response.ConflictTerm != -1 {
firstIndex := rf.getFirstLog().Index
for i := request.PrevLogIndex; i >= firstIndex; i-- {
if rf.logs[i-firstIndex].Term == response.ConflictTerm {
rf.nextIndex[peer] = i + 1
break
}
}
}
}
}
}
DPrintf("{Node %v}'s state is {state %v,term %v,commitIndex %v,lastApplied %v,firstLog %v,lastLog %v} after handling AppendEntriesResponse %v for AppendEntriesRequest %v", rf.me, rf.state, rf.currentTerm, rf.commitIndex, rf.lastApplied, rf.getFirstLog(), rf.getLastLog(), response, request)
}
func (rf *Raft) Start(command interface{}) (int, int, bool) {
rf.mu.Lock()
defer rf.mu.Unlock()
if rf.state != StateLeader {
return -1, -1, false
}
newLog := rf.appendNewEntry(command)
DPrintf("{Node %v} receives a new command[%v] to replicate in term %v", rf.me, newLog, rf.currentTerm)
rf.BroadcastHeartbeat(false)
return newLog.Index, newLog.Term, true
}
完善选举
我们如何确保选出了一个很好地保存了所有已提交日志的 Leader ?
无论谁赢得选举,可以确保 Leader 和超过半数投票给它的节点中拥有最完整的日志——最完整的意思就是 index 和 term 这对唯一标识是最大的。
为了保证日志「更加完善」的节点能够当选领导者,因此选票会向日志完善的节点倾斜,这被称为isLogUpToDate条件。如下:
// used by RequestVote Handler to judge which log is newer
func (rf *Raft) isLogUpToDate(term, index int) bool {
lastLog := rf.getLastLog()
return term > lastLog.Term || (term == lastLog.Term && index >= lastLog.Index)
}
日志应用 异步 applier 的 exactly once
Raft论文的说话,一旦发现commitIndex大于lastApplied,应该立马将可应用的日志应用到状态机中。Raft节点本身是没有状态机实现的,状态机应该由Raft的上层应用来实现,因此我们不会谈论如何实现状态机,只需将日志发送给applyCh这个通道即可。
异步 apply 可以提升 raft 算法的性能,具体可以参照 PingCAP 的博客 。
对于异步 apply,其触发方式无非两种,leader 提交了新的日志或者 follower 通过 leader 发来的 leaderCommit 来更新 commitIndex。很多人实现的时候可能顺手就在这两处异步启一个协程把 [lastApplied + 1, commitIndex] 的 entry push 到 applyCh 中,但其实这样子是可能重复发送 entry 的,原因是 push applyCh 的过程不能够持锁,那么这个 lastApplied 在没有 push 完之前就无法得到更新,从而可能被多次调用。虽然只要上层服务可以保证不重复 apply 相同 index 的日志到状态机就不会有问题,但我个人认为这样的做法是不优雅的。考虑到异步 apply 时最耗时的步骤是 apply channel 和 apply 日志到状态机,其他的都不怎么耗费时间。因此我们完全可以只用一个 applier 协程,让其不断的把 [lastApplied + 1, commitIndex] 区间的日志 push 到 applyCh 中去。这样既可保证每一条日志只会被 exactly once 地 push 到 applyCh 中,也可以使得日志 apply 到状态机和 raft 提交新日志可以真正的并行。我认为这是一个较为优雅的异步 apply 实现。
// a dedicated applier goroutine to guarantee that each log will be push into applyCh exactly once, ensuring that service's applying entries and raft's committing entries can be parallel
func (rf *Raft) applier() {
for rf.killed() == false {
rf.mu.Lock()
// if there is no need to apply entries, just release CPU and wait other goroutine's signal if they commit new entries
for rf.lastApplied >= rf.commitIndex {
rf.applyCond.Wait()
}
firstIndex, commitIndex, lastApplied := rf.getFirstLog().Index, rf.commitIndex, rf.lastApplied
entries := make([]Entry, commitIndex-lastApplied)
copy(entries, rf.logs[lastApplied+1-firstIndex:commitIndex+1-firstIndex])
rf.mu.Unlock()
for _, entry := range entries {
rf.applyCh <- ApplyMsg{
CommandValid: true,
Command: entry.Command,
CommandTerm: entry.Term,
CommandIndex: entry.Index,
}
}
rf.mu.Lock()
DPrintf("{Node %v} applies entries %v-%v in term %v", rf.me, rf.lastApplied, commitIndex, rf.currentTerm)
// use commitIndex rather than rf.commitIndex because rf.commitIndex may change during the Unlock() and Lock()
// use Max(rf.lastApplied, commitIndex) rather than commitIndex directly to avoid concurrently InstallSnapshot rpc causing lastApplied to rollback
rf.lastApplied = Max(rf.lastApplied, commitIndex)
rf.mu.Unlock()
}
}
需要注意以下两点:
- 引用之前的 commitIndex:push applyCh 结束之后更新 lastApplied 的时候一定得用之前的 commitIndex 而不是 rf.commitIndex,因为后者很可能在 push channel 期间发生了改变。
- 防止与 installSnapshot 并发导致 lastApplied 回退:需要注意到,applier 协程在 push channel 时,中间可能夹杂有 snapshot 也在 push channel。如果该 snapshot 有效,那么在 CondInstallSnapshot 函数里上层状态机和 raft 模块就会原子性的发生替换,即上层状态机更新为 snapshot 的状态,raft 模块更新 log, commitIndex, lastApplied 等等,此时如果这个 snapshot 之后还有一批旧的 entry 在 push channel,那上层服务需要能够知道这些 entry 已经过时,不能再 apply,同时 applier 这里也应该加一个 Max 自身的函数来防止 lastApplied 出现回退。
lab 2C 持久化
数据持久化是Raft四大模块中最简单的一部分。在Raft论文中指出,需要持久化的字段只有三个:

冲突优化
nextIndex 优化
需要改造AppendEntries以及其请求体和返回体,添加ConflictIndex和ConflictTerm字段
需要阅读助教的 guide,其中有一段原文为:
If a follower does not have prevLogIndex in its log, it should return with conflictIndex = len(log) and conflictTerm = None.
If a follower does have prevLogIndex in its log, but the term does not match, it should return conflictTerm = log[prevLogIndex].Term, and then search its log for the first index whose entry has term equal to conflictTerm.
Upon receiving a conflict response, the leader should first search its log for conflictTerm. If it finds an entry in its log with that term, it should set nextIndex to be the one beyond the index of the last entry in that term in its log.
If it does not find an entry with that term, it should set nextIndex = conflictIndex.
建议直接读英文版,先按逻辑自己实现一次。
已经说明地很清楚了,梳理之后,逻辑如下:
-
若 follower 没有 prevLogIndex 处的日志,则直接置 conflictIndex = len(log),conflictTerm = None;
- leader 收到返回体后,肯定找不到对应的 term,则设置nextIndex = conflictIndex;
- 其实就是 leader 对应的 nextIndex 直接回退到该 follower 的日志条目末尾处,因为 prevLogIndex 超前了
-
若 follower 有 prevLogIndex 处的日志,但是 term 不匹配;则设置 conlictTerm为 prevLogIndex 处的 term,且肯定可以找到日志中该 term出现的第一个日志条目的下标,并置conflictIndex = firstIndexWithTerm;
- leader 收到返回体后,有可能找不到对应的 term,即 leader 和 follower 在conflictIndex处以及之后的日志都有冲突,都不能要了,直接置nextIndex = conflictIndex
- 若找到了对应的term,则找到对应term出现的最后一个日志条目的下一个日志条目,即置nextIndex = lastIndexWithTerm+1;这里其实是默认了若 leader 和 follower 同时拥有该 term 的日志,则不会有冲突,直接取下一个 term 作为日志发起就好,是源自于 5.4 safety 的安全性保证
如果还有冲突,leader 和 follower 会一直根据以上规则回溯 nextIndex
lab 2D 日志压缩与快照
随着时间推移,存储的日志会越来越多,不但占据很多磁盘空间,服务器重启做日志重放也需要更多的时间。如果没有办法来压缩日志,将会导致可用性问题:要么磁盘空间被耗尽,要么花费太长时间启动。所以日志压缩是必要的。
日志压缩的一般思路是,日志中的许多信息随着时间推移会变成过时的,可以丢弃。例如:一个将 x 设置为 2 的操作,如果在未来将 x 设置为了 3,那么 x=2 这个操作就过时了,可以丢弃。
例如,一个Raft节点当前日志序号范围是[0,100),对范围为 [0,50]日志进行快照后,日志范围就变成为[51,100)。如下图:
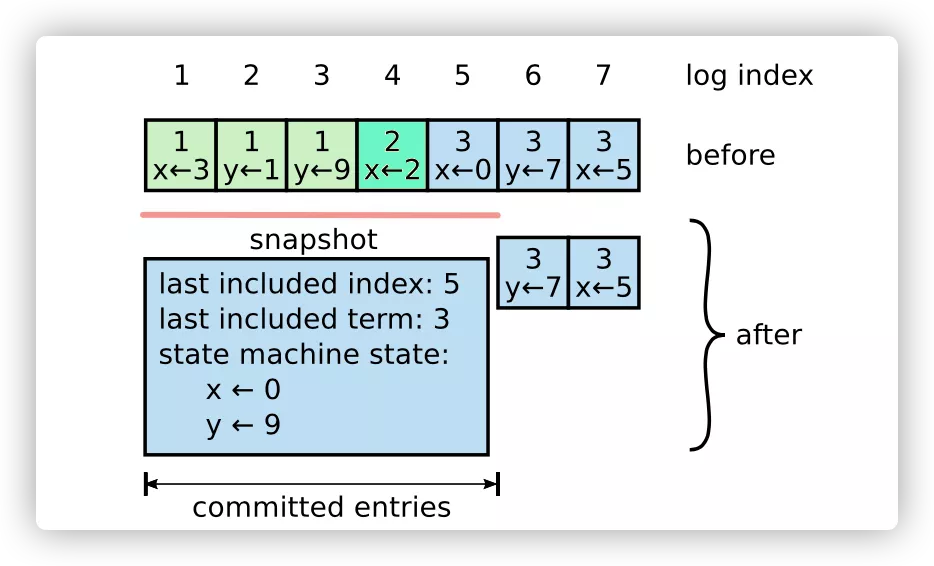
加入日志压缩功能后,需要注意及时对内存中的 entries 数组进行清除。即使得废弃的 entries 切片能够被正常 gc,从而避免内存释放不掉并最终 OOM 的现象出现,具体实现就是 shrinkEntriesArray 函数,具体原理可以参考此博客 。
何时快照?
- 服务端触发的日志压缩:上层应用发送快照数据给Raft实例。
- leader 发送来的 InstallSnapshot:领导者发送快照RPC请求给追随者。当raft收到其他节点的压缩请求后,先把请求上报给上层应用,然后上层应用调用
rf.CondInstallSnapshot()来决定是否安装快照
服务端触发的日志压缩
实现很简单,删除掉对应已经被压缩的 raft log 即可,同时,真正日志序号的在log切片序号为 index - firstIndex
func (rf *Raft) Snapshot(index int, snapshot []byte) {
rf.mu.Lock()
defer rf.mu.Unlock()
snapshotIndex := rf.getFirstLog().Index
if index <= snapshotIndex {
DPrintf("{Node %v} rejects replacing log with snapshotIndex %v as current snapshotIndex %v is larger in term %v", rf.me, index, snapshotIndex, rf.currentTerm)
return
}
rf.logs = shrinkEntriesArray(rf.logs[index-snapshotIndex:])
rf.logs[0].Command = nil
rf.persister.SaveStateAndSnapshot(rf.encodeState(), snapshot)
DPrintf("{Node %v}'s state is {state %v,term %v,commitIndex %v,lastApplied %v,firstLog %v,lastLog %v} after replacing log with snapshotIndex %v as old snapshotIndex %v is smaller", rf.me, rf.state, rf.currentTerm, rf.commitIndex, rf.lastApplied, rf.getFirstLog(), rf.getLastLog(), index, snapshotIndex)
}
leader 发送来的 InstallSnapshot
对于 leader 发过来的 InstallSnapshot,只需要判断 term 是否正确,如果无误则 follower 只能无条件接受。
此外,如果该 snapshot 的 lastIncludedIndex 小于等于本地的 commitIndex,那说明本地已经包含了该 snapshot 所有的数据信息,尽管可能状态机还没有这个 snapshot 新,即 lastApplied 还没更新到 commitIndex,但是 applier 协程也一定尝试在 apply 了,此时便没必要再去用 snapshot 更换状态机了。对于更新的 snapshot,这里通过异步的方式将其 push 到 applyCh 中。
对于服务上层触发的 CondInstallSnapshot,与上面类似,如果 snapshot 没有更新的话就没有必要去换,否则就接受对应的 snapshot 并处理对应状态的变更。注意,这里不需要判断 lastIncludeIndex 和 lastIncludeTerm 是否匹配,因为 follower 对于 leader 发来的更新的 snapshot 是无条件服从的。
// Follwer 接收 Leader日志快照 处理
func (rf *Raft) InstallSnapshot(request *InstallSnapshotRequest, response *InstallSnapshotResponse) {
rf.mu.Lock()
defer rf.mu.Unlock()
defer DPrintf("{Node %v}'s state is {state %v,term %v,commitIndex %v,lastApplied %v,firstLog %v,lastLog %v} before processing InstallSnapshotRequest %v and reply InstallSnapshotResponse %v", rf.me, rf.state, rf.currentTerm, rf.commitIndex, rf.lastApplied, rf.getFirstLog(), rf.getLastLog(), request, response)
response.Term = rf.currentTerm
if request.Term < rf.currentTerm {
return
}
if request.Term > rf.currentTerm {
rf.currentTerm, rf.votedFor = request.Term, -1
rf.persist()
}
rf.ChangeState(StateFollower)
rf.electionTimer.Reset(RandomizedElectionTimeout())
// outdated snapshot
if request.LastIncludedIndex <= rf.commitIndex {
return
}
go func() {
rf.applyCh <- ApplyMsg{
SnapshotValid: true,
Snapshot: request.Data,
SnapshotTerm: request.LastIncludedTerm,
SnapshotIndex: request.LastIncludedIndex,
}
}()
}
func (rf *Raft) CondInstallSnapshot(lastIncludedTerm int, lastIncludedIndex int, snapshot []byte) bool {
rf.mu.Lock()
defer rf.mu.Unlock()
DPrintf("{Node %v} service calls CondInstallSnapshot with lastIncludedTerm %v and lastIncludedIndex %v to check whether snapshot is still valid in term %v", rf.me, lastIncludedTerm, lastIncludedIndex, rf.currentTerm)
// outdated snapshot
if lastIncludedIndex <= rf.commitIndex {
DPrintf("{Node %v} rejects the snapshot which lastIncludedIndex is %v because commitIndex %v is larger", rf.me, lastIncludedIndex, rf.commitIndex)
return false
}
if lastIncludedIndex > rf.getLastLog().Index {
rf.logs = make([]Entry, 1)
} else {
rf.logs = shrinkEntriesArray(rf.logs[lastIncludedIndex-rf.getFirstLog().Index:])
rf.logs[0].Command = nil
}
// update dummy entry with lastIncludedTerm and lastIncludedIndex
rf.logs[0].Term, rf.logs[0].Index = lastIncludedTerm, lastIncludedIndex
rf.lastApplied, rf.commitIndex = lastIncludedIndex, lastIncludedIndex
rf.persister.SaveStateAndSnapshot(rf.encodeState(), snapshot)
DPrintf("{Node %v}'s state is {state %v,term %v,commitIndex %v,lastApplied %v,firstLog %v,lastLog %v} after accepting the snapshot which lastIncludedTerm is %v, lastIncludedIndex is %v", rf.me, rf.state, rf.currentTerm, rf.commitIndex, rf.lastApplied, rf.getFirstLog(), rf.getLastLog(), lastIncludedTerm, lastIncludedIndex)
return true
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号