MIT 6.824 Lab 1 - 实现 MapReduce
MIT 6.824 Lab 1 - 实现 MapReduce
本文章介绍MIT 6.824 Lab 1的实现,主要任务为采用GoLang实现MapReduce分布式计算框架。
完整的 Lab 说明可参阅链接 http://nil.csail.mit.edu/6.824/2021/labs/lab-mr.html 。
windows采用Goland+云服务器
本lab不推荐在window上做实验,推荐在linux,可以弄虚拟机或者直接搞一个服务器,个人推荐服务器,阿里云有学生优惠(做点题可以免费用六个月),华为云或者腾讯云可以免费用1个月。
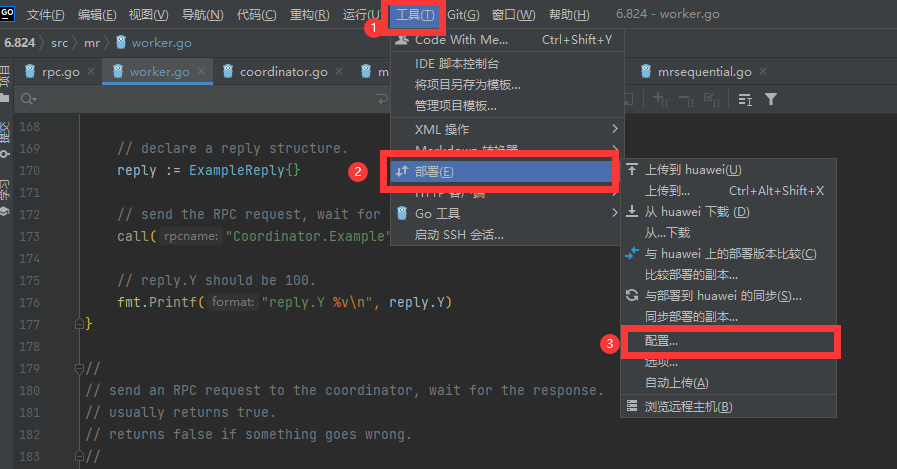
IDE编程写代码还是很爽的,Goland可以通过部署直接将任意代码文件传到服务器指定的路径下,然后再IDE下方用ssh连接到服务器
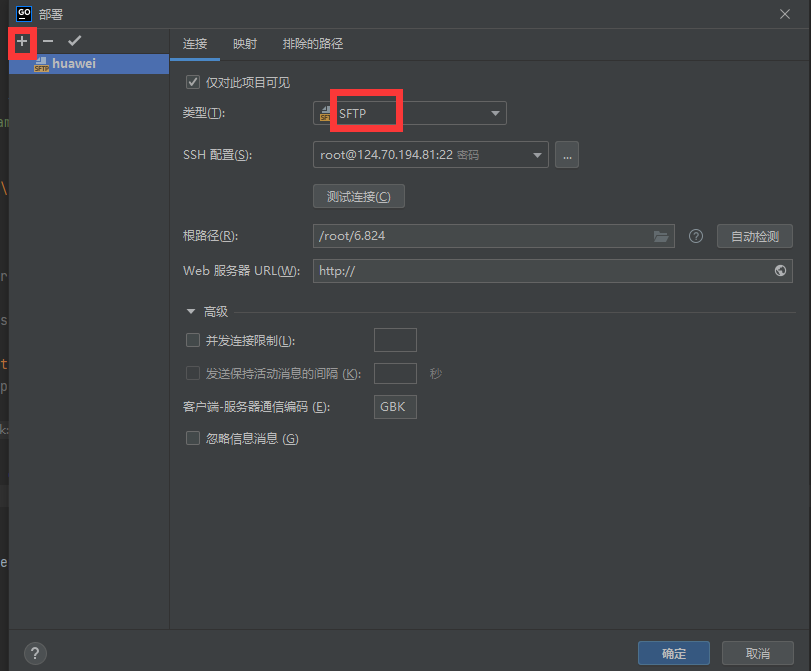
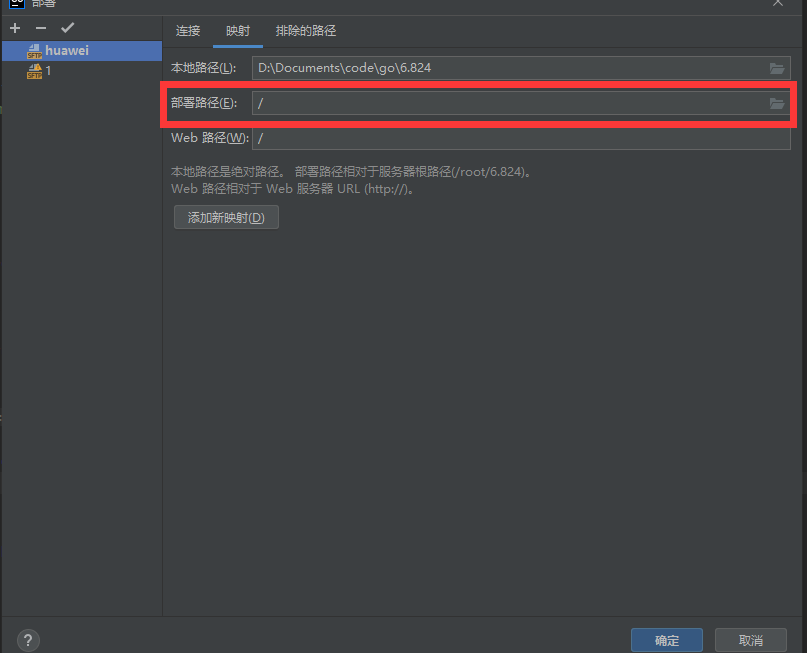
下面是配置Goland的"部署"的具体流程:
安装go环境
实验使用Go 1.15进行实验评分,以 root 或者其他 sudo 用户身份运行下面的命令,下载并且解压 Go 二进制文件到/usr/local目录:
wget -qO- https://golang.org/dl/go1.15.8.linux-amd64.tar.gz | sudo tar -xz -C /usr/local
但在国内连接不上,我是直接在浏览器打开网站 https://golang.org/dl/go1.15.8.linux-amd64.tar.gz ,把压缩包下载下来,然后在上传到服务区上,然后解压
tar -C /usr/local -zxvf go1.11.5.linux-amd64.tar.gz
国内也可以直接下载该版本的压缩包
wget -c https://dl.google.com/go/go1.15.8.linux-amd64.tar.gz -O - | sudo tar -xz -C /usr/local
加入环境变量
通过将 Go 目录添加到$PATH环境变量,系统将会知道在哪里可以找到 Go 可执行文件。
这个可以通过添加下面的行到/etc/profile文件(系统范围内安装)或者$HOME/.profile文件(当前用户安装):
export PATH=$PATH:/usr/local/go/bin
永久保存:
centos
保存文件,并且重新加载新的PATH 环境变量到当前的 shell 会话:
source /etc/profile
Ubuntun
将命令export PATH=$PATH:/usr/local/go/bin写入~/.bashrc 中,记得执行 source ~/.bashrc,来将修改应用到当前的bash环境下。
source ~/.bashrc
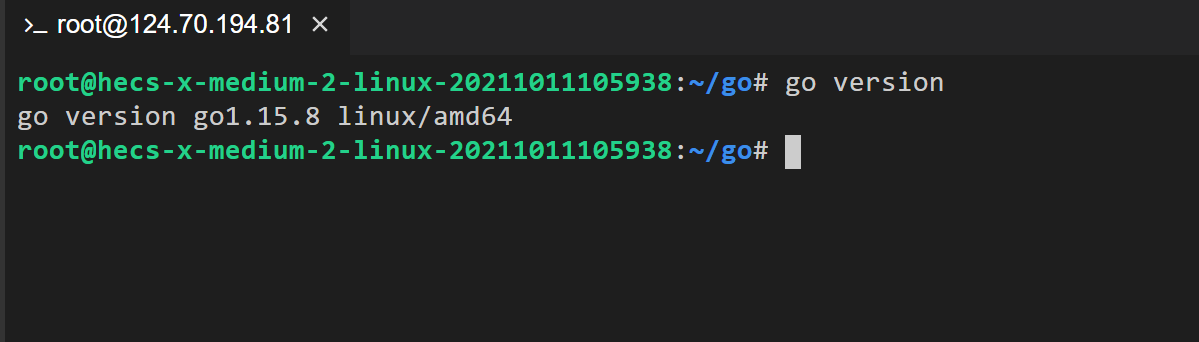
验证 Go 安装过程
通过打印 Go 版本号,验证安装过程。
go version
go语言入门(中文):https://tour.go-zh.org/welcome/1
非分布式实现
首先,我们通过 Git 获取 Lab 的初始代码:
git clone git://g.csail.mit.edu/6.824-golabs-2021 6.824
cd 6.824
初始代码中默认已经提供了 简单的单进程串行 的 MapReduce 参考实现,在 main/mrsequential.go 中。我们可以通过以下命令来试玩一下:
cd src/main go build -buildmode=plugin ../mrapps/wc.go rm mr-out* go run mrsequential.go wc.so pg*.txt more mr-out-0
输出文件在src/main/mr-out-0,文件中每一行标明了单词和出现次数。
go build -buildmode=plugin ../mrapps/wc.go该命令的作用是构建 MR APP 的动态链接库,使用了 Golang 的 Plugin 来构建 MR APP,使得 MR 框架的代码可以和 MR APP 的代码分开编译,而后 MR 框架再通过动态链接的方式载入指定的 MR APP 运行。
具体说:wc.go 实现了Map函数和Reduce函数,但Map和Reduce相当于基础性代码,我们可能会随时改变它,采用上述的动态链接,我们只需要改变wc.go, 然后编译成wc.so,
go run mrsequential.go wc.so pg*.txt这样就可以载入我们整体性架构了,其他架构代码不需要重新部署和运行。mrsequential.go中载入动态库(如,wc.so)代码为:
mapf, reducef := loadPlugin(os.Args[1])
在mrapps目录下提供其他的MR APP实现,几个文件都实现为map, reduce的函数,这两个函数在mrsequential.go中加载并调用。给mrsequential绑定不同的*.so文件,也就会加载不同的map, reduce函数。如此实现某种程度上的动态绑定。
mrsequential.go实现的非分布式的,具体实现很简单:文章提取单词,调用wc.so的Map函数返回一个数组,数组元素为<word1, 1>对,然后排序,然后同样的单词会挨在一起,这样就能某个单词收集到一个数组传到list即可,然后将list传到Reduce函数,最后返回的结果写入文件即可。
分布式实现(单机多进程并行)
一定要看一下lab: http://nil.csail.mit.edu/6.824/2021/labs/lab-mr.html 。
实验要点:
-
协调器和工作器的启动程序在
main/mrcoordinator.go和main/mrworker.go 中;不要更改这些文件。我们需要具体实现代码放在mr/coordinator.go、mr/worker.go和mr/rpc.go 中。可以采用下面命令初步调试我们的代码:
# 启动协调器,输入数据 go run mrcoordinator.go pg-*.txt # 启动工作器,加载动态链接库 go run mrworker.go wc.so -
实验架构:1个协调器和多个工作器,采用rpc通信:项目初始的时候举了一个例子,可以参考一下。
-
协调器Coordinator负责整体任务产生、分配(RPC)和清点(宕机:work超10秒未完成任务,任务重新分配)
-
工作器Worker负责申请任务(RPC)、完成任务
-
Worker超时未完成的话,Coordinator会把任务分配给其他worker,会产生两个Worker完成同一个任务,如果work直接将结果写入文件,会出现冲突。
对于上述第5点,我主要参考https://mr-dai.github.io/mit-6824-lab1/
参考了 Google MapReduce 的做法,Worker 在写出数据时可以先写出到临时文件,最终确认没有问题后再将其重命名为正式结果文件,区分开了 Write 和 Commit 的过程。Commit 的过程可以是 Coordinator 来执行,也可以是 Worker 来执行:
- Coordinator Commit:Worker 向 Coordinator 汇报 Task 完成,Coordinator 确认该 Task 是否仍属于该 Worker,是则进行结果文件 Commit,否则直接忽略
- Worker Commit:Worker 向 Coordinator 汇报 Task 完成,Coordinator 确认该 Task 是否仍属于该 Worker 并响应 Worker,是则 Worker 进行结果文件 Commit,再向 Coordinator 汇报 Commit 完成
这里两种方案都是可行的,各有利弊。我在我的实现中选择了 Coordinator Commit,因为它可以少一次 RPC 调用,在编码实现上会更简单,但缺点是所有 Task 的最终 Commit 都由 Coordinator 完成,在极端场景下会让 Coordinator 变成整个 MR 过程的性能瓶颈。
代码设计与实现
流程如下:
- Coordinator首先输入数据产生n个Map任务,开启一个类似服务器的响应函数
ApplyForTask RPC,等待work申请任务。 - Worker采用多进程模拟多台机器,用无限循环实现即可,Worker调用
ApplyForTask RPC申请任务,得到任务后完成任务,完成任务后继续申请新的任务。 - Coordinator接收到任务申请后,首先判断该Worker上一个任务有没有,如果有且任务记录是该orker(超时的话,应该被取消),记录完成任务的结果。然后分配新的任务。
- 完成MAP任务后,切换到REDUCE任务阶段即可,与上述流程一样
- Coordinator调用多线程完成任务清点工作,超时的任务重新分配
RPC
这里主要定义一些常用的函数和通信交互的结果,一开始可能想的不是全面,但在书写的过程中慢慢补充。
const (
MAP = "MAP"
REDUCE = "REDUCE"
DONE = "DONE"
)
// 一定要大写开头, 不然RPC通信过程中序列化/反序列化的时候可能找不到
// 任务描述
type Task struct {
Id int
Type string
MapInputFile string
WorkerId int
DeadLine time.Time
}
// 任务申请
type ApplyForTaskArgs struct {
WorkerId int
LastTaskId int
LastTaskType string
}
// 任务申请回复
type ApplyForTaskReply struct {
TaskId int
TaskType string
MapInputFile string
NReduce int
NMap int
}
文件的保存的名字
func tmpMapOutFile(workerId int, mapId int, reduceId int) string {
return fmt.Sprintf("tmp-worker-%d-%d-%d", workerId, mapId, reduceId)
}
func finalMapOutFile(mapId int, reduceId int) string {
return fmt.Sprintf("mr-%d-%d", mapId, reduceId)
}
func tmpReduceOutFile(workerId int, reduceId int) string {
return fmt.Sprintf("tmp-worker-%d-out-%d", workerId, reduceId)
}
func finalReduceOutFile(reduceId int) string {
return fmt.Sprintf("mr-out-%d", reduceId)
}
woker
主要代码是不断循环向coordinator请求工作,
MapTask的实现流程:
- 读取reply的文件内容
- 传递动态链接的mapf函数,得到中间加过:数字,元素<word,1>
- 将中间结果
Key的Hash值%nReduc进行分配,实际就是相同的单词给同一个Reduce任务分配,产生结果保存到文件中
ReduceTask的实现流程:
- 读取该Reduce编号的中间结果文件数据
- 对所有中间结果进行排序,相同的单词就挨在一起
- 将相同的单词抽取成一个list,传到动态链接的reducef函数,得到word个数(规范化),保存到Reduce的中间结果文件
// 不断循环向coordinator请求工作
func Worker(mapf func(string, string) []KeyValue, reducef func(string, []string) string) {
// 单机运行,直接使用 PID 作为 Worker ID,方便 debug
id := os.Getpid()
log.Printf("Worker %d 开始工作:\n", id)
lastTaskId := -1
lastTaskType := ""
for {
args := ApplyForTaskArgs{
WorkerId: id,
LastTaskId: lastTaskId,
LastTaskType: lastTaskType,
}
reply := ApplyForTaskReply{}
call("Coordinator.ApplyForTask", &args, &reply)
switch reply.TaskType {
case "":
log.Printf("接收到所有任务完成信号!")
goto End
case MAP:
doMapTask(id, reply.TaskId, reply.MapInputFile, reply.NReduce, mapf)
case REDUCE:
doReduceTask(id, reply.TaskId, reply.NMap, reducef)
}
lastTaskId = reply.TaskId
lastTaskType = reply.TaskType
log.Printf("完成 %s 任务 %d", reply.TaskType, reply.TaskId)
}
End:
log.Printf("Worker %d 结束工作\n", id)
// Your worker implementation here.
// uncomment to send the Example RPC to the coordinator.
// CallExample()
}
func doMapTask(id int, taskId int, fileName string, nReduce int, mapf func(string, string) []KeyValue) {
// 读入输入数据
file, err := os.Open(fileName)
if err != nil {
log.Fatalf("%s 文件打开失败!", fileName)
}
content, err := ioutil.ReadAll(file)
if err != nil {
log.Fatalf("%s 文件内容读取失败!", fileName)
}
file.Close()
kva := mapf(fileName, string(content))
hashedKva := make(map[int][]KeyValue)
for _, kv := range kva {
hashed := ihash(kv.Key) % nReduce
hashedKva[hashed] = append(hashedKva[hashed], kv)
}
for i := 0; i < nReduce; i++ {
outFile, _ := os.Create(tmpMapOutFile(id, taskId, i))
for _, kv := range hashedKva[i] {
fmt.Fprintf(outFile, "%v\t%v\n", kv.Key, kv.Value)
}
outFile.Close()
}
}
func doReduceTask(id int, taskId int, nMap int, reducef func(string, []string) string) {
var lines []string
for i := 0; i < nMap; i++ {
file, err := os.Open(finalMapOutFile(i, taskId))
if err != nil {
log.Fatalf("文件 %s 打开失败!", finalMapOutFile(i, taskId))
}
content, err := ioutil.ReadAll(file)
if err != nil {
log.Fatalf("文件 %s 读取失败!", finalMapOutFile(i, taskId))
}
lines = append(lines, strings.Split(string(content), "\n")...)
}
var kva []KeyValue
for _, line := range lines {
if strings.TrimSpace(line) == "" {
continue
}
split := strings.Split(line, "\t")
kva = append(kva, KeyValue{
Key: split[0],
Value: split[1],
})
}
sort.Sort(ByKey(kva))
outFile, _ := os.Create(tmpReduceOutFile(id, taskId))
i := 0
for i < len(kva) {
j := i + 1
for j < len(kva) && kva[j].Key == kva[i].Key {
j++
}
var values []string
for k := i; k < j; k++ {
values = append(values, kva[k].Value)
}
output := reducef(kva[i].Key, values)
fmt.Fprintf(outFile, "%v %v\n", kva[i].Key, output)
i = j
}
outFile.Close()
}
Coordinator
Coordinator的结构
type Coordinator struct {
// Your definitions here.
lock sync.Mutex // 锁
stage string // 目前任务状态:MAP REDUCE DONE
nMap int // MAP任务数量
nReduce int // Reduce任务数量
tasks map[string]Task // 任务映射,主要是查看任务状态
toDoTasks chan Task // 待完成任务,采用通道实现,内置锁结构
}
Coordinator构造函数,实现功能:初始化和产生MAP任务,开启另一个线程循环扫描任务状态
func MakeCoordinator(files []string, nReduce int) *Coordinator {
c := Coordinator{
stage: MAP,
nMap: len(files),
nReduce: nReduce,
tasks: make(map[string]Task),
toDoTasks: make(chan Task, int(math.Max(float64(len(files)), float64(nReduce)))),
}
// Your code here.
for i, file := range files {
task := Task{
Id: i,
Type: MAP,
WorkerId: -1,
MapInputFile: file,
}
log.Printf("Type: %s", task.Type)
c.tasks[crateTaskId(task.Type, task.Id)] = task
c.toDoTasks <- task
}
log.Printf("Coordinator start\n")
c.server()
// 多线程启动回收机制,回收超时任务
go func() {
for {
time.Sleep(500 * time.Millisecond)
c.lock.Lock()
for _, task := range c.tasks {
if task.WorkerId != -1 && time.Now().After(task.DeadLine) {
log.Printf("%d 运行任务 %s %d 出现故障,重新收回!", task.WorkerId, task.Type, task.Id)
task.WorkerId = -1
c.toDoTasks <- task
}
}
c.lock.Unlock()
}
}()
return &c
}
任务完成、可用 Task 获取与分配
func (c *Coordinator) ApplyForTask(args *ApplyForTaskArgs, reply *ApplyForTaskReply) error {
// 记录woker的上一个任务完成
if args.LastTaskId != -1 {
c.lock.Lock()
taskId := crateTaskId(args.LastTaskType, args.LastTaskId)
// 这里才产生最后的输出结果,是因为怕超时worker和合法worker都写入,造成冲突
if task, ok := c.tasks[taskId]; ok && task.WorkerId == args.WorkerId { // 加后一个条件原因是莫个work出现故障,要被回收
log.Printf("%d 完成 %s-%d 任务", args.WorkerId, args.LastTaskType, args.LastTaskId)
if args.LastTaskType == MAP {
for i := 0; i < c.nReduce; i++ {
err := os.Rename(
tmpMapOutFile(args.WorkerId, args.LastTaskId, i),
finalMapOutFile(args.LastTaskId, i))
if err != nil {
log.Fatalf(
"Failed to mark map output file `%s` as final: %e",
tmpMapOutFile(args.WorkerId, args.LastTaskId, i), err)
}
}
} else if args.LastTaskType == REDUCE {
err := os.Rename(
tmpReduceOutFile(args.WorkerId, args.LastTaskId),
finalReduceOutFile(args.LastTaskId))
if err != nil {
log.Fatalf(
"Failed to mark reduce output file `%s` as final: %e",
tmpReduceOutFile(args.WorkerId, args.LastTaskId), err)
}
}
delete(c.tasks, taskId)
if len(c.tasks) == 0 {
c.cutover()
}
}
c.lock.Unlock()
}
// 获取一个可用的Task并返回
task, ok := <-c.toDoTasks
// 通道关闭,代表整个MR作业已经完成,通知Work退出
if !ok {
return nil
}
c.lock.Lock()
defer c.lock.Unlock()
log.Printf("Assign %s task %d to worker %dls"+
"\n", task.Type, task.Id, args.WorkerId)
// 更新task
task.WorkerId = args.WorkerId
task.DeadLine = time.Now().Add(10 * time.Second)
c.tasks[crateTaskId(task.Type, task.Id)] = task
// 给work返回数据
reply.TaskId = task.Id
reply.TaskType = task.Type
reply.MapInputFile = task.MapInputFile
reply.NMap = c.nMap
reply.NReduce = c.nReduce
return nil
}
运行阶段的切换
func (c *Coordinator) cutover() {
if c.stage == MAP {
log.Printf("所有的MAP任务已经完成!开始REDUCE任务!")
c.stage = REDUCE
for i := 0; i < c.nReduce; i++ {
task := Task{Id: i, Type: REDUCE, WorkerId: -1}
c.tasks[crateTaskId(task.Type, i)] = task
c.toDoTasks <- task
}
} else if c.stage == REDUCE {
log.Printf("所有的REDUCE任务已经完成!")
close(c.toDoTasks)
c.stage = DONE
}
}
完成任务体现
func (c *Coordinator) Done() bool {
// Your code here.
c.lock.Lock()
ret := c.stage == DONE
defer c.lock.Unlock()
return ret
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号