MIT 6.824 Lecture 01 MapReduce.md
分布式系统概要
分布式系统是什么
分布式系统的核心是通过网络来协调,共同完成一致任务的 一些计算机,比如大型网站存储,MapReduce 算法,点对点文件系统
为什么构建分布式系统
- 获得更好的并发性,高计算性能
- 多台主机容错,可以进行故障切换
- 很多主机都是分布在世界各地的,物理环境导致必须构建分布式系统
- 更安全,让不信任的代码运行在另一台主机上
分布式系统的挑战
很多主机并发执行程序,会很复杂
很多意想不到的错误,如网络问题,数据不一致的问题
多台计算机,性能问题
课程会涉及网络应用的基础设施
存储
通信
计算
课程还会提到哪些技术
RPC
多线程
并发控制
分布式的话题
性能,可扩展性
用两倍的机器获得两倍的性能,扩展性并不一定能带来性能的提升
容错
如果你的系统是由千万台主机构建的,那出现主机泵机的可能性很高容错,可用性
自身可恢复性
以上可以通过非易失性存储和数据备份来实现
- 数据一致性
因为分布式系统中,数据会存有很多副本,所以会有副本之间数据不一致的问题
MapReduce
参考资料:
论文:https://pdos.csail.mit.edu/6.824/papers/mapreduce.pdf
中文版本:https://zhuanlan.zhihu.com/p/122571315
MapReduce介绍
Google MapReduce 是一种编程模型,所执行的分布式计算会以一组键值对作为输入,输出另一组键值对,用户则通过编写 Map 函数和 Reduce 函数来指定所要进行的计算。
map (k1, v1) ->list(k2, v2)
reduce (k2, list(v2)) -> list(v2)
课程中老师对MapReduce的讲解:
举个例子:给定大量的文档,计算其中每个单词出现的次数(Word Count)。用户通常需要提供形如如下伪代码的代码来完成计算:
map(String key, String value):
// key: document name
// value: document contents
for each word w in value:
EmitIntermediate(w, “1”);
reduce(String key, Iterator values):
// key: a word
// values: a list of counts
int result = 0;
for each v in values:
result += ParseInt(v);
Emit(AsString(result));
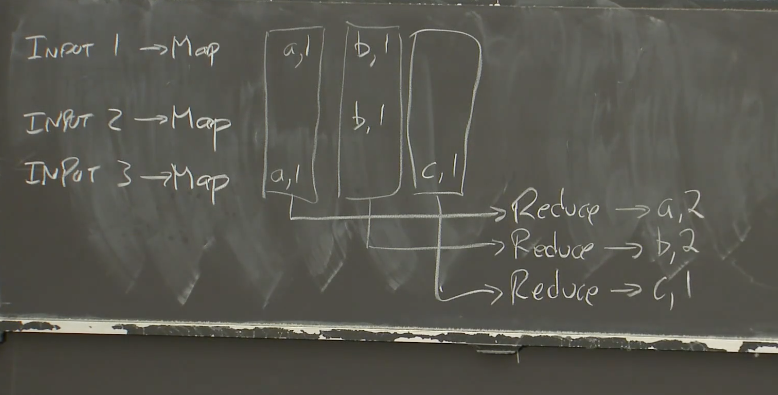
函数式编程模型
MapReduce 所采用的编程模型源自于函数式编程里的 Map 函数和 Reduce 函数。后起之秀 Spark 同样采用了类似的编程模型。
使用函数式编程模型的好处在于这种编程模型本身就对并行执行有良好的支持,这使得底层系统能够轻易地将大数据量的计算并行化,同时由用户函数所提供的确定性也使得底层系统能够将函数重新执行作为提供容错性的主要手段。
MapReduce 计算执行过程
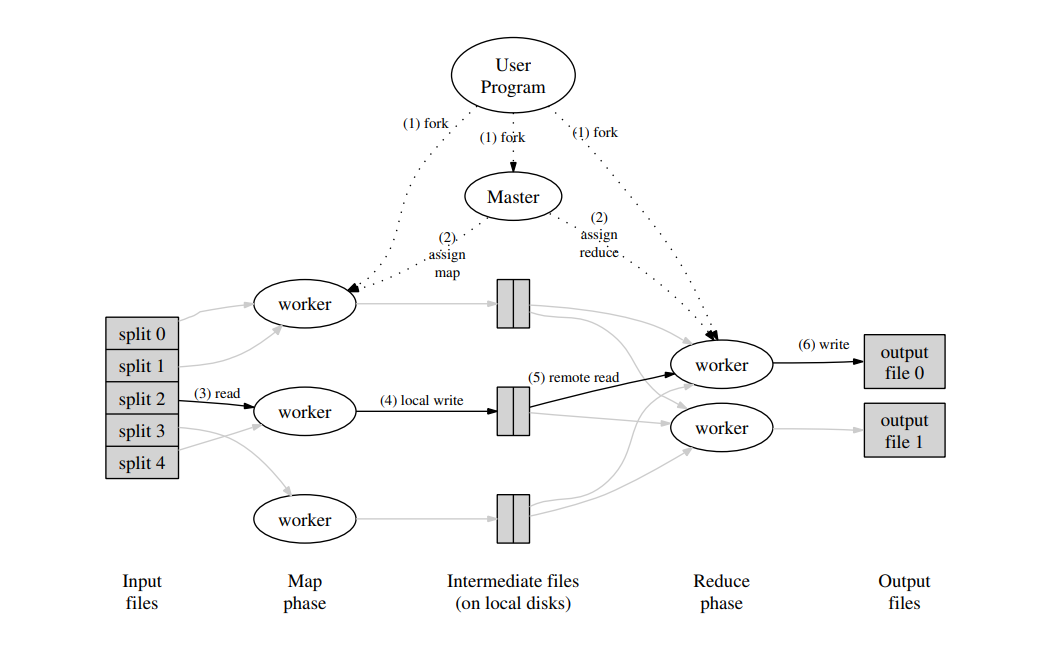
首先,用户通过 MapReduce 客户端指定 Map 函数和 Reduce 函数,以及此次 MapReduce 计算的配置,包括中间结果键值对的 Partition 数量 R 以及用于切分中间结果的哈希函数 hash。
用户开始 MapReduce 计算后,整个 MapReduce 计算的流程可总结如下:
- 作为输入的文件会被分为 M 个 Split,每个 Split 的大小通常在 16~64 MB 之间
- 如此,整个 MapReduce 计算包含 M 个Map 任务和 R 个 Reduce 任务。Master 结点会从空闲的 Worker 结点中进行选取并为其分配 Map 任务和 Reduce 任务
- 收到 Map 任务的 Worker 们(又称 Mapper)开始读入自己对应的 Split,将读入的内容解析为输入键值对并调用由用户定义的 Map 函数。由 Map 函数产生的中间结果键值对会被暂时存放在缓冲内存区中
- 在 Map 阶段进行的同时,Mapper 们周期性地将放置在缓冲区中的中间结果存入到自己的本地磁盘中,同时根据用户指定的 Partition 函数(默认为 hash(key) mod R)将产生的中间结果分为 R 个部分。任务完成时,Mapper 便会将中间结果在其本地磁盘上的存放位置报告给 Master
- Mapper 上报的中间结果存放位置会被 Master 转发给 Reducer。当 Reducer 接收到这些信息后便会通过 RPC 读取存储在 Mapper 本地磁盘上属于对应 Partition 的中间结果。在读取完毕后,Reducer 会对读取到的数据进行排序以令拥有相同键的键值对能够连续分布
- 之后,Reducer 会为每个键收集与其关联的值的集合,并以之调用用户定义的 Reduce 函数。Reduce 函数的结果会被放入到对应的 Reduce Partition 结果文件
实际上,在一个 MapReduce 集群中,Master 会记录每一个 Map 和 Reduce 任务的当前完成状态,以及所分配的 Worker。除此之外,Master 还负责将 Mapper 产生的中间结果文件的位置和大小转发给 Reducer。
值得注意的是,每次 MapReduce 任务执行时,M 和 R 的值都应比集群中的 Worker 数量要高得多,以达成集群内负载均衡的效果。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号