Java中char和String 的深入理解 - 字符编码
出处:https://blog.csdn.net/u010297957/article/details/48495791
开篇
我们并不是在写代码,我们只是将自己的思想通过代码表达出来!
1 将思维变现成为一行代码,是从抽象思维到具体代码的编码过程;继而计算机再将我们的代码再解码为计算机能处理的形式--2进制数字。
2 当计算机需要向你展示数据时它还需要将2进制数字参照一定的规则(码表)编码为人所能理解的格式。
如果不能清楚的理解编码和解码的原理和规则,我想作为程序猿的你是一定会善罢甘休的吧。哈哈,请随我的思路一起,让我们知其所以然吧!
我们这里只讨论狭义的计算机字符编码问题,以下论述都是基于此条件之下,才疏学浅,如有错误请同学们不吝赐教哦。
字符编码
1 总论
What/定义:编码是信息从一种形式或格式转换为另一种形式的过程,而解码是其逆过程。
Why/为什么需要编码:见开篇。
How/怎么编码:人们发明了很多码表,编码和解码实际上就是在查不同的码表(好像字典)的过程。
2 码表
2.1 祖宗:ASCII(American Standard Code for Information Interchange,美国标准信息交换代码),这是个单字节编码表,它能最多能表示256个字符(但实际上只用了7bit,128个。ISO8859-1使用8bit来表示,能表示256)。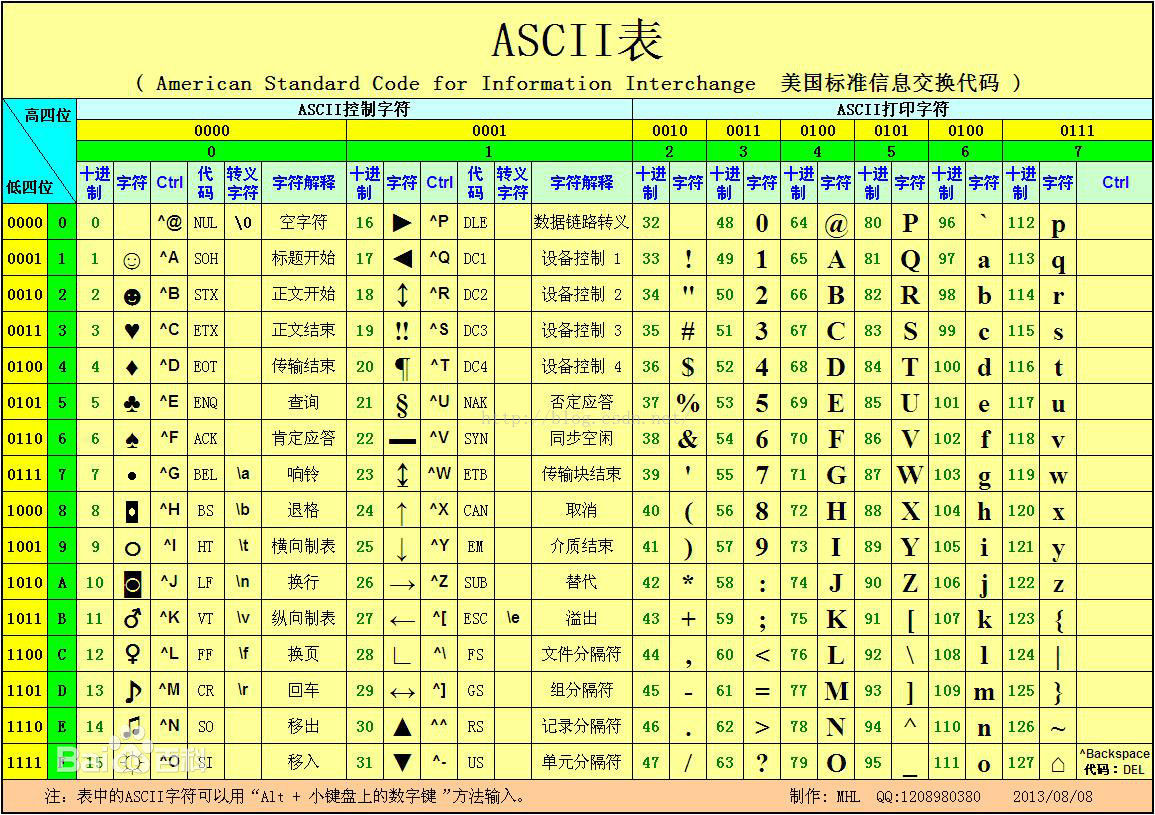
2.2 Unicode
1 历史到今天
1 随着时间的发展,其它语言的人民也需要使用计算机,也需要编码自己的语言,很多国家和地区就各自使用了2个字节来表示自己的文字编码,如GBK、BIG5等。这种方式当然会造成不同语言编码和解码的混乱和错误,人们意识到需要一个统一的码表来囊括世界上所有的字符,从而实现编码的统一。
2 九十年代左右有两个组织分别做了两个码表要做统一,ISO的UCS 10646(Universal Character Set,UCS)和统一码联盟的Unicode。
但我们不需要两个不兼容的统一字符集,在1991年前后,他们终于联合起来共同维护一个标准了(他们还是各自发展,但字符集统一),从Unicode2.0开始,采用与ISO10646-1相同的字库和字码。两者目前兼容发展着。
3 UCS和Unicode使用最大32bit来表示字符,可以表示42亿个字符(4,294,967,296),目前只使用了1,114,112个码位,从0x0~0x10FFFF。
它们为了和不同的区域性字符集相互兼容,把其首256字符使用ISO8859-1所定义的字符,并把大量字符重复编到不同的字符码位置,从而使得旧有的纷繁复杂的编码方式得以和Unicode编码直接互相转换,而不会丢失任何信息。
(摘抄自其它资料,这点我存疑:事实上我发现它只向下兼容8859-1,并且只有使用UTF-8转换格式时才行,直接使用Unicode==UTF-16还是错误结果。错误原因在下边UTF那有描述)
4 UCS-4为4字节,它根据最高位为0的最高那1个字节,表示出2的7次方128个group,然后每个group根据此高字节分为256个plane,每个plane根据根据第3个字节分为256个row,每row有256个cell。group 0的plane 0 称为BMP(Basic Multilingual Plane)。
如果UCS-4的前2个字节全零(也就是用了plane 0),那么将UCS-4的BMP去掉前两个0字节就得到了UCS-2.
1 128group 256plane 256 row 256 cell 2 0000 0000,0000 0000,0000 0000,0000 0000
5 Unicode计划使用17个平面,一共有17*65535=1,114,112个码位。在Unicode5.0中,已定义的码位只有238,605个,分布在plane0,1,2,14,15,16中。15,16只是定义了65534个码位专用区(Private Use Area),分别是0xF0000~0xFFFFD和0x100000~0x10FFFD。专用区PUA:留给大家放自定义字符的区域。
plane 0也有一个专用区:0xE000~0xF8FF,共6400个码位。它还有代理区(Surrogate)0xD800~0xDFFF(55296~57343),共2048个码位。代理区的目的是:用两个UTF-16字符表示BMP之外的字符。
238605-65535*2-6400-2048=99,089。这9万多个字符定义在plane 0(52080),1(3419),2(43253),14(337)上。有71,226个汉字,plane 2的43253都是汉字,plane0上定义了27973个汉字。
6 Unicode3.1开始使用辅助plane,2015年6月17号Unicode发布8.0
Unicode Version 8.0 Released (2015.06.17)
目前的Unicode码表区段
1 0000..007F; Basic Latin 2 0080..00FF; Latin-1 Supplement 3 0100..017F; Latin Extended-A 4 0180..024F; Latin Extended-B 5 0250..02AF; IPA Extensions 6 02B0..02FF; Spacing Modifier Letters 7 0300..036F; Combining Diacritical Marks 8 0370..03FF; Greek 9 0400..04FF; Cyrillic 10 0530..058F; Armenian 11 0590..05FF; Hebrew 12 0600..06FF; Arabic 13 0700..074F; Syriac 14 0780..07BF; Thaana 15 0900..097F; Devanagari 16 0980..09FF; Bengali 17 0A00..0A7F; Gurmukhi 18 0A80..0AFF; Gujarati 19 0B00..0B7F; Oriya 20 0B80..0BFF; Tamil 21 0C00..0C7F; Telugu 22 0C80..0CFF; Kannada 23 0D00..0D7F; Malayalam 24 0D80..0DFF; Sinhala 25 0E00..0E7F; Thai 26 0E80..0EFF; Lao 27 0F00..0FFF; Tibetan 28 1000..109F; Myanmar 29 10A0..10FF; Georgian 30 1100..11FF; Hangul Jamo 31 1200..137F; Ethiopic 32 13A0..13FF; Cherokee 33 1400..167F; Unified Canadian Aboriginal Syllabics 34 1680..169F; Ogham 35 16A0..16FF; Runic 36 1780..17FF; Khmer 37 1800..18AF; Mongolian 38 1E00..1EFF; Latin Extended Additional 39 1F00..1FFF; Greek Extended 40 2000..206F; General Punctuation 41 2070..209F; Superscripts and Subscripts 42 20A0..20CF; Currency Symbols 43 20D0..20FF; Combining Marks for Symbols 44 2100..214F; Letterlike Symbols 45 2150..218F; Number Forms 46 2190..21FF; Arrows 47 2200..22FF; Mathematical Operators 48 2300..23FF; Miscellaneous Technical 49 2400..243F; Control Pictures 50 2440..245F; Optical Character Recognition 51 2460..24FF; Enclosed Alphanumerics 52 2500..257F; Box Drawing 53 2580..259F; Block Elements 54 25A0..25FF; Geometric Shapes 55 2600..26FF; Miscellaneous Symbols 56 2700..27BF; Dingbats 57 2800..28FF; Braille Patterns 58 2E80..2EFF; CJK Radicals Supplement 59 2F00..2FDF; Kangxi Radicals 60 2FF0..2FFF; Ideographic Description Characters 61 3000..303F; CJK Symbols and Punctuation 62 3040..309F; Hiragana(日文平假名) 63 30A0..30FF; Katakana(日文片假名) 64 3100..312F; Bopomofo 65 3130..318F; Hangul Compatibility Jamo 66 3190..319F; Kanbun 67 31A0..31BF; Bopomofo Extended 68 3200..32FF; Enclosed CJK Letters and Months 69 3300..33FF; CJK Compatibility 70 3400..4DB5; CJK Unified Ideographs Extension A 71 4E00..9FFF; CJK Unified Ideographs 72 A000..A48F; Yi Syllables 73 A490..A4CF; Yi Radicals 74 AC00..D7A3; Hangul Syllables 75 D800..DB7F; High Surrogates 76 DB80..DBFF; High Private Use Surrogates 77 DC00..DFFF; Low Surrogates 78 E000..F8FF; Private Use 79 F900..FAFF; CJK Compatibility Ideographs 80 FB00..FB4F; Alphabetic Presentation Forms 81 FB50..FDFF; Arabic Presentation Forms-A 82 FE20..FE2F; Combining Half Marks 83 FE30..FE4F; CJK Compatibility Forms 84 FE50..FE6F; Small Form Variants 85 FE70..FEFE; Arabic Presentation Forms-B 86 FEFF..FEFF; Specials 87 FF00..FFEF; Halfwidth and Fullwidth Forms 88 FFF0..FFFD; Specials 89 10300..1032F; Old Italic 10330..1034F; Gothic 90 10400..1044F; Deseret 91 1D000..1D0FF; Byzantine Musical Symbols 92 1D100..1D1FF; Musical Symbols 93 1D400..1D7FF; Mathematical Alphanumeric Symbols 94 20000..2A6D6; CJK Unified Ideographs Extension B 95 2F800..2FA1F; CJK Compatibility Ideographs Supplement 96 E0000..E007F; Tags 97 F0000..FFFFD; Private Use 98 100000..10FFFD; Private Use
最常用的CJK(Chinese Japanese Korean 中日韩文)区间段是4E00~9FFF,但9FA6~9FFF还是空的,所以实际有值得是4E00~9FA5,这也是大部分人判断中文所用的区段。但大家要知道,其实CJK大部分是描述的中文,日文和韩文还有相应的区间。上表中带有CJK的、平假名Hiragana、片假名Katakana、朝鲜文Hangul的都是中日韩文可能的字符区间:
CJK Unified Ideographs
只是常用的区间,全部CJK区间应该是:
2E80..2EFF(11904-12031): CJK Radicals Supplement 3000..303F(12288-12351): CJK Symbols and Punctuation 3040..309F(12352-12447): Hiragana(日文平假名) 30A0..30FF(12448-12543): Katakana(日文片假名) 3130..318F(12592-12687): Hangul Compatibility Jamo(朝鲜文兼容字母) 31F0..31FF(12784-12799): Katakana Phonetic Extensions(日文片假名语音括展) 3200..32FF(12800-13055): Enclosed CJK Letters and Months 3300..33FF(13056-13311): CJK Compatibility 3400..4DB5(13312-19893): CJK Unified Ideographs Extension A 4E00..9FFF(19968-40959): CJK Unified Ideographs AC00..D7AF(44032-55215): Hangul Syllables(朝鲜文音节) F900..FAFF(63744-64255): CJK Compatibility Ideographs FE30..FE4F(65072-65103): CJK Compatibility Forms 20000..2A6D6(131072-173782): CJK Unified Ideographs Extension B 2F800..2FA1F(194560-195103): CJK Compatibility Ideographs Supplement
Unicode/UCS总结:
也就是说它用2~4个字节的空间描述了已知的接近全部的字符(并且仍在更新,还会把笑脸之类的字符也放入其中),而通常使用的plane 0也就是UCS-2,使用2个字节描述了比较常用的字符,包括大量的CJK文字,所以大家平常能用到的字符大体都在UCS-2中包括了。
2 UTF
1 UTF(UCS/Unicode/Universal Transformation Format)有多种transform方式,常见的有UTF-8/UTF-16/UTF-32。出现原因:
a:事实证明,对可以使用ASCII表示的字符使用Unicode并不高效,因为Unicode使用2个字节。为了解决这个问题,出现了一些中间格式字符集,被称为通用转换格式。可以这么说Unicode是编码方式,它规定了编码(即哪个字符在什么码位),而UTF-8等是Unicode的实现方式,它出于节省空间或其它目的来对Unicode所占空间进行转换。
b:另外我目前的理解是:Unicode码原生不支持与任何码表兼容,包括ASCII。
举例:UCS-2以2字节为单位而ASCII以1个字节为单位,试想英文a,0110,0001和0000,0000 0110,0001计算机是不会认为他们是一样的。而如果使用UTF-8那么,编码就会相同为1个字节0110,0001。
2 UTF-8(将8bit看作一个单位):使用1~4个字节来编码,如,当时用UTF-8存储ASCII字符时就只用1个字节,相似其它字符按一定算法转换为1~4个字节。算法如下
1 UCS-2编码(16进制) UTF-8 字节流(二进制) 2 0000 - 007F 0xxxxxxx 3 0080 - 07FF 110xxxxx 10xxxxxx 4 0800 - FFFF 1110xxxx 10xxxxxx 10xxxxxx
比如“汉”字的Unicode是6C49,那么就需要使用3字节的格式,写出来是1110 0110,1011 0001,1000 1001,也即E6 B1 89。4字节算法没写。
3 UTF-16
3.1 将16bit看作一个单位。设计之初为固定宽度的16bit(2byte)编码格式(可以表示plane 0所有),随着时间发展为了支持增补字符(其它plane)设置了代理对机制(surrogate pair);把范围U+10,0000~U+10,FFFF内的字符使用一对(2个)16bit来表示。
算法如下:对于的UCS码的小于0x10000的部分(plane 0中的),UTF-16编码==UCS-2对应的16位无符号整数。不小于0x10000的部分使用代理对(具体怎么代理不探究了)。
3.2 UCS-2是一个编码方案,而UTF-16是一个实际使用的转换格式。因为UTF-16一个单元是16bit,但计算机只能表示8bit为单位,所以分解(解析显示时)这个单元时这两个8bit谁先谁后就也有说法了(即一个单位中2个字节的字节顺序问题),高字节到低字节称为大尾big-endian,反之称为小尾little-endian。UTF-32也需要考虑这个问题,而UTF-8已8bit为单位,故而没有在单位中排字节顺序的需要。
例如:已知“乙”的Unicode编码是4E 59,当我们收到一个“奎”的Unicode编码59 4E时,我们是该翻译为奎还是乙呢?
解决方案:
1 使用Unicode的推荐字节顺序标记方法BOM(Byte Order Mark)。 2 它的方法是:UCS中有个字符叫"ZERO WIDTH NO-BREAK SPACE",它编码为FE FF,还有个字符FF FE在UCS中不存在。 3 UCS规范建议我们在传输字节流最前,先传输字符FE FF表明字节流是Big-Endian;传输FF FE表明字节流是Little-Endian。
UTF-8不需要用BOM来表明字节顺序,但是可以用BOM来表明编码方式。字符"ZERO WIDTH NO-BREAK SPACE"的UTF-8编码是EF BB BF。如果接受到已此开头的字节流,那么好了,你知道它是UTF-8编码的。
“你好”的Unicode编码:4F 60 , 59 7D
下图是用UTF-8编码的文本:“你好”两个字的编码。
使用UTF-16 Big-endian的“你好”

3.3 比起UTF-8,16的好处在于大部分字符都是用固定长度(2byte)存储(如果长度固定是你的要求的话)。
2.3 中国
GB GB2312 GBK 是国标以及其扩展码表。占用双字节。
BIG5是台湾/香港使用的繁体字符集。
GBK总体范围为:0x8140~0xFEFE,首字母在0x81~0xFE之间,尾字节在0x40~0xFE之间,剔除0x**7F一条线,总计23940个码位,收入21886个汉字(21003)和图形符号(883)。
实际应用
1 所有浏览器或客户端使用http协议请求一个资源时,资源的响应一般都会有个Content-Type来表示服务器资源的类型,浏览器/客户端根据此来对照相应码表解码显示。注意:有时候服务器不返回这个字段,那么大部分浏览器会相应的规则去自己算应该用哪个编码来显示(我并不清楚,大概是有BOM就按照使用对应UTF格式,无BOM使用ISO-8859-1吧?)。
2 考虑到国际化的软件发展趋势,建议不要使用GB家族的编码。
3 传输UTF编码字节流时,使用BOM;
JAVA
好了,我是Java程序员,我只为了理解《Tinking in java》中的一句话才搞了一天时间来研究这个问题的,好在还是有点成果!!
“java中有个基本类型char,它占用固定的2byte空间来表示字符,又因为java设计之初就采用了Unicode编码,所以char能表示所有字符包括中文。”
看到满世界这样的答案,我就不相信了!2字节最多只能标识65536个字符,它是怎么能囊括那么多字符的呢??仅所有汉字就不止6万吧!!!!
好了,不管你看没看完上边的文章,我告诉你结论就好!
结论
1. char
java中的char确实使用2Byte空间,它实际使用的是UCS-2 也就是plane 0,只能表述65536个字符,对于超出其范围的其它plane内容,请看下图:

一旦你使用了大于UCS-2的字符,那么编译器会直接报错!
其实也就是说char使用的是UTF-16格式。有个建议是尽量别用char类型,因为它会导致一些隐蔽的错误。比如,当你在用String时你定义了一个“虫”,你想当然的认为一个char就能盛放String中的一个字符(毕竟char是字符,而String就是描述的char数组),但是你会发现其实这个String的length()是2而不是1,因为它超出了UCS-2,String用两个char的位置(4字节)来表示了这个char,而String本该用一个char的位置来表示它才对。
2. String
首先,String能够支持的字符与你写代码时选择的编码方式有关,当你选择UTF编码时,你可以随便使用Unicode字符,用没脚”虫“当变量名都随你。使用GB*时,没脚虫”虫“不被支持(GBK收录的少一些吧或者这是日本字吧?)
其次,String在Java中是被定义为char数组来组织的,所以你定义的String最终要被转换成char来存放,但是,不要认为超出char的65536就不能存了,如果超出了它会用2个char来存放
在这里我想用两种方向来说1个String占用的空间
1. 在Java中实际使用的空间
这与使用的编码有关
UTF-8:2/4byte,其实就是1个char或者2个char;
GB*:2byte,就是1个char;
2. 如果对其编码,所需要的空间(String.getBytes())
UTF-8:1~4byte,ASCII用1Byte,汉字大部分用3Byte,其它字符参照上边UTF2.2的算法,超出UCS-2的部分比如那个“虫”就会是4Byte;
GB*:ASCII使用1Byte,其它中文2Byte;
3. 额外的部分---从java到class文件
无论.java文件你用GBK或者UTF-8来编码,编译器在将其编译为.class文件后,如果其中有字符串,会使用UTF-8来编码存储字节,占用1-4Byte。详细来说,就是在.class文件的常量池部分,这种字符串数据使用的数据结构是CONSTANT_Utf8_info,代表UTF-8编码的字符串。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号