

BP网络中的反向传播
本文的主要参考:How the backpropagation algorithm works
下面是BP网络的参数结构示意图
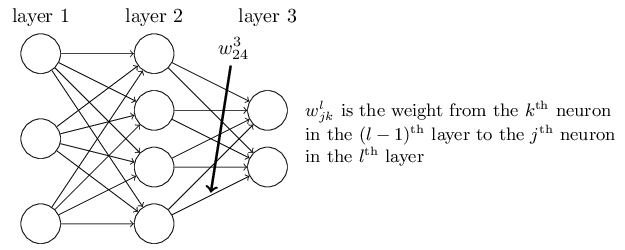
首先定义第l层网络第j个神经元的输出(activation)

为了表示简便,令

则有alj=σ(zlj),其中σ是激活函数
定义网络的cost function,其中的n是训练样本的个数。

下面主要介绍使用反向传播来求取cost function相对于权重wij和偏置项bij的导数。
显然,当输入已知时,cost function只是权值w和偏置项b的函数。这里为了方便推倒,首先计算出∂C/∂zlj,令
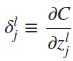
由于alj=σ(zlj),所以显然有
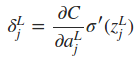
式中的L表示最后一层网络,即输出层。如果只考虑一个训练样本,则cost function可表示为
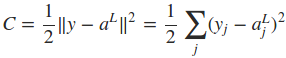
如果将输出层的所有输出看成一个列向量,则δjL可以写成下式,Θ表示向量的点乘

下面最关键的问题来了,如何同过δl+1求取δl。这里就用到了∂C/∂zlj这一重要的中间表达,推倒过程如下
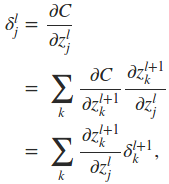

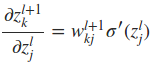
因此,最终有
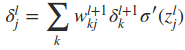
写成向量的形式为
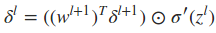
利用与上面类似的推倒,可以得到

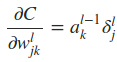
将上面重要的公式用矩阵乘法形式再表达一遍

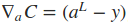

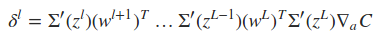
式中Σ'(zL)是主对角线上的元素为σ'(zLj)的对角矩阵。求取了cost function相对于权重wij和偏置项bij的导数之后,便可以使用一些基于梯度的优化算法对网络的权值进行更新。下面是一个2输入2输出的一个BP网络的代码示例,实现的是对输入的每个元素进行逻辑取反操作。


1 import numpy as np 2 3 def tanh(x): 4 return np.tanh(x) 5 6 def tanh_prime(x): 7 x = np.tanh(x) 8 return 1.0 - x ** 2 9 10 class Network(object): 11 12 def __init__(self, sizes): 13 self.num_layers = len(sizes) 14 self.sizes = sizes 15 # self.biases is a column vector 16 # self.weights' structure is the same as in the book: http://neuralnetworksanddeeplearning.com/chap2.html 17 self.biases = [np.random.randn(y, 1) for y in sizes[1:]] 18 self.weights = [np.random.randn(y, x) 19 for x, y in zip(sizes[:-1], sizes[1:])] 20 21 def feedforward(self, a): 22 """Return the output of the network if "a" is input.""" 23 for b, w in zip(self.biases, self.weights): 24 a = sigmoid(np.dot(w, a) + b) 25 return a 26 27 def update_mini_batch(self, mini_batch, learning_rate = 0.2): 28 """Update the network's weights and biases by applying 29 gradient descent using backpropagation to a single mini batch. 30 The "mini_batch" is a list of tuples "(x, y)".""" 31 nabla_b = [np.zeros(b.shape) for b in self.biases] 32 nabla_w = [np.zeros(w.shape) for w in self.weights] 33 34 # delta_nabla_b is dC/db, delta_nabla_w is dC/dw 35 for x, y in mini_batch: 36 delta_nabla_b, delta_nabla_w = self.backprop(x, y) 37 nabla_b = [nb + dnb for nb, dnb in zip(nabla_b, delta_nabla_b)] 38 nabla_w = [nw + dnw for nw, dnw in zip(nabla_w, delta_nabla_w)] 39 self.weights = [w - (learning_rate/len(mini_batch)) * nw 40 for w, nw in zip(self.weights, nabla_w)] 41 self.biases = [b - (learning_rate/len(mini_batch)) * nb 42 for b, nb in zip(self.biases, nabla_b)] 43 44 def backprop(self, x, y): 45 """Return a tuple ``(nabla_b, nabla_w)`` representing the 46 gradient for the cost function C_x. ``nabla_b`` and 47 ``nabla_w`` are layer-by-layer lists of numpy arrays, similar 48 to ``self.biases`` and ``self.weights``.""" 49 nabla_b = [np.zeros(b.shape) for b in self.biases] 50 nabla_w = [np.zeros(w.shape) for w in self.weights] 51 52 # feedforward 53 activation = x 54 activations = [x] # list to store all the activations, layer by layer 55 zs = [] # list to store all the z vectors, layer by layer 56 57 # After this loop, activations = [a0, a1, ..., aL], zs = [z1, z2, ..., zL] 58 for b, w in zip(self.biases, self.weights): 59 z = np.dot(w, activation) + b 60 zs.append(z) 61 activation = sigmoid(z) 62 activations.append(activation) 63 64 # backward pass 65 # delta = deltaL .* sigma'(zL) 66 delta = self.cost_derivative(activations[-1], y) * \ 67 sigmoid_prime(zs[-1]) 68 69 # dC/dbL = delta 70 # dC/dwL = deltaL * a(L-1)^T 71 nabla_b[-1] = delta 72 nabla_w[-1] = np.dot(delta, activations[-2].transpose()) 73 74 '''Note that the variable l in the loop below is used a little 75 differently to the notation in Chapter 2 of the book. Here, 76 l = 1 means the last layer of neurons, l = 2 is the 77 second-last layer, and so on. It's a renumbering of the 78 scheme in the book, used here to take advantage of the fact 79 that Python can use negative indices in lists.''' 80 # z = z(L-l+1), here, l start from 2, end with self.num_layers-1, namely, L-1 81 # delta = delta(L-l+1) = w(L-l+2)^T * delta(L-l+2) .* z(L-l+1) 82 # nabla_b[L-l+1] = delta(L-l+1) 83 # nabla_w[L-l+1] = delta(L-l+1) * a(L-l)^T 84 for l in xrange(2, self.num_layers): 85 z = zs[-l] 86 sp = sigmoid_prime(z) 87 delta = np.dot(self.weights[-l + 1].transpose(), delta) * sp 88 nabla_b[-l] = delta 89 nabla_w[-l] = np.dot(delta, activations[-l - 1].transpose()) 90 return (nabla_b, nabla_w) 91 92 def evaluate(self, test_data): 93 """Return the number of test inputs for which the neural 94 network outputs the correct result. Note that the neural 95 network's output is assumed to be the index of whichever 96 neuron in the final layer has the highest activation.""" 97 test_results = self.feedforward(test_data) 98 return test_results 99 100 def cost_derivative(self, output_activations, y): 101 return (output_activations - y) 102 103 #### Miscellaneous functions 104 def sigmoid(z): 105 return 1.0/(1.0 + np.exp(-z)) 106 107 # derivative of the sigmoid function 108 def sigmoid_prime(z): 109 return sigmoid(z) * (1 - sigmoid(z)) 110 111 if __name__ == '__main__': 112 113 nn = Network([2, 2, 2]) 114 115 X = np.array([[0, 0], 116 [0, 1], 117 [1, 0], 118 [1, 1]]) 119 120 y = np.array([[1, 1], 121 [1, 0], 122 [0, 1], 123 [0, 0]]) 124 125 for k in range(40000): 126 if k % 10000 == 0: 127 print 'epochs:', k 128 # Randomly select a sample. 129 i = np.random.randint(X.shape[0]) 130 nn.update_mini_batch(zip([np.atleast_2d(X[i]).T], [np.atleast_2d(y[i]).T])) 131 132 for e in X: 133 print(e, nn.evaluate(np.atleast_2d(e).T))
运行结果
epochs: 0 epochs: 10000 epochs: 20000 epochs: 30000 (array([0, 0]), array([[ 0.98389328], [ 0.97490859]])) (array([0, 1]), array([[ 0.97694707], [ 0.01646559]])) (array([1, 0]), array([[ 0.03149928], [ 0.97737158]])) (array([1, 1]), array([[ 0.01347963], [ 0.02383405]]))

 浙公网安备 33010602011771号
浙公网安备 33010602011771号