
机器学习之Logistic 回归算法
声明:本篇博文是学习《机器学习实战》一书的方式路程,系原创,若转载请标明来源。
1 Logistic 回归算法的原理
1.1 需要的数学基础
我在看机器学习实战时对其中的代码非常费解,说好的利用偏导数求最值怎么代码中没有体现啊,就一个简单的式子:θ= θ - α Σ [( hθ(x(i))-y(i) ) ] * xi 。经过查找资料才知道,书中省去了大量的理论推导过程,其中用到了线性函数、sigmoid 函数、偏导数、最大似然函数、梯度下降法。下面让我们一窥究竟,是站在大神的肩膀描述我自己的见解。
1.2 Logistic 回归的引入
Logistic 回归是概率非线性模型,用于处理二元分类结果,名为回归实为分类。下面给出一个二元分类的例子,如下图所示:
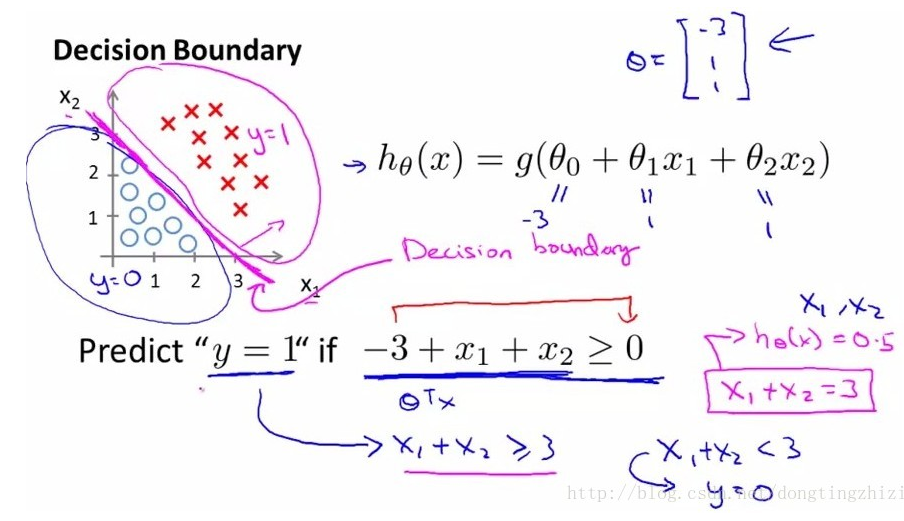
图中数据分成两类,打叉的一类用 y = 1 表示,另一类为圆圈用 y= 0 表示。现在我们要对数据进行分类,要找到一个分类函数(边界线),我们很容易得出一个线性函数对其分类:0 = θ0 + θ1x1 + θ2x2 。但我们想要的函数应该是,能接受所有的输入然后预测类别。例如:在两个分类的情况下,函数输出 0 或 1。因此,我们就需要引入Sigmoid 函数,这个函数的性质可以满足要求。Sigmoid 函数:
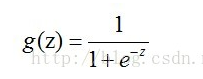
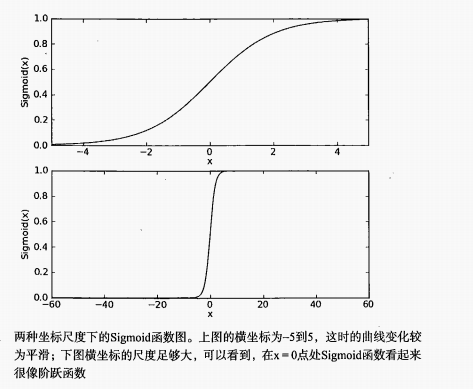
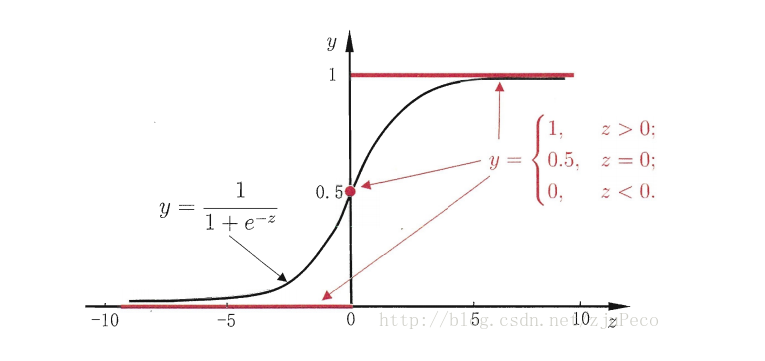
Sigmoid 函数的值域为(0,1),且具有良好的从0 到 1 的跳跃性,如在两个不同的坐标尺度下的函数图形:
所以,我们把线性方程和Sigmoid 函数结合起来就能解决问题。即 :分类预测函数 hθ (x) = g( θ0 + θ1x1 + θ2x2) .我们就可以对样本数据进行分类,如下图所示:
对于线性的分类边界,如下形式:
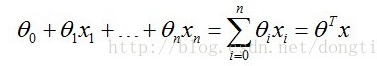
分类预测函数,如下形式:
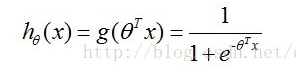
其中,θT 是向量 θ (θ0, θ1,... ,θn) 的转置,向量 x ( x0 , x1 ,... , xn),n -1为数据的维度,x0 =1,这是便于计算。
1.3 分类预测函数问题的转化成求θ
通过上面的分析,我们得出了分类预测函数 hθ(x) , 但其中向量 x 是已知的(x 是未知类别号的对象数据),向量 θ 未知,即我们把求分类函数问题转化成求向量 θ 。因为Sigmoid 函数的取值区间(0,1),那我们可以看做概率 P(y = 1 | xi ; θ)= hθ(x) , 表示在 xi 确定的情况下,类别 y = 1 的概率。由此,我们也可以得出在 xi 确定的情况下,类别 y = 0 的概率 P(y = 0 | xi ; θ)= 1 - P(y = 1 | xi ; θ)= 1 - hθ(x) . 即 :
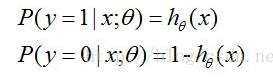
我们可以将这两个式子合并得:
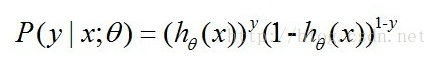
其中的 y = 0 或 1 .
这时候我们可以利用最大似然函数对向量 θ 求值,可以理解为选取的样本数据的概率是最大的,那么样本数为 m 的似然函数为:
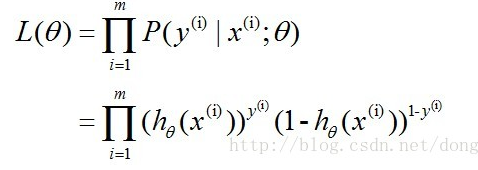
通过对数的形式对似然函数进行变化,对数似然函数:
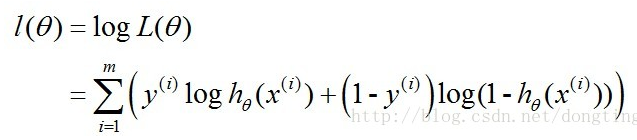
这里的最大似然函数的值就是我们所要求的向量 θ , 而求解的方法利用梯度下降法。
1.4 梯度下降法求解θ
在用梯度下降法时,我们将会利用Sigmoid 函数的一个性质: g, (z) = g(z)[ 1- g(z) ] 。
构造一个Cost函数(损失函数),该函数表示预测的输出(h)与训练数据类别(y)之间的偏差,可以是二者之间的差(h-y)或者是其他的形式。综合考虑所有训练数据的“损失”,将Cost求和或者求平均,记为J(θ)函数,表示所有训练数据预测值与实际类别的偏差。
损失函数:
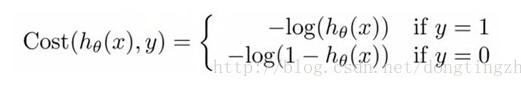
J(θ)代价函数:
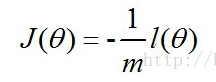
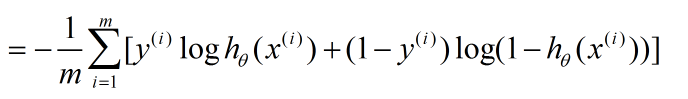
其中,x(i) 每个样本数据点在某一个特征上的值,即特征向量x的某个值,y(i) 是类别号,m 是样本对象个数。
梯度下降法含义:
梯度下降法,就是利用负梯度方向来决定每次迭代的新的搜索方向,使得每次迭代能使待优化的目标函数逐步减小。梯度其实就是函数的偏导数。
这里对用梯度下降法对 J (θ) 求最小值,与求似然函数的最大值是一样的。则 J(θ) 最小值的求解过程:
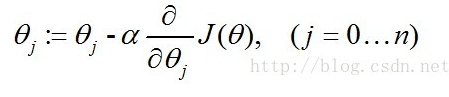
其中 α 是步长。
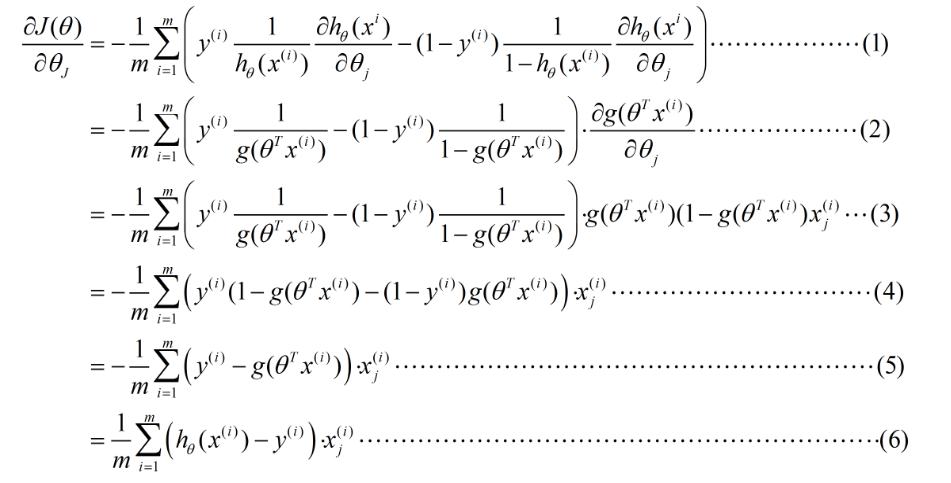
则可以得出:
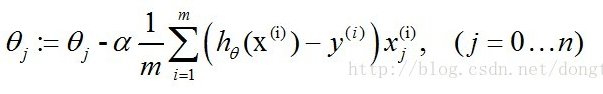
因为 α 是个常量,所以一般情况可以把 1/m 省去,省去不是没有用1/m ,只是看成 α 和1/m 合并成 α 。
最终式子为:
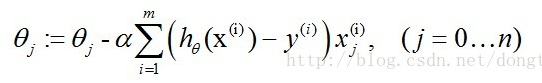
这就是一开始,我对代码中公式困惑的地方。在这里我在补充一点,以上的梯度下降法可以认为是批量梯度下降法(Batch Gradient Descent),由于我们有m个样本,这里求梯度的时候就用了所有m个样本的梯度数据。下面介绍随机梯度下降法(Stochastic Gradient Descent):
随机梯度下降法,其实和批量梯度下降法原理类似,区别在与求梯度时没有用所有的m个样本的数据,而是仅仅选取一个样本j来求梯度。随机梯度下降法,和4.1的批量梯度下降法是两个极端,一个采用所有数据来梯度下降,一个用一个样本来梯度下降。自然各自的优缺点都非常突出。对于训练速度来说,随机梯度下降法由于每次仅仅采用一个样本来迭代,训练速度很快,而批量梯度下降法在样本量很大的时候,训练速度不能让人满意。对于准确度来说,随机梯度下降法用于仅仅用一个样本决定梯度方向,导致解很有可能不是最优。对于收敛速度来说,由于随机梯度下降法一次迭代一个样本,导致迭代方向变化很大,不能很快的收敛到局部最优解。公式为:
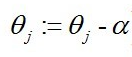
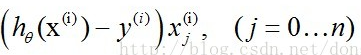
到这里已经把Logistics 回归的原理推导完成。这里对以上推导做一次总结:
边界线 ——> Sigmoid 函数 ——>求向量 θ ——> P(y=1 | x ; θ) = hθ(x) —— > 似然函数 l (θ) ——> 代价函数 J (θ) ——> 梯度下降法求解向量 θ ——> 最终公式 θj
2 使用python 实现Logistic 回归
2.1 Logistic 回归梯度上升优化算法
2.1.1 收集数据和处理数据

1 # 从文件中提取数据 2 def loadDataSet(): 3 dataMat = [] ; labelMat = [] 4 fr = open('testSet.txt') 5 for line in fr.readlines(): # 对文件的数据进行按行遍历 6 lineArr = line.strip().split() 7 dataMat.append([1.0, float(lineArr [0]), float(lineArr[1])]) 8 labelMat.append(int(lineArr[2])) # 数据的类别号列表 9 return dataMat , labelMat
2.1.2 Sigmoid 函数
1 # 定义sigmoid 函数 2 def sigmoid(inX): 3 return longfloat( 1.0 / (1 + exp(-inX)))
使用longfloat() 是为防止溢出。
2.1.3 批量梯度上升算法的实现
1 # Logistic 回归梯度上升优化算法 2 def gradAscent(dataMatIn, classLabels): 3 dataMatrix = mat(dataMatIn) # 将数列转化成矩阵 4 labelMat = mat(classLabels).transpose() # 将类标号转化成矩阵并转置成列向量 5 m,n = shape(dataMatrix) # 获得矩阵dataMatrix 的行、列数 6 alpha = 0.001 # 向目标移动的步长 7 maxCycles = 500 # 迭代次数 8 weights = ones((n ,1)) # 生成 n 行 1 列的 矩阵且值为1 9 for k in range(maxCycles): 10 h = sigmoid(dataMatrix*weights) # dataMatrix*weights 是 m * 1 的矩阵,其每一个元素都会调用sigmoid()函数,h 也是一个 m * 1 的矩阵 11 error = (labelMat - h) # 损失函数 12 weights = weights + alpha + dataMatrix.transpose()* error # 每步 weights 该变量 13 return weights.getA()
解释第 13 行代码:矩阵通过这个getA()这个方法可以将自身返回成一个n维数组对象 ,因为plotBestFit()函数中有计算散点x,y坐标的部分,其中计算y的时候用到了weights,如果weights是矩阵的话,weights[1]就是[0.48007329](注意这里有中括号!),就不是一个数了,最终你会发现y的计算结果的len()只有1,而x的len()则是60。
2.2 根据批量梯度上升法分析数据:画出决策边界
1 # 对数据分类的边界图形显示 2 def plotBestFit(weights): 3 import matplotlib.pyplot as plt 4 dataMat,labelMat=loadDataSet() 5 dataArr = array(dataMat) 6 n = shape(dataArr)[0] # 数据的行数,即对象的个数 7 xcord1 = []; ycord1 = [] # 对类别号为 1 的对象,分 X 轴和 Y 轴的数据 8 xcord2 = []; ycord2 = [] # 对类别号为 0 的对象,分 X 轴和 Y 轴的数据 9 for i in range(n): # 对所有的对象进行遍历 10 if int(labelMat[i])== 1: # 对象的类别为:1 11 xcord1.append(dataArr[i,1]); ycord1.append(dataArr[i,2]) 12 else: 13 xcord2.append(dataArr[i,1]); ycord2.append(dataArr[i,2]) 14 fig = plt.figure() 15 ax = fig.add_subplot(111) 16 ax.scatter(xcord1, ycord1, s=30, c='red', marker='s') # 对散点的格式的设置,坐标号、点的大小、颜色、点的图形(方块) 17 ax.scatter(xcord2, ycord2, s=30, c='green') # 点的图形默认为圆 18 x = arange(-3.0, 3.0, 0.1) 19 y = (-weights[0]-weights[1]*x)/weights[2] # 线性方程 y = aX + b,y 是数据第三列的特征,X 是数据第二列的特征 20 ax.plot(x, y) 21 plt.xlabel('X1'); plt.ylabel('X2') 22 plt.show()
运行结果:
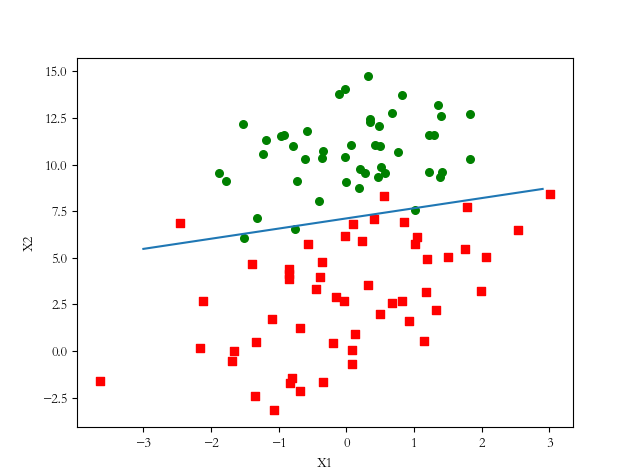
有结果效果图可知,边界线基本可以对样本进行较好的分类。
2.3 利用随机梯度上升法训练样本
1 # 随机梯度上升法 2 def stocGradAscent0(dataMatrix, classLabels, numIter=150): 3 m,n = shape(dataMatrix ) 4 weights = ones(n) 5 for j in range(numIter): # 迭代次数 6 dataIndex = range(m) # 7 for i in range(m): # 对所有对象的遍历 8 alpha = 4/(1.0+j+i)+0.01 # 对步长的调整 9 randIndex = int (random.uniform(0,len(dataIndex))) # 随机生成一个整数,介于 0 到 m 10 h = sigmoid(sum(dataMatrix[randIndex]*weights)) # 对随机选择的对象计算类别的数值(回归系数值) 11 error = classLabels[randIndex] - h # 根据实际类型与计算类型值的误差,损失函数 12 weights = weights + alpha * error * dataMatrix[randIndex] # 每步 weights 改变值 13 del(dataIndex [randIndex]) # 去除已经选择过的对象,避免下次选中 14 return weights
在随机梯度上升法求解的 θ ,对样本进行分类,并画出其边界线,运行的结果图:
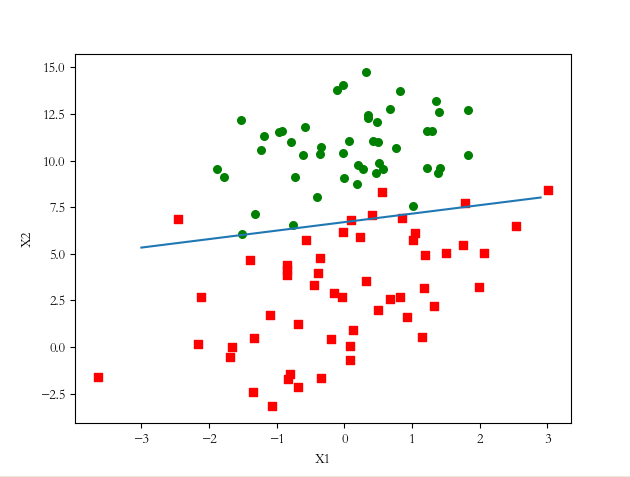
利用随机梯度上升法,通过150 次迭代得出的效果图和批量梯度上升法的效果图差不过,但随机梯度的效率比批量梯度上升法快很多。
3 实例:从疝气病症预测病马的死亡率
3.1 未知对象的预测
1 # 对未知对象进行预测类别号 2 def classifyVector(inX , weights): 3 prob = sigmoid(sum(inX * weights)) # 计算回归系数 4 if prob > 0.5: 5 return 1.0 6 else: 7 return 0.0
3.2 样本数据和测试函数
1 # 实例:从疝气病预测病马的死亡率 2 def colicTest(): 3 frTrain = open('horseColicTraining.txt'); frTest = open('horseColicTest.txt')# 数据文件 4 trainingSet = []; trainingLabels = [] # 样本集和类标号集的初始化 5 for line in frTrain.readlines(): 6 currLine = line.strip().split('\t') # 根据制表符进行字符串的分割 7 lineArr =[] 8 for i in range(21): 9 lineArr.append(float(currLine[i])) 10 trainingSet.append(lineArr) 11 trainingLabels.append(float(currLine[21])) 12 #trainWeights = stocGradAscent0(array(trainingSet), trainingLabels, 500) # 通过对训练样本计算出回归系数 13 trainWeights = gradAscent(array(trainingSet), trainingLabels) # 通过对训练样本计算出回归系数 14 errorCount = 0; numTestVec = 0.0 # 错误个数和错误率的初始化 15 # 预测样本的遍历 16 for line in frTest.readlines(): 17 numTestVec += 1.0 18 currLine = line.strip().split('\t') 19 lineArr =[] 20 for i in range(21): 21 lineArr.append(float(currLine[i])) 22 if int(classifyVector(array(lineArr), trainWeights))!= int(currLine[21]): # 预测的类别号与真实类别号的比较 23 errorCount += 1 24 errorRate = (float(errorCount)/numTestVec) 25 print u'本次测试的错误率是; %f' % errorRate 26 return errorRate
3.3 预测结果函数
1 # 预测结果函数 2 def multiTest(): 3 numTests = 10; errorSum = 0.0 4 for k in range(numTests): 5 errorSum += colicTest() 6 print u'经过 %d 次测试结果的平均错误率是: %f ' % (numTests ,errorSum /float(numTests))
利用随机梯度上升法训练的样本集,测试结果:
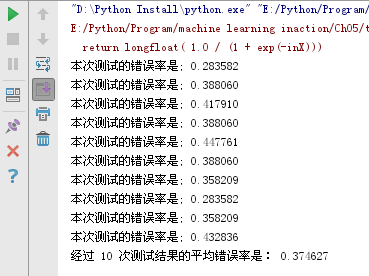
利用批量梯度上升法训练的样本集,测试结果:
附 完整程序


1 # coding:utf-8 2 from numpy import * 3 4 # 从文件中提取数据 5 def loadDataSet(): 6 dataMat = [] ; labelMat = [] 7 fr = open('testSet.txt') 8 for line in fr.readlines(): # 对文件的数据进行按行遍历 9 lineArr = line.strip().split() 10 dataMat.append([1.0, float(lineArr [0]), float(lineArr[1])]) 11 labelMat.append(int(lineArr[2])) # 数据的类别号列表 12 return dataMat , labelMat 13 14 # 定义sigmoid 函数 15 def sigmoid(inX): 16 return longfloat( 1.0 / (1 + exp(-inX))) 17 18 # Logistic 回归批量梯度上升优化算法 19 def gradAscent(dataMatIn, classLabels): 20 dataMatrix = mat(dataMatIn) # 将数列转化成矩阵 21 labelMat = mat(classLabels).transpose() # 将类标号转化成矩阵并转置成列向量 22 m,n = shape(dataMatrix) # 获得矩阵dataMatrix 的行、列数 23 alpha = 0.001 # 向目标移动的步长 24 maxCycles = 500 # 迭代次数 25 weights = ones((n ,1)) # 生成 n 行 1 列的 矩阵且值为1 26 for k in range(maxCycles): 27 h = sigmoid(dataMatrix*weights) # dataMatrix*weights 是 m * 1 的矩阵,其每一个元素都会调用sigmoid()函数,h 也是一个 m * 1 的矩阵 28 error = (labelMat - h) # 损失函数 29 weights = weights + alpha + dataMatrix.transpose()* error # 每步 weights 该变量 30 return weights.getA() 31 32 # 对数据分类的边界图形显示 33 def plotBestFit(weights): 34 import matplotlib.pyplot as plt 35 dataMat,labelMat=loadDataSet() 36 dataArr = array(dataMat) 37 n = shape(dataArr)[0] # 数据的行数,即对象的个数 38 xcord1 = []; ycord1 = [] # 对类别号为 1 的对象,分 X 轴和 Y 轴的数据 39 xcord2 = []; ycord2 = [] # 对类别号为 0 的对象,分 X 轴和 Y 轴的数据 40 for i in range(n): # 对所有的对象进行遍历 41 if int(labelMat[i])== 1: # 对象的类别为:1 42 xcord1.append(dataArr[i,1]); ycord1.append(dataArr[i,2]) 43 else: 44 xcord2.append(dataArr[i,1]); ycord2.append(dataArr[i,2]) 45 fig = plt.figure() 46 ax = fig.add_subplot(111) 47 ax.scatter(xcord1, ycord1, s=30, c='red', marker='s') # 对散点的格式的设置,坐标号、点的大小、颜色、点的图形(方块) 48 ax.scatter(xcord2, ycord2, s=30, c='green') # 点的图形默认为圆 49 x = arange(-3.0, 3.0, 0.1) 50 y = (-weights[0]-weights[1]*x)/weights[2] # 线性方程 y = aX + b,y 是数据第三列的特征,X 是数据第二列的特征 51 ax.plot(x, y) 52 plt.xlabel('X1'); plt.ylabel('X2') 53 plt.show() 54 55 # 随机梯度上升法 56 def stocGradAscent0(dataMatrix, classLabels, numIter=150): 57 m,n = shape(dataMatrix ) 58 weights = ones(n) 59 for j in range(numIter): # 迭代次数 60 dataIndex = range(m) # 61 for i in range(m): # 对所有对象的遍历 62 alpha = 4/(1.0+j+i)+0.01 # 对步长的调整 63 randIndex = int (random.uniform(0,len(dataIndex))) # 随机生成一个整数,介于 0 到 m 64 h = sigmoid(sum(dataMatrix[randIndex]*weights)) # 对随机选择的对象计算类别的数值(回归系数值) 65 error = classLabels[randIndex] - h # 根据实际类型与计算类型值的误差,损失函数 66 weights = weights + alpha * error * dataMatrix[randIndex] # 每步 weights 改变值 67 del(dataIndex [randIndex]) # 去除已经选择过的对象,避免下次选中 68 return weights 69 70 # 对未知对象进行预测类别号 71 def classifyVector(inX , weights): 72 prob = sigmoid(sum(inX * weights)) # 计算回归系数 73 if prob > 0.5: 74 return 1.0 75 else: 76 return 0.0 77 78 # 实例:从疝气病预测病马的死亡率 79 def colicTest(): 80 frTrain = open('horseColicTraining.txt'); frTest = open('horseColicTest.txt')# 数据文件 81 trainingSet = []; trainingLabels = [] # 样本集和类标号集的初始化 82 for line in frTrain.readlines(): 83 currLine = line.strip().split('\t') # 根据制表符进行字符串的分割 84 lineArr =[] 85 for i in range(21): 86 lineArr.append(float(currLine[i])) 87 trainingSet.append(lineArr) 88 trainingLabels.append(float(currLine[21])) 89 trainWeights = stocGradAscent0(array(trainingSet), trainingLabels, 500) # 通过随机梯度上升法计算回归系数 90 #trainWeights = gradAscent(array(trainingSet), trainingLabels) # 通过批量梯度上升法计算出回归系数 91 errorCount = 0; numTestVec = 0.0 # 错误个数和错误率的初始化 92 # 预测样本的遍历 93 for line in frTest.readlines(): 94 numTestVec += 1.0 95 currLine = line.strip().split('\t') 96 lineArr =[] 97 for i in range(21): 98 lineArr.append(float(currLine[i])) 99 if int(classifyVector(array(lineArr), trainWeights))!= int(currLine[21]): # 预测的类别号与真实类别号的比较 100 errorCount += 1 101 errorRate = (float(errorCount)/numTestVec) 102 print u'本次测试的错误率是; %f' % errorRate 103 return errorRate 104 105 # 预测结果函数 106 def multiTest(): 107 numTests = 10; errorSum = 0.0 108 for k in range(numTests): 109 errorSum += colicTest() 110 print u'经过 %d 次测试结果的平均错误率是: %f ' % (numTests ,errorSum /float(numTests)) 111 112 if __name__ == '__main__': 113 # 用批量梯度上升法画边界线 114 ''' 115 dataSet, labelSet = loadDataSet() 116 #weights = gradAscent(dataSet, labelSet) 117 #plotBestFit(weights) 118 ''' 119 # 用随机梯度上升法画边界线 120 ''' 121 dataSet, labelSet = loadDataSet() 122 #weightss = stocGradAscent0(array(dataSet), labelSet ) 123 #plotBestFit(weightss) 124 ''' 125 # 实例的预测 126 multiTest()


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· .NET Core 中如何实现缓存的预热?
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 如何调用 DeepSeek 的自然语言处理 API 接口并集成到在线客服系统
· 【译】Visual Studio 中新的强大生产力特性