
hive(在大数据集合上的类SQL查询和表)学习
1、jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=true&characterEncoding=UTF-8&useSSL=false
2、desc (formatted) 表名;
可以查看表的描述
3、文件以逗号分隔,重命名csv结尾,可以用Excel打开
4、Linux下有一个wc -l 文件名,看文件内容数量
5、外部表,出现空值,同样内容放到外部表,出现空值,而放在分区表,却全部显示
删除内部表(管理表)即把内容也会删除
7)“-e”不进入 hive 的交互窗口执行 sql 语句
[hadoop@master hive]$ bin/hive -e "select id from student;"
8、“-f”执行脚本中 sql 语句
(1)在/opt/module/datas 目录下创建 hivef.sql 文件
[hadoop@master datas]$ touch hivef.sql
文件中写入正确的 sql 语句
select *from student;
(2)执行文件中的 sql 语句
[hadoop@master hive]$ bin/hive -f /opt/module/datas/hivef.sql
(3)执行文件中的 sql 语句并将结果写入文件中
[hadoop@master hive]$ bin/hive -f /opt/module/datas/hivef.sql >
/opt/module/datas/hive_result.txt
9、退出 hive 窗口:
exit:先隐性提交数据,再退出; quit:不提交数据,退出;
10在 hive cli 命令窗口中如何查看 hdfs 文件系统
hive(default)>dfs -ls /;
11)在 hive cli 命令窗口中如何查看 hdfs 本地系统
hive(default)>! ls /opt/module/datas;
12)查看在 hive 中输入的所有历史命令
(1)进入到当前用户的根目录/root 或/home/atguigu
(2)查看. hivehistory 文件
[hadoop@master ~]$ cat .hivehistory
13)在 hive-site.xml 文件中添加如下配置信息,就可以实现显示当前数据库,以及查询 表的头信息配置。
<property>
<name>hive.cli.print.header</name>
<value>true</value>
</property>
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
</property>
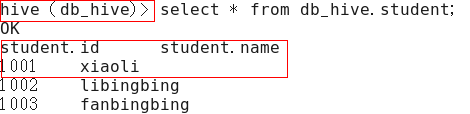
配置前
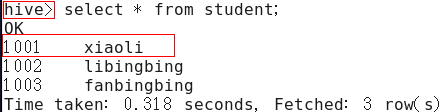
配置后
14)参数的配置三种方式
(1)配置文件方式 默认配置文件:hive-default.xml 用户自定义配置文件:hive-site.xml cp hive-default.xml hive-site.xml
注意:用户自定义配置会覆盖默认配置。另外,Hive 也会读入 Hadoop 的配置,因 为 Hive 是作为 Hadoop 的客户端启动的,Hive 的配置会覆盖 Hadoop 的配置。配置文件 的设定对本机启动的所有 Hive 进程都有效。
(2)命令行参数方式
启动 Hive 时,可以在命令行添加-hiveconf param=value 来设定参数。 例如
bin/hive -hiveconf mapred.reduce.tasks=10;
注意:仅对本次 hive 启动有效 查看参数设置:
hive (default)> set mapred.reduce.tasks;
(3)参数声明方式
可以在 HQL 中使用 SET 关键字设定参数 例如:
hive (default)> set mapred.reduce.tasks=100; 注意:仅对本次 hive 启动有效。
查看
hive (default)> set mapred.reduce.tasks;
上述三种设定方式的优先级依次递增。即配置文件<命令行参数<参数声明。注意某些 系统级的参数,例如 log4j 相关的设定,必须用前两种方式设定,因为那些参数的读取在会 话建立以前已经完成了。
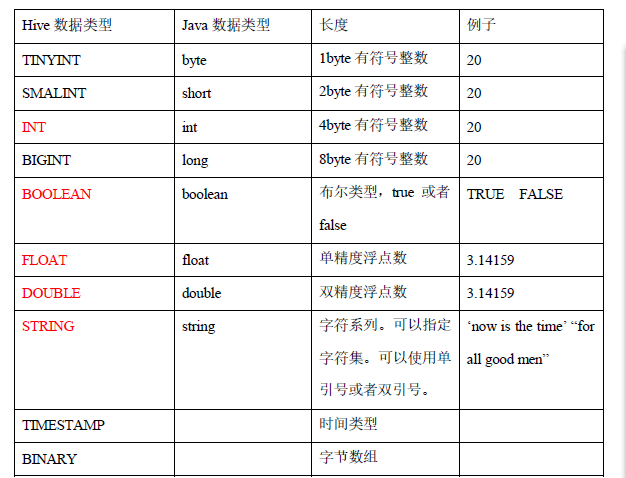
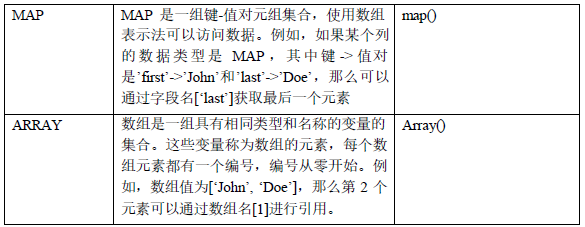
15Hive 数据类型

16创建表
{
"name": "songsong",
"friends": ["bingbing" , "lili"] , "children": {
"xiao song": 18 , "xiaoxiao song": 19
}
"address": {
"street": "hui long guan" , "city": "beijing"
}
create table if not exists test( name string,
friends array<string>, children map<string, int>,
address struct<street:string, city:string>)
row format delimited fields terminated by ',' collection items terminated by '_'
map keys terminated by ':'
lines terminated by '\n';
字段解释
row format delimited fields terminated by ',' -- 列分隔符
collection items terminated by '_' --MAP STRUCT 和 ARRAY 的分隔符(数据分割符号) map keys terminated by ':' -- MAP 中的 key 与 value 的分隔符
lines terminated by '\n'; -- 行分隔符
17导入数据
load data local inpath '/opt/module/datas/test.txt' into table test;
是本地导入,不是集群
select friends[1],children['xiao song'],address.city from test where
name="songsong";
18转换(隐式转换只能向上转不能向下转)
使用 CAST 操作显示进行数据类型转换,例如 CAST('1' AS INT)将把字符串'1' 转换 成整数 1
19修改数据库
数据库的其他元数据信息都是不可更改的,包括数 据库名和数据库所在的目录位置。
只能修改dbproperties属性
hive (default)> alter database db_hive set dbproperties('createtime'='20170830');
在 mysql 中查看修改结果
hive> desc database extended db_hive;
20显示数据库
显示数据库
hive> show databases;
2)过滤显示查询的数据库
hive> show databases like 'db_hive*'; OK
db_hive db_hive_1
显示数据库信息
hive> desc database db_hive;
OK
db_hive hdfs://hadoop102:8020/user/hive/warehouse/db_hive.db atguiguUSER
2)显示数据库详细信息,extended
hive> desc database extended db_hive;
21删除数据库
如果数据库不为空,可以采用 cascade 命令,强制删除
hive> drop database db_hive cascade;
22创建表
语法
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name
[(col_name data_type [COMMENT col_comment], ...)] [COMMENT table_comment]
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)] [CLUSTERED BY (col_name, col_name, ...)
[SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS] [ROW FORMAT row_format]
[STORED AS file_format]
[LOCATION hdfs_path]
解释
字段解释说明:
(1)CREATE TABLE 创建一个指定名字的表。如果相同名字的表已经存在,则抛出 异常;用户可以用 IF NOT EXISTS 选项来忽略这个异常。
(2)EXTERNAL 关键字可以让用户创建一个外部表,在建表的同时指定一个指向实际 数据的路径(LOCATION),Hive 创建内部表时,会将数据移动到数据仓库指向的路 径;若创建外部表,仅记录数据所在的路径,不对数据的位置做任何改变。在删除表的 时候,内部表的元数据和数据会被一起删除,而外部表只删除元数据,不删除数据。
(3)COMMENT:为表和列添加注释。
(4)PARTITIONED BY 创建分区表
(5)CLUSTERED BY 创建分桶表
(6)SORTED BY 不常用
(7)ROW FORMAT
DELIMITED [FIELDS TERMINATED BY char] [COLLECTION ITEMS TERMINATED BY char]
[MAP KEYS TERMINATED BY char] [LINES TERMINATED BY char]
| SERDE serde_name [WITH SERDEPROPERTIES (property_name=property_value, property_name=property_value, ...)]
用户在建表的时候可以自定义 SerDe 或者使用自带的 SerDe。如果没有指定 ROW
FORMAT 或者 ROW FORMAT DELIMITED,将会使用自带的 SerDe。在建表的时候,用户 还需要为表指定列,用户在指定表的列的同时也会指定自定义的 SerDe,Hive 通过 SerDe 确定表的具体的列的数据。
(8)STORED AS 指定存储文件类型 常用的存储文件类型:SEQUENCEFILE(二进制序列文件)、TEXTFILE(文本)、 RCFILE(列式存储格式文件)
如果文件数据是纯文本,可以使用 STORED AS TEXTFILE。如果数据需要压缩, 使用 STORED AS SEQUENCEFILE。
(9)LOCATION :指定表在 HDFS 上的存储位置。
(10)LIKE 允许用户复制现有的表结构,但是不复制数据。
21普通创建表
。当我们 删除一个管理表时,Hive 也会删除这个表中数据。管理表不适合和其他工具共享数据。
create table if not exists student2( id int, name string
)
row format delimited fields terminated by '\t' stored as textfile
location '/user/hive/warehouse/student2';
根据查询结果创建表(查询的结果会添加到新创建的表中)
create table if not exists student3
as select id, name from student;
(3)根据已经存在的表结构创建表
create table if not exists student4 like student;
22查询表
desc formatted student2;
23外部表
因为表是外部表,所有 Hive 并非认为其完全拥有这份数据。删除该表并不会删除掉这 份数据,不过描述表的元数据信息会被删除掉。
create external table if not exists default.dept( deptno int,
dname string, loc int
)
row format delimited fields terminated by '\t';
本地导入
load data local inpath '/opt/module/datas/dept.txt' into table default.dept;
24分区表
create table dept_partition(deptno int, dname string, loc string) partitioned by (month string) row format delimited fields terminated by '\t';
加载数据
load data local inpath '/home/hadoop/dept.txt' into table default.dept_partition partition(month='201709');
select * from dept_partition where month='201709';
增加分区(多个)
alter table dept_partition add partition(month='201705') partition(month='201704');
删除分区(多个)
alter table dept_partition drop partition (month='201705'), partition (month='201706');
查看分区 表
show partitions dept_partition;
查看分区表结构
hive>desc formatted dept_partition;
二级分区表
hive (default)> create table dept_partition2(
deptno int, dname string, loc string
)
partitioned by (month string, day string)
row format delimited fields terminated by '\t';
select * from dept_partition2 where month='201709' and day='13';
数据直接上传到分区目录上,让分区表和数据产生关联的两种方式
(1)方式一:上传数据后修复 上传数据
hive (default)> dfs -mkdir -p
/user/hive/warehouse/dept_partition2/month=201709/day=12;
hive (default)> dfs -put /opt/module/datas/dept.txt
/user/hive/warehouse/dept_partition2/month=201709/day=12;
查询数据(查询不到刚上传的数据)
hive (default)> select * from dept_partition2 where month='201709' and day='12';
执行修复命令
hive>msck repair table dept_partition2;
再次查询数据
hive (default)> select * from dept_partition2 where month='201709' and day='12';
(2)方式二:上传数据后添加分区
上传数据
hive (default)> dfs -mkdir -p
/user/hive/warehouse/dept_partition2/month=201709/day=11;
hive (default)> create table dept_partition2(
deptno int, dname string, loc string
)
partitioned by (month string, day string)
row format delimited fields terminated by '\t';
hive (default)> dfs -put /opt/module/datas/dept.txt
/user/hive/warehouse/dept_partition2/month=201709/day=11;
执行添加分区
hive (default)> alter table dept_partition2 add partition(month='201709', day='11');
查询数据
hive (default)> select * from dept_partition2 where month='201709' and day='11';
(3)方式三:上传数据后 load 数据到分区 创建目录
hive (default)> dfs -mkdir -p
/user/hive/warehouse/dept_partition2/month=201709/day=10;
上传数据
hive (default)> load data local inpath '/opt/module/datas/dept.txt' into table dept_partition2 partition(month='201709',day='10');
查询数据
hive (default)> select * from dept_partition2 where month='201709' and day='10';
25重命名表
alter table dept_partition2 rename to dept_partition3
26加载表
hive>load data [local] inpath '/opt/module/datas/student.txt' [overwrite] into table student
[partition (partcol1=val1,…)];
(1)load data:表示加载数据
(2)local:表示从本地加载数据到 hive 表;否则从 HDFS 加载数据到 hive 表
(3)inpath:表示加载数据的路径
(4)into table:表示加载到哪张表
(5)student:表示具体的表
(6)overwrite:表示覆盖表中已有数据,否则表示追加
(7)partition:表示上传到指定分区
27通过查询语句向表中插入数据(Insert)
创建分区表
create table student(id string, name string) partitioned by (month string) row format delimited fields terminated by '\t';
2)基本插入数据
insert into table
student partition(month='201709')
values('1004','wangwu');
基本模式插入(根据单张表查询结果)
hive (default)> insert overwrite table student partition(month='201708') select id, name from student where month='201709';
多插入模式(根据多张表查询结果)
hive (default)> from student
insert overwrite table student partition(month='201707') select id, name where month='201709'
insert overwrite table student partition(month='201706') select id, name where month='201709';
根据查询结果创建表(查询的结果会添加到新创建的表中)
create table if not exists student3
as select id, name from student;
创建表时通过 Location 指定加载数据路径
创建表,并指定在 hdfs 上的位置
hive (default)> create table if not exists student5(
id int, name string
)
row format delimited fields terminated by '\t' location '/user/hive/warehouse/student5';
2)上传数据到 hdfs 上
hive (default)> dfs -put /opt/module/datas/student.txt /user/hive/warehouse/student5;
3)查询数据
hive (default)> select * from student5
