
学习python
python优缺点
简单易学免费,开源,高层语言,可移植型,解释性,面向对象,可扩展性,丰富的库,规范的代码
缺点
运行速度,国内市场小,中文资料匮乏,构架选择太多
(所有的库在python官网的pypi里面)
在python里面一用pip install 下载东西,进行下载二在官网pypi内下载需要的包
程序用来处理变量,而变量是用来存储数据
python3里用input,没有raw_input只在python2里有
而且python2里是print “‘’” 直接写,没有括号
加号 + 是列表连接运算符,星号 * 是重复操作。
print 默认输出是换行的,如果要实现不换行需要在变量末尾加上 end="":
isinstance 和 type 的区别在于:
type()不会认为子类是一种父类类型。
isinstance()会认为子类是一种父类类型。
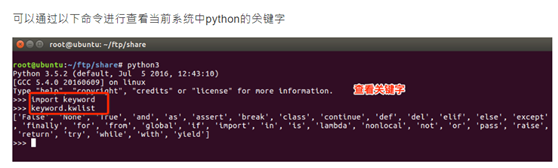
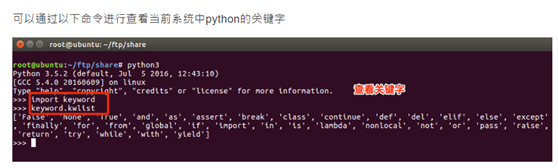
查看python关键字命令
当从pycharm的.py文件,在xshell和xftp软件中上传到虚拟机下的root/code后,先运用命令
chmod +x test3.py(传输的文件)
然后进入vi test3.py
末行模式输入set nu 显示行数,然后set list查看格式(此时应为Windows的格式,要转为Linux格式)
保存退出输入 dos2unix
没有则下载apt-get install dos2unix
然后dos2unix test3.py即可
运行./test3.py 即可
若是运行c程序,因为已经apt-get install gcc-c++
所以直接编译文件
vi test1.c
chmod +x test1.c
vi test1.c
./a.out
即可
而如果在Windows下面即cmd命令下运行,
可选择进入文件目录下输入python main.py
也可以输入完整路径执行
(对于python小程序小游戏这种,要在Windows下执行pip install pygame以及pip install wheel 命令,才可以运行该程序)
默认情况下,mysql只允许本地登录,如果要开启远程连接,则需要修改/etc/mysql/my.conf文件。
一、修改/etc/mysql/my.conf
找到bind-address = 127.0.0.1这一行注释即可
二、为需要远程登录的用户赋予权限
1、新建用户远程连接mysql数据库
grant all on *.* to admin@'%' identified by '123456' with grant option;
flush privileges;
允许任何ip地址(%表示允许任何ip地址)的电脑用admin帐户和密码(123456)来访问这个mysql server。
注意admin账户不一定要存在。
2、支持root用户允许远程连接mysql数据库
grant all privileges on *.* to 'root'@'%' identified by '123456' with grant option;
flush privileges;
然后在Navicat里连接自己的ip192.168.0.235,输入账号和密码即可测试
成功后输入./python.py
可能会出现没有数据库的错误
mysql -u账号-p密码
进入后使用show databases查看数据库
使用create database school default charetset utf8mb4
创建之后,quit返回,vi python.py 把数据库修改
然后./python.py即可(前提是,编辑好python.py或者从ftp导入,然后chmod +x python.py 然后dos2unix python.py)
python编写的三种模式
Ide
交互式
命令行
注释的引入
单行 #
多行''' '''
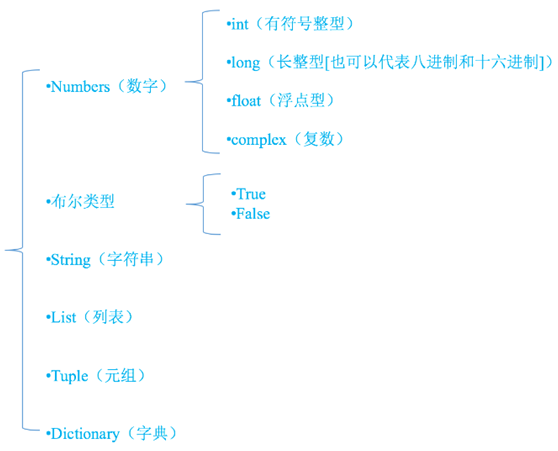
标示符由字母、下划线和数字组成,且数字不能开头
小驼峰式命名法(lower camel case): 第一个单词以小写字母开始;第二个单词的首字母大写,例如:myName、aDog
大驼峰式命名法(upper camel case): 每一个单字的首字母都采用大写字母,例如:FirstName、LastName
不过在程序员中还有一种命名法比较流行,就是用下划线“_”来连接所有的单词,比如send_buf
查看关键字:
- and as assert break class continue def del
- elif else except exec finally for from global
- if in import is lambda not or pass
- print raise return try while with yield
可以通过以下命令进行查看当前系统中python的关键字
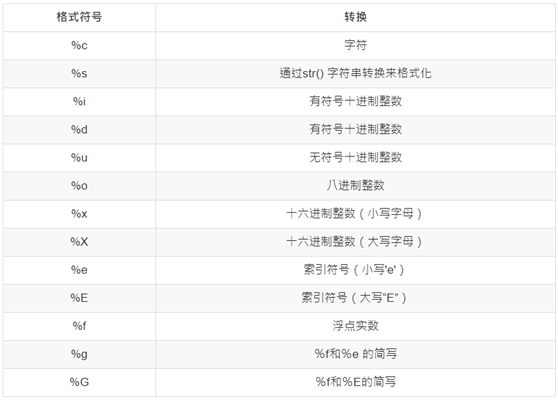
格式化输出
格式化代码 ctrl+alt+L
换行输出
在输出的时候,如果有\n那么,此时\n后的内容会在另外一行显示
- raw_input()的小括号中放入的是,提示信息,用来在获取数据之前给用户的一个简单提示
- raw_input()在从键盘获取了数据以后,会存放到等号右边的变量中
- raw_input()会把用户输入的任何值都作为字符串来对待
input()
input()函数与raw_input()类似,但其接受的输入必须是表达式。
nput()接受表达式输入,并把表达式的结果赋值给等号左边的变量
python3版本中
没有raw_input()函数,只有input()
并且 python3中的input与python2中的raw_input()功能一样
算术运算符
下面以a=10 ,b=20为例进行计算

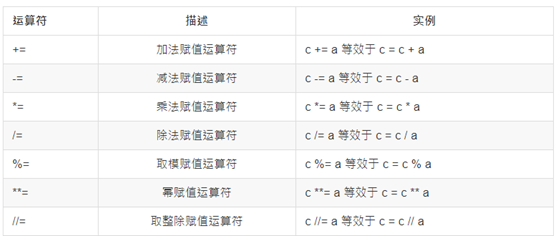
复合赋值运算符
常用的数据类型转换
Python转义字符
在需要在字符中使用特殊字符时,python用反斜杠(\)转义字符。如下表:
| 转义字符 | 描述 |
|---|---|
| \(在行尾时) | 续行符 |
| \\ | 反斜杠符号 |
| \' | 单引号 |
| \" | 双引号 |
| \a | 响铃 |
| \b | 退格(Backspace) |
| \e | 转义 |
| \000 | 空 |
| \n | 换行 |
| \v | 纵向制表符 |
| \t | 横向制表符 |
| \r | 回车 |
| \f | 换页 |
| \oyy | 八进制数,yy代表的字符,例如:\o12代表换行 |
| \xyy | 十六进制数,yy代表的字符,例如:\x0a代表换行 |
| \other | 其它的字符以普通格式输出 |
比较(即关系)运算符
python中的比较运算符如下表

逻辑运算符

注:and 不是&& ,or 不是|| ,not 不是 !
注意:代码的缩进为一个tab键,或者4个空格
if 条件:(有冒号)
条件成立
else 条件:
或者
if 条件:(有冒号)
条件成立
elif 条件:
while 条件 :
条件成立执行
for 临时变量 in 列表或者字符串
条件存在执行
else :
不存在执行
break结束循环,continue跳过本次循环
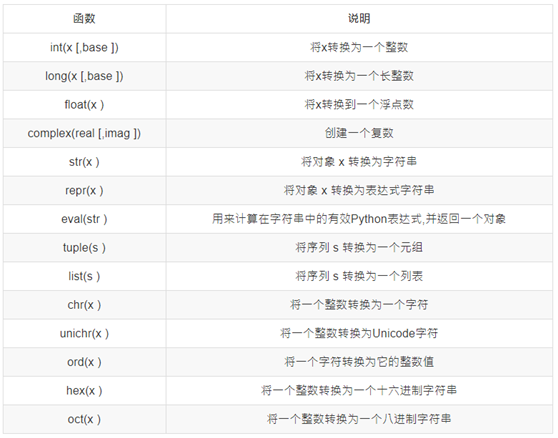
Python数据类型转换
有时候,我们需要对数据内置的类型进行转换,数据类型的转换,你只需要将数据类型作为函数名即可。
以下几个内置的函数可以执行数据类型之间的转换。这些函数返回一个新的对象,表示转换的值。
| 函数 | 描述 |
|---|---|
|
将x转换为一个整数 |
|
|
将x转换到一个浮点数 |
|
|
创建一个复数 |
|
|
将对象 x 转换为字符串 |
|
|
将对象 x 转换为表达式字符串 |
|
|
用来计算在字符串中的有效Python表达式,并返回一个对象 |
|
|
将序列 s 转换为一个元组 |
|
|
将序列 s 转换为一个列表 |
|
|
转换为可变集合 |
|
|
创建一个字典。d 必须是一个序列 (key,value)元组。 |
|
|
转换为不可变集合 |
|
|
将一个整数转换为一个字符 |
|
|
将一个字符转换为它的整数值 |
|
|
将一个整数转换为一个十六进制字符串 |
|
|
将一个整数转换为一个八进制字符串 |
字符串格式
菜鸟教程
http://www.runoob.com/python3/python3-string.html
单引号或者双引号
输入为input,而字符串或者列表元组,下标为从左到右为0开始递增,从右到左为从-1开始递减
#!/usr/bin/python
# encoding
name="abcdef"
print(name[::])
print(name[3:5])
print(name[2:])
print(name[2:-2])
print(name[5:1:-2])
mystr="hello world itcast and itcastapp"
print(mystr.find("itcast"))
print(mystr.find("itcast",0,10))#从0到10(左闭右开)找itcast出现的下标,rfind从右边开始查找
print(mystr.count("itcast"))#计算字符串里面包含多少itcast
print(id(name))
name="hello world ha ha"
print(name)
print(id(name))#变量的id值指向地址
print(name.replace("ha","Ha"))
print(name.replace("ha","Ha",1))#从左取代几个
print(name.split())
print(name.split(" ",1))#指定分割几次,从左开始
print(name.capitalize())#转换为首字母大写
print(name.title())#转换为每个字母首字母大写
print(name.startswith("hello"))#判断是否以hello开始,区分大小写,Hello会为false
print(name.startswith("Hello"))
print(name.endswith("ha"))#判断结尾
print(name.lower(),name.upper())#转换大小写
print(name.ljust(20))#返回一个原来字符串左对齐,以数字为长度的rjust()右对齐
print(name.center(29))#和边一样,不过居中对齐
mystr=" hello world "
print(mystr)
print(mystr.lstrip())#去掉左边空格rstip去掉右边空格,strp去掉两边,不包括中间
print(name.partition("itcast"))#划分为三部分,以引号内容为中间,没有则后续两个空的
mystr="hello world itcast and itcastapp"
print(mystr.partition("itcast"))
print(mystr.rpartition("itcast"))#从右边开始
mystr="hello\nworld"
print(mystr)
print(mystr.splitlines())#按照行分割,返回一个以各行作为元素的列表
print(mystr.isalpha())#所有都是字母则为true
print(mystr.isalnum())#所有都是字母或者数字则为true,isspace()只包含空格为true
digit="123"
print(digit.isdigit())#所有都是数字为true
li=["my","name","is","dongGe"]
str=" "
print(li)
print(str.join(li))#加入到里面
str="_"
print(str.join(li))
依次输出为
abcdef
de
cdef
cd
fd
12
-1
2
6710752
hello world ha ha
6749072
hello world Ha Ha
hello world Ha ha
['hello', 'world', 'ha', 'ha']
['hello', 'world ha ha']
Hello world ha ha
Hello World Ha Ha
True
False
True
hello world ha ha HELLO WORLD HA HA
hello world ha ha
hello world ha ha
hello world
hello world
('hello world ha ha', '', '')
('hello world ', 'itcast', ' and itcastapp')
('hello world itcast and ', 'itcast', 'app')
hello
world
['hello', 'world']
False
False
True
['my', 'name', 'is', 'dongGe']
my name is dongGe
my_name_is_dongGe
列表操作
#!/usr/bin/python
# encoding
namelist=["xiaoWang","xiaoZhang","xiaoHua"]
print(namelist)
print(namelist[1])
for name in namelist:
print("for:"+name)
length=len(namelist)
i=0;
while i<length:
print("while:"+namelist[i])
i=i+1
namelist.append("xiaoLi")
print(namelist)
a=[1,2]
b=[3,4]
print(a,b)
a.append(b)#整体添加,为嵌套
print(a)
a.extend(b)#逐一添加
print(a)
a.insert(1,3)#指定位置之前嵌套进去
print(a)
namelist[1]="xiaoLiu"#下标修改
print(namelist)
filename="xiaoWang"
if filename in namelist:
print("找到了")
else:
print("没找到")
a=['a','b','c','a','b']
print(a.index('a',1,4))#查找,没找到会报错,左闭右开
del namelist[1]#del根据下标删除
print(namelist)
namelist.pop()#默认删除最后一个
print(namelist)
namelist.remove("xiaoWang")#根据内容删除
print(namelist)
a=[1,4,2,3]
print(a)
a.reverse()#颠倒
print(a)
a.sort()#排序
print(a)
a.sort(reverse=True)#倒叙
print(a)
输出执行为
['xiaoWang', 'xiaoZhang', 'xiaoHua']
xiaoZhang
for:xiaoWang
for:xiaoZhang
for:xiaoHua
while:xiaoWang
while:xiaoZhang
while:xiaoHua
['xiaoWang', 'xiaoZhang', 'xiaoHua', 'xiaoLi']
[1, 2] [3, 4]
[1, 2, [3, 4]]
[1, 2, [3, 4], 3, 4]
[1, 3, 2, [3, 4], 3, 4]
['xiaoWang', 'xiaoLiu', 'xiaoHua', 'xiaoLi']
找到了
3
['xiaoWang', 'xiaoHua', 'xiaoLi']
['xiaoWang', 'xiaoHua']
['xiaoHua']
[1, 4, 2, 3]
[3, 2, 4, 1]
[1, 2, 3, 4]
[4, 3, 2, 1]
元组操作
aTuple=("et",77,99.9)
print(aTuple)
print(id(aTuple))
print(type(aTuple))
print(aTuple[1])
#aTuple[1]=55 #不能修改也不能删除,会报错
a=('a','b','c','a','b')
#a.index('a',1,3)#没有会报错
print(a.index('a',1,4))
print(a.count('a'))
执行输出为
('et', 77, 99.9)
31940520
<class 'tuple'>
77
3
2
字典操作为
#!/usr/bin/python
# encoding
info={'name':'班长','id':100,'sex':'f','address':'地球亚洲中国北京'}
print(info['name'])
print(info)
print(info['address'])
#print(info['age'])#不存在则会报错
#当我们不确定时用get方法,还可以设置默认值
age=info.get('age')#因为age不存在所以为None
print(type(age))
age=info.get('age',18)#不存在则会创建18
print(age)
info['id']=120#进行修改
print(info)
info['birth']='1997-03-30'#没有则创建键值对
print(info)
del info['birth']#删除键值对
print(info)
#del info#删除整个字典
# info.clear()#清空字典
# print(info)
print(len(info))#测量字典键值对
print(info.keys())#输出键的所有
print(info.values())#输出值的所有
print(info.items())#键值对方式输出所有
#print(info.has_key('name'))#如果key在为true
for key in info.keys():
print(key,end=" ")
print("\n")
for value in info.values():
print(value,end=" ")
print("\n")
for item in info.items():
print(item,end=" ")
print("\n")
for key,value in info.items():
print("key=%s,value=%s"%(key,value),end=" ")
print("\n")
chars=['a','b','c','d']
i=0
for chr in chars:
print("%d %s"%(i,chr))
i+=1
for j,chr in enumerate(chars):
print(j,chr)
输出为
班长
{'name': '班长', 'id': 100, 'sex': 'f', 'address': '地球亚洲中国北京'}
地球亚洲中国北京
<class 'NoneType'>
18
{'name': '班长', 'id': 120, 'sex': 'f', 'address': '地球亚洲中国北京'}
{'name': '班长', 'id': 120, 'sex': 'f', 'address': '地球亚洲中国北京', 'birth': '1997-03-30'}
{'name': '班长', 'id': 120, 'sex': 'f', 'address': '地球亚洲中国北京'}
4
dict_keys(['name', 'id', 'sex', 'address'])
dict_values(['班长', 120, 'f', '地球亚洲中国北京'])
dict_items([('name', '班长'), ('id', 120), ('sex', 'f'), ('address', '地球亚洲中国北京')])
name id sex address
班长 120 f 地球亚洲中国北京
('name', '班长') ('id', 120) ('sex', 'f') ('address', '地球亚洲中国北京')
key=name,value=班长 key=id,value=120 key=sex,value=f key=address,value=地球亚洲中国北京
0 a
1 b
2 c
3 d
0 a
1 b
2 c
3 d
