常用的数据分析软件和工具有哪些?
目录
- ①传统BI软件:SAP BO、IBM Cognos、Oracle BIEE
- ②敏捷BI软件:Tableau、Power BI、FineBI
三、统计分析软件:MATLAB、SPSS、Stata、SAS、EViews
一、基础软件:
Excel

Microsoft Excel是Microsoft为使用Windows和Apple Macintosh操作系统的电脑编写的一款电子表格软件。直观的界面、出色的计算功能和图表工具,再加上成功的市场营销,使Excel成为最流行的个人计算机数据处理软件。在1993年,作为Microsoft Office的组件发布了5.0版之后,Excel就开始成为所适用操作平台上的电子制表软件的霸主。
Excel的功能很强大,能做的事情很多,不仅仅可以做数据存储和制作工作表,与数据分析有关的功能还有这些:
- 各种处理数据的函数
- 条件格式
- 数据图表
- 外部图表
- 分类汇总
- 数据透视表/数据透视图
- VBA编程
- ……
SQL

结构化查询语言是高级的非过程化编程语言,允许用户在高层数据结构上工作。它不要求用户指定对数据的存放方法,也不需要用户了解具体的数据存放方式,所以具有完全不同底层结构的不同数据库系统, 可以使用相同的结构化查询语言作为数据输入与管理的接口。结构化查询语言语句可以嵌套,这使它具有极大的灵活性和强大的功能。
我们做数据分析工作时,多数数据来源于信息系统后台的数据库,SQL非常方便我们访问和查询数据库。我们做数据分析工作时,多数数据来源于数据库,SQL非常方便我们访问和查询数据库。
二、BI软件:
①传统BI软件:
SAP BO

SAP BusinessObjects Business Intelligence是用于数据报告,可视化和共享的集中式套件。作为SAP业务技术平台的本地BI层,它将数据转换为有用的见解,可随时随地使用。
随着大数据时代的来临,BI分析工具也热火朝天的发展起来。由于一直在做SAP的BI产品,所以主要围绕着SAP BO提供的报表工具做一个简单的选型介绍。
目前SAP BO提供了下列组件供我们选择:

BIP:称为BOE平台,作为核心的BO组件,为我们提供了门户支持(LaunchPad,支持浏览器、Mobile App),报表开发平台(Workspace),语义层连接(OLAP等连接)等功能。
Crystal Report:固定格式报表,财务三大表的优秀载体,但是不支持即席查询。
Web Intelligence:分析型报表,支持多维分析,可以进行简单的数据挖掘,与Excel良好集成,不过打印功能一直是个缺陷。
Dashboard:水晶易表,可以做管理驾驶舱、核心KPI预警等,以数据可视化为主要目的,更直观的展示数据。
Explorer:功能更多偏向数据探索,对现有数据进行简单分析、研究,并对部分关注的指标进行对比,以便发现不同指标间的联系,指导管理决策。
BI Mobile:两款Mobile客户端,SAP BusinessObjects Mobile & SAP BusinessObjects Explorer,分别对应了不同的报表工具,IOS系统可以直接在AppStore中下载使用,具体功能不多说了。
Analysis:类似Explorer,MSOffice版本的与Excel优秀集成,可以从BW的模型、Query,BO的Universe、报表等对象中拉取数据做分析,对比数据非常方便。
Visual Intelligence:新的一款数据可视化工具,目前已经改名为Lumira,对HANA有着优秀的集成能力,轻松查看HANA的分析结果。
IBM Cognos

Cognos是在BI核心平台之上,以服务为导向进行架构的一种数据模型,是唯一可以通过单一产品和在单一可靠架构上提供完整业务智能功能的解决方案。它可以提供无缝密合的报表、分析、记分卡、仪表盘等解决方案,通过提供所有的系统和资料资源,以简化公司各员工处理资讯的方法。作为一个全面、灵活的产品,Cognos业务智能解决方案可以容易地整合到现有的多系统和数据源架构中。
Cognos提供与IBM DB2,Microsoft SQL Server和NCR Teradata的整合数据库软件。公司同样与企业资源计划(Enterprise Resource Planning,ERP)供应商有合作,如SAP、J.D. Edwards、 Oracle、 PeopleSoft和Baan。Cognos最近的发展方向是提供更多的基于互联网的软件版本,以及为无线设备提供解决方案。
大模块来看, Cognos产品组件只有三个:
- Cognos Powerplay Transformation Server:负责将数据源变成数据立方体;
- Cognos Powerplay Enterprise Server:负责将数据立方体以OLAP分析、OLAP报表等方式展现出来;
- Cognos ReportNet Server:负责实现基于数据库的数据查询、报表制作、仪表盘制作、报表/仪表盘展示等等;
Oracle BIEE

Oracle BIEE(简称BIEE)作为Oracle的新的商业智能平台企业版,起源于Oracle所收购的Siebel公司,BIEE原来叫做Siebel Analytic。
Oracle BIEE是一个非常有创造力的工具,它对于物理层,逻辑层,展现层的理解和定义创造了一个非常简洁而清晰的数据模型,使用这个数据模型可以完整地连接企业内各个异构数据源,从而使商业智能真正能够在企业范围内得到大规模部署和使用。
BIEE:Oracle Business Intelligence Enterprise Edition Oracle在05年底收购Siebel,取其前端开发工具Siebel Analytics作为Oracle BI的新平台。区别原Discoverer起见,称为Enterprise Edition,而原来的Discoverer就变成了Standard Edition了。二者各取部分结合,加个xe,于是又有所谓的Standards Edition One.这就是OBIEE、OBISE和OBISE ONE的简单缘起。 07年Oracle收了Hyperion,于是取Hyperion BI的部分组件,合并升级为现在的OBI EE Plus。
BIEE的数据模型分为3层:
1、 物理层Physical,用于定义和连接各类异构数据源,型数据库、符合XML规范的源数据、OLAP服务、Essbase、Excel等,具体定义数据源物理表结构、字段数据类型、主外键。可简单理解为“物理表定义”。值得一提的是,BIEE只是保存定义,并没有存储数据本身。物理层通过“连接池”、“缓存查询结果”等技术来提高性能。
2、 逻辑层Business Model and Mapping,基于物理层构建的DW多维数据模型如星型模型或雪花模型,以及定义逻辑模型与物理模型间的映射关系。需要定义事实表和维度表的主外键关系,可以定义维度表的层次和事实表的度量。这里是整个BIEE的设计核心,需要“整合”开发人员和业务人员两种视觉。一个逻辑层的表,可能来自多个物理层的表;一个逻辑层的字段,可以来自多个物理层的多个表。
3、 展现层Presentation,该层隐藏掉任何技术术语和模型,去掉任何业务不关心的字段如ID列,以最终用户的视角和术语行描述。最常见的做法是面对不同的用户组——业务部门,来设计不同的展现层分析项。这样做的好处是:可以把报表开发更加完善,符合最终用户的需求。
②敏捷BI软件:
Tableau
Tableau Software致力于帮助人们查看并理解数据。Tableau 帮助任何人快速分析、可视化并分享信息。超过 42,000 家客户通过使用 Tableau 在办公室或随时随地快速获得结果。数以万计的用户使用 Tableau Public 在博客与网站中分享数据。
Tableau公司将数据运算与美观的图表完美地嫁接在一起。它的程序很容易上手,各公司可以用它将大量数据拖放到数字“画布”上,转眼间就能创建好各种图表。这一软件的理念是,界面上的数据越容易操控,公司对自己在所在业务领域里的所作所为到底是正确还是错误,就能了解得越透彻。
Power BI

Microsoft Power BI 是一系列的软件服务、应用和连接器,这些软件服务、应用和连接器协同工作,将不相关的数据源转化为合乎逻辑、视觉上逼真的交互式见解。 不管你的数据是简单的 Microsoft Excel 工作簿,还是基于云的数据仓库和本地混合数据仓库的集合,Power BI 都可让你轻松连接到数据源,可视化(或发现)重要信息,并与所需的任何人共享这些信息。
Power BI 的组成部分:
Power BI 由名为 Power BI Desktop 的 Microsoft Windows 桌面应用程序、名为 Power BI 服务的联机 SaaS(软件即服务)以及可在任意设备上使用的移动版 Power BI 应用(包含适用于 Windows、iOS 和 Android 的本机移动 BI 应用)组成。
FineBI

FineBI是帆软软件有限公司推出的一款商业智能(Business Intelligence)产品,它可以通过最终业务用户自主分析企业已有的信息化数据,帮助企业发现并解决存在的问题,协助企业及时调整策略做出更好的决策,增强企业的可持续竞争性。
系统架构
数据处理:数据处理服务,用来对原始数据进行抽取,转换,加载。为分析服务生成数据仓库FineCube。
即时分析:可以选择数据快速创建表格或者图表以使数据可视化、添加过滤条件筛选数据,即时排序,使数据分析更快捷。
多维度分析:OLAP分析实现,提供各种分析挖掘功能和预警功能,例如任意维度切换,添加,多层钻取,排序,自定义分组,智能关联等等。
Dashboard:提供各种样式的表格和多种图表服务,配合各种业务需求展现数据。
三、统计分析软件:
MATLAB

MATLAB是美国MathWorks公司出品的商业数学软件,用于数据分析、无线通信、深度学习、图像处理与计算机视觉、信号处理、量化金融与风险管理、机器人,控制系统等领域。
MATLAB是matrix&laboratory两个词的组合,意为矩阵工厂(矩阵实验室),软件主要面对科学计算、可视化以及交互式程序设计的高科技计算环境。它将数值分析、矩阵计算、科学数据可视化以及非线性动态系统的建模和仿真等诸多强大功能集成在一个易于使用的视窗环境中,为科学研究、工程设计以及必须进行有效数值计算的众多科学领域提供了一种全面的解决方案,并在很大程度上摆脱了传统非交互式程序设计语言(如C、Fortran)的编辑模式。
MATLAB和Mathematica、Maple并称为三大数学软件。它在数学类科技应用软件中在数值计算方面首屈一指。行矩阵运算、绘制函数和数据、实现算法、创建用户界面、连接其他编程语言的程序等。MATLAB的基本数据单位是矩阵,它的指令表达式与数学、工程中常用的形式十分相似,故用MATLAB来解算问题要比用C,FORTRAN等语言完成相同的事情简捷得多,并且MATLAB也吸收了像Maple等软件的优点,使MATLAB成为一个强大的数学软件。在新的版本中也加入了对C,FORTRAN,C++,JAVA的支持。
SPSS

1984年SPSS总部首先推出了世界上第一个统计分析软件微机版本SPSS/PC+,开创了SPSS微机系列产品的开发方向,极大地扩充了它的应用范围,并使其能很快地应用于自然科学、技术科学、社会科学的各个领域。世界上许多有影响的报刊杂志纷纷就SPSS的自动统计绘图、数据的深入分析、使用方便、功能齐全等方面给予了高度的评价。
Stata

Stata的统计功能很强,除了传统的统计分析方法外,还收集了近20年发展起来的新方法,如Cox比例风险回归,指数与Weibull回归,多类结果与有序结果的logistic回归,Poisson回归,负二项回归及广义负二项回归,随机效应模型等。具体说, Stata具有如下统计分析能力:
数值变量资料的一般分析:参数估计,t检验,单因素和多因素的方差分析,协方差分析,交互效应模型,平衡和非平衡设计,嵌套设计,随机效应,多个均数的两两比较,缺项数据的处理,方差齐性检验,正态性检验,变量变换等。
分类资料的一般分析:参数估计,列联表分析 ( 列联系数,确切概率 ) ,流行病学表格分析等。
等级资料的一般分析:秩变换,秩和检验,秩相关等
相关与回归分析:简单相关,偏相关,典型相关,以及多达数十种的回归分析方法,如多元线性回归,逐步回归,加权回归,稳键回归,二阶段回归,百分位数 ( 中位数 ) 回归,残差分析、强影响点分析,曲线拟合,随机效应的线性回归模型等。
其他方法:质量控制,整群抽样的设计效率,诊断试验评价, kappa等。
SAS

SAS(全称STATISTICAL ANALYSIS SYSTEM,简称SAS)是全球最大的私营软件公司之一,是由美国北卡罗来纳州立大学1966年开发的统计分析软件。
1976年SAS软件研究所(SAS INSTITUTE INC)成立,开始进行SAS系统的维护、开发、销售和培训工作。期间经历了许多版本,并经过多年来的完善和发展,SAS系统在国际上已被誉为统计分析的标准软件,在各个领域得到广泛应用。
1966年,美国农业部(USDA)收集到巨量的农业数据,急需一种计算机化统计程序来对其进行分析。由美国国家卫生研究院(NIH)资助的八所大学联合会共同解决了这一问题。 最终,统计分析系统(statistical analysis system),也就是SAS应运而生,既给了SAS公司一个响亮的名字,亦成为了公司化运作的起点。
位于北卡罗来纳州首府罗利市的北卡罗来纳州立大学(NCSU)成为该联盟的领导者,因为其更为强大的大型中央处理计算机计算能力而胜出。 NCSU教职员工Jim Goodnight和Jim Barr成为项目负责人。 Barr创建了整个架构,Goodnight则负责实施和实现架构上的各种功能特性,并拓展了系统的性能。 当NIH于1972年停止供资时,社团联盟同意为该项目提供资金,使NCSU能够继续开发维护系统运作,从而支持其统计分析需求。
EViews
![]()
EViews是Econometrics Views的缩写,通常称为计量经济学软件包。是专门为大型机构开发的、用以处理时间序列数据的时间序列软件包的新版本。
EViews是Econometrics Views的缩写,直译为计量经济学观察,通常称为计量经济学软件包。它的本意是对社会经济关系与经济活动的数量规律,采用计量经济学方法与技术进行“观察”。计量经济学研究的核心是设计模型、收集资料、估计模型、检验模型、应用模型(结构分析、经济预测、政策评价)。EViews是完成上述任务比较得力的必不可少的工具。正是由于EViews等计量经济学软件包的出现,使计量经济学取得了长足的进步,发展成为一门较为实用与严谨的经济学科。
四、数据分析编程语言
Python

Python是一种跨平台的计算机程序设计语言。 是一个高层次的结合了解释性、编译性、互动性和面向对象的脚本语言。最初被设计用于编写自动化脚本(shell),随着版本的不断更新和语言新功能的添加,越多被用于独立的、大型项目的开发。
Python是一门简单易学且功能强大的编程语言。它拥有高效的高级数据结构,并且能够用简单而又高效的方式进行面向对象编程。 Python优雅的语法和动态类型,再结合它的解释性,使其在许多领域成为编写脚本或开发应用程序的理想语言。
近年来,数据分析工作岗位变得越来越受欢迎,很多人都开始转行做数据分析。而大家也知道,有多种语言都可应用于数据分析,但Python却成为大家的首选,那么为什么使用Python做数据分析?我们来看看原因吧。
Python的语法简单,代码可读性高,容易入门,有利于初学者学习;当我们进行数据处理的时候,我们希望将数据变得数值化,变成计算机可以运作的数字形式,我们可以直接使用一行列表推导式完成,十分简单。
Python在数据分析和交互、探索性计算以及数据可视化等方面都有非常成熟的库和活跃的社区,让Python成为数据任务处理重要解决方案。在数据处理和分析方面,Python拥有numpy、pandas、matplotlib、scikit-learn、ipython等优秀的库以及工具,尤其是pandas在处理数据方面有着绝对优势。
Python拥有强大的通用编程能力,有别于R语言,Python不仅在数据分析方面能力强大,在爬虫、WEB、自动化运维甚至于游戏等领域都有非常不错的作用,公司只需要使用一种技术就可以完成全部服务,有利于业务融合,也可以提高工作效率。
Python是人工智能首选的编程语言,在人工智能时代,Python成为最受欢迎的编程语言。得益于Python简洁、丰富的库和社区,大部分深度学习框架都优先支持Python语言。
R语言

R是用于统计计算和图形的语言和环境。这是一个类似于S语言和环境的GNU项目,该项目是由约翰·钱伯斯及其同事在贝尔实验室(原AT&T,现为朗讯技术公司)开发的。R可以看作是S的不同实现。存在一些重要的区别,但是为S编写的许多代码在R的情况下不会改变。
R提供了各种各样的统计信息(线性和非线性建模,经典统计检验,时间序列分析,分类,聚类……)和图形技术,并且具有高度的可扩展性。S语言通常是统计方法论研究的首选工具,R语言提供了一种开放源代码的途径来参与该活动。
R的优势之一是可以轻松制作出精心设计的具有出版质量的图表,包括需要时的数学符号和公式。对于图形中次要设计选项的默认值,我们已格外小心,但用户保留完全控制权。
根据自由软件基金会的GNU通用公共许可证的条款,R可作为自由软件以源代码形式获得。它可以在各种UNIX平台和类似系统(包括FreeBSD和Linux),Windows和MacOS上编译并运行。
五、大数据分析框架
①批处理:
MapReduce

MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算。概念"Map(映射)"和"Reduce(归约)",是它们的主要思想,都是从函数式编程语言里借来的,还有从矢量编程语言里借来的特性。它极大地方便了编程人员在不会分布式并行编程的情况下,将自己的程序运行在分布式系统上。 当前的软件实现是指定一个Map(映射)函数,用来把一组键值对映射成一组新的键值对,指定并发的Reduce(归约)函数,用来保证所有映射的键值对中的每一个共享相同的键组。
MapReduce是面向大数据并行处理的计算模型、框架和平台,它隐含了以下三层含义:
1)MapReduce是一个基于集群的高性能并行计算平台(Cluster Infrastructure)。它允许用市场上普通的商用服务器构成一个包含数十、数百至数千个节点的分布和并行计算集群。
2)MapReduce是一个并行计算与运行软件框架(Software Framework)。它提供了一个庞大但设计精良的并行计算软件框架,能自动完成计算任务的并行化处理,自动划分计算数据和计算任务,在集群节点上自动分配和执行任务以及收集计算结果,将数据分布存储、数据通信、容错处理等并行计算涉及到的很多系统底层的复杂细节交由系统负责处理,大大减少了软件开发人员的负担。
3)MapReduce是一个并行程序设计模型与方法(Programming Model & Methodology)。它借助于函数式程序设计语言Lisp的设计思想,提供了一种简便的并行程序设计方法,用Map和Reduce两个函数编程实现基本的并行计算任务,提供了抽象的操作和并行编程接口,以简单方便地完成大规模数据的编程和计算处理。
Spark
![]()
Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎。Spark是UC Berkeley AMP lab (加州大学伯克利分校的AMP实验室)所开源的类Hadoop MapReduce的通用并行框架,Spark,拥有Hadoop MapReduce所具有的优点;但不同于MapReduce的是——Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce的算法。
Spark 是一种与 Hadoop 相似的开源集群计算环境,但是两者之间还存在一些不同之处,这些有用的不同之处使 Spark 在某些工作负载方面表现得更加优越,换句话说,Spark 启用了内存分布数据集,除了能够提供交互式查询外,它还可以优化迭代工作负载。
Spark 是在 Scala 语言中实现的,它将 Scala 用作其应用程序框架。与 Hadoop 不同,Spark 和 Scala 能够紧密集成,其中的 Scala 可以像操作本地集合对象一样轻松地操作分布式数据集。
尽管创建 Spark 是为了支持分布式数据集上的迭代作业,但是实际上它是对 Hadoop 的补充,可以在 Hadoop 文件系统中并行运行。通过名为 Mesos 的第三方集群框架可以支持此行为。Spark 由加州大学伯克利分校 AMP 实验室 (Algorithms, Machines, and People Lab) 开发,可用来构建大型的、低延迟的数据分析应用程序。
②流处理:
Spark Streaming

Spark Streaming 是 Spark 核心 API 的一个扩展,可以实现高吞吐量的、具备容错机制的实时流数据的处理。
Spark Streaming 支持从多种数据源获取数据,包括 Kafka、Flume、Twitter、ZeroMQ、Kinesis 以及 TCP Sockets。从数据源获取数据之后,可以使用诸如 map、reduce、join 和 window 等高级函数进行复杂算法的处理,最后还可以将处理结果存储到文件系统、数据库和现场仪表盘中。
在 Spark 统一环境的基础上,可以使用 Spark 的其他子框架,如机器学习、图计算等,对流数据进行处理。Spark Streaming 处理的数据流如下面图 1 所示。
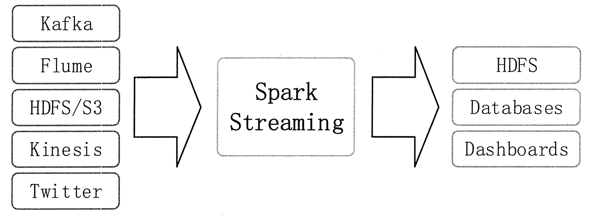
图 1 Spark Streaming处理的数据流
与 Spark 的其他子框架一样,Spark Streaming 也是基于核心 Spark 的。Spark Streaming 在内部的处理机制是,接收实时的输入数据流,并根据一定的时间间隔(如 1 秒)拆分成一批批的数据,然后通过 Spark Engine 处理这些批数据,最终得到处理后的一批批结果数据。它的工作原理如图 2 所示。

图 2 Spark Streaming 原理
Spark Streaming 支持一个高层的抽象,叫作离散流(DiscretizedStream)或者 DStream,它代表连续的数据
DStream 既可以利用根据 Kafka、Flume 和 Kinesis 等数据源获取的输入数据流来创建,也可以在其他 DStream 的基础上通过高阶函数获得。
在内部,DStream 是由一系列 RDD 组成的。一批数据在 Spark 内核中对应一个 RDD 实例。因此,对应流数据的 DStream 可以看成是一组 RDD,即 RDD 的一个序列。也就是说,在流数据分成一批一批后,会通过一个先进先出的队列,Spark Engine 从该队列中依次取出一个个批数据,并把批数据封装成一个 RDD,然后再进行处理。
Flink

Apache Flink是由Apache软件基金会开发的开源流处理框架,其核心是用Java和Scala编写的分布式流数据流引擎。Flink以数据并行和流水线方式执行任意流数据程序,Flink的流水线运行时系统可以执行批处理和流处理程序。此外,Flink的运行时本身也支持迭代算法的执行。
任何类型的数据都是作为事件流产生的。信用卡交易,传感器测量,机器日志或网站或移动应用程序上的用户交互,所有这些数据均作为流生成。
数据可以作为无界流或有界流处理。
-
无界流有一个起点,但没有定义的终点。它们不会终止并在生成数据时提供数据。无界流必须被连续处理,即,事件在被摄取后必须被及时处理。无法等待所有输入数据到达,因为输入是无界的,并且在任何时间都不会完成。处理无边界数据通常需要以特定顺序(例如事件发生的顺序)来摄取事件,以便能够推断出结果的完整性。
-
有界流具有定义的开始和结束。可以通过在执行任何计算之前提取所有数据来处理有界流。由于有界数据集始终可以排序,因此不需要有序摄取即可处理有界流。绑定流的处理也称为批处理。

③交互式处理:
Hive

hive是基于Hadoop的一个数据仓库工具,用来进行数据提取、转化、加载,这是一种可以存储、查询和分析存储在Hadoop中的大规模数据的机制。hive数据仓库工具能将结构化的数据文件映射为一张数据库表,并提供SQL查询功能,能将SQL语句转变成MapReduce任务来执行。Hive的优点是学习成本低,可以通过类似SQL语句实现快速MapReduce统计,使MapReduce变得更加简单,而不必开发专门的MapReduce应用程序。hive十分适合对数据仓库进行统计分析。
因此,hive 并不适合那些需要高实时性的应用,例如,联机事务处理(OLTP)。hive 查询操作过程严格遵守Hadoop MapReduce 的作业执行模型,hive 将用户的hiveQL 语句通过解释器转换为MapReduce 作业提交到Hadoop 集群上,Hadoop 监控作业执行过程,然后返回作业执行结果给用户。hive 并非为联机事务处理而设计,hive 并不提供实时的查询和基于行级的数据更新操作。hive 的最佳使用场合是大数据集的批处理作业,例如,网络日志分析。
Spark SQL

spark SQL的架构如图16-12所示,在Shark原有的架构上重写了逻辑执行计划的优化部分,解决了Shark存在的问题。Spark SQL在Hive兼容层面仅依赖HiveQL解析和Hive元数据,也就是说,从HQL被解析成抽象语法树(AST)起,就全部由Spark SQL接管了。Spark SQL执行计划生成和优化都由Catalyst(函数式关系查询优化框架)负责。
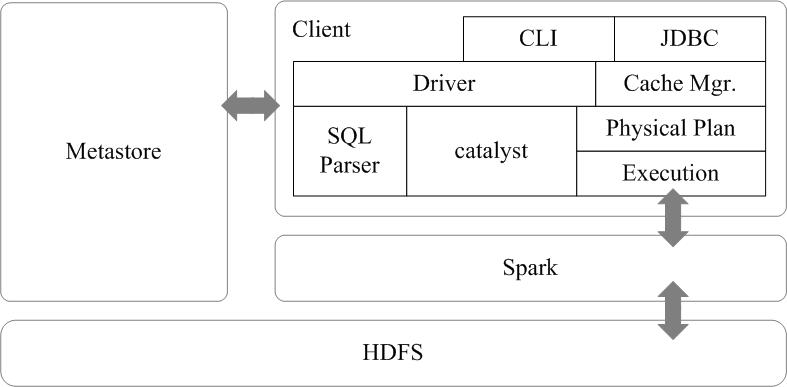
图16-12-Spark-SQL架构
Spark SQL增加了SchemaRDD(即带有Schema信息的RDD),使用户可以在Spark SQL中执行SQL语句,数据既可以来自RDD,也可以来自Hive、HDFS、Cassandra等外部数据源,还可以是JSON格式的数据。Spark SQL目前支持Scala、Java、Python三种语言,支持SQL-92规范。从Spark1.2 升级到Spark1.3以后,Spark SQL中的SchemaRDD变为了DataFrame,DataFrame相对于SchemaRDD有了较大改变,同时提供了更多好用且方便的API,如图16-13所示。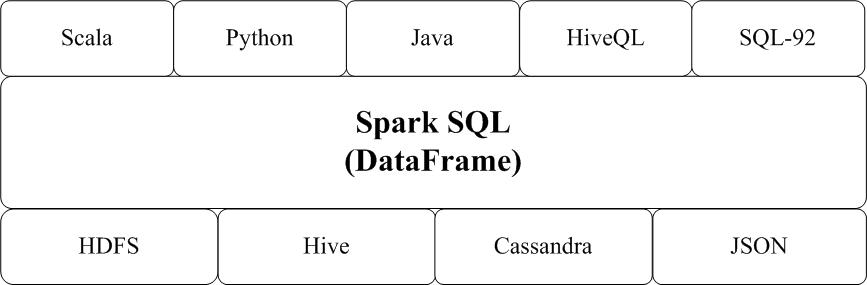
图16-13-Spark-SQL支持的数据格式和编程语言
Spark SQL可以很好地支持SQL查询,一方面,可以编写Spark应用程序使用SQL语句进行数据查询,另一方面,也可以使用标准的数据库连接器(比如JDBC或ODBC)连接Spark进行SQL查询,这样,一些市场上现有的商业智能工具(比如Tableau)就可以很好地和Spark SQL组合起来使用,从而使得这些外部工具借助于Spark SQL也能获得大规模数据的处理分析能力。
数据科学交流群,群号:189158789 ,欢迎各位对数据科学感兴趣的小伙伴的加入!
深信积累的力量,时间就是你最好的朋友,否则它就是你最大的敌人。
如果你想分享此文章,请注明:作者:PurStar 出处:www.cnblogs.com/purstar

 浙公网安备 33010602011771号
浙公网安备 33010602011771号