
Python数据处理库pandas基本使用
---恢复内容开始---
pandas提供过便于操作数据的数据类型,也提供了许多分析函数和分析工具,使得数据分析易于操作。

一、pandas库中Series类型
Series可以生成数据的索引(自动索引和自定义索引),见下例:
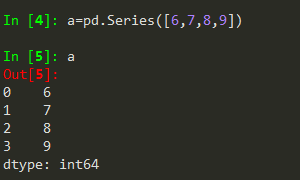

Series可从标量(必须有index)、字典(直接应用Series函数)、ndarray、列表构建。
基本操作:类似于ndarray和字典类型。可以用自定义索引b['b']=7, 也可以用自动生成的自动索引b[1]=7,但注意不可混合使用。如
b[['c', 'd', 0]]输出的第三个元素为NaN , 其切片和运算操作与ndarray基本相同,见下例:
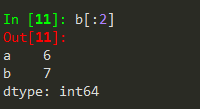
in 在列表或ndarray类型中表示某值是否在列表或ndarray中,而对于Series类型是判断是否在对象的索引列表中。
b.get('f', 100) 返回索引值'f'对应的值,若没有则返回100 。
两个Series类型a+b相加,得到Series类型c,则c的索引值为a和b索引值的并,c的值分为两种情况,若索引值在a和b中都存在,则对应值相加;否则(只存在于a和b中的一个),对应值为空。
可以给Series对象起名字,如b.name='匹配'。
二、Pandas库的DataFrame类型
由索引和多列数据构成,可以理解为一个表格。其每列值的类型可以不同,且既有行索引也有列索引,常用于表达二维数据。
可由二维ndarray对象、一维列表等、Series类型、其他DataFrame类型创建。见下例:
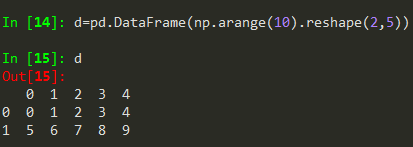
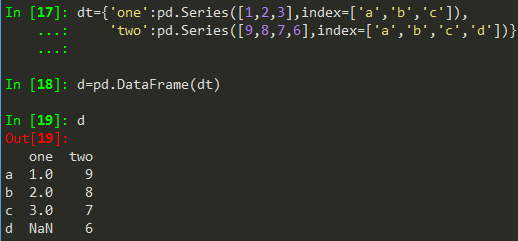
对于字典dl={'one':[1,2,3], 'two':[9,8,7]} 也可直接用pd.DataFrame(dt,index=['a', 'b', 'c', 'd'])来创建。
若要获得某个位置的数据,需要用到行列的联合索引,如d['a']['one']=1.0
d['one']可获得one对应的一列对象,包括行索引值。
d.ix['a']可获得a对应的一行对象,包括列索引值。
---恢复内容结束---
