
百亿级通用推荐系统实践
版权声明:本文由吕慧伟原创文章,转载请注明出处:
文章原文链接:https://www.qcloud.com/community/article/188
来源:腾云阁 https://www.qcloud.com/community
我们每个人每天都会使用到不同的推荐系统,无论是听歌,购物,看视频,还是阅读新闻,推荐系统都可以根据你的喜好给你推荐你可能感兴趣的内容。不知不觉之间,推荐系统已经融入到我们的生活当中。作为大数据时代最重要的几个信息系统之一,推荐系统主要有下面几个作用:
- 提升用户体验。通过个性化推荐,帮助用户快速找到感兴趣的信息。
- 提高产品销售。推荐系统帮助用户和产品建立精准连接,从而提高产品转化率。
- 发掘长尾价值。根据用户兴趣推荐,使得平时不是很热门的商品可以销售给特定的人群。
- 方便移动互联网用户交互。通过推荐,减少用户操作,主动帮助用户找到他感兴趣的内容。
以应用宝为例,对于两个不同用户A和B,打开应用程序的界面是很不一样的。用户A是一个年轻男性用户,平时可能喜欢玩手机游戏和看小说,所以应用宝的推荐系统会给他推荐游戏的应用。而用户B是一个年轻女性用户,平时喜欢购物和轻游戏,所以应用的推荐系统就会给她推荐购物的应用。这样一来,从用户的角度,减少了他找到自己喜欢的应用的时间;从产品的角度,用户更愿意去点击和安装他喜欢的应用,所以提高了产品的转化率。
图1. 应用宝首页界面
除了应用宝之外,腾讯云推荐系统还应用在腾讯的QQ空间、QQ、企鹅FM、QQ会员和黄钻贵族等12个不同的业务的200多个不同推荐场景,每天处理的推荐请求有上百亿个。那么,这个日均百亿级请求的推荐系统是怎么打造而成的呢?主要需要解决两个问题:
- 支持众多业务和场景。
- 支持海量用户请求。
1.通用化推荐算法库
首先要解决的问题是如何支持众多业务和场景。对于不同的场景,用到的数据、算法和模型都会有很多的不同,如果对于每个场景都从头开发,将会耗费非常多的时间和人力。那么有没有更好的方法呢?毕竟常用的推荐算法就是那么几种,有没有一种方法使得同一个推荐算法可以复用到不同的推荐场景呢?那就需要对推荐算法库进行通用化设计。
下面举一个例子来说明推荐系统是什么,又是怎么工作的。如图2所示,一个推荐系统是由学习系统、模型和推荐系统三部分组成的。其中,学习系统通过机器学习的方法对用户的历史数据进行统计、分析,从而训练得到一个模型。这个模型是用户行为规律的总结,会在后面预测系统中对新用户的请求进行预测。比如图中简单的例子,学习系统的输入是5个不同用户的行为,对于男性用户A,他喜欢的《王者荣耀》这个游戏,对于女性用户B,她喜欢的则是《奇迹暖暖》,那么对于这5个用户统计得到的模型是男性用户喜欢《王者荣耀》的概率是0.67,而女性用户喜欢《奇迹暖暖》的概率是1。有了这个简单的模型以后,如果在预测系统中有一个新的用户请求,来自一个男性用户,那么按照前面的模型,会按照概率的大小,把《王者荣耀》推荐给这个用户。
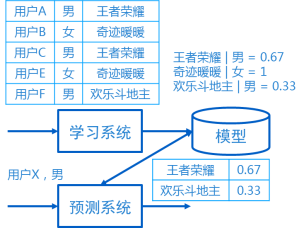
图2. 推荐系统例子
实际的推荐系统中,学习系统处理的用户数据量会更大,数据的维度也更多,用到的推荐模型也会更复杂,常用的有协同模型、内容模型和知识模型。其中,协同模型主要通过我的朋友喜欢什么来猜测我喜欢这么;内容模型则是根据物品本身来预测用户喜欢A所以也可能喜欢B;知识模型则是根据用户的限定条件,按照他的需要进行推荐。
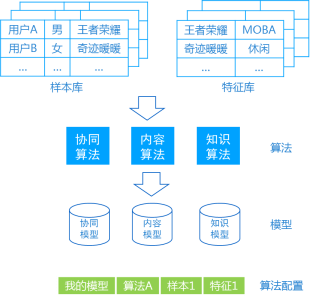
图3. 通用化推荐算法库
一个常见的推荐系统由下面四个部分组成:样本库、特征库、 算法和模型。其中,样本库存储从流水日志中提取的用户行为和特征;特征库存储用户和物品的属性等特征;算法是用于训练模型用到的机器学习算法;模型库存储的是从样本和特征计算得到的训练模型。为了不同的算法可以用于不同的样本和特征,我们可以使用图3中的算法配置表来存储数据、算法和模型的映射关系,将模型、算法、样本和特征的关系解耦,使得算法可以复用。比如,我的模型是从样本1和特征1使用算法A训练得到。
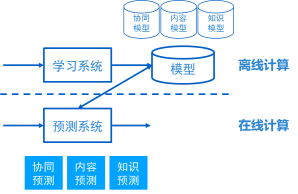
图4. 推荐系统的离线和在线计算分工
学习系统训练一个模型一般会花比较长的时间,这部分我们称为离线计算,对实时性要求并不高,比如,可以在几个小时的时间内计算出来,重要的是模型的质量。而预测系统则不一样,因为预测系统是直接面向用户请求,所以要求它响应快,同时必须能够处理海量用户的请求,系统必须稳定可靠。接下去我们会使用一个实时计算平台来满足这部分的要求。
2.面向海量在线服务的实时计算平台
除了前面提到的通用化算法库,我们需要解决的第二个问题是如何处理海量的用户请求。这部分我们用的是一个名为R2的面向海量在线服务的自研实时计算平台。R2有下面几个特点:
- 海量,目前在R2系统上,每天处理上百亿的个性化推荐请求;
- 实时,每个请求的处理平均延时为18ms;
- 可靠,系统稳定性为99.99%。
R2从一开始就是围绕线上服务而设计。首先,为了快速处理海量请求,我们参考了Apache Storm,把R2定义成一个流处理框架。其次,为了系统的高可用性,在设计的时候,考虑了系统不会出现单点故障。第三,为了方便扩容,计算资源是可插拔的。第四,系统可以支持动态调度以方便负载平衡。第五,为了方便运维,还紧密结合运维工具提供告警和监控。
我们先来看一下R2这个流处理框架是如何处理推荐请求的。如图5所示的推荐场景用于猜测用户喜欢的手机应用,可以分为三步来计算:
- 根据id得到用户特征;
- 使用决策树判断喜欢某个应用的概率;
- 对结果重新排序。其中,使用决策树这一步因为计算量大,可以通过并行计算来缩短处理时间,每个处理单元可以处理子树的一部分,最后在第三步将结果汇总以后重新排序。
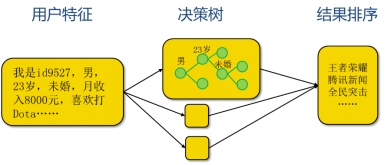
图5. 流计算场景:猜测用户喜欢的手机应用
R2的架构如图6所示,分为业务层、通信层和全局配置层三层。其中,业务层负责业务处理逻辑;通信层负责基于名字的通信和分布式流处理;全局配置层负责可适应的拓扑配置、动态扩缩容和动态负载调度。
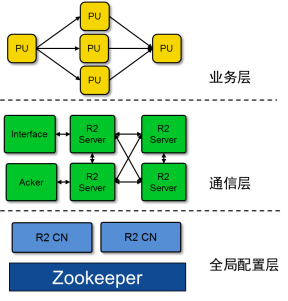
图6. 实时计算平台R2架构
其中,业务层由两部分组成:计算拓扑图和计算单元(PU)。计算拓扑图负责数据的流向,而计算单元负责业务的逻辑计算。通信层负责PU之间的通信以及拓扑图执行跟踪。其中,Interface负责从业务接入请求,Acker负责跟踪拓扑图执行情况,而R2Server负责转发PU之间的通信、启动PU和监控PU心跳。PU之间的通信都通过R2Server转发。全局配置层负责拓扑管理和名字服务,通过Zookeeper来进行动态配置。其中,拓扑管理将逻辑拓扑映射到物理拓扑,名字服务提供PU地址查询。
3.腾讯云推荐引擎
基于上面的经验,我们打造了腾讯云推荐引擎。腾讯云推荐引擎(CRE)是面向广大中小互联网企业打造的一站式云推荐引擎解决方案,提供安全、便捷、精准、可靠的推荐系统服务,提升其业务的点击转化率和用户体验。如图7所示,CRE由算法模型和在线计算两部分组成。算法模型部分由于采用了通用推荐算法库设计,用户在接入推荐场景时只需要通过简单配置,就可以直接使用已有的算法模版。在线计算部分集成了R2的优势,系统稳定可靠,并且支持快速扩容。
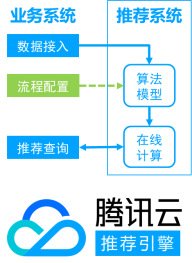
图7. 腾讯云推荐引擎
腾讯云推荐引擎具有下面的功能:
- 一天接入,快速上线;
- 模板化算法,节省99%代码;
- 快速扩容,应对业务快速增长;
- 稳定可靠,节省运维开销。
这些功能降低了推荐系统的技术门槛,使得搭建推荐系统变得简单便捷。更多有关腾讯云推荐引擎的信息请点击查看
4.总结
综上所述,要打造一个百亿级通用推荐系统,需要考虑下面几点:
1.为了能够支持尽可能多的业务和场景,推荐算法库需要做通用化设计。
2.为了支撑海量在线用户的实时请求,实时计算平台必须低延时,可扩展,而且稳定可靠。
3.云推荐引擎的解决方案,在通用化的基础上,同时考虑了易用性,方便用户接入。
目前腾讯云推荐引擎正在内测中,更多信息请点击查看

 浙公网安备 33010602011771号
浙公网安备 33010602011771号