
【文智背后的奥秘】系列篇——海量数据抓取
版权声明:本文由文智原创文章,转载请注明出处:
文章原文链接:https://www.qcloud.com/community/article/138
来源:腾云阁 https://www.qcloud.com/community
大数据已经是个非常热门的话题,文智平台正是基于大数据的背景,利用并行计算系统和分布式爬虫系统,结合独特的语义分析技术, 一站式满足用户NLP、转码、抽取、全网数据抓取等中文语义分析需求的开放平台。现有的研究、工程应用方向基本上都是围绕着大数据的存储、计算等方面展开,但是对于一个基础环节——数据获取却很少有相关的介绍。本文重点围绕如何获取垂直海量数据展开讨论。
一.引言
数据的作用不言而喻,在各行各业中,分门别类的数据为用户的在线生活体验提供了基本的素材,附近的餐馆、即将上映的电影、最近热门新闻等等能够涵盖我们生活的方方面面。同时所有的这一切也成就了今天在各个垂直领域诸如大众点评、豆瓣、今日头条等专业的公司。具体到搜索业务来说,无论是多么优秀的架构、精准的算法,最终也是需要依赖完备、准确、及时的数据作为落地基础。
从搜索业务来看,数据的价值主要体现在如下几个方面:
-
直接提供搜索数据源。海量的数据为检索提供了必不可少的素材。为此数据工作的一个基本目标是数据完备性。完备性可以从两方面来理解,一方面是实体本身的完备,是0和1的关系,这是刚性需求,例如你搜索《来自星星的你》,如果没有这部片子,那么结果显然不能满足用户需求;另一方面是实体内部信息的完备,例如《来自星星的你》如果缺少了演员字段,那么你搜索“金秀贤”的时候可能依然得不到想要的结果。另外要提的一点是完备性通常还对时间有约束,热点资讯、突发事件等如果不能在第一时间呈现,那么对于用户来说都是个硬伤。
-
改善相关性质量。干净、精确的数据可以使得在相关性计算阶段减少歧义,改善召回品质,互联网中的数据鱼龙混杂,各个网站的水平也是良莠不齐,不做去噪直接使用的话往往会适得其反。通过高质量的数据补充,对最终结果的排序也有良好的辅助作用。例如豆瓣的影评分数、热度因子可以在视频搜索中辅助结果排序,并且可以改善数据刚上架时由于点击量缺失造成排序上不来这种冷启动的过程。
-
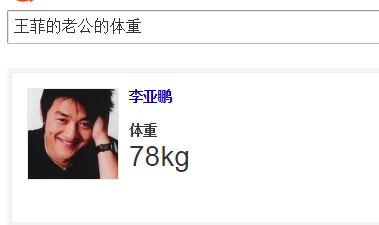
丰富搜索产品特性,满足搜索直达需求。当数据完备、及时、准确之后就可以对数据做关联聚合,在这个时候超越文本本身的各种语义特征、知识关联等一些高阶应用相继涌现,大家常常听到的Google的Knowledge Graph、Facebook的Graph Search以及百度知心搜索等都是建立在这一个基础之上。将散落在互联网上碎片化的知识整合起来形成直观答案显然是一种更“懂”你的方式。如图1,搜索王菲老公的体重,知识图谱搜索可以直接输出想要的结果。
![]()
图1、搜狗知识图谱搜索结果
总体而言,数据获取工作主要围绕快、准、全三个要素以及一个高阶的关联需求展开。本文重点分析数据如何发现、抓取、更新等方面做一个介绍。
二.数据发现
互联网中的数据良莠不齐,如何从纷繁复杂的互联网中发现有价值的数据是一个有趣的问题。通常数据发现的过程中存在几个难点:
-
数据海量,无法遍历穷举;
-
鱼龙混杂,需要甄别出高价值的数据;
-
存在死链、无效参数、作弊、陷阱等页面使得数据获取的过程中存在各种坑。
问题3这里我们需要结合不同的场景做一些不同的策略,一般在目标对象很清晰的情况下可以通过人工手段做一些规避,因此这里不展开讨论。我们重点讨论1和2这种海量网页中发现高价值数据的问题,有了这个清晰的目标后,接下来就转换为另外两个问题:
-
从哪个网站获取?
-
如何得到这个网站内有价值的链接?
问题1:如何获取有效站点?通常有下面几个办法:
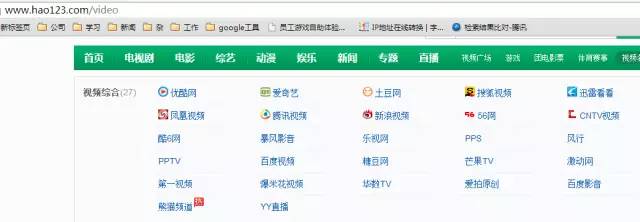
- 垂直榜单数据,一般领域内的热门站点都会存在于各大垂直榜单数据中,以视频站点为例,可以监控类似www.hao123.com上的垂直分类数据做提取收集
![]()
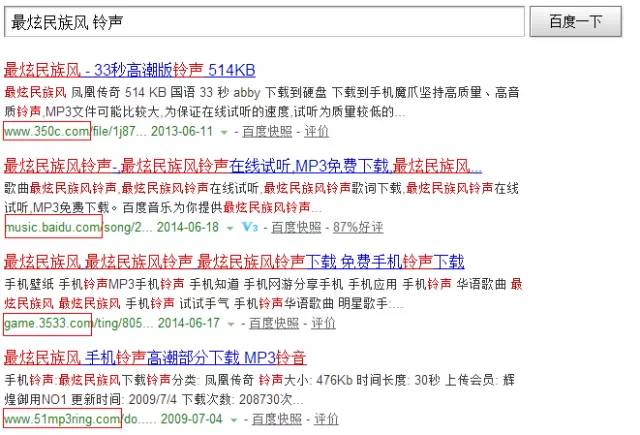
图2.垂直榜单数据 - 关键字提取,通常可以利用关键字到综合搜索引擎(google、百度等)中获取。这里有个问题就是关键字如何获取,一方面可以垂直引擎中的零结果的关键字或者其他低CTR关键字,另一方面可以利用已经积累的数据构造,例如想要获取音乐铃声类的站点,可以以“最炫民族风 铃声”构造出特定特征的关键字。
![]()
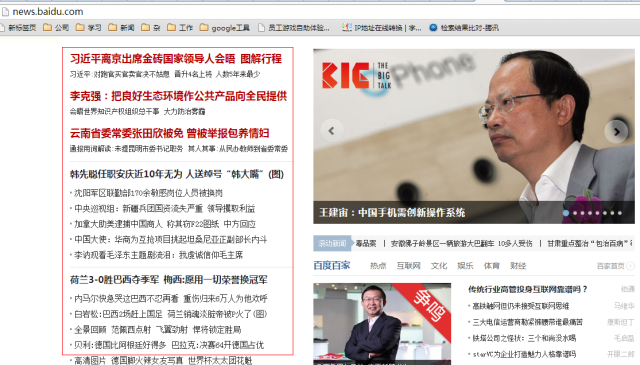
图3、关键字获取 - 同类垂直综合站点中爬取,以获取新闻站点为例,可以到http://news.baidu.com中将其中的链接抽取汇聚成特定的一些站点。
![]()
图4、综合类站点页面
问题2:如何从网站内得到高价值的链接呢?
一般的url都有一些显著特征,通常可以利用前面的方法2,利用大量的query到综合搜索引擎中做site检索获取大量同站点内url,这里基于一个假设就是搜索引擎能召回的数据都是亿万链接中尽量有价值的展现给用户,召回的结果已经融合了用户点击、数据本身质量、站点权威等因子在这里,是一个综合权威的结果。得到同站点url后我们可以分析其特征,对于一些显著特征占比的url可以认为是高价值链接的特征,例如百度百科http://baike.baidu.com/subview/(d+)/(d+).htm和http://baike.baidu.com/view/(d+).htm 类似这种特殊的片段。在得到高质量的特征的url后可以对库内已经抓取的数据做链接分析,反转父链子链关系汇聚出一些能产生高价值数据的父链作为种子持续发现高价值数据。图5展示了通过库内链接关系可以分析出http://news.163.com/latest/作为一个高质量种子页持续发现高价值数据。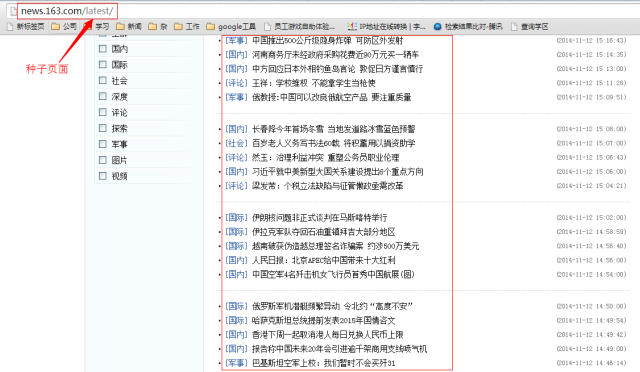
图5、高质量种子页面
三、数据抓取
前面我们介绍了如何获取有价值的url,得到url后通常需要将其抓取下来做后续的处理,如果量小可以使用curl库或者wget直接搞定,这里面临两个比较大的问题:
- 速度如果控制不好会导致被目标站点封禁;
- wget或者直接构造http请求只能获取到静态页面,对于动态页面只能获取到原始的一些js代码。
为此,我们需要一种爬虫引擎能够优雅、柔性的抓取,同时尽可能模拟浏览器的行为,使得抓取的结果能尽可能的完整。对于问题1可以有两种办法:
-
有效的压力控制,这里的压力是指单位时间内对目标站点的访问量,一是压力的计算需要根据对方站点规模(参考alexa排名)、pv量以及当前爬虫的规模做一个适当的计算,同时可以根据不同时间段做合适的调整,例如晚上通常目标网站的pv小我们可以适当提高我们抓取压力;
-
提高出口代理,尽量复用出口ip,由于外网ip的资源非常珍贵,需要提高出口ip的管理,按照运营商、地域、ip段进行分散管理,同时可以从外网获取一些公用的代理地址做补充。
对于问题2,则通常需要模拟浏览器的行为,研究浏览器js的解析、运行的一些行为,通常可以研究webkit做一些ajax异步拉取的填充,使得抓取的页面尽可能的和浏览器中访问看到的一致,这里并不展开webkit引擎的开发使用。
在回答了前面这两个问题后,介绍我们目前爬虫引擎的一个基本结构,主要由以下几部分组成:
-
access:接入模块,主要用于屏蔽多业务入口,在这里主要做屏蔽多业务入口,对外屏蔽后台各种处理逻辑,同时将url归一化后按照子域hash到对应的lcs模块中处理;
-
dns server和robots server:主要是存放请求dns解析的结果和robots解析的结果,采用key-value 的存储方式加上LRU淘汰策略,另外后台有逻辑定期更新。
-
lcs:引擎核心控制模块,控制了url下发的速度,lcs在收到请求后会先请求dns和robots,用以获得目标网站ip以及是否在robots范围内允许下载,对允许下载的url送入到排队队列中进行排队,同时对上游access发送的超额url做过载截断,使得系统满足压力控制,同时在这里对排队长度做一定的控制,降低排队时长,使得系统可以尽量的满足实时抓取的需求。
-
cs:纯粹的抓取模块,负责处理抓取中存在的各种问题,例如死链、跳转、压缩解压、chunck接受等问题,同时带有webkit的解析引擎会负责模拟浏览器行为对动态页面做解析抓取。
-
主控master:负责各个模块心跳检测,配置下发等一些控制模块
整个系统是一个完全无状态设计,尽量多逻辑做简单,除了一些系统内必备的重试之外其余的出错尽量在上层做重试。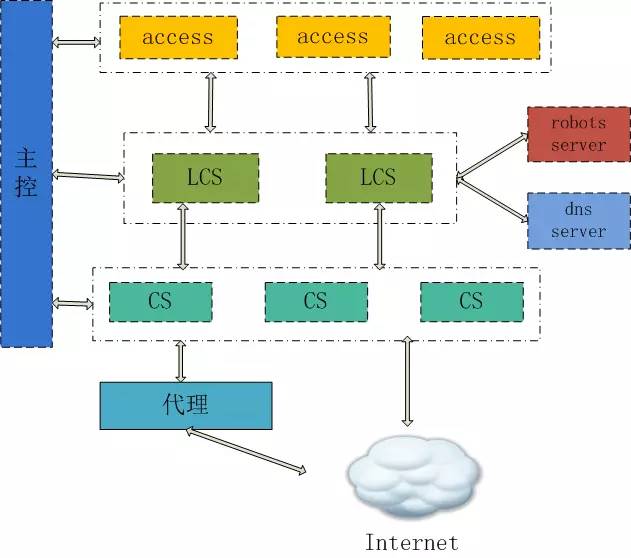
图6、爬虫引擎结构
四.数据抽取
有了抓取的数据之后需要对原始网页中的信息进行有效信息的加工提取,源于部门多年技术积累,我们对爬取的数据可以做两类抽取:
1.基于机器学习+规则实现的通用抽取方案,该方案通过预处理、Dom建树和css渲染等过程先对html进行dom解析,之后根据事先训练好的模型对网页进行分型操作,例如识别出新闻、论坛、小说等网页结构,最后根据文本长度、文本位置、标签名称等特征对网页进行分块抽取得到相关的信息。该方法是一个通用的解决方案,主要能够实现标题、正文抽取,网页结构分类等一些基础的抽取需求。对于一般常见的抽取服务即可满足需求。
图7、通用抽取部分抽取结果
2.基于url模板的结构化抽取方案,前面基于机器学习的方案只能满足通用的、相对粗糙的信息提取,无法对精准的字段做抽取。为此我们提供一种精确到字段的结构化抽取的方法,该方法的主要思路是事先配置好需要抽取内容的模版(模版可以是正则表达式或XPATH),然后基于html进行精确的模版匹配,最后将匹配结果输出即可。这里主要的难点在于xpath的配置的便捷性以及后续一些噪音的处理过程,这里不再展开赘述。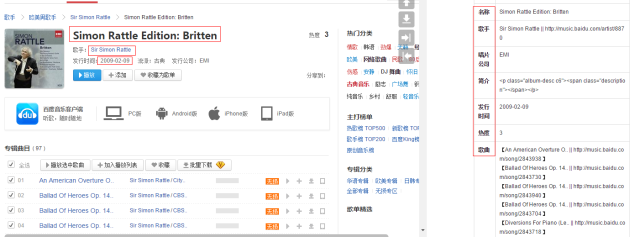
图8、结构化抽取结果
五.数据更新
通过前面的步骤我们可以完成数据的发现、抓取到入库,通常这个时候已经可以满足使用需求,但是对于影视类、知识类等数据常常是在更新变化的,对于此类数据为了保证数据的时新性、权威性需要进行不断的更新。更新的难点通常还是由于库内的数量巨大,如果需要全量短时间内更新的话在现有的资源规模基本上难以实现,通常主流的办法都是按照一定的策略做选取,选取出候选更新集做更新,之后再同步到全量数据集合中。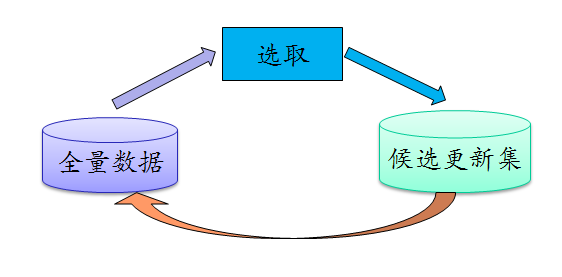
图9、数据更新
选取策略通常需要结合不同的业务特性做不同的策略。以视频为例,通常视频的剧集更新都是在一定的时间范围,国产剧集一般是每天凌晨24点,美剧则是周一周二,综艺则是周六周日。为此每次新抓取的数据都记录一个更新时间,通过分析库内连续剧集更新时间我们可以推断出下一次更新的时间,那么我们可以经过一轮大的选取,从全量数据中选取出当天可能会更新的数据,对这一批量小的数据进行更新。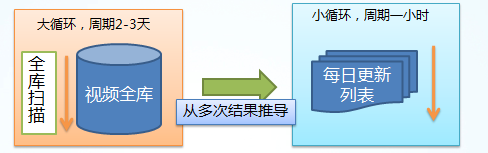
图10、视频更新策略
另外对于一些剧集,各大视频播放网站正在热播的数据则需要做到分钟级别的更新,一般这种量比较小,但是由于热度很高,所以其更新频率需要做到更高,为此对于榜单数据,我们通过分析抓取各垂直站点的热门榜单及分析微博数据,得到热门资源列表。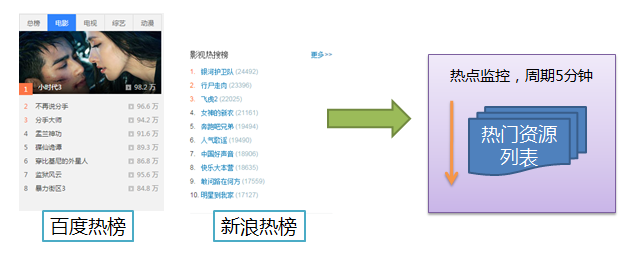
图11、榜单数据
更新则主要是体现在两个方面:一是页面发生变化,例如字段发生更新等情况;二是页面失效,变成死链。页面变化更新通常例如电视剧追剧、app应用版本的升级相应的内容发生变化。一般这里重新走一遍之前结构化抽取的流程即可。对于页面失效、死链这种可以从页面展现形态区分为页面级死链和内容级死链。页面级死链可以通过http返回码404直接识别。对于内容级死链我们通常有两个步骤同步进行验证:
- 死链特征提取,通过分析出死链样本学习出一定死链特征模型
- 竞品交叉验证,例如古剑奇谭如果检测到风行这个站点死链,那么可以到风行、soku、百度这些视频站点进行搜索比对,做一次竞品间的比对。
通过前面这两个步骤基本可以完成一轮失效检测。为了进一步修正模型,提高失效置信度,我们外加了一层人工抽样审核,并且将结果反馈到模型中,指导下一轮迭代运行。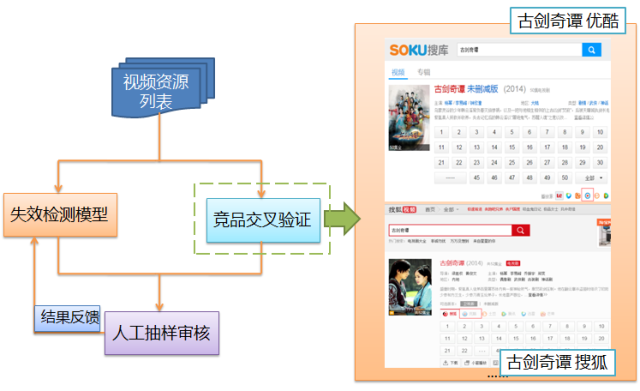
图12、失效检测
六.总结
总体而言,对于一个垂直的数据获取平台我们构建了如下的一个流程,主要分为下载发现、离线存储、抽取清洗三大块。调度发现包括了前面提到的页面发现、数据抓取、压力控制等内容,抓取后的数据主要由tbase、cfs等存储介质进行存储,之后我们有一套结构化抽取平台和通用抽取平台对数据进行规整、关联聚合形成独立供业务使用的结构化数据。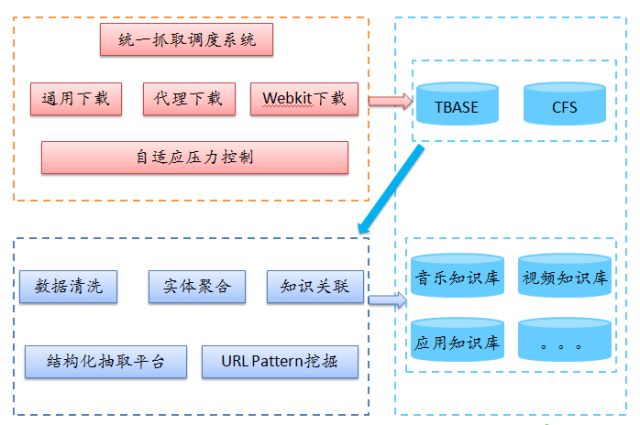
图13、垂直数据获取流程
数据抓取平台是我们一个基础平台,后续我们也会开放出相应的服务,并且持续对体验做优化,希望我们的服务能够更广泛的应用,为业务提供更大的价值。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号