

谈谈KV存储集群的设计要点
版权声明:本文由廖念波原创文章,转载请注明出处:
文章原文链接:https://www.qcloud.com/community/article/150
来源:腾云阁 https://www.qcloud.com/community
Key-value存储系统,是非常普遍的需求,几乎每个在线的互联网后台服务都需要KV存储,我们团队在KV存储方面,经历过几个时期,我自己深感要做好不容易。
这里扯远一点,展开说一下:
第一个时期,很早期的时候,我们的数据存储在mysql表里,按照用户账号简单的分库分表,为了保证访问高并发,利用每个mysql服务器的内存做数据缓存;主备两套分布在不同IDC,业务逻辑自己做副本同步。当时主要的问题是:内存的数据结构扩展困难、运维工作琐碎、数据同步机制本身的缺陷导致不能做异地IDC部署,这些缺点对于业务飞速发展、一地机房已经不够用的局面非常被动
第二个时期,我们设计了新的KV存储系统,其用户数据结构容易扩展、具备可以多地部署的数据同步机制,很好的应对了新时期业务发展的需要。为了设备成本考虑,我们把数据做冷热分离,访问频繁的数据会加载到专门的cache层,且对于不同的访问模型,挂载不同架构的cache,另外一个file层专门做数据持久化。这样的设计,使得架构太复杂,bug收敛速度慢,运维工作相比以前甚至更复杂了。
第三个时期,为了应对普遍的KV存储需求,我们以公共组件的形式重新设计了KV存储,作为团队标准的组件之一,得到了大规模的应用。结合同期抽象出来的逻辑层框架、路由管理等其他组件,团队的公共基础组件和运维设施建设的比较完备了,整个业务的开发和运维实现了标准化。但这个阶段就用了我们团队足足2年多时间。
不同于无数据的逻辑层框架,KV存储系统的架构设计会更复杂、运维工作更繁琐、运营过程中可能出现的状况更多、bug收敛时间会更长。一句话:团队自己做一个KV存储系统是成本很高的,而且也有比较高的技术门槛。
设计一个KV存储,需要考虑至少这些方面:
-
如何组织机器的存储介质,通常是内存、磁盘文件;例如用hash的方式组织内存
-
如何设计用户的数据结构,使得通用、易于扩展、存储利用率高;例如PB序列化、Json、XML方式
-
友好的访问接口,而不只是get / set一整个value
-
如何做集群分布、如何sharding、如何做到方便的扩缩容;例如一致性hash算法
-
如何做数据冗余、副本间如何同步、一致性问题;副本间如何选举master
-
备份与恢复、数据校验与容错
-
读写性能
-
其他可能的特殊需求:例如我们设计过一个KV存储,用于存储一些公众号的个数不受限粉丝列表
上面八点,业内的KV存储组件一般都会考虑到,或者各有特色,各自优势在伯仲之间。但是综合过去的经验教训,我们觉得有一点很容易被忽视:可运维性、运维自动化、黑盒化运维。
举一个例子,前面提到的我们第二个时期的KV存储系统,刚开始应用的时候,一次扩容过程会有10多步的运维操作,包括load数据、做增量同步、多次修改机器状态、数据比对等等,需要运维同事以高度的责任心来完成。另外就是运维同事必须如该KV存储架构设计者一样深刻理解系统背后的原理和细节,否则就不能很好的执行运维操作,这个要求也非常高,新老交接周期长,还容易出运维事故。
基于上面的考虑,同事为了让用户更容易学习和接受,毫秒服务引擎在redis cluster的基础上,实现了运维web化,并加上了集群的监控。
毫秒服务引擎(msec, 取英文名Mass Service Engine in Cluster的首字母组合)是腾讯一个开源框架,其创作冲动和构建经验,来自QQ后台团队超过10年的运营思考。官网:
毫秒引擎可以通过web界面方便的进行:
-
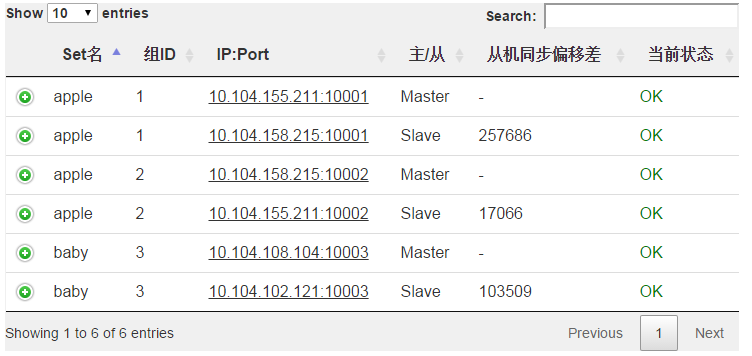
集群概要状态查看
![]()
-
可以在web上方便的完成日常的运维操作:新搭集群、扩缩容、故障机器的恢复:
![]()
-
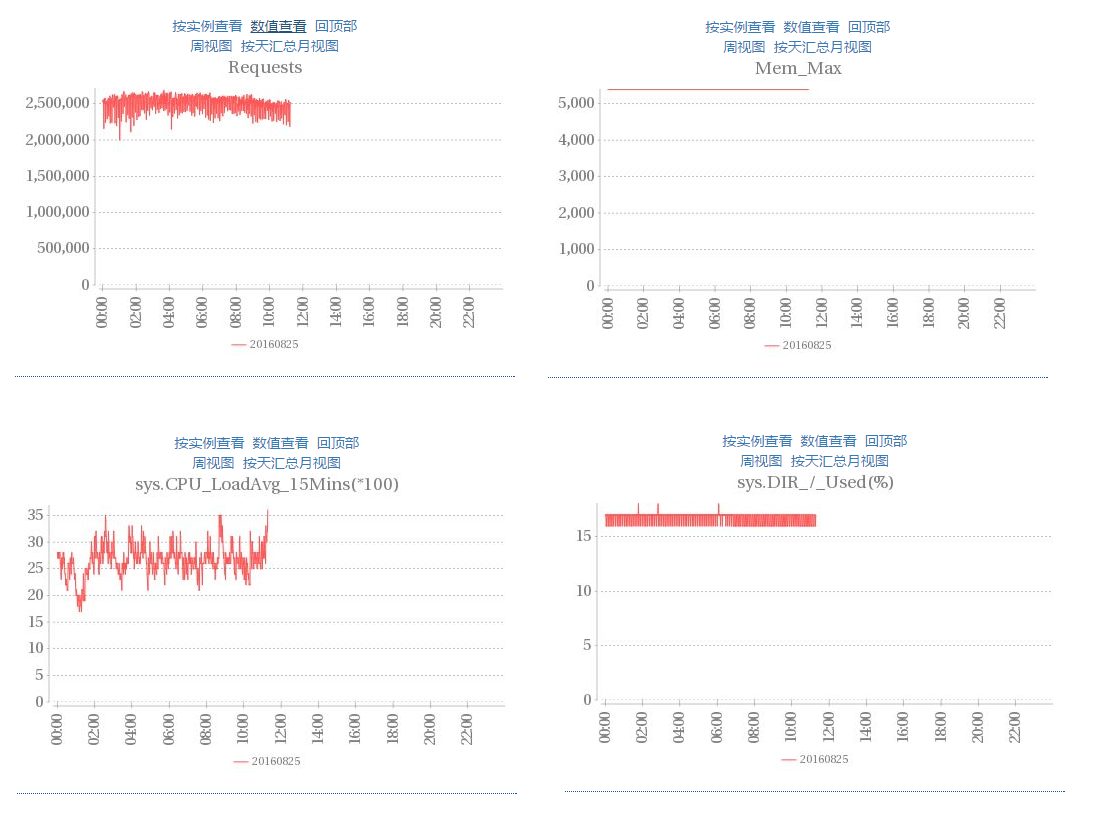
请求量、内存使用、cpu等各种状态信息可直观监控,也可以按IP粒度查看
![]()

限于篇幅和时间限制,详细的可见腾讯云服务市场、毫秒服务引擎官网,或者微信公众号:msec-engine

 浙公网安备 33010602011771号
浙公网安备 33010602011771号