
Spark2.3.1中用各种模式来跑官方Demo
1 使用单机local模式提交任务
local模式也就是本地模式,也就是在本地机器上单机执行程序。使用这个模式的话,并不需要启动Hadoop集群,也不需要启动Spark集群,只要有一台机器上安装了JDK、Scala、Spark即可运行。
进入到Spark2.1.1的安装目录,命令是:
cd /opt/spark/spark-2.1.1-bin-hadoop2.7
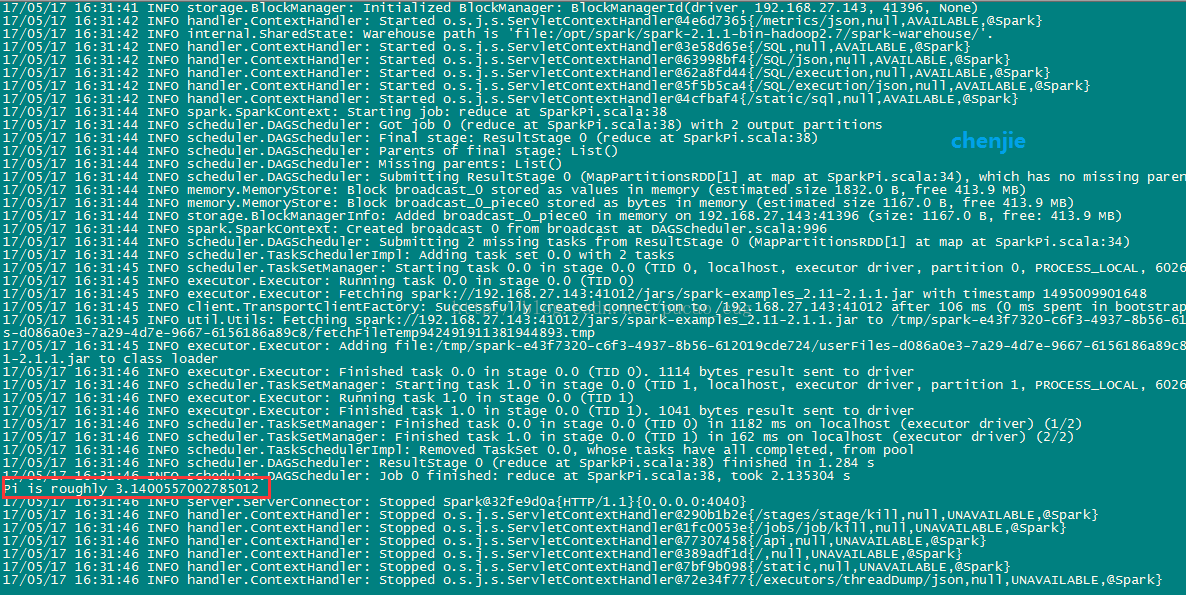
执行命令,用单机模式运行计算圆周率的Demo:
./bin/spark-submit --class org.apache.spark.examples.SparkPi --master local examples/jars/spark-examples_2.11-2.1.1.jar
如图:
2 使用独立的Spark集群模式提交任务
这种模式也就是Standalone模式,使用独立的Spark集群模式提交任务,需要先启动Spark集群,但是不需要启动Hadoop集群。启动Spark集群的方法是进入$SPARK_HOME/sbin目录下,执行start-all.sh脚本,启动成功后,可以访问下面的地址看是否成功:
http://Spark的Marster机器的IP:8080/
如图:

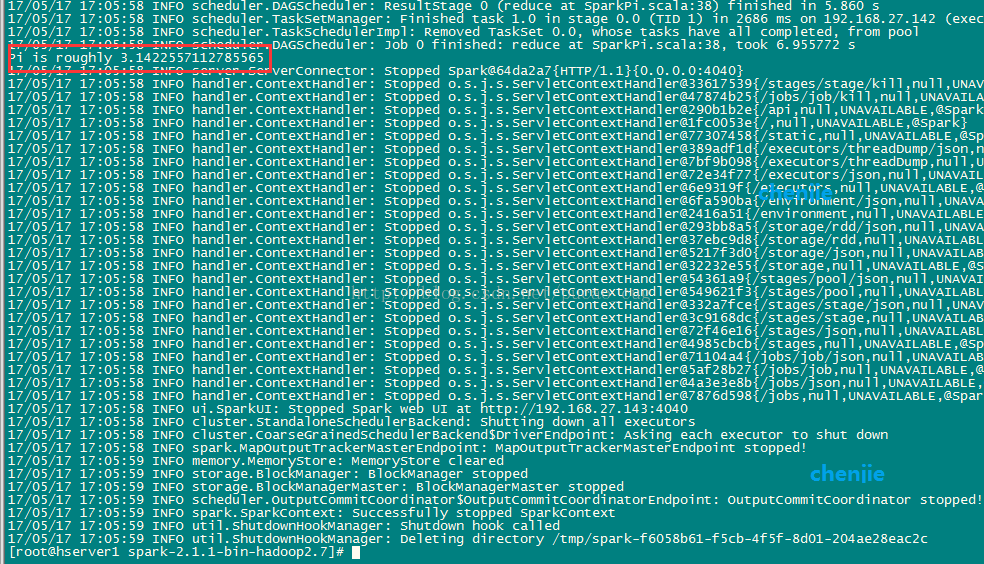
执行命令,用Standalone模式运行计算圆周率的Demo:
./bin/spark-submit --class org.apache.spark.examples.SparkPi --master spark://192.168.27.143:7077 examples/jars/spark-examples_2.11-2.1.1.jar
如图:
3 用yarn-client模式执行计算程序
cd /opt/spark/spark-2.1.1-bin-hadoop2.7
执行命令,用yarn-client模式运行计算圆周率的Demo:
./bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn-client examples/jars/spark-examples_2.11-2.1.1.jar
我这里出现了报错, 如图:
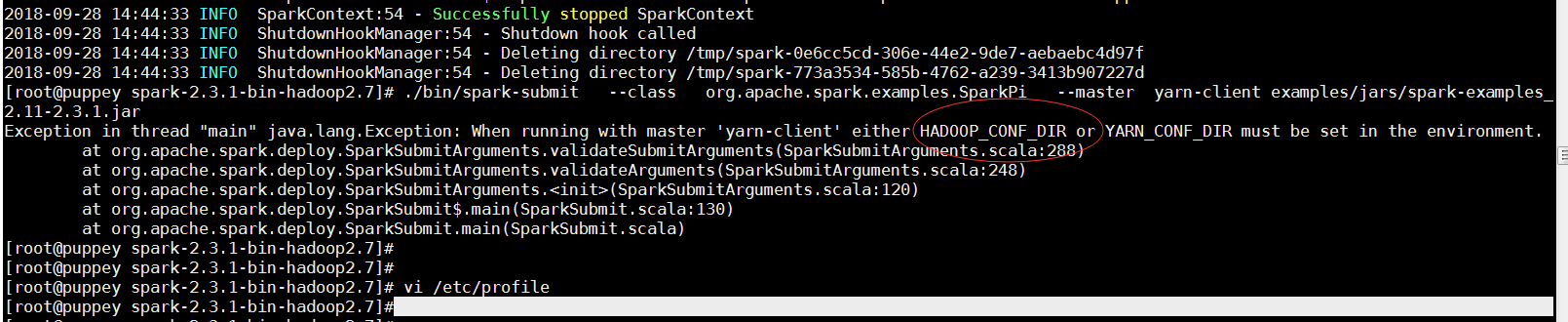
解决方法:
echo -e "export HADOOP_CONF_DIR=/usr/local/hadoop-2.7.3/etc/hadoop" >> /etc/profile source /etc/profile
接着运行...
又出现了如下报错....

经一番gooole, 由于VMware设置了4g内存,本地虚机启动了太多程序导致内存不够引起.
解决方案:
修改yarn-site.xml,添加下列property
<property> <name>yarn.nodemanager.pmem-check-enabled</name> <value>false</value> </property> <property> <name>yarn.nodemanager.vmem-check-enabled</name> <value>false</value> </property>

4 用yarn-cluster模式执行计算程序
cd /opt/spark/spark-2.1.1-bin-hadoop2.7
执行命令,用yarn-cluster模式运行计算圆周率的Demo:
./bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn-cluster examples/jars/spark-examples_2.11-2.1.1.jar
注意,使用yarn-cluster模式计算,结果没有输出在控制台,结果写在了Hadoop集群的日志中,如何查看计算结果?注意到刚才的输出中有地址:



 浙公网安备 33010602011771号
浙公网安备 33010602011771号