
WaveNet: 原始音频生成模型
官方博客 WaveNet: A Generative Model for Raw Audio
paper地址:paper
Abstract
WaveNet是probabilistic and autoregressive的生成,对每个预测的audio sample的分布都基于前面的前面的sample分布。在TTS的应用中,能达到state_of_art的效果,听觉感受上优于parametric and concatenative的系统。同时系统还可以生成音乐,作为discriminative model对phoneme做识别
Introduction
受neural autore-gressive generative models生成图像的启发[1][2]来生成wideband raw audio waveforms,主要挑战在于每秒采样率高达16,000 samples。
Contributions
1.We show that WaveNets can generate raw speech signals with subjective naturalness never before reported in the field of text-to-speech (TTS), as assessed by human raters。
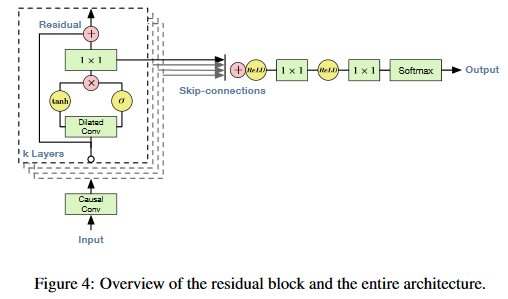
2. In order to deal with long-range temporal dependencies needed for raw audio generation,we develop new architectures based on dilated causal convolutions, which exhibit very large receptive fields.(超大感受野)
3.We show that when conditioned on a speaker identity, a single model can be used to generate different voices
4.The same architecture shows strong results when tested on a small speech recognition dataset, and is promising when used to generate other audio modalities such as music
WaveNet
概率模型: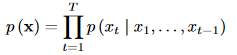 Each audio sample xt is therefore conditioned on the samples at all previous timesteps, the conditional probability distribution is modelled by a stack of convolutional layers.
Each audio sample xt is therefore conditioned on the samples at all previous timesteps, the conditional probability distribution is modelled by a stack of convolutional layers.
The model outputs a categorical distribution over the next value Xt with a softmax layer and it is optimized to maximize the log-likelihood of the data w.r.t. the parameters. Because log-likelihoods are tractable, we tune hyper-
parameters on a validation set and can easily measure if the model is overfitting or underfitting
- DILATED CAUSAL CONVOLUTIONS:
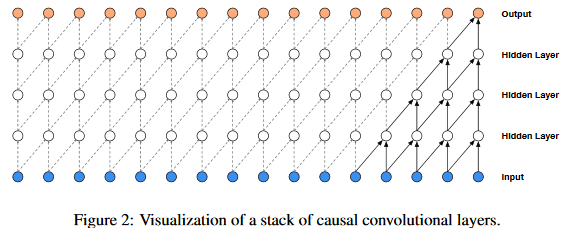
The main ingredient of WaveNet are causal convolution。Because models with causal convolutions do not have recurrent connections, they are typically faster to train than RNNs, especially when applied to very long sequences(只有因果卷积,而没有递归连接)。One of the problems of causal convolutions is that they require many layers, or large filters to increase the receptive field. For example, in Fig. 2 the receptive field is only 5 (= #layers + filter length - 1)
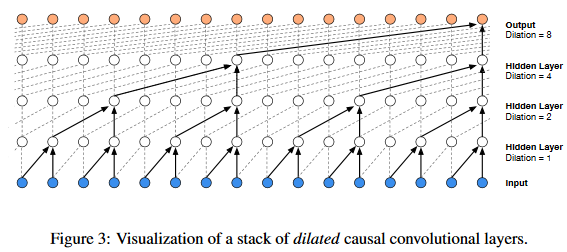
A dilated convolution (also called a trous, or convolution with holes) is a convolution where the filter is applied over an area larger than its length by skipping input values with a certain step。Stacked dilated convolutions enable networks to have very large receptive fields with just a few layers, while preserving the input resolution throughout the network as well as computational efficiency
- SOFTMAX DISTRIBUTIONS
Softmax distribution tends to work better to modeling the conditional distributions over the individual audio samples。Because raw audio is typically stored as a sequence of 16-bit integer values (one per timestep), a
softmax layer would need to output 65,536 probabilities per timestep to model all possible value.这里用[3]提出的$\{mu}-law$方法做了一个量化压缩,将输出概率数目压缩到了256个可能的值
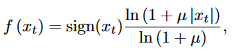
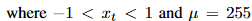 这个非线性压缩变换后的声音效果和原声音相差不大
这个非线性压缩变换后的声音效果和原声音相差不大
- GATED ACTIVATION UNITS
使用了和[1]相同的gated激活单元:

- RESIDUAL AND SKIP CONNECTIONS
Both resudula and skip method are used to speed up convergence and enable training of much deeper model
- CONDITIONAL WAVE NET
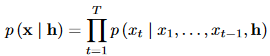
For example, in a multi-speaker setting we can choose the speaker by feeding the speaker identity to the model as an extra input. Similarly, for TTS we need to feed information about the text as an extra input.
Global conditioning is characterised by a single latent representation h that influences the output distribution across all timestep:
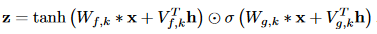
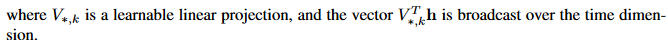

模型中采用的扩大卷积的方法来极大的增加感受野,对序列数据建模很有用
[1]van den Oord, A ̈ aron, Kalchbrenner, Nal, and Kavukcuoglu, Koray. Pixel recurrent neural networks.
[2]J ́ ozefowicz, Rafal, Vinyals, Oriol, Schuster, Mike, Shazeer, Noam, and Wu, Yonghui. Exploring the
[3] ITU-T. Recommendation G. 711. Pulse Code Modulation (PCM) of voice frequencies, 1988

 浙公网安备 33010602011771号
浙公网安备 33010602011771号