
炼丹的不二法门
1.数据增广
简单,行之有效地增加训练数据量,提高模型的泛化能力。
- 水平翻转(horizontally flipping)
- 位移 裁剪 颜色抖动(color jittering)
- 组合操作
例如同时做旋转和随机尺度变换,此外还可以把每个patch中所有像素在HSV颜色空间中的饱和度和明度提升0.25-4次幂方,乘以0.7-1.4之间的一个因子,再加一个-0.1-0.1之间的值。同样你可以在色调通道(H)对每张图片或patch 的所有像素增加一个-0.1~0.1之间的值。
2.预处理
- 零均值化和标准化
零均值化:X -= numpy.mean(X, axis=0)
数据有过大的均值可能导致参数的梯度过大,如果有后续的处理,可能要求数据零均值,比如主成分分析 PCA。零均值化并没有消除像素之间的相对差异,人们对图像信息的摄取通常来自于像素之间的相对色差,而不是像素值的高 低。归一化是为了让不同维度的数据具有相同的分布。假如二维数据(X1,X2)两个维度都服从均值为零的正态分布,但是X1方差为100,X2方差为1。那么对(X1,X2)进行随机采样在二维坐标系中绘制的图像,应该是狭长的椭圆 形。 归一化后加快了梯度下降求最优解的速度并有可能提高精度。考虑数据特征提取的表达式:
S = w1*x1 + w2*x2 + b
梯度计算:
dS / dw1 = x1 ; dS / dw2 = x2
由于学习率全局统一,所以两者沿梯度步进的速率相等,但由于二者分布不一致,X1沿梯度下降非常陡峭,X2较为平缓,梯度差异太大导致优化困难(下图左),此时优化的步骤容易走之字路线,右图对两个原始特征进行了归一 化,其对应的等高线显得很圆,在梯度下降进行求解时能较快的收敛。
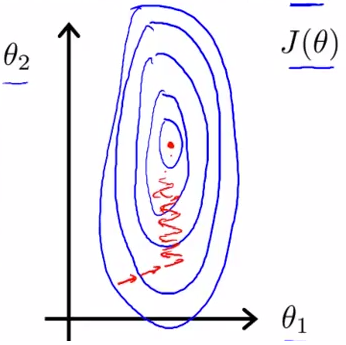
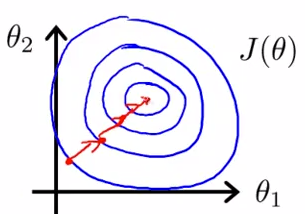
min_max标准化:x = (x - min)/(max - min) ,如在处理自然图像时,我们获得的像素值在 [0,255] 区间中,常用的处理是将这些像素值除以 255,使它们缩放到 [0,1] 中.
z-score 0均值标准化:x = (x - u)/σ uσ
- 白化
白化相当于在零均值化和归一化操作之间插入一个旋转操作,将数据投影到主轴上。一张图片经过白化后,可以认为每个像素之间是统计独立的。然而白化很少在卷积神经网络中使用,可能原因是图像信息本来就是依靠像素之间的 相对差异来体现的,白化让像素间去相关,让这种差异变得不确定,损失了信息。
3.初始化
- 不要将参数全部初始化为零
参数零初始化时,无论输入是什么,中间神经元的激活值都是相同的(任意一个神经元的激活值,当权重W是零向量时,W*X也是零向量,因此经过激活函数后激活值都相同),反向传播过程中计算的梯度也是相同,每个权重参数 的更新因此也是相同的,网络因此失去了不对称性。解决方法是使用近零的小值来进行初始化,打破网络对称性。
4.训练过程
- 卷积层和池化层
输入数据最好是2的整数幂次方,比如32(CIFAR-10中图片尺寸),64,224(ImageNet中常见的尺寸)。此外采用较小尺寸的滤波器(例3x3),小的步长(例1)和0值填充,不仅会减少参数数量,还会提升整个网络的准确率。 当用3x3的滤波器,步长为1,填充(pad)为1时,会保持图片或特征图的空间尺寸不变。池化层经常用的池化大小是2x2。
- 学习率
使用验证集是获得合适LR(Learning Rate)的有效手段。开始训练时,LR通常设为0.1。在实践中,******当你观察到在验证集上的loss或者准确率不再变化时********,将LR除以2或5后继续跑。
-
在预训练的模型上微调
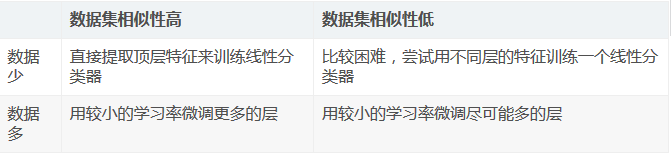
很多state-of-the-arts deep networks的模型被开源出来,这些预训练的模型泛化能力(generalization abilities)很强,因此可以在这些模型的基础上根据自己的任务微调。微调涉及两个重要的因素:新数据集的大小和两个数据集 的相似度
- 激活函数
sigmoid 与 tanh 曾经很流行,但现在很少用于视觉模型了,主要原因在于当输入的绝对值较大时,其梯度(导数)接近于零,这时参数几乎不再更新,梯度的反向传播过程将被中断,出现梯度消散的现象。
ReLU 优点:
-
实现起来非常简单,加速了计算过程。
-
加速收敛,没有饱和问题,大大缓解了梯度消散的现象。
ReLU 缺点:
就是它可能会永远“死”掉,假如有一组二维数据 X(x1, x2)分布在 x1:[0,1], x2:[0,1] 的区域内,有一组参数 W(w1, w2)对 X 做线性变换,并将结果输入到ReLU。
F = w1*x1 + w2*x
如果 w1 = w2 = -1,那么无论 X 如何取值,F 必然小于等于零。那么 ReLU 函数对 F 的导数将永远为零。这个 ReLU 节点将永远不参与整个模型的学习过程。
为了解决ReLU 在负区间的导数为零的问题,人们发明了 Leaky ReLU, Parametric ReLU, Randomized ReLU 等变体,他们的中心思想都是为ReLU 函数在负区间赋予一定的斜率,从而让其导数不为零(这里设斜率为 alpha)。
Leaky ReLU 就是直接给 alpha 指定一个固定的值,整个模型都用这个斜率
Parametric ReLU 将 alpha 作为一个参数,通过从数据中学习获取它的最优值。
Randomized ReLU 的alpha 是在规定的区间内随机选取的,在测试阶段是定值。
有学者将当前最优的两类CNN网络结合不同的激活函数在CIFAR-10,CIFAR-100和NDSB数据集上做实验,评价四种激活函数的优劣。
实验结果表明Leaky ReLU取较大的alpha准确率更好。Parametric
ReLU很容易在小数据集上过 拟合(训练集上错误率最低,测试集上不理想),但依然比ReLU好。RReLU效果较好,实验表明它可以克服模型过拟合,这可能由于alpha选择的随机性。在实践中,
Parametric ReLU 和 Randomized ReLU 都是可取的。
- 正则化Regularityzation
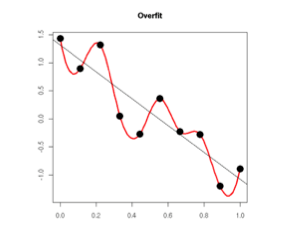
L2正则化:将模型中所有的参数的平方级作为惩罚项加入到目标函数(objective)中来实现。也就是说,对网络中的每一个权重w ,我们将其项 $L_2{\lambda}W_2$加入到目标函数中,其中λ是正则化的强度参数。在惩罚项公式 的前面加上12是很常见的,这样做的原因是因为优化函数12λw2 求导的时候不至于前面产生一个常数项因子2,而只是λw 这样简单的形式。对L2正则化的直观的解释是,L2正则化对尖峰向量的惩罚很强,并且倾向于分散权重的向 量。关于L2解决过拟合,比较流行的说法是:模型过于复杂是因为模型尝试去兼顾各个测试数据点, 导致模型函数如下图,处于一种动荡的状态, 在某些很小的区间里,函数值的变化很剧烈。这就意味着函数在某些小区间里的导 数值(绝对值)非常大,由于自变量值可大可小,所以只有系数足够大,才能保证导数值很大。
而加入正则能抑制系数过大的问题: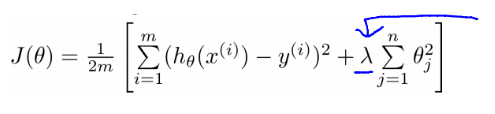 如果发生过拟合, 参数θ一般是比较大的值, 加入惩罚项后, 只要控制λ的大小,当λ很大时,θ1到θn就会很小,即达到了约束数量庞大的特征的目的
如果发生过拟合, 参数θ一般是比较大的值, 加入惩罚项后, 只要控制λ的大小,当λ很大时,θ1到θn就会很小,即达到了约束数量庞大的特征的目的
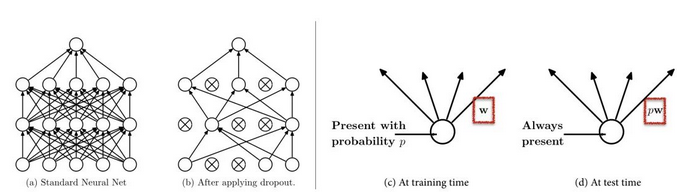
- DropOut
- 学习率
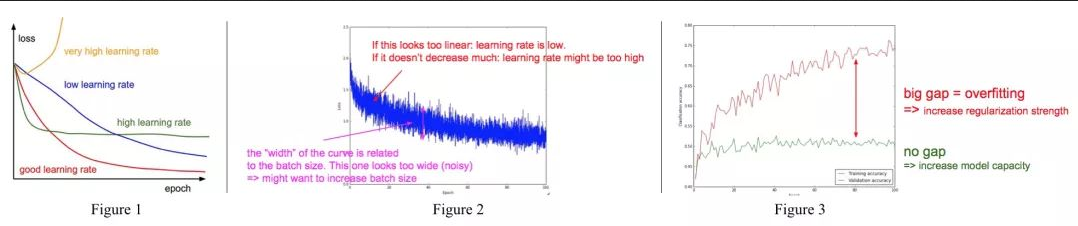
图2中横坐标是epoch(网络在整个训练集上完整的跑一遍的时间,所以每个epoch中会有多个mini batches),纵坐标是每个训练batch的分类loss。如果loss曲线表现出线性(下降缓慢)表明学习率太低;如果loss不再下降,表明学习率太高陷入局部最小值;曲线的宽度和batch size有关,如果宽度太宽,说明相邻batch间的变化太大,应该减小batch size。
图3中红色线是训练集上的精确率,绿色验证集上的精确率。当验证集上精确度收敛时,红线和绿线间隔过大很明显训练集上出现了过拟合。当两线间隔很小且准确率都很低时,说明模型学习能力太低,需要增加模型的capacity。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号