
《MuseGAN: Multi-track Sequential Generative Adversarial Networks for Symbolic Music Generation and Accompaniment》论文阅读笔记
出处:2018 AAAI
SourceCode:https://github.com/salu133445/musegan
abstract:
(写得不错 值得借鉴)重点阐述了生成音乐和生成图片,视频及语音的不同。首先音乐是基于时间序列的;其次音符在和弦、琶音(arpeggios)、旋律、复音等规则的控制之下的;同时一首歌曲是多track的。总之不能简单堆叠音符。本文基于GAN提出了三种模型来生成音乐:jamming model, the composer model and the hybrid model。作者从摇滚音乐中挑选出了10万个bar来进行训练,生成5个轨道的piano-rolls:bass, drums, guitar, piano and strings。同时作者使用了一些intra-track and inter-track objective metrics来衡量生成的音乐质量(?)。
Introduction:
GAN在文字,图片,视频上取得了巨大的成就,音乐方面也有些进展,但问题在于:
(1)音乐有自己的基于时间的架构,如下图所示:
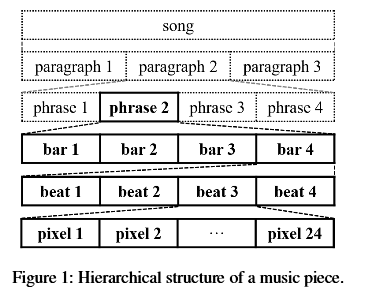
(2)音乐是多轨道/多乐器的
现代管弦乐(orchestra)常常有4个部分:brass, strings, woodwinds and percussion,摇滚乐队常用的是bass, a drum set, guitars and possibly a vocal,音乐理论要求这些元素按时间展开后harmony并且counterpoint.
(3)musical notes are often grouped into chords,arpeggios or melodies.所以,单音(monophonic)的音乐和NLP的生成都不能直接被引入来生成复调(polyphonic)的音乐。
由于上述三个问题,许多已有工作做了一些简化的处理方式,生成单轨单音音乐,introducing a chronological ordering of notes for polyphonic music,组合单音音乐变成复音音乐等。作者的目标是摒弃这些简化手法,1) harmonic and rhythmic structure, 2) multi-track interdependency, and 3) temporal structure。该模型能够产生音乐from scratch (i.e. without human inputs),也能follow the underlying temporal structure of a track given a priori by human.作者提出了三种方式来处理track之间的交互
(1)每个track独立生成 one generates tracks independently by their private generators (one for each)
(2)所有track由一个生成器生成 another generates all tracks jointly with only one generator
(3)在(1)的基础上,每个track生成时有额外的input信息,以保证harmonious and coordinated
为了突出group的性质,作者关注bars(这点参考了[1]),而不是notes,并使用CNN来提取隐藏特征。
除了刚才提到的测量标准,最后居然找了144个路人来对生成音乐进行评测。
contribution:

接下来介绍了GAN 和WGAN,WGAN-GP并最终选用WGAN-GP。
Proposed Model:
这里再次强调了关注的是Bar[1],并列举了一些理由。
- 数据表示
使用了multiple-track piano-roll representation表示方式,a piano-roll representation is a binary-valued, scoresheet-like matrix representing the presence of notes over different time steps, and a multiple-track piano-roll is defined as a set of piano-rolls of different tracks。一个有M个track,每个trank有R个time_step,候选bar数量为S的bar记录为X,其数据形式为$X^{RxSxM}$,T个bar则被表示为 $\{X^{t}\}_{t=1}^{T}$。因此每个X的矩阵大小是固定的,有利于CNN训练特征。
- 构建Tranck间的相关性(Interdependency)
提出了三种谱曲方式
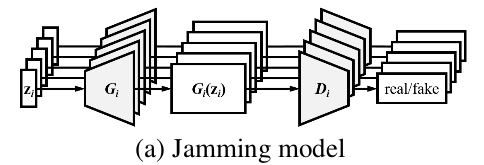
Jamming Model--每一个Track拥有自己的一组G和D,及独立的隐空间变量Zi。
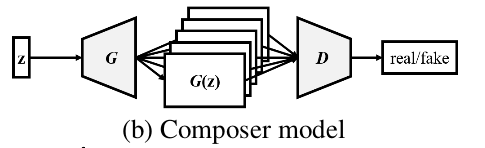
Composer Model -- 全局一组G和D,公用Z来生成所有的Track

Hybrid Model -- 混合上面两种模式,每个track一个Gi接受独立的Zi(intra-track random vector)及全局的Z(inter-track random vector)共同组合成的输入向量,同时公用一个D来生成track。与Composer Model相比,混合模式更加灵活,可以在G模型中使用不同的参数(如层数,卷积核大小等),将音轨的独立生成和全局和谐结合起来。
- 构建时序相关性(Temporal Structure)
上面提到的结构目的在于怎样在不同音轨中生成单个的bar,bar与bar之间的时序关联需要其他的结构来补充生成。作者采用了两种方式:


Generation from Scratch -- 将G分为两个sub network:$G_{temp}$和$G_{bar}$,$G_{temp}$将z映射成一个隐空间向量的序列![]() ,作者希望它能承载一些时序信息,随后
,作者希望它能承载一些时序信息,随后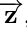 被送入$G_{bar}$,序列化地生成piano-rolls。
被送入$G_{bar}$,序列化地生成piano-rolls。
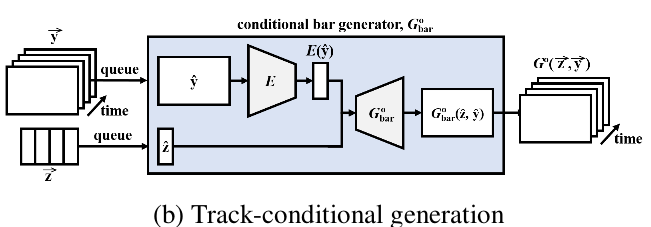
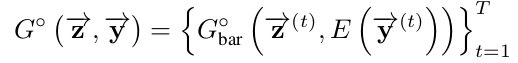
Track-conditional Generation--这种方式假定了各个track的n个bar已经被给定了,即为 ,这里添加了一个编码器E,负责将映射为
,这里添加了一个编码器E,负责将映射为 (这个也是从[1]里参考得来的)
(这个也是从[1]里参考得来的)
- MuseGAN
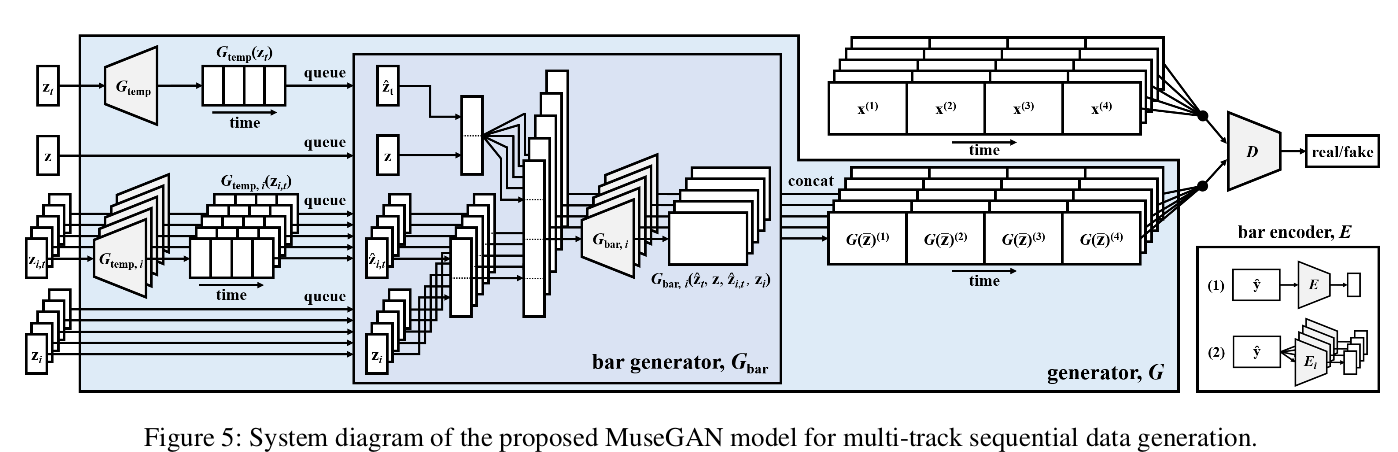
模型的输入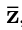 由4部分构成:
由4部分构成:
an inter-track time-dependent random vectors $z_t$ 轨道间全局 时间相关 向量
an inter-track time-independent random vectors z 轨道间全局 时间无关 向量
an intra-track time-independent random vectors $z_i$ 轨道内单独 时间无关 向量
an intra-track time-dependent random vectors $z_{i,t}$ 轨道内单独 时间相关 向量
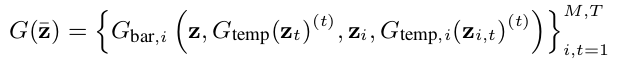
从该生成公式上可以清楚地看出,各轨道间的输入变量(分为时间相关和无关)和全局输入变量(分为时间相关和无关)如何结合起来,形成MuseGan生成系统
Dataset
MuseGAN的piano-roll训练数据是基于Lakh MIDI dataset (LMD)[3],原数据集噪声很大,使用了三步来做清理(如下图),midi解析使用了pretty midi[2]
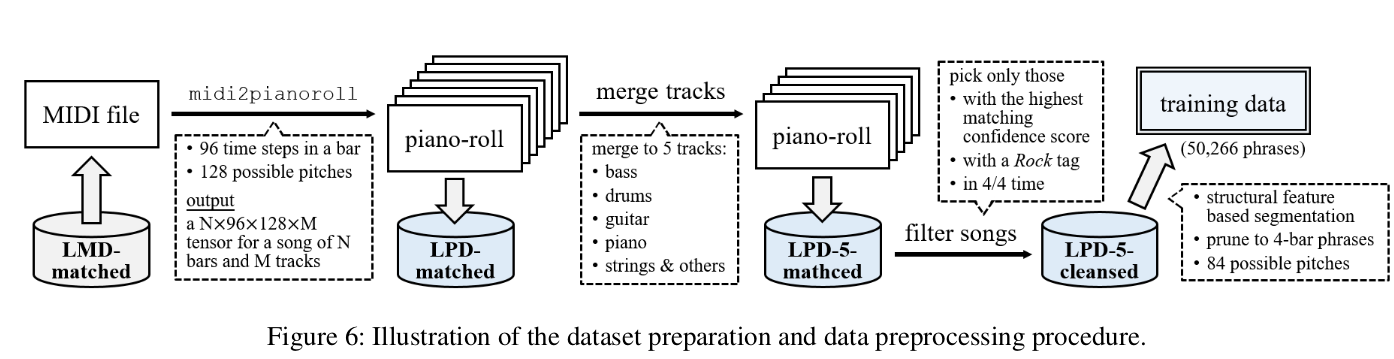
要注意的是,(1)一些track上的note非常稀疏,这里作者对这种不平衡数据做了merge操作(merging tracks of similar instruments by summing their piano-rolls,具体可能需要看代码),对于非bass, drums, guitar, piano and strings 这5类的track统一归纳到string上去.[5,6]中对track类型进行了较好的数据预归类;(2)选取piano-roll时选取higher confidence score in matching的,rock标签,4/4拍;(3)piano-roll的segment采用了state_of_art的方式structural features[7],每4个小节为一个phrase。Notably, although we use our models to generate fixed-length segments only, the track-conditional model is able to generate music of any length according to the input.(4)音域使用C1到C8(钢琴最右键)。
最终输出一首歌的tensor为:4 (bar) × 96 (time step) × 84 (note) × 5 (track)
模型设置:
根据WGAN的理论,update G once every five updates of D and apply batch normalization only to G。其余略。
Objective Metrics for Evaluation:
使用了4个intra-track和1个inter-track(最后一个)度量标准
- EB: ratio of empty bars (in %)
- UPC: number of used pitch classes per bar (from 0 to 12)
- QN: ratio of “qualified” notes (in %) 一个长度不少于3个time_step的音符被认为是qualified的。这个指标可以衡量是否生成的音乐是否过于碎片化。
- DP, or drum pattern: ratio of notes in 8- or 16-beat patterns, common ones for Rock songs in 4/4 time (in %).
- TD: or tonal distance [8]. It measures the hamornicity between a pair of tracks. Larger TD implies weaker inter-track harmonic relations.调式距离?
[9]:综述 [10]RNN生成music [11]生成chorales [12]:Song from PI [13]:C-RNN-GAN [14]:seqGAN(combined GANs and reinforcement learning to gen sequences of discrete tokens. It has been applied to generate monophonic music, using the note event representation) [15]:midi_net(convolutional GANs to generate melodies that follows a chord sequence given a priori, either from scratch or conditioned on the melody of previous bars)
[1]Yang, L.-C.; Chou, S.-Y.; and Yang, Y.-H. 2017. MidiNet: A convolutional generative adversarial network for symbolicdomain music generation. In ISMIR.
[2]Raffel, C., and Ellis, D. P. W. 2014. Intuitive analysis, creation and manipulation of MIDI data with pretty midi. In ISMIR Late Breaking and Demo Papers.
[3]Raffel, C., and Ellis, D. P. W. 2016. Extracting ground truth information from MIDI files: A MIDIfesto. In ISMIR.
[4]Raffel, C. 2016. Learning-Based Methods for Comparing Sequences, with Applications to Audio-to-MIDI Alignment and Matching. Ph.D. Dissertation, Columbia University.
[5]Chu, H.; Urtasun, R.; and Fidler, S. 2017. Song from PI: A musically plausible network for pop music generation. In ICLR Workshop.
[6]Yang, L.-C.; Chou, S.-Y.; and Yang, Y.-H. 2017. MidiNet: A convolutional generative adversarial network for symbolic-domain music generation. In ISMIR.
[7]Serrà, J.; Mller, M.; Grosche, P.; and Arcos, J. L. 2012. Unsupervised detection of music boundaries by time series structure features. In AAAI.
[8]Harte, C.; Sandler, M.; and Gasser, M. 2006. Detecting harmonic change in musical audio. In ACM MM workshop on Audio and music computing multimedia.
[9]Briot, J.-P.; Hadjeres, G.; and Pachet, F. 2017. Deep learning techniques for music generation: A survey. arXiv preprint arXiv:1709.01620.
[10] Sturm, B. L.; Santos, J. F.; Ben-Tal, O.; and Korshunova, I. 2016. Music transcription modelling and composition using deep learning. In Conference on Computer Simulation of Musical Creativity.
[11]Hadjeres, G.; Pachet, F.; and Nielsen, F. 2017. DeepBach:A steerable model for Bach chorales generation. In ICML.
[12]Chu, H.; Urtasun, R.; and Fidler, S. 2017. Song from PI: A musically plausible network for pop music generation. In ICLR Workshop.
[13]Mogren, O. 2016. C-RNN-GAN: Continuous recurrent neural networks with adversarial training. In NIPS Worshop on Constructive Machine Learning Workshop.
[14]Yu, L.; Zhang, W.; Wang, J.; and Yu, Y. 2017. SeqGAN: Sequence generative adversarial nets with policy gradient. In AAAI.
[15]Yang, L.-C.; Chou, S.-Y.; and Yang, Y.-H. 2017. MidiNet: A convolutional generative adversarial network for symbolic-domain music generation. In ISMIR.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号