
《The Unreasonable Effectiveness of Recurrent Neural Networks》阅读笔记
李飞飞徒弟Karpathy的著名博文The Unreasonable Effectiveness of Recurrent Neural Networks阐述了RNN(LSTM)的各种magic之处,并提供code实现简单的词生成。
原文地址;http://karpathy.github.io/2015/05/21/rnn-effectiveness/
Recurrent Neural Networks
- sequence
Vanilla Neural Networks (and also Convolutional Networks)经常受限于使用fixed-size的输入和输出,同时由于layer的数量固定,所以也必然是fixed-sized computational steps。RNN令人振奋的核心之处就在于提供了over sequences of vectors的操作,无论是input output还是最常见的both of them。
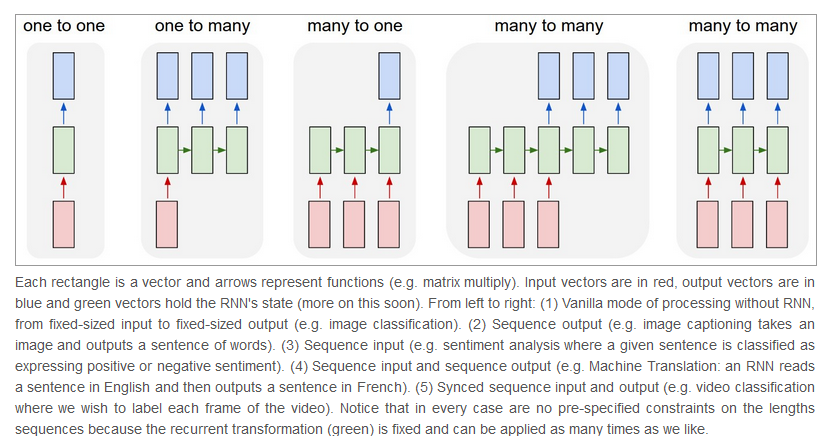
RNNs combine the input vector with their state vector with a fixed (but learned) function to produce a new state vector. This can in programming terms be interpreted as running a fixed program with certain inputs and some internal variables.(大师的归纳能力就是强悍)。对于非序列化的数据(如图片)也可以使用RNN控制状态来进行训练。For instance, the figure below shows results from two very nice papers from DeepMind. On the left, an algorithm learns a recurrent network policy that steers its attention around an image; In particular, it learns to read out house numbers from left to right (Ba et al.). On the right, a recurrent network generates images of digits by learning to sequentially add color to a canvas (Gregor et al.)。
- Computation
相对来说,RNN的API非常简单

output vector’s contents are influenced not only by the input you just fed in, but also on the entire history of inputs you’ve fed in in the past.
对于一个简单的RNN class来说,其实现如下:
 h是仅有的hidden vector(初始化为0),待学习参数W_hh, W_xh,W_hy
h是仅有的hidden vector(初始化为0),待学习参数W_hh, W_xh,W_hy
- Going Deep
RNN也可以像寻常神经网络一样进行层的堆叠

In other words we have two separate RNNs: One RNN is receiving the input vectors and the second RNN is receiving the output of the first RNN as its input. Except neither of these RNNs know or care - it’s all just vectors coming in and going out, and some gradients flowing through each module during backpropagation.
- Getting fancy
对于改进版的LSTM,作者不过多的做解释说明,差别就在计算self.h时,采用了更多的门控制来进行更新操作,后续的网络默认都使用LSTM。
Character-Level Language Models
了解了 how RNN work后,这章我们训练一个RNN character-level language models。一个例程,假定我们有了字母表“helo”包含四个字母,training sequence是单词“hello”,则可以划分出4个训练用例:1. The probability of “e” should be likely given the context of “h”, 2. “l” should be likely in the context of “he”, 3. “l” should also be likely given the context of “hel”, and finally 4. “o” should be likely given the context of “hell”.每个字母被编码成one-hot形式被送入RNN网络(每个字母调用一次step),每次输出一个代表概率的4维向量
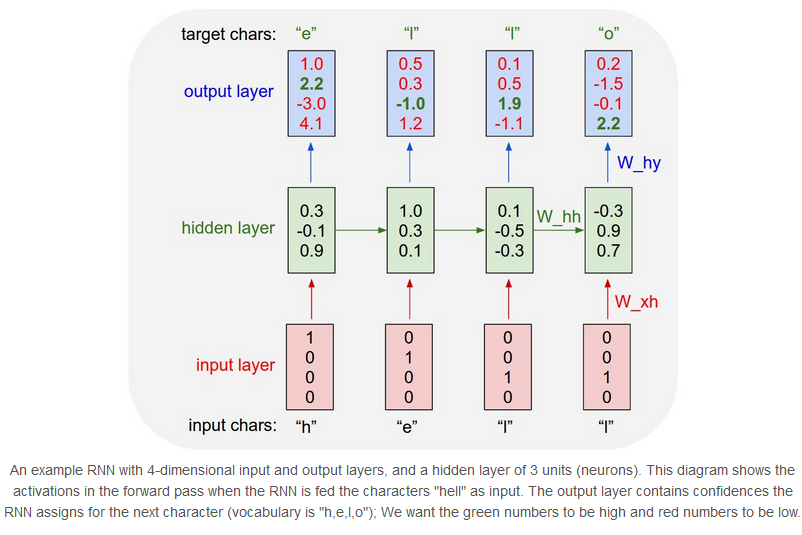
对于输出的四维向量来说,我们的目标是将其中正确表达的字母所在维度的值(图中绿色的值)通过BP调整3个参数来提高,并且降低其他维度的值。
Fun with RNNs
接下来是代码秀时间,作者秀了一下用简单的RNN/LSTM生成的Paul Graham ,莎士比亚,维基百科(html),latex,Linux source code等等产物。
由于Ka大神没有对LSTM做过多的阐述,以下LSTM相关的笔记来自简书《理解 LSTM 网络》
地址:https://www.jianshu.com/p/9dc9f41f0b29
将RNN展开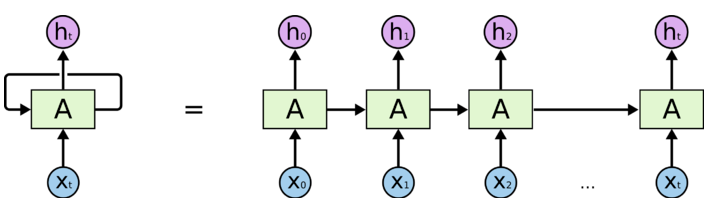
这个图其实不太好,不太直观的地方在于没有清晰地展示出循环传递的到底是什么数据(水平箭头方向),实则就是$h_t$
RNN尝试解决每一步的输出和之前输入信息(隐含以前每一步的输出信息)的依赖关系,但是当时间轴被拉得很长时,问题就出来了,网络会逐渐丧失长期记忆的依赖关系(梯度消失 无法更新)。Long Short Term正是RNN的改良品种。

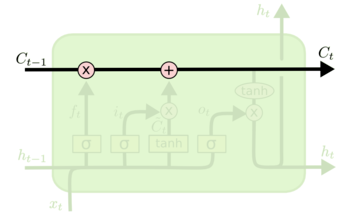 LSTM中细胞状态$C_t$的传递与更新,经过了下面的3个门单元(每个门单元包含一个 sigmoid 神经网络层和一个 pointwise 乘法)运算,更新到下一步
LSTM中细胞状态$C_t$的传递与更新,经过了下面的3个门单元(每个门单元包含一个 sigmoid 神经网络层和一个 pointwise 乘法)运算,更新到下一步
- 忘记门
输入:&h_{t-1}& 、$x_t$
输出:一个0到1的数值,表示记忆$c_{t-1}$保留的程度
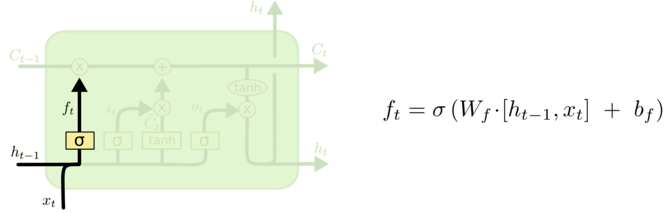
- 输入层门
决定哪些新信息需要被存放在cell中
输入:&h_{t-1}& 、$x_t$
输出:$i_t$(决定我们需要更新什么值)
同时输出一个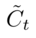 (加入到状态中)
(加入到状态中)
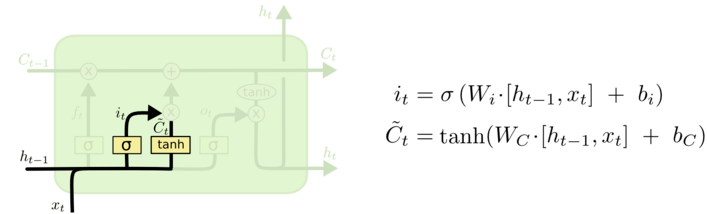
- 细胞更新
将$c_{t-1}$更新为$c_t$ 前面遗忘门和输入门准备好的数据,派上用场了
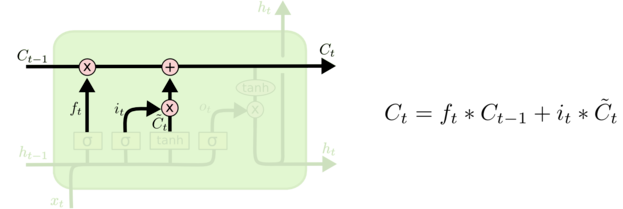
- 输出
最终输出的结果$h_t$依赖于前面计算好的$C_t$

各种变种LTSM:
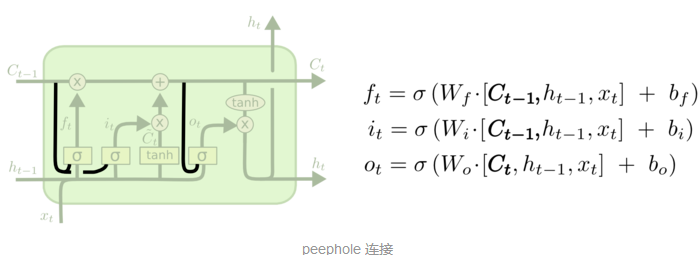
让各个门层也接受细胞状态输入的peephole connection:
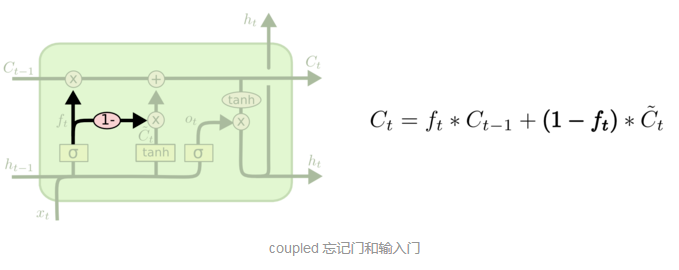
coupled 忘记和输入门:
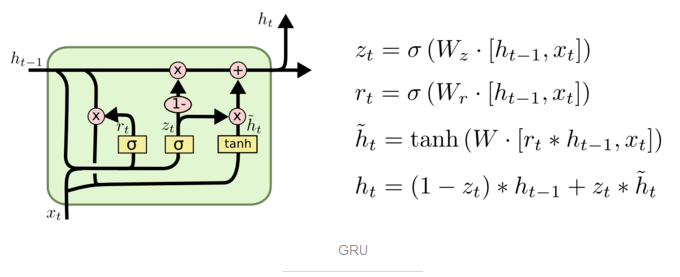
Gated Recurrent Unit (GRU):
将忘记门和输入门合成了一个单一的 更新门。同样还混合了细胞状态和隐藏状态,和其他一些改动。最终的模型比标准的 LSTM 模型要简单,也是非常流行的变体。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号