
Image2Caption
定义
图像标注或语言生成图像问题把计算机视觉与自然语言处理联系在了一起,是广义的人工智能领域的一大难题.通常涉及到特征提取(用cnn提取出图像内部不为人类感知的向量特征)和语言模型建立。为图像提取文字信息可以节省大量的图像资料的人工标注成本,转为语音后可以方便视觉障碍者理解图片内容。从文字生成图像也有艺术创作和罪犯画像等实用领域。任务扩展为视频后,应用将更为广泛。
codaLab基于MScoco数据集举行的相关竞赛排行榜,鹅厂方案暂时领先
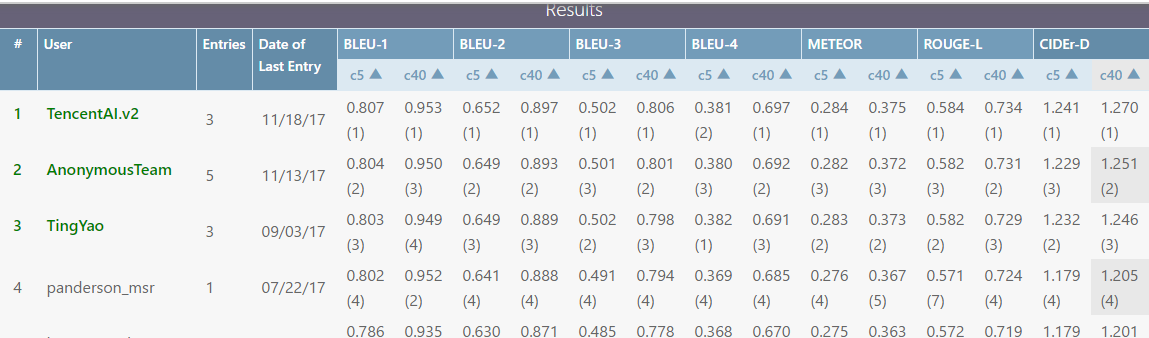
相关数据集信息

任务描述
统一两个子任务图片特征提取和描述图片的自然语言生成,对于训练集图片$I$,想到得到的描述句序列可以表示为$S = {S\_0,S\_0,S\_0.....S\_n}$,$S\_i$为组成句子的词,则模型概率可以表示为
$P(S|I;\theta)=\prod_{t=0}^NP(S_t|S_0,S_1,...,S_{t-1},I;\theta)$每个输出词都和所有前期输入词上下文相关,所以RNN,LSTM等网络成为首选训练网络,取对数似然函数
$\log P(S|I;\theta)=\sum_{t=0}^N\log P(S_t|S_0,S_1,...,S_{t-1},I;\theta)$
则目标函数为最大化所有训练样本的对数似然之和
$ \theta^*=\arg\max_{\theta}\sum_{(I,S)}\log P(S|I;\theta)$ (I,S为配对训练样本)
生成过程则满足
$\arg\max_{S}P(S|I;\theta^*)$
由于组成句子的词语序列数量庞大,计算全部序列来挑选概率不现实,故而引入beam search来缩小搜索空间
特征提取
用作特征提取子模型的通常是深度卷积神经网络(CNN)。这种网络可以在图像描述数据集(MS-coco)中的图像上直接训练。或者可以使用预训练的模型(比如用于图像分类的当前最佳的模型,为 ILSVRC 挑战赛在 ImageNet 数据集上开发的表现最好的模型,如vgg,inception等),或者也可以使用混合方法,即使用预训练的模型并根据实际问题进行微调。
语言模型
一般来说,就是根据一个词序列来计算下一个词的出现概率,对于图像描述,语言模型这种神经网络可以基于网络提取出的特征预测描述中的词序列并根据已经生成的词构建描述。常用的方法是使用循环神经网络作为语言模型,比如长短期记忆网络(LSTM)。每个输出时间步骤都会在序列中生成一个新词,然后每个生成的词都会使用一个词嵌入(比如 word2vec)进行编码,该编码会作为输入被传递给解码器以生成后续的词。
编码器-解码器架构
构建子模型的一种常用方法是使用编码器-解码器架构,其中两个模型是联合训练的。

这种架构原本是为机器翻译开发的,其中输入的序列(比如法语)会被一个编码器网络编码成固定长度的向量。然后一个分立的解码器网络会读取这些编码并用另一种语言(比如英语)生成输出序列。





N-gram的基本原理
N-gram是计算机语言学和概率论范畴内的概念,是指给定的一段文本或语音中N个项目(item)的序列。项目(item)可以是音节、字母、单词或碱基对。通常N-grams取自文本或语料库。
N=1时称为unigram,N=2称为bigram,N=3称为trigram,以此类推。
举例来说:将“informationretrieval”视为一段文本,它的5-grams的items依次为:
infor,nform,forma,ormat,rmati,matio,ation,tion,ionr,onre,nret,retr,retri,etrie,triev,rieva,ieval
有时为了便于分析,还会在前面加空格,这就多出4个items:____i,___in,__inf,_info
举例中文:“你今天休假了吗”,它的bigram依次为:
你今,今天,天休,休假,假了,了吗
制造这种语言模型的原因是基于这么一种思想:在整个语言环境中,句子T的出现概率是由组成T的N个item的出现概率组成的,如下公式所示
P(T)=P(W1W2W3Wn)=P(W1)P(W2|W1)P(W3|W1W2)…P(Wn|W1W2…Wn-1)
以上公式难以实际应用。此时出现马尔科夫模型,该模型认为,一个词的出现仅仅依赖于它前面出现的几个词。这就大大简化了上述公式。
P(W1)P(W2|W1)P(W3|W1W2)…P(Wn|W1W2…Wn-1)≈P(W1)P(W2|W1)P(W3|W2)…P(Wn|Wn-1)
通常采用bigram和trigram进行计算。
论文
-
《Show and Tell:一种神经图像描述生成器(Show and Tell: A Neural Image Caption Generator)》,2015:https://arxiv.org/abs/1411.4555
引入了NIC(Natural Image Caption)模型的原始形态,再早期的原形是2015CVPR的paper《show and Tell》(2015年coco比赛第一名)。NIC模型的结构非常“简单”:就是利用encoder-decoder框架,首先利用CNN(这里是GoogLeNet)作为encoder,将 Softmax 之前的那一层固定维数的向量作为图像特征;再使用LSTM作为decoder,其中图像特征输入decoder(图像特征仅在开始时刻输入,后面就没用了)。模型的训练就是和任务描述那里介绍的一样,使用最大化对数似然来训练,然后在测试阶段采用beam search来减小搜索空间。NIC 模型仅在decoder的开始时刻输入了图像特征,而不是在每个解码时刻都输入了图像特征。作者给出的理由是,如果在每个时刻都输入图像特征,那么模型会把图像的噪声放大,并且容易过拟合。实际上,后面的一些文章在基于attention来做caption,那么就必然要每个时刻都输入。因此本文的模型是非常简单的。
encoder-decoder的优点:非常灵活,不限制输入和输出的模态,也不限制两个网络的类型;
encoder-decoder的缺点:当输入端是文本时,将变长序列表达为固定维数向量,存在信息损失,并且目前还不能处理太长的文本。
-
《Show, Attend and Tell:使用视觉注意的神经图像描述生成(Show, Attend and Tell: Neural Image Caption Generation with Visual Attention)》,2015:https://arxiv.org/abs/1502.03044
-
《用于视觉识别和描述的长期循环卷积网络(Long-term recurrent convolutional networks for visual recognition and description)》,2015:https://arxiv.org/abs/1411.4389
-
《用于生成图像描述的深度视觉-语义对齐(Deep Visual-Semantic Alignments for Generating Image Descriptions)》,2015:https://arxiv.org/abs/1412.2306
1. 训练细节
在训练过程中,固定学习率且不加动量(momentum);词条化后去掉了词频小于5的词;在ImageNet上预训练GoogLeNet,并且在训练caption模型时这部分的参数保持不变;在大型新闻语料上预训练词向量,但是效果并没有明显提升;使用dropout和模型ensemble,并权衡模型的容量:隐层单元个数与网络深度;512维词向量;使用困惑度(perplexity)来指导调参。
个人觉得,这种简单粗暴的模型结构,参数的设置真的太重要了。
2. 自动评价与人工评价
作者在论文中多次强调,需要更好的自动评价计算方式。因为以自动评价指标来评测的话,模型的评测结果在很多时候要比人写的caption的评测结果还要好,但人工评价的结果显示,实际上模型的caption相比于人写的caption还有很大差距。
3. 迁移学习与数据标注的质量
一个很容易想到的问题是,是否可以把在某个数据集下训练的模型迁移到另一数据集?高质量的标注数据和更多的数据可以补偿多少领域错配问题?
首先来看迁移学习的问题,作者首先指出,在Flickr8k和Flick30k这两个数据集上,如果用Flickr30k来训练,效果会提升4个BLEU,更大量的数据带来了更好的效果,凸显data-driven的价值。但是如果用COCO做训练,尽管数据量五倍于Flickr30k,但由于收集过程不统一,带来了词表的差别以及较大的领域错配,效果下降了10个BLEU。PASCAL数据集没有提供训练集,使用COCO训练的效果要比使用Flickr30k的效果要好。
然后再看标注质量的问题。此前已经提到过,SBU数据集的噪声较大,所以可以看作是“弱标注”的(weak labeling),但尽管如此,如果使用COCO来训练,效果依旧会下降。
4. 生成的caption是否具备多样性
作者探讨了模型生成的描述是否有新颖性,是否同时具备多样性和高质量。

首先来看多样性(diversity)。作者挑了测试集里的三个图片的caption,每张图片都有模型生成的3-best描述(加粗的是没在训练集中出现过的),可以看出这些描述可以展现图像的不同方面,因此作者认为该模型生成的caption具备多样性。
再来看质量。如果只考虑模型生成的最佳候选caption,那么它们中的80%在训练集中出现过;如果考虑top15,则有一半是完全新的描述,但仍然具备相似的BLEU分,因此作者认为该模型生成的caption兼具了多样性和高质量。
5. NIC模型的改进:NICv2
作者列举了使他们成为2015COCO比赛第一名的几点重要改进。
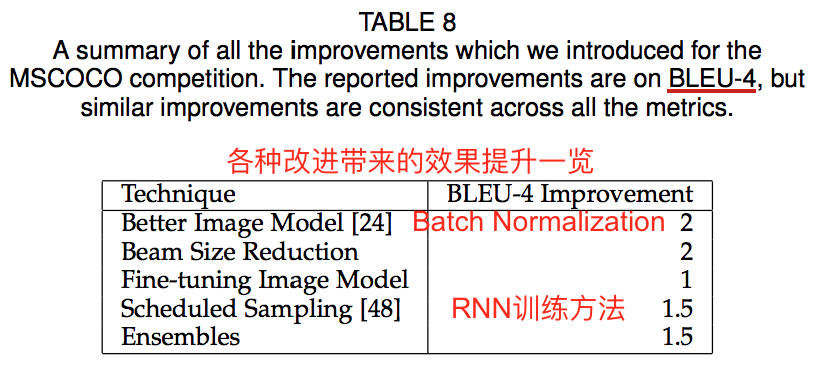
(1)Batch Normalization:在encoder的GoogLeNet中引入了Batch Normalization
(2)encoder端的fine-tuning
刚才提到,encoder端的CNN在预训练后,是不参与caption模型的训练的,其参数值是保持不变的。而这里他们进行了微调:首先固定encoder的参数,训练500k步decoder,以得到一个不错的LSTM;然后encoder和decoder联合训练100k步。作者特别强调,CNN不能陪着LSTM一起从头开始就联合训练,而必须在LSTM已经不错的情况下再进行联合训练,否则预训练的CNN也会被“带跑”。另外,作者说使用K20单机训练了超过三周,而并行训练时会使效果变差。
CNN的fine-tuning带来的效果是,一些例子可以正确描述颜色。作者认为,在ImageNet预训练的过程,使得“颜色”这样的和分类无关的特征被抛弃了。
(3)RNN的训练使用Scheduled Sampling:对应于2015NIPS的文章,RNN的训练trick
对于 Image Caption 和 Machine Translation 等一系列生成变长序列的任务,RNN的训练和测试过程其实存在不统一的地方:训练时,对于输入 I 和目标序列 S 构成的样本 (I, S) ,目标是最大化似然函数 P(S|I) ,进而 train 出来模型的参数。我们知道,似然函数是被拆解成条件概率的连乘形式,而每个词的条件概率求解过程中,RNN接受的输入信息包括上一时刻的隐状态、encoder的编码向量以及上一时刻的词。
问题就出在,“上一时刻的词”在训练过程中是被指定为目标序列 S 中的词的,也就是说它是“正确的”;而在测试时,“正确的”上一时刻目标词是不知道的,取而代之的是由模型生成的词(虽然仍然是Softmax计算出词表中概率最大的那个词,但是训练过程会使模型去弥合Softmax计算的词与正确的词之间的loss;而测试过程就真的只是生成一个词之后就不管了,因为没有监督信号),这就带来了训练和测试的不统一(discrepancy)。如果测试过程中的某个时刻生成了错误的词,那么这个错误会被快速放大,因为生成的这段序列很有可能没在训练过程中出现过。
在我看来,测试过程中使用softmax来取概率最大的词(并结合 beam search )已经是很“正确”的做法了。作者在RNN的训练过程中做一些变化:Scheduled Sampling就是指RNN在训练时会随机使用模型真实输出来作为下一个时刻的输入,而不像原先那样只会使用目标词来作为下一时刻的输入。作者认为,这种方式可以强迫模型在训练过程中“学会”如何处理错误。
我认为这和 negative sampling 策略(如 word2vec 等模型所采用的加速训练策略,NCE 的简化版本)正好相反,因为在负采样中,训练过程中构造的负样本的似然是要最小化的,而在这里却作为了强迫模型在训练过程中学习到新知识的一种方式,但是从“错误”的样本里能学出来什么呢?
关于各种改进的RNN训练方法的比较,可以参考https://arxiv.org/pdf/1511.05101.pdf
(4)模型ensemble:改变一些训练条件,训练出多个模型。作者训练了5个Scheduled Sampling模型和10个fine-tuning CNN模型。
(5)减小beam search的候选结果个数(k)
在NIC模型中,作者只取了1和20两个值。在改进过程中,发现k取3是最好的搜索规模。按道理说,k越大应该越好,但实际上是较小的k取得了最好的结果,说明目标函数与人工的标准不匹配,或者模型过拟合;作者同时发现,减少k可以提升新颖性(生成的caption出现在训练集的比例从80%降到了60%),所以认为模型是过拟合了。这样的话,减少k可以视作一种正则化。
6. 展望
作者提到,一个方向是希望模型能够给出有针对性的描述,例如根据用户提问来给出caption,这就成了一种VQA任务;另外一个就是需要更好的自动评价指标。

文章
-
维基百科:自动图像标注:https://en.wikipedia.org/wiki/Automatic_image_annotation
-
Show and Tell:在 TensorFlow 中开源的图像描述:https://research.googleblog.com/2016/09/show-and-tell-image-captioning-open.html
-
Andrej Karpathy 和李飞飞:使用卷积网络和循环网络的自动图像描述;视频:https://www.youtube.com/watch?v=xKt21ucdBY0 ;幻灯片:https://cs.stanford.edu/people/karpathy/sfmltalk.pdf
项目
-
用于生成图像描述的深度视觉-语义对齐,2015:http://cs.stanford.edu/people/karpathy/deepimagesent/
-
NeuralTalk2:运行在 GPU 上的有效图像描述 Torch 代码,来自 Andrej Karpathy:https://github.com/karpathy/neuraltalk2
- Google的im2txt开源项目********* http://www.jianshu.com/p/18ecbaf9322c?from=groupmessage
- http://blog.csdn.net/sparkexpert/article/details/70846094 代码:https://github.com/ndscigdata
- http://blog.csdn.net/gbbb1234/article/details/70543584 代码:github:https://github.com/tensorflow/models/tree/master/im2txt#generating-captions
https://www.cnblogs.com/Determined22/p/6910277.html
http://www.cnblogs.com/Determined22/p/6914926.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号