
MTCNN人脸检测识别笔记
论文:Joint Face Detection and Alignment using Multi-task Cascaded Convolutional Networks
论文链接:https://arxiv.org/abs/1604.02878
官方代码链接:https://github.com/kpzhang93/MTCNN_face_detection_alignment
其他代码实现(MXNet):https://github.com/pangyupo/mxnet_mtcnn_face_detection
一 模型及流程概览
使用mtcnn神经网络进行人脸检测是目前比较主流的方式,相较于传统的人脸检测方法,mtcnn更能够适用各种自然条件下复杂的人脸场景。mtcnn是两年前发表的成果,在原作者实现的时候先后有两个版本:V1和V2。V1就是用matlab实现的论文《Joint Face Detection and Alignment using Multi-task Cascaded Convolutional Neural Networks》,V2在V1的stage3后又添加了一个stage4,以实现更精确的回归。
训练前,对图像做了multi scale的resize,构成了图像金字塔,然后这些不同scale的图像作为3个stage的输入进行训练,目的是为了可以检测不同scale的人脸。
将图像进行多级scale操作(除了第一次resize,每次resize操作使得待检测图片的面积变为之前的一半),如果最小边长小于12,则停止scale操作;对于720p的图片来说,一共会进行11次scale: [0.6, 0.4242640687119285, 0.3, 0.21213203435596426, 0.15, 0.10606601717798213, 0.075, 0.053033008588991064, 0.0375, 0.026516504294495532, 0.01875];然后将11个不同尺度的图片送入P-Net;
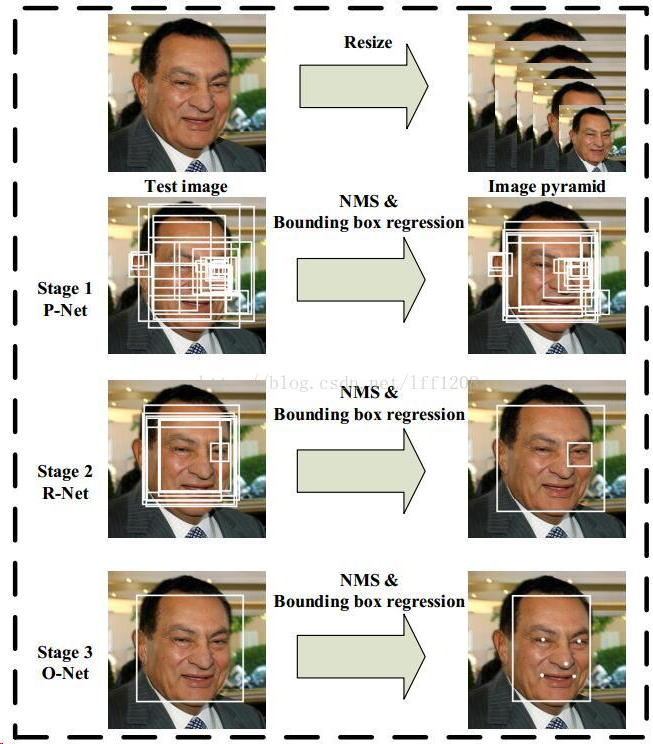
MTCNN由三个子模型组成,由粗到细(coarse-to-fine)生成结果:
P(Proposal)-Net:浅层的全卷积神经网络CNN快速产生候选窗体和边界回归向量,利用NMS方法去除重叠窗体。在训练阶段,顶部有3条支路用来分别做人脸分类、人脸框的回归和人脸关键点定位;在推理阶段,输出只有N个bounding box的4个坐标信息和score,当然这4个坐标信息已经用回归支路的输出进行修正了,score可以看做是人脸的概率,具体可以看代码。
R(Refine)-Net:通过更复杂的全连接CNN精炼候选窗体,利用边界框向量微调候选窗体,再利用NMS去除重叠窗体,丢弃大量的重叠窗体。输入是P-Net中得到的大量bounding box并都被resize成24*24尺寸。同样在推理阶段,这一步的输出只有M个bounding box的4个坐标信息和score,4个坐标信息也用回归支路的输出进行修正了。
O(Output)-Net:网络结构比R-Net多一层卷积,功能与R-Net作用一样,只是在去除重叠候选窗口的同时,显示五个人脸关键点定位。输入大小调整为48*48,输出包含P个bounding box的4个坐标信息、score和关键点信息。

二、损失函数
1. face classification
判定是否包含face的二分类问题,采用交叉熵损失函数

2.bounding box regression
回归检测人脸包围盒,使用L2 loss

3.facial landmark localization

4. 权值平衡
不同的阶段对应的损失函数组合不一样,权重也不一样,因此定义了公式4用来控制对不同的输入计算不同的损失。可以在出,在P-Net和R-Net中,关键点的损失权重(α)要小于O-Net部分,这是因为前面2个stage重点在于过滤掉非人脸的bbox。β存在的意义是比如非人脸输入,就只需要计算分类损失,而不需要计算回归和关键点的损失。 
三 模型细节
- PNet
图片尺寸:12*12*3
卷积层一 : [in_channel(3), shape(3), shape(3), out_channel(10)] 激活PReLU MaxPool
卷积层二 : [in_channel(10), shape(3), shape(3), out_channel(16)] 激活PReLU MaxPool
卷积层三 : [in_channel(16), shape(3), shape(3), out_channel(32)] 激活PReLU
卷积层四_一 : [in_channel(32), shape(1), shape(1), out_channel(2)] conv4-1 激活Softmax 到 prob1层 对应人脸概率的得分
卷积层四_二 : [in_channel(32), shape(1), shape(1), out_channel(4)] conv4-2
rnet: 24x24x3, onet:48x48x3
三、人脸对齐的一些笔记

 浙公网安备 33010602011771号
浙公网安备 33010602011771号