
音乐分类/生成杂记
任何的自动语音识别系统中,第一步一般都是提取特征,也就是把音频信号中具有辨识性的成分提取出来,舍弃掉其他不相关的信息,比如背景噪音等等。而语音的特征提取本质上是降低信号的冗余度,用较少的数据表现语音的特征。
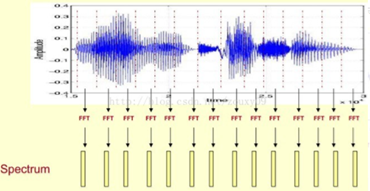
这里,这段语音被分为很多帧,每帧语音都对应于一个频谱(通过短时FFT计算),频谱表示频率与能量的关系。在实际使用中,频谱图有三种,即线性振幅谱、对数振幅谱、自功率谱(对数振幅谱中各谱线的振幅都作了对数计算,所以其纵坐标的单位是dB(分贝)。这个变换的目的是使那些振幅较低的成分相对高振幅成分得以拉高,以便观察掩盖在低幅噪声中的周期信号)。
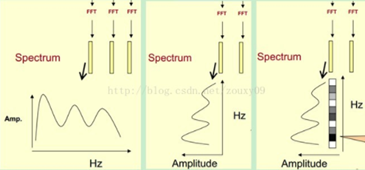
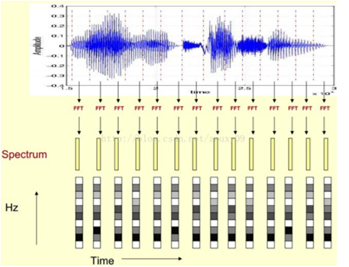
我们先将其中一帧语音的频谱通过坐标表示出来,如上图左。现在我们将左边的频谱旋转90度。得到中间的图。然后把这些幅度映射到一个灰度级表示(也可以理解为将连续的幅度量化为K(16、32等)个量化值),0表示黑,255表示白色。幅度值越大,相应的区域越黑。这样就得到了最右边的图。把每一帧的声谱按照时间顺序平行拼接起来,会得到一个随着时间变化的频谱图,这个就是描述语音信号的spectrogram声谱图。
2.1.2 梅尔频率倒谱系数(MFCC)提取
为实现歌曲的音乐基因标注,首先需要将音频转化成计算机能够识别的格式,同时要求对音频不失真,业界最常用到的语音特征就是梅尔频率倒谱系数(Mel-scale Frequency Cepstral Coefficients,MFCC)。
MFCC:梅尔声谱特征,是音频表示的基础特征,它是一种在自动语音和说话人识别中广泛使用的特征。根据人耳听觉机理的研究发现,人耳对不同频率的声波有不同的听觉敏感度。从200Hz到5000Hz的语音信号对语音的清晰度影响对大。两个响度不等的声音作用于人耳时,则响度较高的频率成分的存在会影响到对响度较低的频率成分的感受,使其变得不易察觉,这种现象称为掩蔽效应。由于频率较低的声音在内耳蜗基底膜上行波传递的距离大于频率较高的声音,故一般来说,低音容易掩蔽高音,而高音掩蔽低音较困难。在低频处的声音掩蔽的临界带宽较高频要小。所以,人们从低频到高频这一段频带内按临界带宽的大小由密到疏安排一组带通滤波器,对输入信号进行滤波。将每个带通滤波器输出的信号能量作为信号的基本特征,对此特征经过进一步处理后就可以作为语音的输入特征。由于这种特征不依赖于信号的性质,对输入信号不做任何的假设和限制,又利用了听觉模型的研究成果。因此,这种更符合人耳的听觉特性,而且当信噪比降低时仍然具有较好的识别性能。
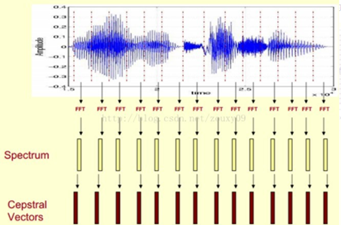
得到MFCC特征之后,音频就可以通过一系列的倒谱向量来描述了,每个向量就是每帧的MFCC特征向量。
特征提取的流程如下:

首先生成二进制PCM文件,再将其进行等量切分,然后对每个PCM提取MFCC特征,计算均值、协方差生成最终模型特征。
① 将音频文件利用模数转换成数字信号,生成PCM二进制文件,包括采样和量化,即以采样率和采样位数把声音连续波形转换成离散的数据点。
② 为了产生更多的训练特征和集成学习,利用切片工具将PCM文件按照大小每625kb切为1片,小于625KB的不作切分,直接输出,为音频特征抽取做好数据准备,其中切片的大小可以设定,一首歌曲通常分成10~20个小文件。
③ 根据PCM文件提取MFCC(梅尔声谱)特征,对语音信号进行分帧,加窗,求取频谱及倒谱操作
1)先对语音进行预加重、分帧和加窗;
2)对每一个短时分析窗,通过FFT得到对应的频谱;
3)将上面的频谱通过Mel滤波器组得到Mel频谱;
4)在Mel频谱上面进行倒谱分析(取对数,做逆变换,实际逆变换一般是通过DCT离散余弦变换来实现,取DCT后的第2个到第13个系数作为MFCC系数),获得Mel频率倒谱系数MFCC,这个MFCC就是这帧音频的特征。
④ 计算MFCC每维特征的均值、协方差,生成libsvm格式的特征,可以直接传给模型训练。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号