java高级(更新中)
多线程的创建
方式一: 继承于Thread类
- 创建一个继承于Thread类的子类
- 重写Thread类的run() --> 将此线程执行的操作声明在run()中
- 创建Thread类的子类的对象
- .通过此对象调用start()
测试Thread中的常用方法:
1. start():启动当前线程;调用当前线程的run()
2. run():通常需要重写Thread类中的此方法,将创建的线程要执行的操作声明在此方法中
3. currentThread():静态方法,返回执行当前代码的线程
4. getName()∶获取当前线程的名字
5. setName():设置当前线程的名字
6. yield():释放当前cpu的执行权
7. join():在线程a中调用线程b的join(),此时线程a就进入阻塞状态,直到线程b完全执行完以后,线程a才结束阻塞状态。
8. stop():已过时。当执行此方法时,强制结束当前线程。
9. sleep(long millitime):让当前线程*睡眠"指定的millitime毫秒。在指定的millitime毫秒时间内,当前线程是阻塞状态。
10. isAlive():判断当前线程是否存活
线程的优先级:
1.
MAX_PRIORITY: 10
MIN_PRIORITY: 1
NORM_PRIORITY: 5-->默认优先级
2.如何获取和设置当前线程的优先级:
getPriority():获取线程的优先级
setpriority( int p)∶设置线程的优先级
说明:高优先级的线程要抢占低优先级线程cpu的执行权。但是只是从概率上讲,高优先级的线程高概率的情况下被执行。并不意味着只有当高优先级的线程执行完以后,低优先级的线程才执行。
创建多线程的方式二:实现Runnable接口
1.创建一个实现了Runnable接口的类
2.实现类去实现Runnable中的抽象方法: run()
3.创建实现类的对象
4.将此对象作为参数传递到Thread类的构造器中,创建Thread类的对象
5.通过Thread类的对象调用start()
比较创建线程的两种方式。
开发中:优先选择:实现Runnable接口的方式
原因:
1.实现的方式没有类的单继承性的局限性
2.实现的方式更适合来处理多个线程有共享数据的情况。
联系:
public class Thread implements Runnable
相同点:两种方式都需要重写run(),将线程要执行的逻辑声明在run()中。
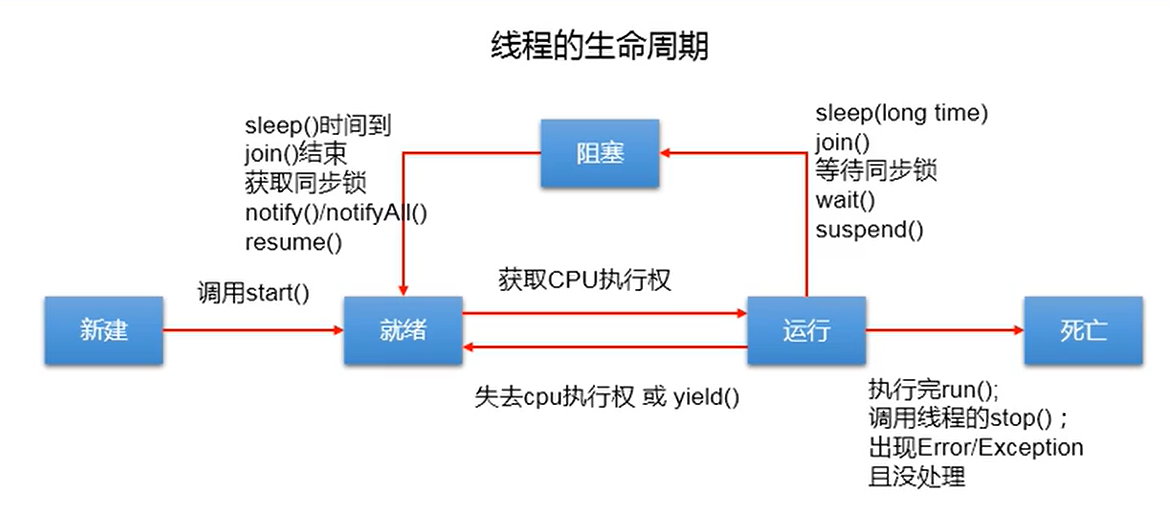
线程的生命周期
线程安全问题
例子:创建三个窗口卖票,总票数为100张.使用实现Runnable接口的方式
1.问题:卖票过程中,出现了重票、错票-->出现了线程的安全问题
2.问题出现的原因:当某个线程操作车票的过程中,尚未操作完成时,其他线程参与进来,也操作车票
3.如何解决:当一个线程a在操作ticket的时候,其他线程不能参与进来。直到线程a操作完ticket时,线程才可以开始操作ticket。这种情况即使线程a出现了阻塞,也不能被改变。
4.在Java中,我们通过同步机制,来解决线程的安全问题。
方式一:同步代码块(临界区)
synchronized(同步监视器){
//需要被同步的代码
}
说明:
1.操作共享数据的代码,即为需要被同步的代码
2.共享数据:多个线程共同操作的变量。比如: ticket就是共享数据。
3.同步监视器,俗称:锁。任何一个类的对象,都可以充当锁。
要求:多个线程必须要共用同一把锁。
补充:在实现Runnable接口创建多线程的方式中,我们可以考虑使用this充当同步监视器。
方式二:同步方法
如果操作共享数据的代码完整的声明在一个方法中,我们不妨将此方法声明同步的。
使用同步方法解决实现Runnable接口的线程安全问题
关于同步方法的总结:
1.同步方法仍然涉及到同步监视器,只是不需要我们显式的声明。
2.非静态的同步方法,同步监视器是:this
静态的同步方法,同步监视器是:当前类本身
5.同步的方式,解决了线程的安全问题。---好处
操作同步代码时,只能有一个线程参与,其他线程等待。相当于是一个单线程的过程,效率低。
解决线程安全问题的方式三:Lock锁--- JDK5.日新增
1.synchronized 与Lock的异同?
相同:二者都可以解决线程安全问题
不同: synchronized机制在执行完相应的同步代码以后,自动的释放同步监视器
Lock需要手动的启动同步(Lock()),同时结束同步也需要手动的实现(unLock())
2.优先使用顺序:
Lock →同步代码块(已经进入了方法体,分配了相应资源)→同步方法(在方法体之外)
1 public class LockTest { 2 public static void main(String[] args) { 3 SThread sT = new SThread(); 4 5 Thread t1 = new Thread(sT); 6 Thread t2 = new Thread(sT); 7 Thread t3 = new Thread(sT); 8 9 t1.start(); 10 t2.start(); 11 t3.start(); 12 13 14 } 15 } 16 17 class SThread implements Runnable { 18 private int tickets = 100; 19 //Object obj = new Object(); 20 private ReentrantLock lock = new ReentrantLock(true); 21 22 @Override 23 public void run() { 24 while (true) { 25 try { 26 lock.lock(); 27 if (tickets > 0) { 28 System.out.println("" + Thread.currentThread().getName() + ":" + tickets); 29 tickets--; 30 } else { 31 return; 32 } 33 } 34 finally 35 { 36 lock.unlock(); 37 } 38 39 } 40 41 } 42 }
使用ReentrantLock 类
private ReentrantLock lock = new ReentrantLock(true);
用ReentrantLock 的对象调用lock方法和unlock方法进行“锁”
线程通信
线程通信的例子:使用两个线程打印1-100。线程1,线程2交替打印
public class ThreadTest02 { public static void main(String[] args) { SThread sT = new SThread(); Thread t1 = new Thread(sT); Thread t2 = new Thread(sT); //Thread t3 = new Thread(sT); t1.start(); t2.start(); //t3.start(); } } class SThread implements Runnable { private int tickets = 100; //Object obj = new Object(); @Override public void run() { while (true) { synchronized (this) { notify(); if (tickets > 0) { System.out.println("" + Thread.currentThread().getName() + ":" + tickets); tickets--; } else { return; } try { wait(); } catch (InterruptedException e) { e.printStackTrace(); } } } } }
涉及到的三个方法:
wait():一旦执行此方法,当前线程就进入阻塞状态,并释放同步监视器。
notify():一旦执行此方法,就会唤醒被wait的一个线程。如果有多个线程被wait,就唤醒优先级高的那个线程
否则,会出现ILlegalMonitorStateException异常
notifyALL():一旦执行此方法,就会唤醒所有被wait的线程。
sLeep()和wait()的异同?
1.相同点:一旦执行方法,都可以使得当前的线程进入阻塞状态。
2.不同点:
1)两个方法声明的位置不同:Thread类中声明sLeep() , object类中声明wait()
2)调用的要求不同: sleep()可以在任何需要的场景下调用。wait()必须使用在同步代码
3)关于是否释放同步监视器:如果两个方法都使用在同步代码块或同步方法中,sleep()不会释放锁,wait会释放锁
创建线程方式三:通过Callable接口实现
package org.ThreadTest.First; //创建线程方式三,实现Callable接口 ---jdk5.0新增 import sun.applet.Main; import java.util.concurrent.Callable; import java.util.concurrent.ExecutionException; import java.util.concurrent.FutureTask; class NewThread implements Callable { private int sum = 0; @Override public Object call() throws Exception { for (int i = 1; i < 100; i++) { System.out.println(""+Thread.currentThread().getName()+":"+i); sum += i; } return sum; } } public class ThreadNew { public static void main(String[] args) throws ExecutionException, InterruptedException { NewThread nt = new NewThread(); FutureTask Ft = new FutureTask(nt); new Thread(Ft).start(); Object sum = Ft.get(); System.out.println("总和为:"+sum); } }
如何理解实现calLable接口的方式创建多线程比实现Runnable接口创建多线程方式强大
1. calL()可以有返回值的。
2. calL()可以抛出异常,被外面的操作捕获,获取异常的信息
3. callable是支持泛型的
创建线程的方式四:使用线程池
好处:
1.提高响应速度(减少了创建新线程的时间)
2.降低资源消耗(重复利用线程池中线程,不需要每次都创建)
3.便于线程管理
corePoolsize:核心池的大小
maximumPooLsize:最大线程数
keepAliveTime:线程没有任务时最多保持多长时间后会终止
class numThread implements Runnable { @Override public void run() { for (int i = 0; i < 100; i++) { System.out.println(""+Thread.currentThread().getName()+":"+i); } } } class numThread1 implements Runnable { @Override public void run() { for (int i = 0; i < 100; i++) { System.out.println(""+Thread.currentThread().getName()+":"+i); } } } class numThread2 implements Callable { private int sum = 0; @Override public Object call() throws Exception { for (int i = 0; i < 100; i++) { System.out.println(""+Thread.currentThread().getName()+":"+i); sum += i; } return null; } } public class ThreadPool { public static void main(String[] args) { ExecutorService service = Executors.newFixedThreadPool(10); //设置线程属性 ThreadPoolExecutor service1 = (ThreadPoolExecutor)service; //service1.setCorePoolSize(); service.execute(new numThread()); service.execute(new numThread1()); service.submit(new numThread2()); service.shutdown(); } }
常用类
string:
字符串,使用一对””引起来表示。
1.String声明为finaL的,不可被继承
2.String实现了SerializabLe接口:表示字符串是支持序列化的。
实现了Comparable接口:表示String可以比较大小
3.String内部定义了final char[ ] value用于存储字符串数据
4.String:代表不可变的字符序列。简称:不可变性。
体现:
1.当对字符串重新赋值时,需要重写指定内存区域赋值,不能使用原有的value进行赋值。
2.当对现有的字符串进行连接操作时,也需要重新指定内存区域赋值,不能使用原有的value进行赋值。
3.当调用string的replace()方法修改指定字符或字符串时,也需要重新指定内存区域
5.通过字面量的方式(区别于new)给一个字符串赋值,此时的字符串值声明在字符串常量池中。
6.字符串常量池中是不会存储相同内容的字符串的。
上面是new一个String 下面是在常量区,String s = “abc”这样直接赋值
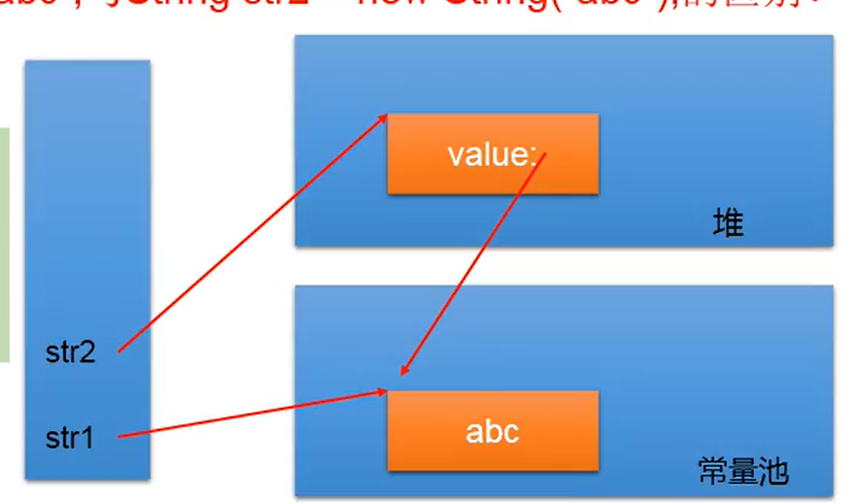
- 常量与常量的拼接结果在常量池。且常量池中不会存在相同内容的常量。
- 只要其中有一个是变量,结果就在堆中
- 如果拼接的结果调用intern()方法,返回值就在常量池中
String,StringBuffer,StringBuilder
String、StringBuffer、StringBuilder三者的异同?
String:不可变的字符序列;底层使用char[]存储
StringBuffer:可变的字符序列;线程安全的,效率低;底层使用char[]存储
StringBuilder:可变的字符序列;jdk5.0新增的,线程不安全的,效率高;底层使用char[]存储
对比String、StringBuffer、StringBuilder三者的效率:
从高到低排列: StringBuilder > StringBuffer > String
java.util.Date类
/---java.sqL.Date类(时util.Date的子类)
1.两个构造器的使用
>构造器一: Date():创建一个对应当前时间的Date对象
>构造器二:创建指定毫秒数的Date对象
2.两个方法的使用
>toString():显示当前的年、月、日、时、分、秒
>getTime():获取当前Date对象对应的毫秒数。(时间戳)
3. java.sqL.Date对应着数据库中的日期类型的变量
>如何实例化
>如何将java.util.Date对象转换为java.sql. Date对象
方式一(局限,有时候我们用不到多态):
Date date = new java.sql.Date(15456411564648L); java.sql.Date date1 = (java.sql.Date)date;
方式二:
Date date = new Date(); java.sql.Date date1 = new java.sql.Date(date.getTime());
jdk 8之前的日期时间的API测试
1. System类中currentTimeMillis();
2. java.util.Date和子类java.sql.Date
3. simpLeDateFormat
4. calendar
simpLeDateFormat
@Test public void TestSimpleDateFormat() throws ParseException { //格式化:日期--->字符串 SimpleDateFormat Sdf = new SimpleDateFormat(); Date d = new Date(); String s= Sdf.format(d); System.out.println(s); //格式化的反过程,解析:字符串---->日期 String s1 = "21-5-5 下午9:11"; Date d1 = Sdf.parse(s1); System.out.println(d1); }
指定方式进行格式化和解析
通过带参的构造器
SimpleDateFormat sddf = new SimpleDateFormat("yyyy-MM-dd hh:mm:ss"); Date d2 = new Date(); String s2= sddf.format(d); System.out.println(s2);
String s3 = "2021-05-05 09:18:43";
Date d3 = sddf.parse(s3);
System.out.println(d3);
Calendar
public void TestCalendar() { Calendar c = Calendar.getInstance(); int day = c.get(Calendar.DAY_OF_WEEK); System.out.println(day); Date d = c.getTime(); System.out.println(d); }

jdk8.0之后与日期相关的API

LocalDate、 LocaLTime、 LocalDateTime 的使用
@Test public void TestLocalDate() { //now(); LocalDate localdate = LocalDate.now(); LocalTime localtime = LocalTime.now(); LocalDateTime localDateTime = LocalDateTime.now(); //of()设置时间 LocalDateTime localDateTime1 = localDateTime.of(2021,5,6,16,10); System.out.println(localDateTime1); }
Instant
@Test public void TestInstant() { Instant instant = Instant.now();//本初子午线的时间 System.out.println(instant); //当前地区时间 OffsetDateTime offsetDateTime = instant.atOffset(ZoneOffset.ofHours(8)); System.out.println(offsetDateTime); long epochMilli= instant.toEpochMilli(); //时间戳(毫秒级别) System.out.println(epochMilli); Instant instant1 = Instant.ofEpochMilli(1620289151747L); System.out.println(instant1); }
其他时间API,这里太多了

java比较器
一、说明: Java中的对象,正常情况下,只能进行比较: ==或!=。不能使用〉或〈的
但是在开发场景中,我们需要对多个对象进行排序,言外之意,就需要比较对象的大小。
如何实现?使用两个接口中的任何一个: Comparable或Comparator
Comparable接口的使用:
Comparable接口的使用举例:
1.像String、包装类等实现了Comparable接口,重写了compareTo()方法,给出了比较两个对象大小的方式
package org.sd.compareable; public class Goods implements Comparable{ private String Name; private Double price; public String getName() { return Name; } public Double getPrice() { return price; } public Goods(String name, Double price) { Name = name; this.price = price; } @Override public String toString() { return "Goods{" + "Name='" + Name + '\'' + ", price=" + price + '}'; } @Override public int compareTo(Object o) { if(o instanceof Goods) { Goods goods = (Goods) o; if(this.price>goods.price) { return 1; } else if(this.price<goods.price) { return -1; } else { return this.Name.compareTo(goods.Name); //return 0; } } throw new RuntimeException("传入数据类型不一致!"); } }
public class TestCompareable{ @Test public void Test() { Goods[] arr = new Goods[3]; arr[0] = new Goods("Tom",16.8); arr[1] = new Goods("lucy",980.2); arr[2] = new Goods("jack",93.5); Arrays.sort(arr); System.out.println(Arrays.toString(arr)); } }
Comparator接口的使用:
定制排序1.背景:
当元素的类型没有实现java.Lang.Comparable接口而又不方便修改代码,
或者实现了java.Lang. Comparable接口的排序规则不适合当前的操作,
那么可以考虑使用Comparator的对象来排序
二、comparable接口与Comparator的使用的对比:
Comparable接口的方式一旦一定,保证Comparable接口实现类的对象在任何位置都可以比较大小
Comparator接口属于临时性的比较。
@Test public void test3() { String[] arr = new String[]{"AA","BB","CC","MM","GG","OO"}; Arrays.sort(arr, new Comparator() { @Override public int compare(Object o1, Object o2) { if (o1 instanceof String && o2 instanceof String) { String s1 = (String) o1; String s2 = (String) o2; return -s1.compareTo(s2); } throw new RuntimeException("数据类型不一样!"); } }); System.out.println(Arrays.toString(arr)); }
注解
注解的使用
1.理解Annotation:
- jdk 5.新增的功能
- Annotation其实就是代码里的特殊标记,这些标记可以在编译,类加载。运行时被读取,并执行相应的出处理,程序员可以在不改变原有逻辑的情况下,在源文件中嵌入一些补充信息。
- 在JavaSE中,注解的使用目的比较简单,例如标记过时的功能,忽略警告等。在JavaEE/Android中注解占据了更重要的角色,例如用来配置应用程序的任何切面,代替JavaEE旧版中所遗留的繁代码和XML配置等。
2. Annocation的使用示例
示例一:生成文档相关的注解
示例二:在编译时进行格式检查(JDK内置的三个基本注解)
@Override:限定重写父类方法,该注解只能用于方法
@Deprecated:用于表示所修饰的元素(类,方法等)已过时。通常是因为所修饰的结构危险或存在更好的选择
@Suppresswarnings:抑制编译器警告
3.如何自定义注解
参照@Suppresswarnings定义
- 注解声明为:@interface
- 内部定义成员,通常使用vaLue表示
- 可以指定成员的默认值,使用default定义
- 如果自定义注解没有成员,表明是一个标识作用。
- 如果注解有成员,在使用注解时,需要指明成员的值。
如果注解有成员,在使用注解时,需要指明成员的值。
4.元注解
jdk提供的4种元注解
元注解:对现有的注解进行解释说明的注解
Retention:指定所修饰的Annotation 的生命周期: SOURCE\CLASS(默认行为)\RUNTIME
只有声明为RUNTIME生命周期的注解,才能通过反射获取。
Target
Documented
Inherited
集合之collection
package org.sd.java; import org.junit.Test; import java.util.ArrayList; import java.util.Arrays; import java.util.Collection; /** *向Collection接口的实现类的对象中添加数据时,要求obj所在类要重写equals方法 * * @Author:SD * @Date:Created in 16:22 2021/5/26 * @Github:https://github.com/SD-XD * @Blog:https://www.cnblogs.com/punished/ */ public class CollectionTest { @Test public void test1() { Collection coll = new ArrayList(); coll.add(123); coll.add(456); coll.add(new String("Tom")); coll.add(new Person("jerry",30)); //1.contains(object obj),判断当前集合中是否包含pbj boolean contains = coll.contains(123); System.out.println(contains); System.out.println(coll.contains(new String("Tom"))); //判断的内容,调用equals System.out.println(coll.contains(new Person("jerry",30))); //containsAll(Collection coll);判断形参coll中的所有元素都存在于当前集合中 Collection coll1 = Arrays.asList(123, 456); System.out.println(coll.containsAll(coll1)); } @Test public void Test2() //3.remove(Object obj) 移除操作 { Collection coll = new ArrayList(); coll.add(123); coll.add(456); coll.add(new String("Tom")); coll.add(new Person("jerry",30)); coll.remove(123); System.out.println(coll); //4.removeAll(Collection coll1) 从当前集合中一出coll1所有元素 Collection coll1 = Arrays.asList(123,456); coll.removeAll(coll1); System.out.println(coll); } @Test public void Test3() //3.remove(Object obj) 移除操作 { Collection coll = new ArrayList(); coll.add(123); coll.add(456); coll.add(new String("Tom")); coll.add(new Person("jerry",30)); //5.retainAll(Collection coll1) 获取当前集合和coll1集合的交集,并返回给当前集合 /* Collection coll1 = Arrays.asList(123,456,789); coll.retainAll(coll1); System.out.println(coll);*/ //6.equals(Object obj)要想返回true,判断当前集合的形参 Collection coll1 = new ArrayList(); coll1.add(456); coll1.add(123); coll1.add(new String("Tom")); coll1.add(new Person("jerry",30)); System.out.println(coll.equals(coll1)); } @Test public void Test4() { Collection coll = new ArrayList(); coll.add(123); coll.add(456); coll.add(new String("Tom")); coll.add(new Person("jerry",30)); //7.hashcode();返回当前对象hash值 System.out.println(coll.hashCode()); //8.集合-->手机壳i,toArray() } }
Person测试类
package org.sd.java; import java.util.Objects; /** * @Author:SD * @Date:Created in 16:26 2021/5/26 * @Github:https://github.com/SD-XD * @Blog:https://www.cnblogs.com/punished/ */ public class Person { private String name; private int age; public String getName() { return name; } public Person(String name, int age) { this.name = name; this.age = age; } public int getAge() { return age; } public void setName(String name) { this.name = name; } @Override public String toString() { return "Person{" + "name='" + name + '\'' + ", age=" + age + '}'; } @Override public boolean equals(Object o) { if (this == o) return true; if (o == null || getClass() != o.getClass()) return false; Person person = (Person) o; return age == person.age && Objects.equals(name, person.name); } /*@Override public int hashCode() { return Objects.hash(name, age); }*/ public void setAge(int age) { this.age = age; } }
迭代器使用
集合元素的遍历操作,使用迭代器Iterator接口
1.内部的方法:hasNext()和next()
2.集合对象每次调用iterator()方法都得到一个全新的迭代器对象,
默认游标都在集合的第一个元素之前。
3.内部定义了remove(),可以在遍历的时候,删除集合中的元素。此方法不同于集合直接调用remove()
迭代器原理
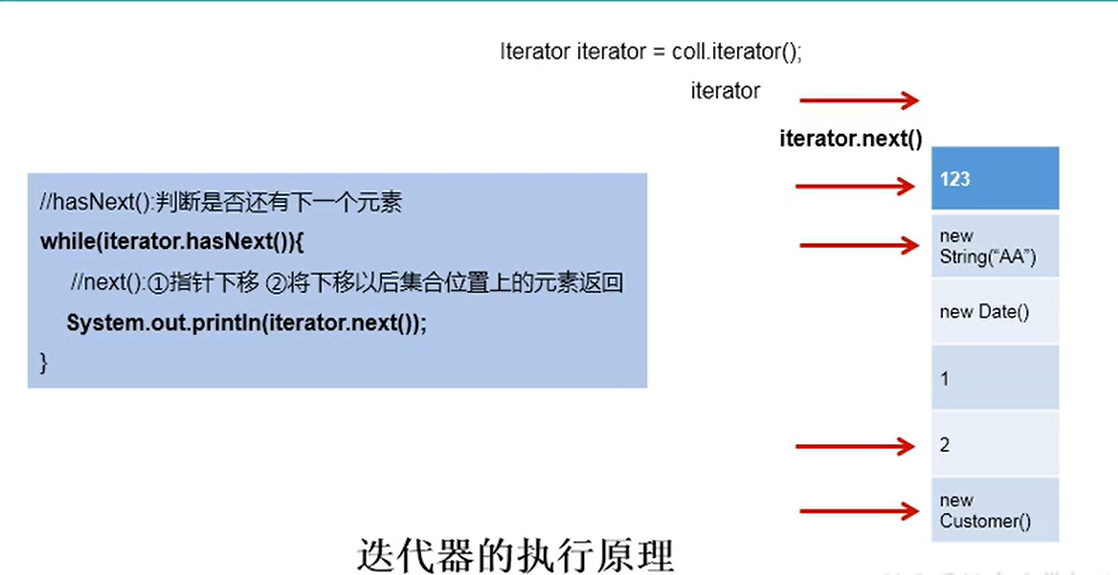
public class IteratorTest { @Test public void test1() { Collection coll = new ArrayList(); coll.add(123); coll.add(456); coll.add(new String("Tom")); coll.add(new Person("jerry",30)); coll.add(false); Iterator iterator = coll.iterator(); //方式一: /*System.out.println(iterator.next()); System.out.println(iterator.next()); System.out.println(iterator.next()); System.out.println(iterator.next()); System.out.println(iterator.next()); //抛异常 NoSuchElementException ,不建议 System.out.println(iterator.next());*/ //方式二:同样不推荐 /*for(int i = 0; i<5; i++) { System.out.println(iterator.next()); }*/ //方式三:推荐 while(iterator.hasNext()) { System.out.println(iterator.next()); } } }
增强for循环(foreach)

@Test public void Test1() { Collection coll = new ArrayList(); coll.add(123); coll.add(456); coll.add(new String("Tom")); coll.add(new Person("jerry",30)); coll.add(false); //for(集合元素的类型 局部变量:集合对象) for(Object obj:coll) { System.out.println(obj); } } @Test public void test2() { int[] arr = new int[]{1,2,3,4,5}; for(int i:arr) { System.out.println(i); } }
Collection子接口之一List接口
Collection接口:单列集合,用来存储一个一个的对象
List接口:存储有序的、可重复的数据。-->“动态”数组,替换原有的数组
- ArrayList:作为List接口的主要实现类,线程不安全的,效率高;底层使用Object[]elementData存储
- LinkedList:对于频繁的插入、删除操作,使用此类效率比ArrayList高;底层使用双向链表存储
- Vector:作为List接口的古老实现类;线程安全的,效率低;底层使用Object[] eLementData存储
ArrayList源码分析
jdk7
ArrayList list = new ArrayList();//底层创建了长度是10的object[]数组eLementData
list.add(123);//eLementData[0] = new Integer(123);
list.add(11);//如果此次的添加导致底层elementData数组容量不够,则扩容。
默认情况下,扩容为原来的容量的1.5倍,同时需要将原有数组中的数据复制到新的数组中。
结论:建议开发中使用带参的构造器: ArrayList list = new ArrayList(int capacity)
jdk8
ArrayList list = new ArrayList();//底层object[] elementData初始化为}.并没有创建长度为10的数组
list.add(123);//第一次调用add()时,底层才创建了长度10的数组,并将数据123添加到eLementDat
后续的添加和扩容操作与jdk 7无异。
小结
jdk7中的ArrayList的对象的创建类似于单例的饿汉式,而jdk8中的ArrayList的对象
的创建类似于单例的懒汉式,延迟了数组的创建,节省内存。
LinkedList源码分析
LinkedList list = new LinkedList(); //内部声明了Node类型的first和Last属性,默认值为null List.add(123);//将123封装到Node中,创建了Node对象。
其中,Node定义为:体现了LinkedList的双向链表的说法
private static class Node<E> { E item; Node<E> next; Node<E> prev; Node(Node<E> prev, E element, Node<E> next) { this.item = element; this.next = next; this.prev = prev; } }
Vector的源码分析
jdk7和jdk8中通过Vector()构造器创建对象时,底层都创建了长度为10的数组,在扩容方面,默认扩容为原来的数组长度的2倍。
List接口方法

List接口常用方法

Connection子接口之二Set接口框架
/----set接口:存储无序的、不可重复的数据-->高中讲的集合”
/----HashSet: 作为Set接口的主要实现类;线程不安全的;可以存储nulL值
/----LinkedHashSet:作为HashSet的子类;遍历其内部数据时,可以按照添加的
/----TreeSet:可以按照添加对象的指定属性,进行排序。
- Set接口中没有额外定义新的方法,使用的都是collection中声明过的方法。
- 要求:向Set中添加的数据,其所在的类一定要重写hashcode()和equals()
- 要求:重写的hashCode()和equals()尽可能保持一致性:相等的对象必须具有相等的散列码
set
一.存储无序的、不可重复的数据
以HashSet为例说明:
1.无序性:不等于随机性。存储的数据在底层数组中并非按照数组索引的顺序添加,而是根据数据的哈希值判断再索引的那个位置
2.不可重复性:保证添加的元素按照equals()判断时,不能返回true.即:相同的元素只能添加一个。
二、添加元素的过程:以Hashset为例:
我们向HashSet中添加元素a,首先调用元素a所在类的hashCode()方法,计算元素a的哈希值,
此哈希值接着通过某种算法计算出在HashSet底层数组中的存放位置(即为:索引位置),
判断数组此位置上是否已经有元素:
如果此位置上没有其他元素,则元素a添加成功。
如果此位置上有其他元素b(或以链表形式存在的多个元素),则比较元素a与元素b的hash值:
- 如果hash值不相同,则元素α添加成功。--->情况2
- 如果hash值相同,进而需要调用元素a所在类的equLas ()方法:
equals()返回true,元素a添加失败
equals()返回faLse,则元素α添加成功。--->情况3
对于添加成功的情况2和情况3而言:元素a与已经存在指定索引位置上数据以链表的方式存储。
jdk 7 ︰元素a放到数组中,指向原来的元素。
jdk 8∶原来的元素在数组中,指向元素a
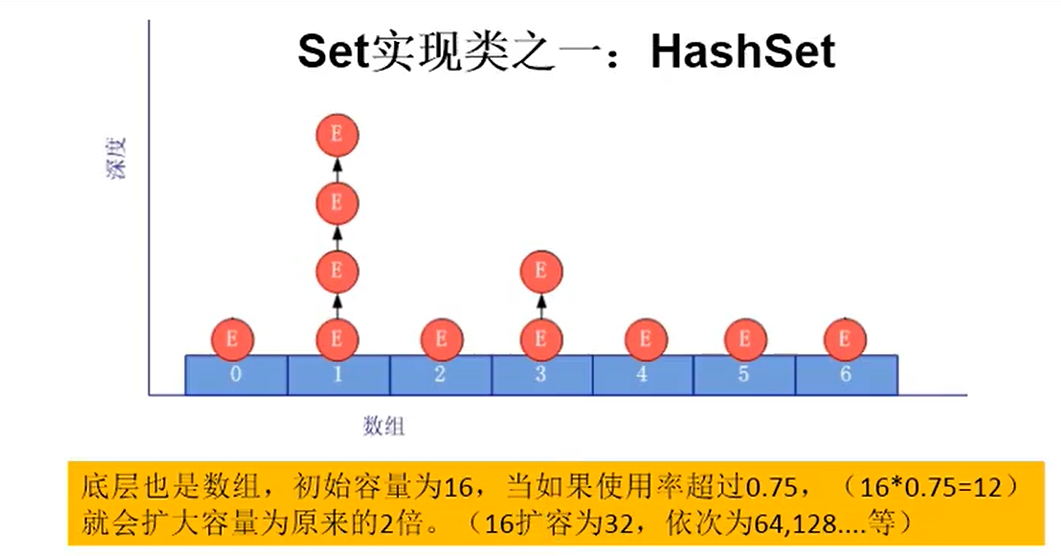
HashSet底层:数组+链表
LinkedHashSet的使用
LinkedHashSet作为HashSet的子类,在添加数据的同时,每个数据还维护了两个引用,记录此数据前一个数据和后一个数据。
优点:对于频繁的遍历操作,LinkedHashSet效率高于HashSet
TreeSet
1.向Treeset中添加的数据,要求是相同类的对象。
2.两种排序方式:自然排序(实现Comparable接口)和定制排序
3.自然排序中,比较两个对象是否相同的标准为: compareTo()返回e.不再是equals( ).
4.定制排序中,比较两个对象是否相同的标准为: compare()返回e.不再是equals().
集合之Map
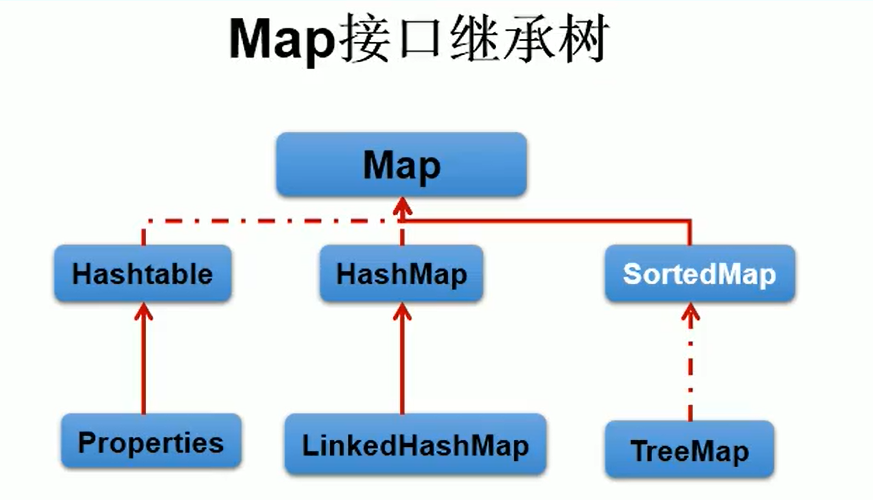
—、Map的实现类的结构:
/----Map:双列数据,存储key-value对的数据---键值对
/----HashMap:作为Map的主要实现类;线程不安全的,效率高;存储nuLl的key和value
/----LinkedHashMap:保证在遍历map元素时,可以按照添加的顺序实现遍历。
原因:在原有的HashMap底层结构基础上,添加了一对指针,指向前一个和后一个元素。
对于频繁的遍历操作,此类执行效率高于HashMap .
/----TreeNap:保证按照添加的key-value对进行排序,实现排序遍历。此时考虑key的自然排序或定制排序
底层使用红黑树
/----Hashtable:作为古老的实现类;线程安全的,效率低;不能存储nulL的key和vaLue
/----Properties:常用来处理配置文件。key和value都是string类型
HashMap的底层:
数组+链表(jdk7及之前)
数组+链表+红黑树(jdk 8)
二、Map结构的理解:
- Map中的Rey:无序的、不可重复的,使用Set存储所有的key ---〉 key所在的类要重写equals()和nashCode()(Hashlap为例)
- Map中的value:无序的、可重复的,使用Collection存储所有的vaLue --->vaLue所在的类要重写equals()
- 一个键值对: key-value构成了一个Entry对象。
- Map中的entry:无序的、不可重复的,使用set存储所有的entry
三、HashMap的底层实现原理
以jdk7为例说明:
HashMap map = new HashMap( ):
在实例化以后,底层创建了长度是16的一维数组Entry[] table。
...可能已经执行过多次put.. .
map.put( key1, vaLue1):
首先,调用key1所在类的hashCode()计算key1哈希值,此哈希值经过某种算法计算以后,得到在Entry数组中的存放位置。
如果此位置上的数据为空,此时的key1-value1添加成功。----情况1
如果此位置上的数据不为空,(意味着此位置上存在一个或多个数据(以链表形式存在)),比较key1和已经存在的一个或多个数据的哈希值:
如果key1的哈希值与已经存在的数据的哈希值都不相同,此时key1-vaLue1添加成功。----情况2
如果key1的哈希值和已经存在的某一个数据(key2-vaLue2)的哈希值相同,继续比较:调用key1所在类的equals(key2)
如果equals()返回false:此时key1-vaLue1添加成功。----情况3
如果equals()返回true:使用value1替换value2。
在不断的添加过程中,会涉及到扩容问题,默认的扩容方式:扩容为原来容量的2倍
jdk8相较于jdk7在底层实现方面的不同:
1. new HashMap():底层没有创建一个长度为16的数组
2. jdk8底层的数组是:Node[],而非Entry[]
3.首次调用put()方法时,底层创建长度为16的数组
4. jdk7底层结构只有:数组+链表。jdk8中底层结构:数组+链表+红黑树。
当数组的某一个索引位置上的元素以链表形式存在的数据个数>8且当前数组的长度>64时,
此时此索引位置上的所有数据改为使用红黑树存储。
DEFAULT_IN工TIAL__CAPACITY : HashMap的默认容量,16
DEFAULT_LOAD_FACTOR: HashMap的默认加载因子:0.75
threshold:扩容的临界值,=容量*填充因子:16*0.75 =>12
TREETFY_ THRESHOLD: Bucket中链表长度大于该默认值,转化为红黑树:8
MIN_TREEIFY_CAPACITY:桶中的Node被树化时最小的hash表容量:64
常用方法
遍历
public class MapTest { @Test public void Test1() { Map map = new HashMap(); map.put("AA",123); map.put("BB",456); map.put("DD",56); //遍历所有key,keySet() Set set = map.keySet(); Iterator iterator = set.iterator(); while(iterator.hasNext()) { System.out.println(iterator.next()); } //遍历所有value,values() Collection values = map.values(); Iterator iterator1 = values.iterator(); while(iterator1.hasNext()) { System.out.println(iterator1.next()); } //遍历所有key-value,entryset() Set entryset = map.entrySet(); Iterator iterator2 = entryset.iterator(); while(iterator2.hasNext()) { Object obj = iterator2.next(); Map.Entry entry = (Map.Entry) obj; System.out.println(entry.getKey()+"-->"+entry.getValue()); } } }
Collections工具类
Collections是一个操作Set、List和 Map等集合的工具类
collections类中提供了多个synchronizedXxx()方法,该方法可使将指定集合包装成线程同步的集合,从而可以解决多线程并发访问集合时的线程安全问题

泛型
什么是泛型
泛型:标签
jdk5.0新增
把元素的类型设计成参数,这个类型参数叫做泛型。
Collection<E>,List<E>,ArrayList<E>这个<E>就是类型参数,即泛型。
只能允许处理改类型
在集合中使用泛型
- 集合接口或集合类在jdk5时都修改为带泛型的结构。
- 在实例化集合类时,可以指明具体的泛型类型
- 指明完以后,在集合类或接口中凡是定义类或接口时,内部结构(比如:方法,构造器,属性等)使用到类的泛型的位置,都指定为实例化的泛型类型。比如: add(E e)--->实例化以后: add ( integer e)
- 注意点:泛型的类型必须是类,不能是基本数据类型。需要用到基本数据类型的位置,拿包装类来代替
- 如果实例化时,没有指明泛型的类型。默认类型为java.Lang. object


通配符的使用
通配符:?
类A是类B的父类,G<A>和G<B>是没有关系的,二者共同的父类是:G<?>
有限制条件的通配符的使用
?extends A:
G<? extends A>可以作为G<A>和G<B>的父类,其中B是A的子类
?super A:
G<?super A>可以作为G<A>和G<B>的父类,其中B是A的父类
IO流
File
1.如何创建File类的实例
- File(String filePath)
- File(string parentPath,String childPath)
- File(File parentFile,String childPath)
2.
相对路径:相较于某个路径下,指明的路径。
绝对路径:包含盘符在内的文件或文件目录的路径
3.路径分隔符
windows : \
lunix: /
File类的常用方法


File类的使用
- FiLe类的一个对象,代表一个文件或一个文件目录(俗称:文件夹)
- FiLe类声明在java.io包下
- 3.FiLe类中涉及到关于文件或文件目录的创建、删除、重命名、修改时间、文件大小等方法,并未涉及到写入或读取文件内容的操作。如果需要读取或写入文件内容,必须使用Io流来完成。
- 后续File类的对象常会作为参数传递到流的构造器中,指明读取或写入的"终点".

 浙公网安备 33010602011771号
浙公网安备 33010602011771号