通过命令管理ceph集群
ceph 集群维护
http://docs.ceph.org.cn/rados/ ceph 集群配置、部署与运维
通过套接字进行单机管理
在ceph的节点上使用socket管理只针对ceph的节点单机管理并不会对所有节点生效
node 节点:
root@ceph-node1:~# ll /var/run/ceph/
total 0
drwxrwx--- 2 ceph ceph 140 Nov 13 10:16 ./
drwxr-xr-x 25 root root 840 Nov 13 10:17 ../
srwxr-xr-x 1 ceph ceph 0 Nov 13 10:16 ceph-osd.0.asok=
srwxr-xr-x 1 ceph ceph 0 Nov 13 10:16 ceph-osd.1.asok=
srwxr-xr-x 1 ceph ceph 0 Nov 13 10:16 ceph-osd.2.asok=
srwxr-xr-x 1 ceph ceph 0 Nov 13 10:16 ceph-osd.3.asok=
srwxr-xr-x 1 ceph ceph 0 Nov 13 10:16 ceph-osd.4.asok=
mon节点
root@ceph-mon1:~# ll /var/run/ceph/
total 0
drwxrwx--- 2 ceph ceph 60 Nov 13 10:16 ./
drwxr-xr-x 25 root root 840 Nov 13 10:18 ../
srwxr-xr-x 1 ceph ceph 0 Nov 13 10:16 ceph-mon.ceph-mon1.asok=
可在 node 节点或者 mon 节点通过 ceph 命令进行单机管理本机的 mon 或者 osd 服务
先将 admin 认证文件同步到 mon 或者 node 节点:
cephadmin@ceph-deploy:~/ceph-cluster$ pwd
/home/cephadmin/ceph-cluster
cephadmin@ceph-deploy:~/ceph-cluster$ scp ceph.client.admin.keyring root@172.16.100.31:/etc/ceph
查看ceph --admin-socket 查看osd的socket 使用帮助
root@ceph-node1:~# ceph --admin-socket /var/run/ceph/ceph-osd.4.asok --help|less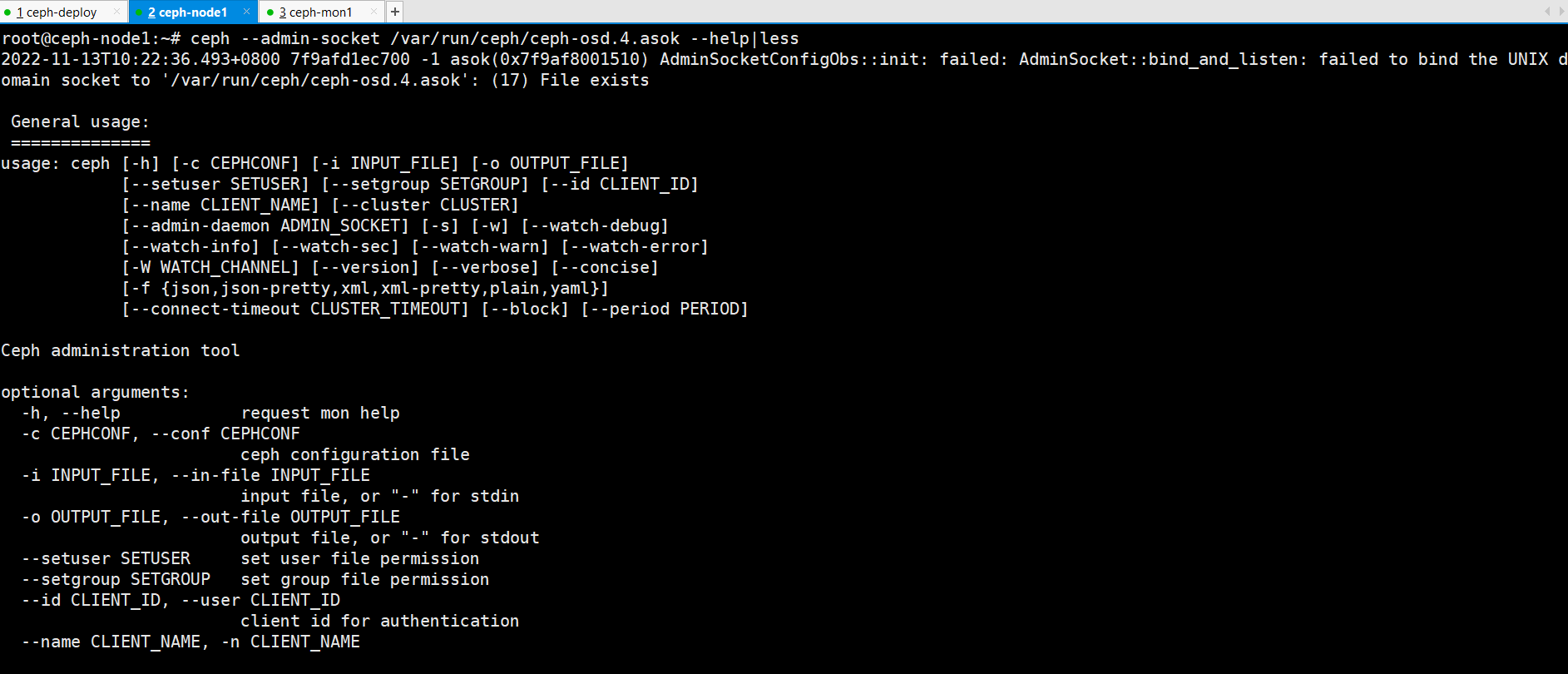
在 mon 节点获取 --admin-daemon 服务帮助
root@ceph-mon1:~# ceph --admin-daemon /var/run/ceph/ceph-mon.ceph-mon1.asok help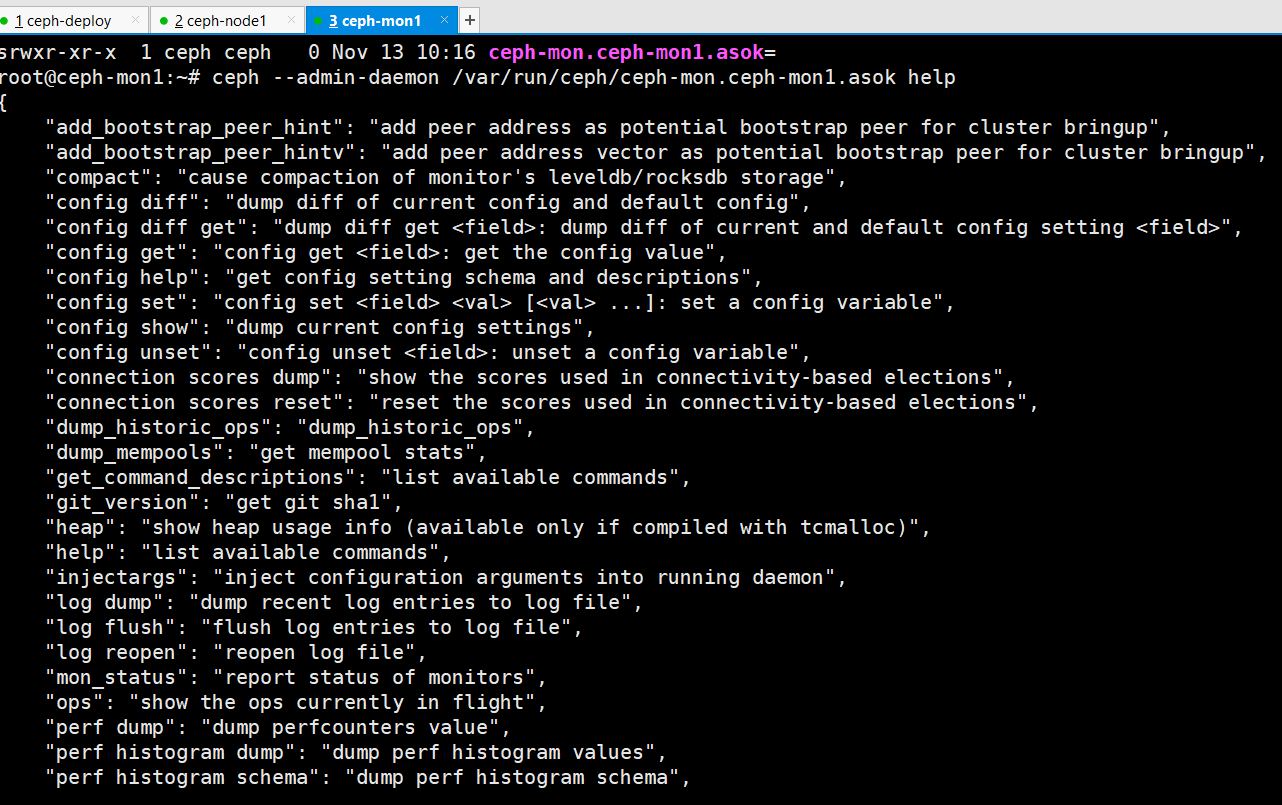
查看mon状态
root@ceph-mon1:~# ceph --admin-daemon /var/run/ceph/ceph-mon.ceph-mon1.asok mon_status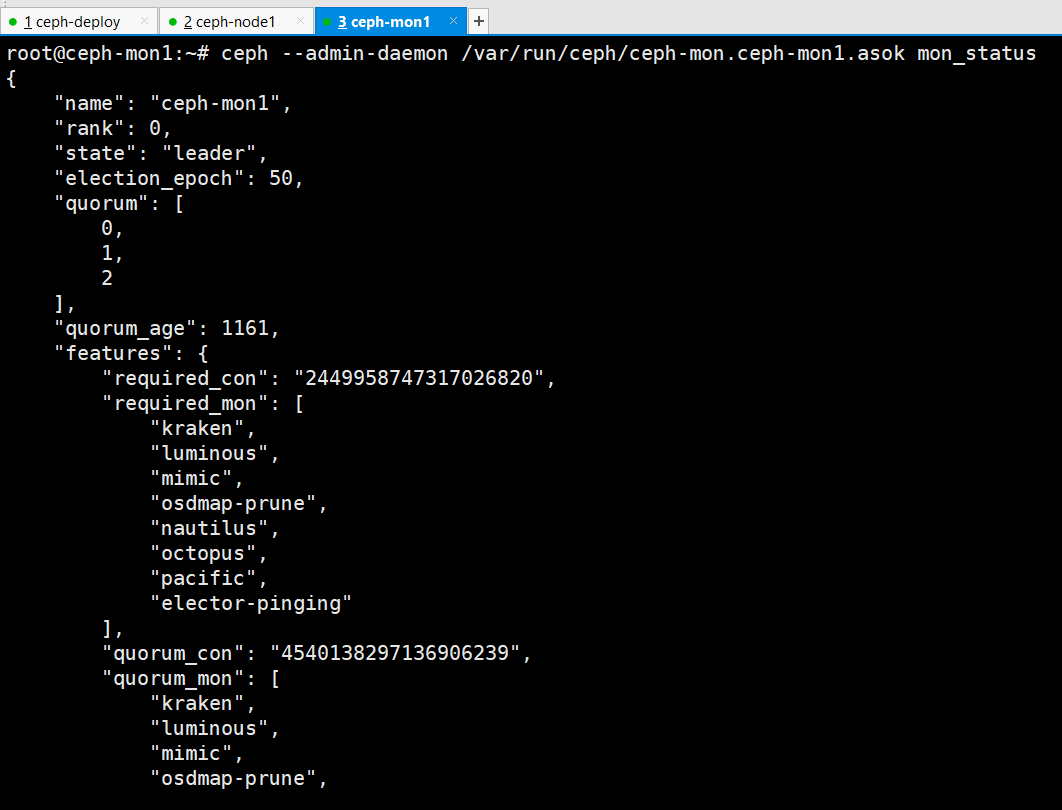
查看mon配置信息
root@ceph-mon1:~# ceph --admin-daemon /var/run/ceph/ceph-mon.ceph-mon1.asok config show | less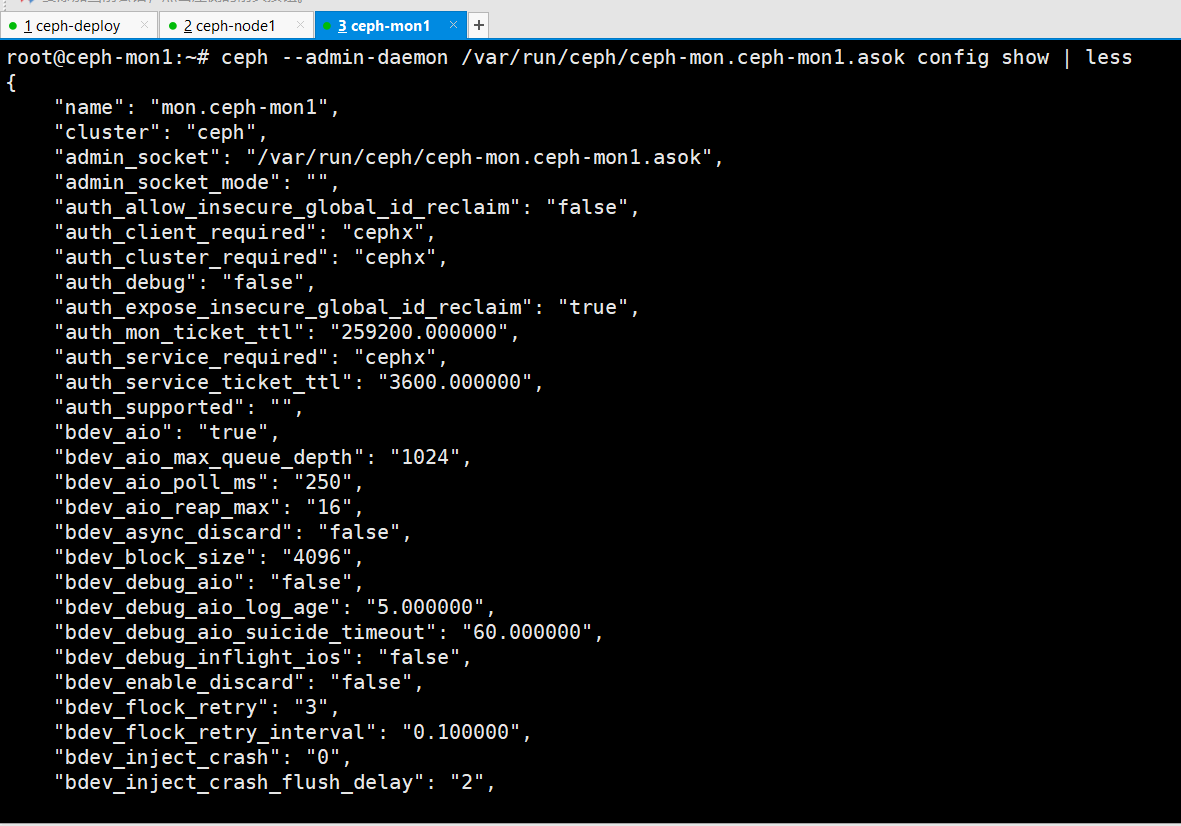
ceph 集群的停止或重启
OSD的维护
重启之前,要提前设置 ceph 集群不要将 OSD 标记为 out,以及将backfill和recovery设置为no,避免 node 节点关闭服务后osd被踢出 ceph 集群外,以及存储池进行修复数据,等待节点维护完成后,再将所有标记取消设置。
cephadmin@ceph-deploy:~/ceph-cluster$ ceph osd set noout
noout is set
cephadmin@ceph-deploy:~$ ceph osd set norecover
norecover is set
cephadmin@ceph-deploy:~$ ceph osd set nobackfill
nobackfill is set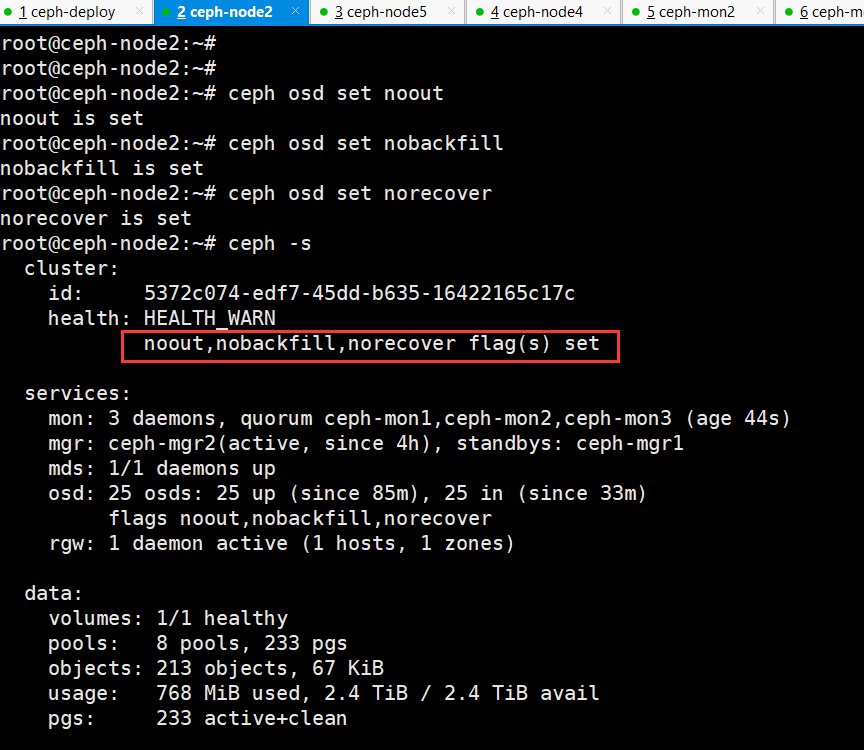
当ceph的节点恢复时,就是用unset取消标记,使集群的osd开始重新服务,并开始修复数据。
cephadmin@ceph-deploy:~/ceph-cluster$ ceph osd unset noout
noout is unset
cephadmin@ceph-deploy:~/ceph-cluster$ ceph osd unset nobackfill
nobackfill is unset
cephadmin@ceph-deploy:~/ceph-cluster$ ceph osd unset norecover
norecover is unset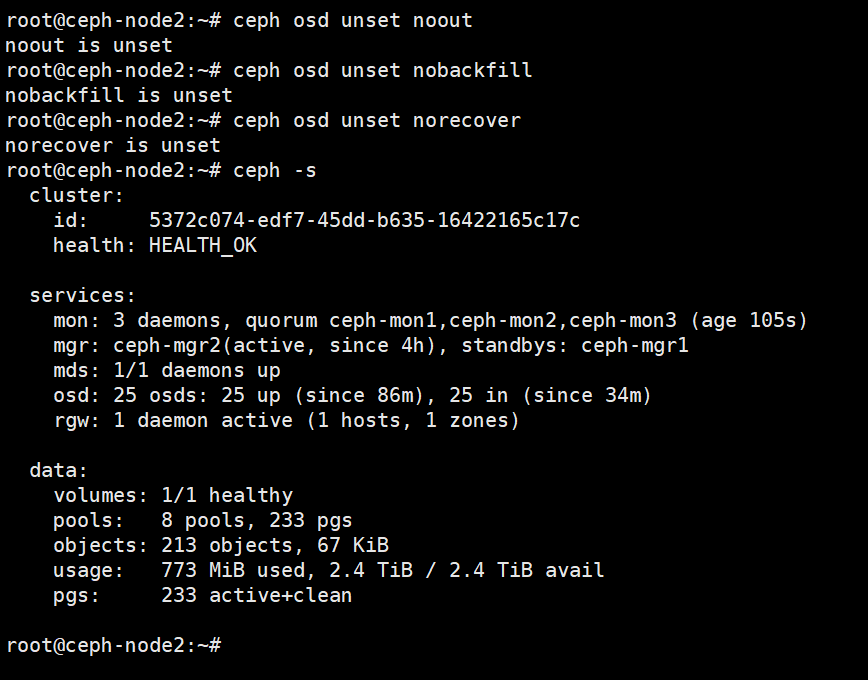
ceph集群服务停机关闭顺序
1、确保ceph集群当前为noout、nobackfill、norecover状态
2、关闭存储客户端停止读写数据
3、如果使用了 RGW,关闭 RGW
4、关闭 cephfs 元数据服务
5、关闭 ceph OSD
6、关闭 ceph manager
7、关闭 ceph monitor
ceph集群启动顺序
启动 ceph monitor
启动 ceph manager
启动 ceph OSD
关闭 cephfs 元数据服务
启动 RGW
启动存储客户端
启动服务后取消 noout-->ceph osd unset noout
添加节点服务器
0、查看当前ceph osd数量
当前osd数量为20个
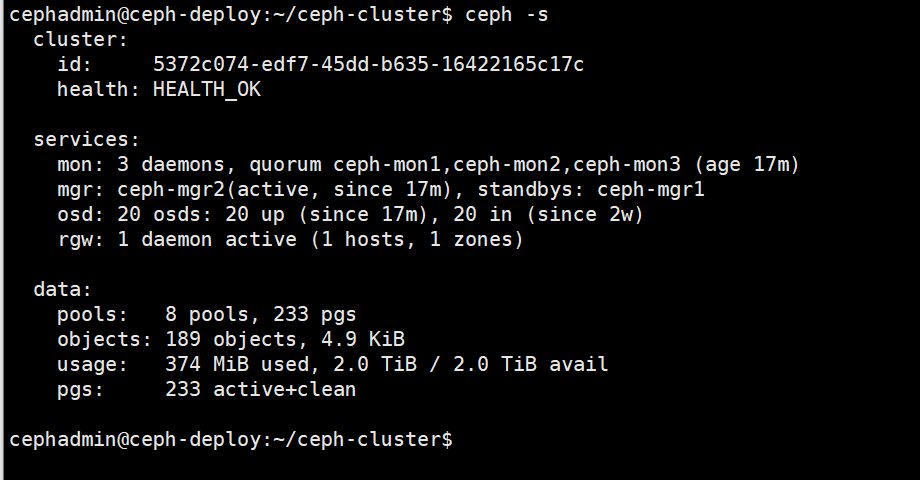
1、ceph-deploy 添加新节点 node5 的 hosts 主机名解析,并分发到所有ceph节点
root@ceph-deploy:~# vim /etc/hosts
172.16.100.40 ceph-deploy.example.local ceph-deploy
172.16.100.31 ceph-node1.example.local ceph-node1
172.16.100.32 ceph-node2.example.local ceph-node2
172.16.100.33 ceph-node3.example.local ceph-node3
172.16.100.34 ceph-node4.example.local ceph-node4
172.16.100.41 ceph-node5.example.local ceph-node5
172.16.100.35 ceph-mon1.example.local ceph-mon1
172.16.100.36 ceph-mon2.example.local ceph-mon2
172.16.100.37 ceph-mon3.example.local ceph-mon3
172.16.100.38 ceph-mgr1.example.local ceph-mgr1
172.16.100.39 ceph-mgr2.example.local ceph-mgr2
2、node05 添加仓库源
#支持 https 镜像仓库源:
root@ceph-node5:~# apt install -y apt-transport-https ca-certificates curl software-properties-common
#导入 key:
root@ceph-node5:~# wget -q -O- 'https://mirrors.tuna.tsinghua.edu.cn/ceph/keys/release.asc' | sudo apt-key add -
OK
#添加ceph 16.x pacific版本仓库地址
root@ceph-node5:~# apt-add-repository 'deb https://mirrors.tuna.tsinghua.edu.cn/ceph/debian-pacific/ bionic main'
#更新apt仓库
root@ceph-node5:~# apt update
3、node05节点安装 python2环境
root@ceph-node5:~# apt install python-pip配置pip加速
root@ceph-node1:~# mkdir .pip
root@ceph-node1:~# vim .pip/pip.conf
[global]
index-url = https://mirrors.aliyun.com/pypi/simple/
[install]
trusted-host=mirrors.aliyun.com
4、node5节点创建cephadmin用户
root@ceph-node5:~# groupadd -r -g 2022 cephadmin && useradd -r -m -s /bin/bash -u 2022 -g 2022 cephadmin && echo cephadmin:123456 | chpasswd添加cephadmin用户sudo权限
root@ceph-node5:~# echo "cephadmin ALL=(ALL) NOPASSWD: ALL" >> /etc/sudoers
5、配置 ceph-deploy 节点免秘钥登录 node5节点
cephadmin@ceph-deploy:~$ ssh-copy-id cephadmin@ceph-node5
/usr/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/home/cephadmin/.ssh/id_rsa.pub"
/usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
6、ceph-deploy添加node5到集群
cephadmin@ceph-deploy:~/ceph-cluster$ ceph-deploy install --no-adjust-repos --nogpgcheck ceph-node5
7、将admin秘钥推送到node5节点
cephadmin@ceph-deploy:~/ceph-cluster$ ceph-deploy admin ceph-node5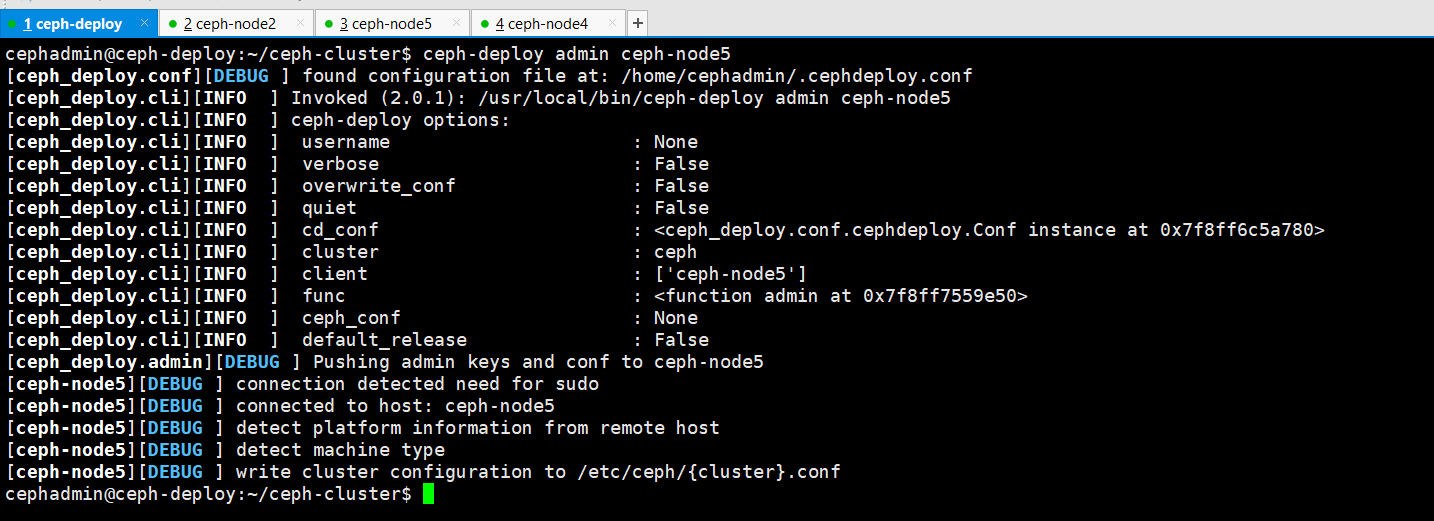
node5节点验证admin秘钥

8、为node5安装ceph基础运行环境
osd数据磁盘擦除前必须在node节点安装ceph运行环境
cephadmin@ceph-deploy:~/ceph-cluster$ ceph-deploy install --release pacific ceph-node5
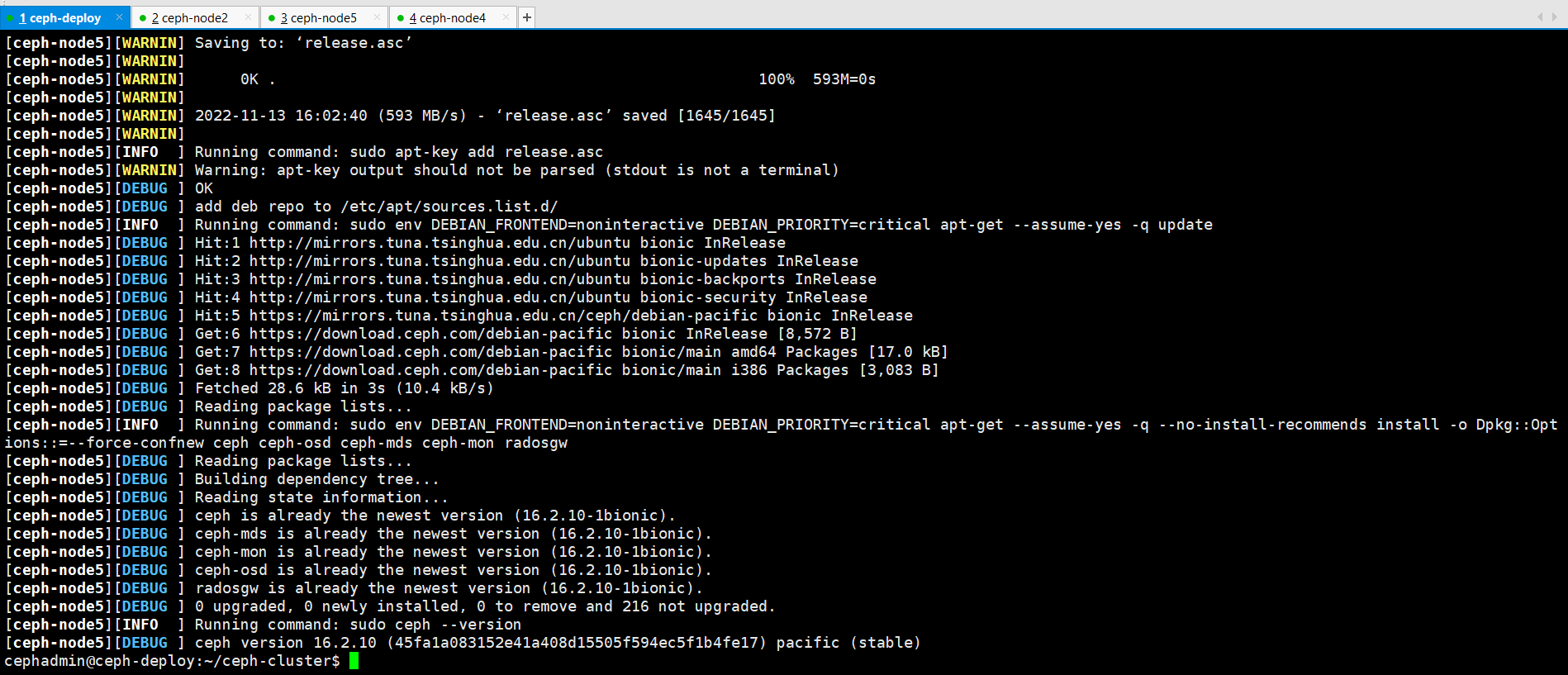
移除所有多余不可用的包组
root@ceph-node5:~# apt autoremove列出所有node5节点所有的数据磁盘
cephadmin@ceph-deploy:~/ceph-cluster$ ceph-deploy disk list ceph-node5
9、在deploy节点使用ceph-deploy disk zap 擦除各 ceph node 的 ceph 数据磁盘
擦除前确保已经在node5节点安装ceph运行环境!
cephadmin@ceph-deploy:~/ceph-cluster$ pwd
/home/cephadmin/ceph-cluster
cephadmin@ceph-deploy:~/ceph-cluster$ ceph-deploy disk zap ceph-node5 /dev/sdb
cephadmin@ceph-deploy:~/ceph-cluster$ ceph-deploy disk zap ceph-node5 /dev/sdc
cephadmin@ceph-deploy:~/ceph-cluster$ ceph-deploy disk zap ceph-node5 /dev/sdd
cephadmin@ceph-deploy:~/ceph-cluster$ ceph-deploy disk zap ceph-node5 /dev/sde
cephadmin@ceph-deploy:~/ceph-cluster$ ceph-deploy disk zap ceph-node5 /dev/sdf
10、将node5节点的数据盘创建ceph的osd
cephadmin@ceph-deploy:~/ceph-cluster$ pwd
/home/cephadmin/ceph-cluster
cephadmin@ceph-deploy:~/ceph-cluster$ ceph-deploy osd create ceph-node5 --data /dev/sdb
cephadmin@ceph-deploy:~/ceph-cluster$ ceph-deploy osd create ceph-node5 --data /dev/sdc
cephadmin@ceph-deploy:~/ceph-cluster$ ceph-deploy osd create ceph-node5 --data /dev/sdd
cephadmin@ceph-deploy:~/ceph-cluster$ ceph-deploy osd create ceph-node5 --data /dev/sde
cephadmin@ceph-deploy:~/ceph-cluster$ ceph-deploy osd create ceph-node5 --data /dev/sdf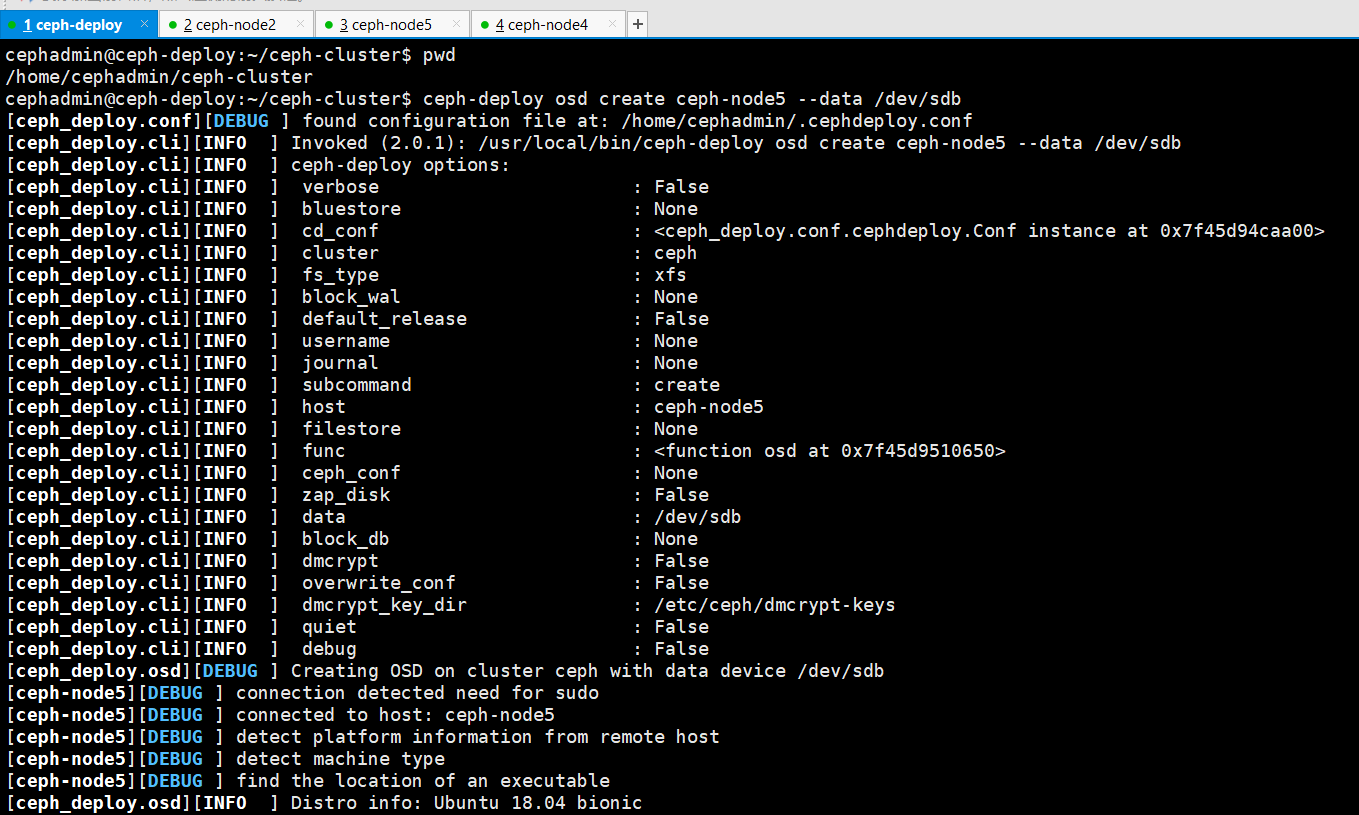

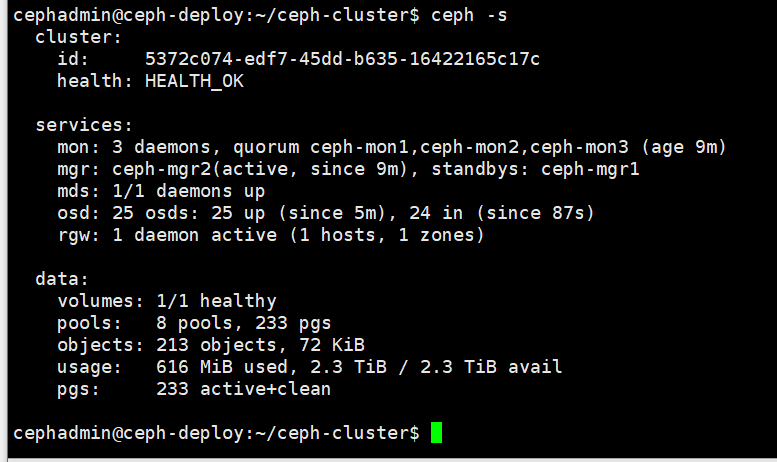
11、验证节点添加后的 osd 数量
添加新节点后的osd数量为25
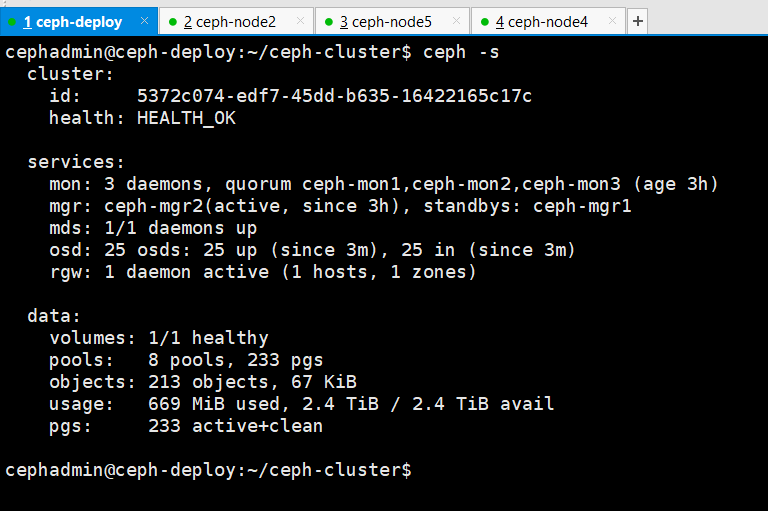
删除OSD
ceph和很多存储一样,增加磁盘(扩容)都比较方便,但要删除磁盘(缩容)会比较麻烦,但一般不会缩容
1、把故障的 OSD 从 ceph 集群删除
cephadmin@ceph-deploy:~/ceph-cluster$ ceph osd out 24
2、等待ceph数据修复

数据修复完成
3、停止改节点osd的进程
找到osd24对应的节点
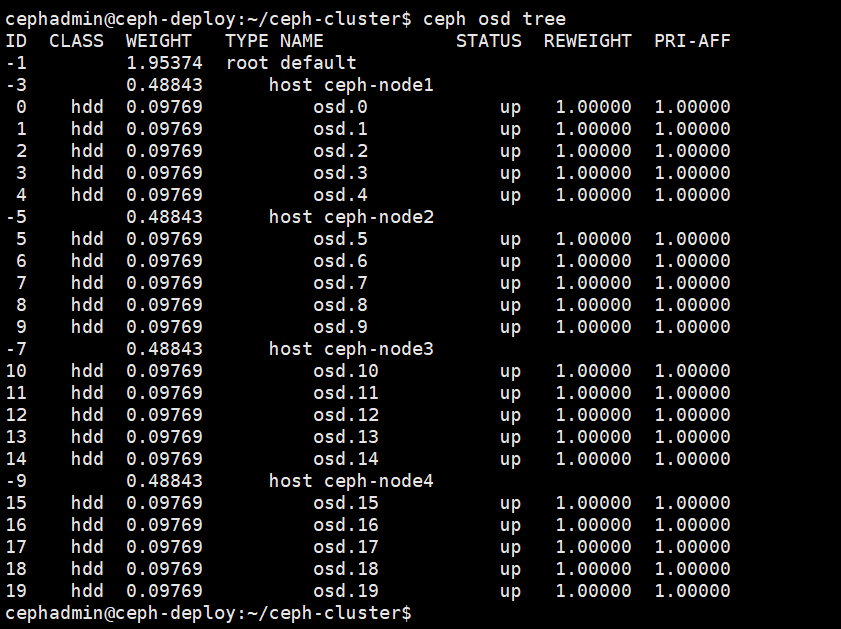
cephadmin@ceph-deploy:~/ceph-cluster$ ceph osd tree
找到对应osd24 service服务s
root@ceph-node5:~# systemctl status ceph-osd@24.service
停止osd24
root@ceph-node5:~# systemctl stop ceph-osd@24.service
root@ceph-node5:~# systemctl status ceph-osd@24.service
4、执行删除osd24
cephadmin@ceph-deploy:~/ceph-cluster$ ceph osd rm 24
removed osd.24
查看osd24状态

查看集群状态,可以发现有一条警告,没有在crush算法中删除

5、在crush算法中和auth验证中删除osd24
cephadmin@ceph-deploy:~/ceph-cluster$ ceph osd crush remove osd.24
removed item id 24 name 'osd.24' from crush map
cephadmin@ceph-deploy:~/ceph-cluster$ ceph auth del osd.24
updated
6、在osd.24对应的节点上卸载
root@ceph-node5:~# df -h|grep osd
tmpfs 482M 28K 482M 1% /var/lib/ceph/osd/ceph-22
tmpfs 482M 28K 482M 1% /var/lib/ceph/osd/ceph-20
tmpfs 482M 28K 482M 1% /var/lib/ceph/osd/ceph-21
tmpfs 482M 28K 482M 1% /var/lib/ceph/osd/ceph-24
tmpfs 482M 28K 482M 1% /var/lib/ceph/osd/ceph-23
root@ceph-node5:~# umount /var/lib/ceph/osd/ceph-24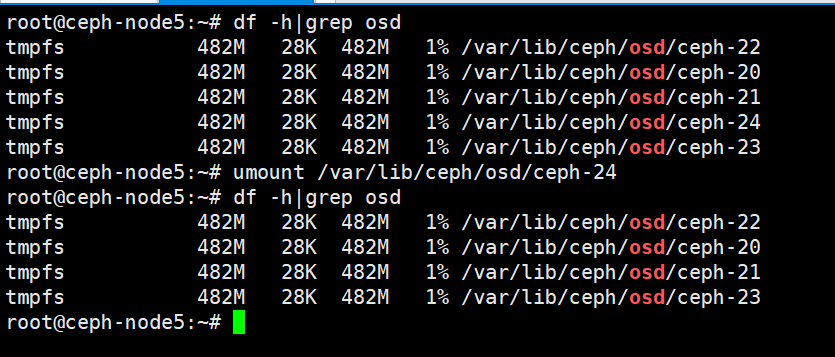
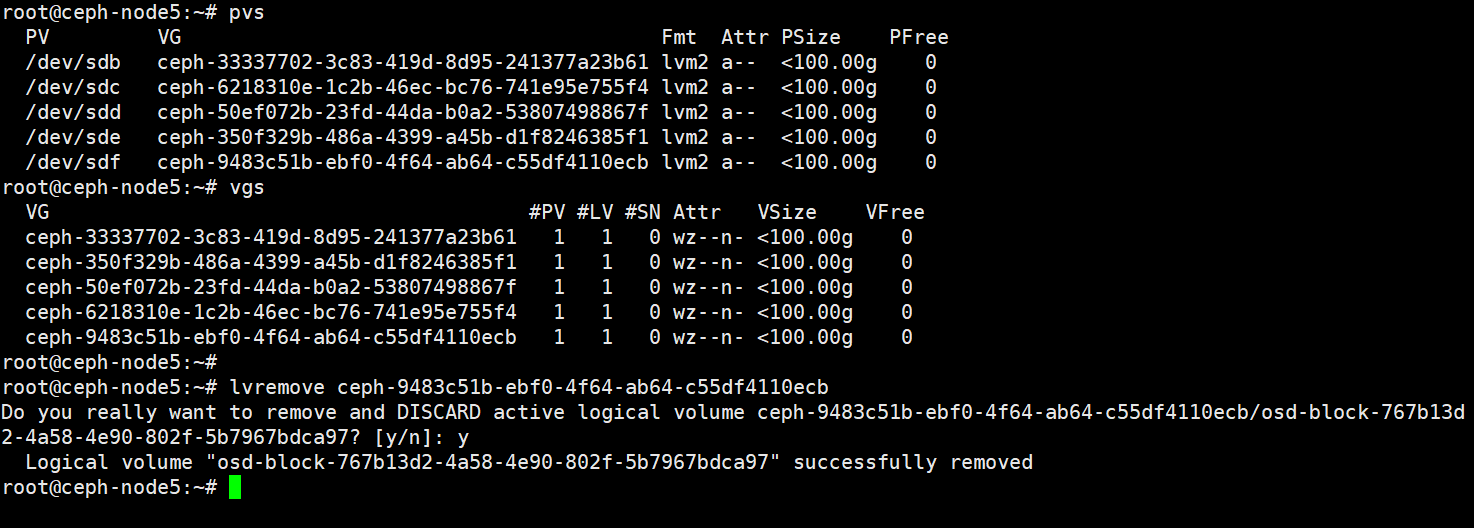
7、在osd.24对应的节点上删除osd磁盘产生的逻辑卷
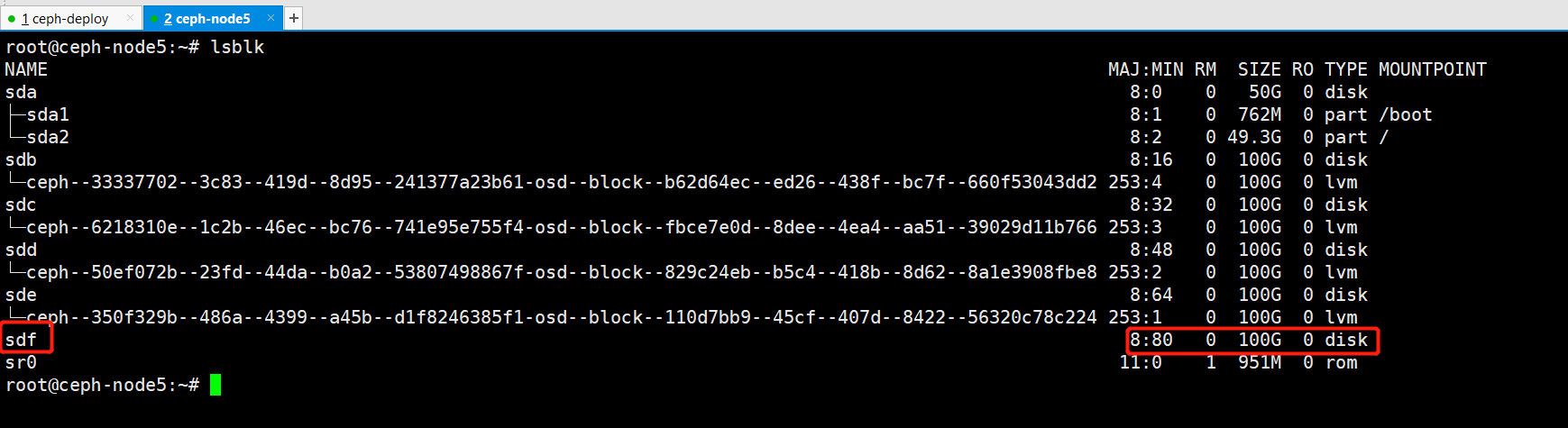
查找 OSD 对应的硬盘
假设osd.3磁盘损坏,则根据ceph osd tree定位osd所在节点,并根据块设备找到盘符

删除osd对应的逻辑卷
root@ceph-node5:~# pvs
PV VG Fmt Attr PSize PFree
/dev/sdb ceph-33337702-3c83-419d-8d95-241377a23b61 lvm2 a-- <100.00g 0
/dev/sdc ceph-6218310e-1c2b-46ec-bc76-741e95e755f4 lvm2 a-- <100.00g 0
/dev/sdd ceph-50ef072b-23fd-44da-b0a2-53807498867f lvm2 a-- <100.00g 0
/dev/sde ceph-350f329b-486a-4399-a45b-d1f8246385f1 lvm2 a-- <100.00g 0
/dev/sdf ceph-9483c51b-ebf0-4f64-ab64-c55df4110ecb lvm2 a-- <100.00g 0
root@ceph-node5:~# vgs
VG #PV #LV #SN Attr VSize VFree
ceph-33337702-3c83-419d-8d95-241377a23b61 1 1 0 wz--n- <100.00g 0
ceph-350f329b-486a-4399-a45b-d1f8246385f1 1 1 0 wz--n- <100.00g 0
ceph-50ef072b-23fd-44da-b0a2-53807498867f 1 1 0 wz--n- <100.00g 0
ceph-6218310e-1c2b-46ec-bc76-741e95e755f4 1 1 0 wz--n- <100.00g 0
ceph-9483c51b-ebf0-4f64-ab64-c55df4110ecb 1 1 0 wz--n- <100.00g 0
root@ceph-node5:~#
root@ceph-node5:~# lvremove ceph-9483c51b-ebf0-4f64-ab64-c55df4110ecb
Do you really want to remove and DISCARD active logical volume ceph-9483c51b-ebf0-4f64-ab64-c55df4110ecb/osd-block-767b13d2-4a58-4e90-802f-5b7967bdca97? [y/n]: y
Logical volume "osd-block-767b13d2-4a58-4e90-802f-5b7967bdca97" successfully removed
删除完成
删除服务器
删除服务器之前需要把服务器的osd停止并从集群中删除,建议依次将osd标记删除,不要所有同时操作
0、开启ceph集群禁止数据的修复
0、开启ceph集群禁止数据的修复
cephadmin@ceph-deploy:~/ceph-cluster$ ceph osd set nobackfill
nobackfill is set
cephadmin@ceph-deploy:~/ceph-cluster$ ceph osd set norecover
norecover is set
1、 查看节点osd
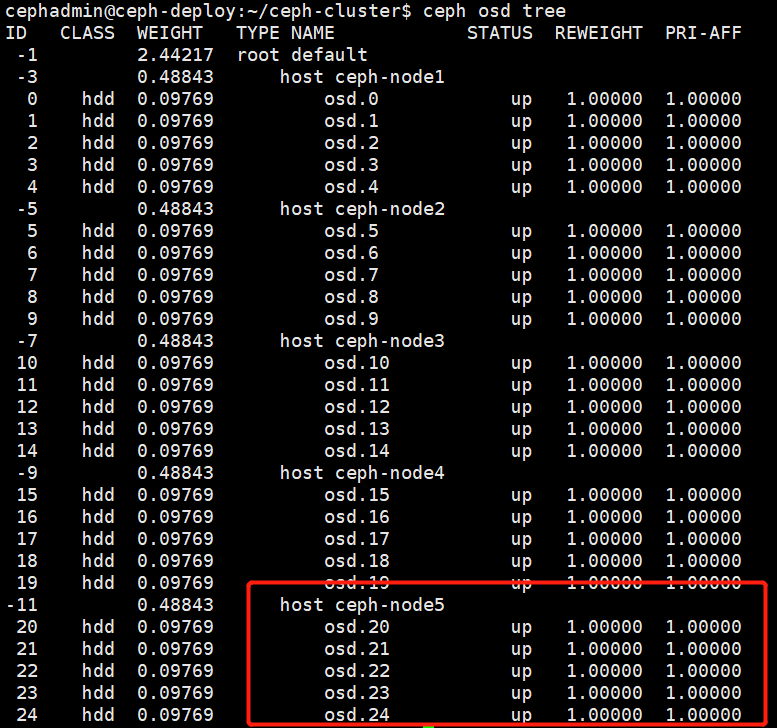
2、标记节点所有osd out
cephadmin@ceph-deploy:~/ceph-cluster$ ceph osd out 20
marked out osd.20.
3、停止osd服务
root@ceph-node5:~# systemctl stop ceph-osd@20.service
4、删除osd
cephadmin@ceph-deploy:~/ceph-cluster$ ceph osd rm 20
removed osd.20
5、在crush算法中和auth验证中删除osd20
cephadmin@ceph-deploy:~/ceph-cluster$ ceph osd crush remove osd.20
removed item id 20 name 'osd.20' from crush map
cephadmin@ceph-deploy:~/ceph-cluster$ ceph auth del osd.20
updated
6、查找节点服务器对应osd的挂载路径和逻辑卷路径
root@ceph-node5:~# df -h|grep osd
tmpfs 482M 28K 482M 1% /var/lib/ceph/osd/ceph-22
tmpfs 482M 28K 482M 1% /var/lib/ceph/osd/ceph-20
tmpfs 482M 28K 482M 1% /var/lib/ceph/osd/ceph-21
tmpfs 482M 28K 482M 1% /var/lib/ceph/osd/ceph-23
tmpfs 482M 68K 482M 1% /var/lib/ceph/osd/ceph-24
root@ceph-node5:~# ll /var/lib/ceph/osd/ceph-20/block
lrwxrwxrwx 1 ceph ceph 93 Nov 19 10:22 /var/lib/ceph/osd/ceph-20/block -> /dev/ceph-33337702-3c83-419d-8d95-241377a23b61/osd-block-b62d64ec-ed26-438f-bc7f-660f53043dd2
7、卸载osd
root@ceph-node5:~# umount /var/lib/ceph/osd/ceph-20
8、删除osd对应的逻辑卷
root@ceph-node5:~# pvs
PV VG Fmt Attr PSize PFree
/dev/sdb ceph-33337702-3c83-419d-8d95-241377a23b61 lvm2 a-- <100.00g 0
/dev/sdc ceph-6218310e-1c2b-46ec-bc76-741e95e755f4 lvm2 a-- <100.00g 0
/dev/sdd ceph-50ef072b-23fd-44da-b0a2-53807498867f lvm2 a-- <100.00g 0
/dev/sde ceph-350f329b-486a-4399-a45b-d1f8246385f1 lvm2 a-- <100.00g 0
/dev/sdf ceph-ee036335-403d-433e-8c95-f87ab1a134fc lvm2 a-- <100.00g 0
root@ceph-node5:~# vgs
VG #PV #LV #SN Attr VSize VFree
ceph-33337702-3c83-419d-8d95-241377a23b61 1 1 0 wz--n- <100.00g 0
ceph-350f329b-486a-4399-a45b-d1f8246385f1 1 1 0 wz--n- <100.00g 0
ceph-50ef072b-23fd-44da-b0a2-53807498867f 1 1 0 wz--n- <100.00g 0
ceph-6218310e-1c2b-46ec-bc76-741e95e755f4 1 1 0 wz--n- <100.00g 0
ceph-ee036335-403d-433e-8c95-f87ab1a134fc 1 1 0 wz--n- <100.00g 0
root@ceph-node5:~#
root@ceph-node5:~# lvremove ceph-33337702-3c83-419d-8d95-241377a23b61
Do you really want to remove and DISCARD active logical volume ceph-33337702-3c83-419d-8d95-241377a23b61/osd-block-b62d64ec-ed26-438f-bc7f-660f53043dd2? [y/n]: y
Logical volume "osd-block-b62d64ec-ed26-438f-bc7f-660f53043dd2" successfully removed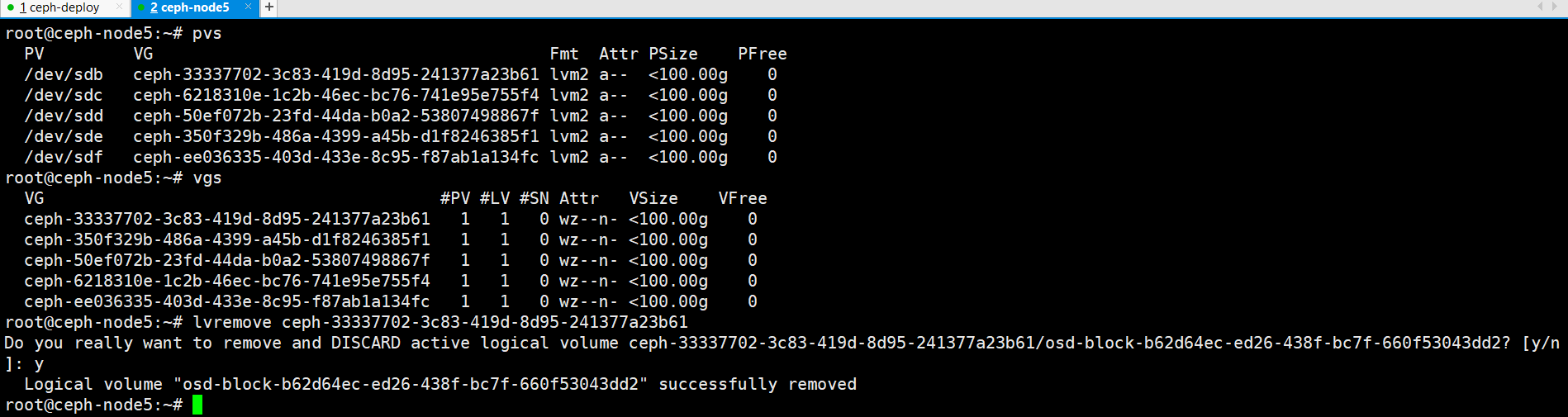
验证删除
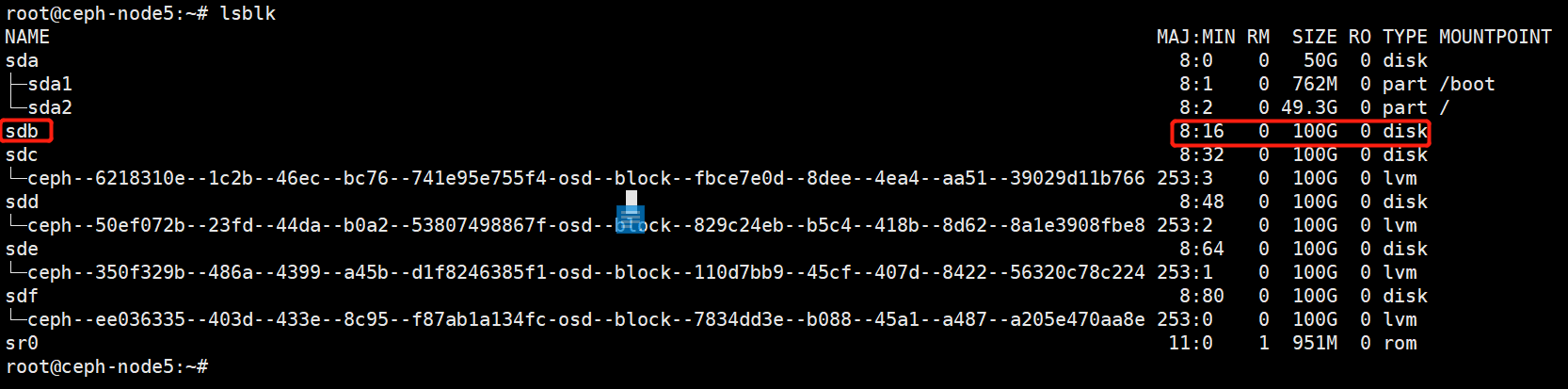
查看节点osd,验证osd20已经删除
root@ceph-node5:~# ceph osd tree
查看ceph状态,已经删除一个osd
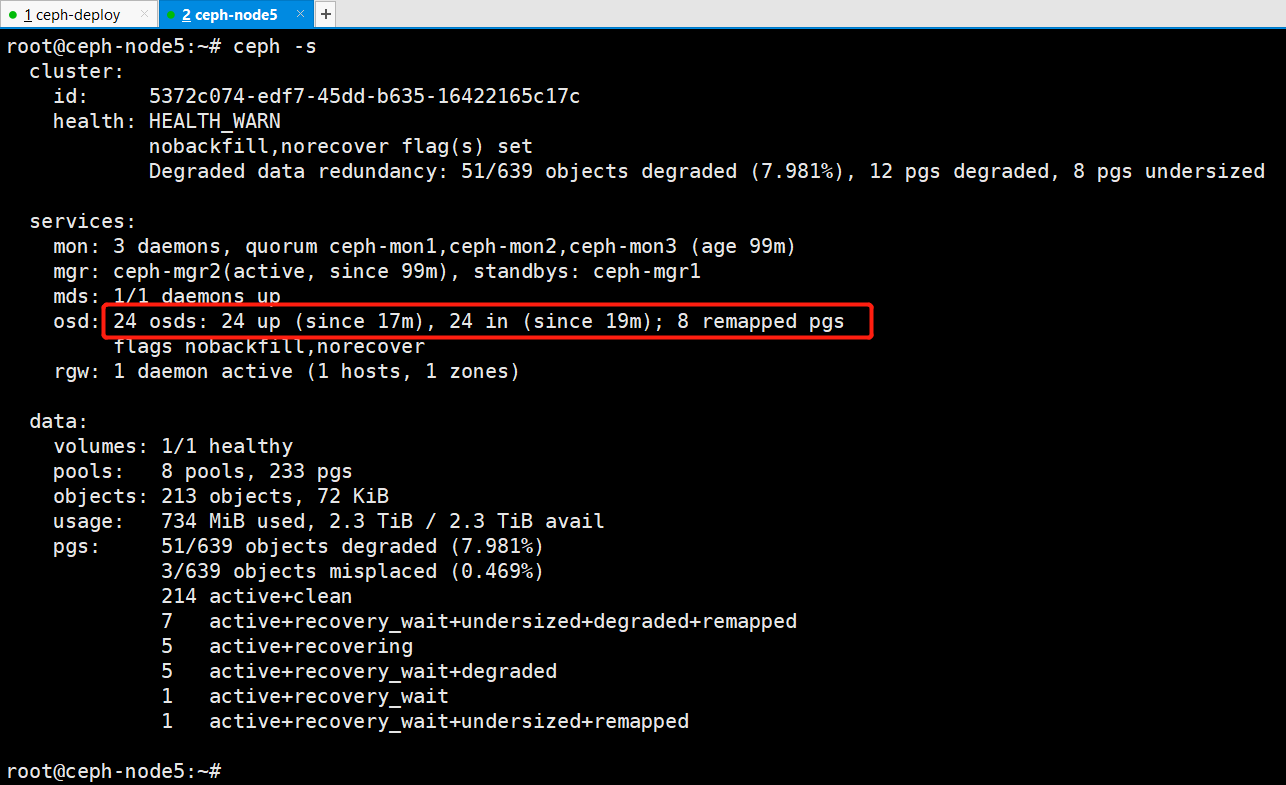
9、重复1-8步骤操作,依次将该节点上剩余osd一次卸载删除
10、从 crush 删除节点node5
cephadmin@ceph-deploy:~/ceph-cluster$ ceph osd crush rm ceph-node5
removed item id -11 name 'ceph-node5' from crush map
11、取消设置ceph的数据禁止修复
cephadmin@ceph-deploy:~/ceph-cluster$ ceph osd unset nobackfill
nobackfill is unset
cephadmin@ceph-deploy:~/ceph-cluster$ ceph osd unset norecover
norecover is unset
等待数据修复完成

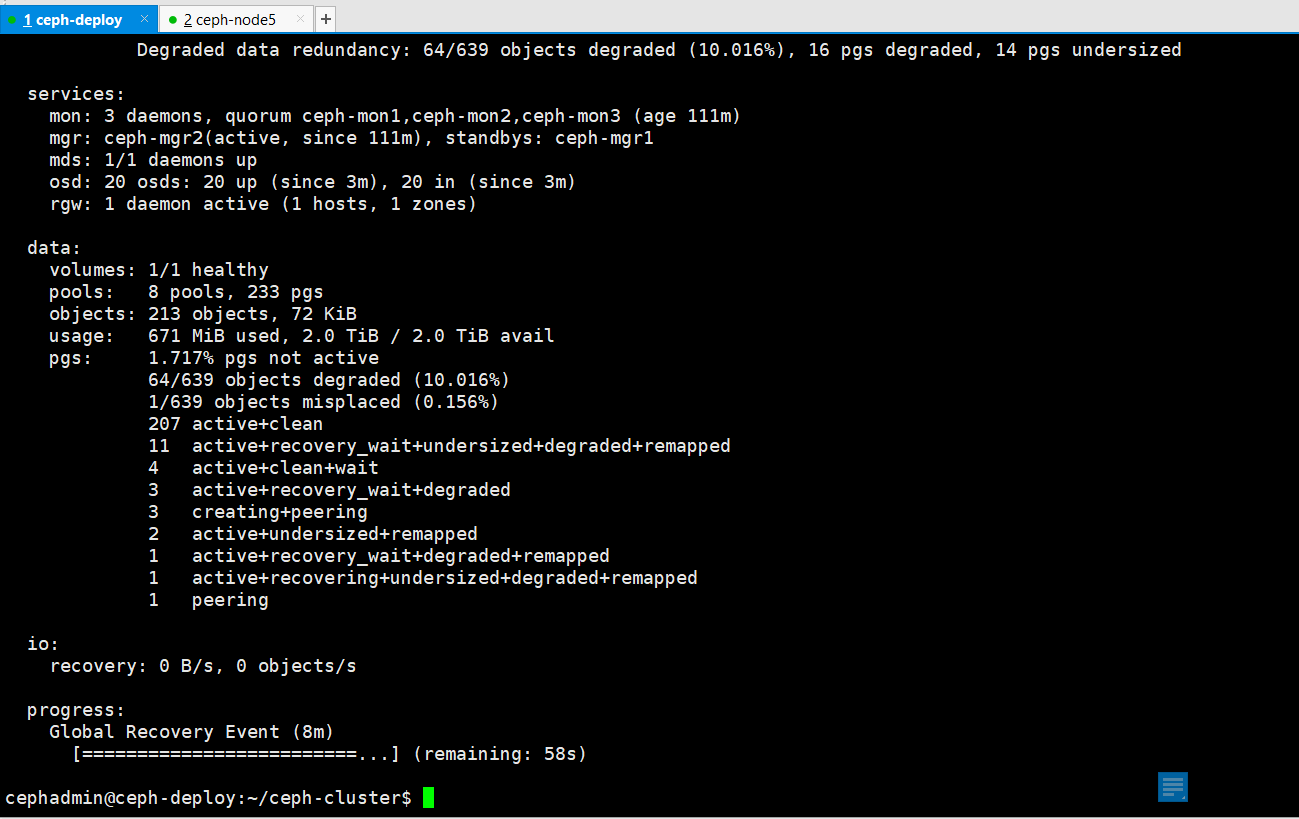
验证ceph状态

验证集群节点,已经删除ceph-node5节点
本文来自博客园,作者:PunchLinux,转载请注明原文链接:https://www.cnblogs.com/punchlinux/p/17061830.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号