ceph集群添加node节点及OSD
初始化 ceph 存储节点
初始化存储节点等于在存储节点安装了 ceph 及 ceph-rodsgw 安装包,但是使用默认的官方仓库会因为网络原因导致初始化超时,因此各存储节点推荐修改 ceph 仓库为阿里或者清华等国内的镜像源:
修改 ceph 镜像源
各节点配置清华的 ceph 镜像源:
CentOS
ceph-mimic 版本(13)
vim /etc/yum.repos.d/ceph.repo
[Ceph]
name=Ceph packages for $basearch
baseurl=https://mirrors.tuna.tsinghua.edu.cn/ceph/rpm-octopus/el7/$basearch
enabled=1
gpgcheck=1
type=rpm-md
gpgkey=https://mirrors.tuna.tsinghua.edu.cn/ceph/keys/release.asc
[Ceph-noarch]
name=Ceph noarch packages
baseurl=https://mirrors.tuna.tsinghua.edu.cn/ceph/rpm-octopus/el7/noarch
enabled=1
gpgcheck=1
type=rpm-md
gpgkey=https://mirrors.tuna.tsinghua.edu.cn/ceph/keys/release.asc
[ceph-source]
name=Ceph source packages
baseurl=https://mirrors.tuna.tsinghua.edu.cn/ceph/rpm-octopus/el7/SRPMS
enabled=1
gpgcheck=1
type=rpm-md
gpgkey=https://mirrors.tuna.tsinghua.edu.cn/ceph/keys/release.asc
ceph-nautilus 版本(14):
vim /etc/yum.repos.d/ceph.repo
[Ceph]
name=Ceph packages for $basearch
baseurl=https://mirrors.tuna.tsinghua.edu.cn/ceph/rpm-nautilus/el7/$basearch
enabled=1
gpgcheck=1
type=rpm-md
gpgkey=https://mirrors.tuna.tsinghua.edu.cn/ceph/keys/release.asc
[Ceph-noarch]
name=Ceph noarch packages
baseurl=https://mirrors.tuna.tsinghua.edu.cn/ceph/rpm-nautilus/el7/noarch
enabled=1
gpgcheck=1
type=rpm-md
gpgkey=https://mirrors.tuna.tsinghua.edu.cn/ceph/keys/release.asc
[ceph-source]
name=Ceph source packages
baseurl=https://mirrors.tuna.tsinghua.edu.cn/ceph/rpm-nautilus/el7/SRPMS
enabled=1
gpgcheck=1
type=rpm-md
gpgkey=https://mirrors.tuna.tsinghua.edu.cn/ceph/keys/release.asc
修改 epel 镜像源:
https://mirrors.tuna.tsinghua.edu.cn/help/epel/
yum install epel-release -y
sed -e 's!^metalink=!#metalink=!g' \
-e 's!^#baseurl=!baseurl=!g' \
-e 's!//download\.fedoraproject\.org/pub!//mirrors.tuna.tsinghua.edu.cn!g' \
-e 's!http://mirrors\.tuna!https://mirrors.tuna!g' \
-i /etc/yum.repos.d/epel.repo /etc/yum.repos.d/epel-testing.repo
yum makecache fast
Ubuntu
Ubuntu 18.04:
ceph-octopus 版本(15):
cat /etc/apt/sources.list
deb https://mirrors.tuna.tsinghua.edu.cn/ceph/debian-octopus bionic main
Ubuntu 18.04:
ceph-pacific 版本(16):
cat /etc/apt/sources.list
deb https://mirrors.tuna.tsinghua.edu.cn/ceph/debian-pacific bionic main
初始化node存储节点
ceph-deploy节点上执行,此步骤必须执行,否 ceph 集群的后续安装步骤会报错
cephadmin@ceph-deploy:~/ceph-cluster$ pwd
/home/cephadmin/ceph-cluster
cephadmin@ceph-deploy:~/ceph-cluster$ ceph-deploy install --no-adjust-repos --nogpgcheck ceph-node1 ceph-node2 ceph-node3
--no-adjust-repos #不修改已有的 apt 仓库源(默认会使用官方仓库)
--nogpgcheck #不进行校验多个节点之间使用空格间隔
也可以单独添加一个node节点
cephadmin@ceph-deploy:~/ceph-cluster$ ceph-deploy install --no-adjust-repos --nogpgcheck ceph-node4
初始化完成
此过程会在指定的ceph node节点按照串行的方式逐个服务器安装 ceph-base ceph-common 等组件包
node节点部署ceph运行环境
在ceph-deploy部署节点执行
1、OSD 节点安装运行环境:
cephadmin@ceph-deploy:~/ceph-cluster$ ceph-deploy install --release pacific ceph-node1 ceph-node2 ceph-node3 ceph-node4
#擦除磁盘之前通过 deploy 节点对 node 节点执行安装 ceph 基本运行环境
2、移除node存储节点不可用的包,所有node节点执行
root@ceph-node1:~# apt autoremove
3、列出 ceph node 节点可用磁盘:
cephadmin@ceph-deploy:~/ceph-cluster$ ceph-deploy disk list ceph-node1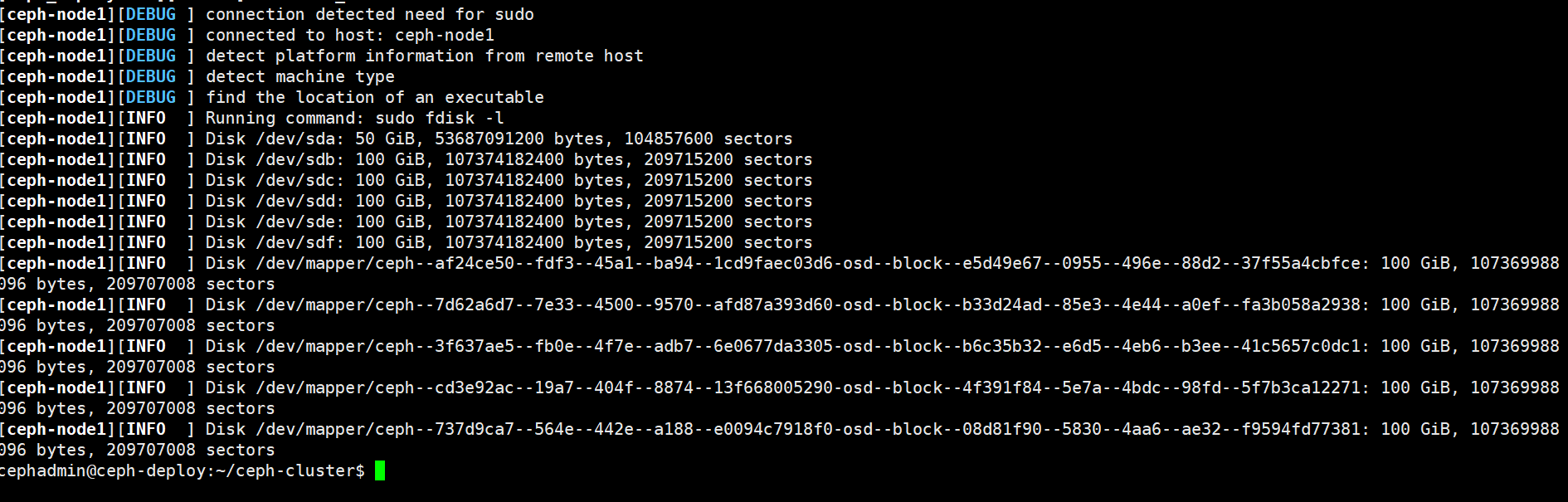
也可以到node节点上验证磁盘
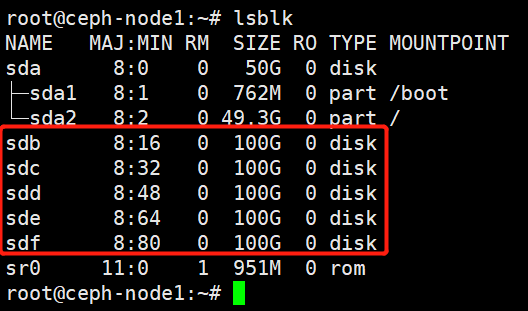
4、使用 ceph-deploy disk zap 擦除各 ceph node 的 ceph 数据磁盘:
ceph-node1 ceph-node2 ceph-node3 ceph-node4 的存储节点磁盘擦除过程如下:
ceph-deploy部署节点执行
ceph-deploy disk zap ceph-node1 /dev/sdb
ceph-deploy disk zap ceph-node1 /dev/sdc
ceph-deploy disk zap ceph-node1 /dev/sdd
ceph-deploy disk zap ceph-node1 /dev/sde
ceph-deploy disk zap ceph-node1 /dev/sdf
ceph-deploy disk zap ceph-node2 /dev/sdb
ceph-deploy disk zap ceph-node2 /dev/sdc
ceph-deploy disk zap ceph-node2 /dev/sdd
ceph-deploy disk zap ceph-node2 /dev/sde
ceph-deploy disk zap ceph-node2 /dev/sdf
ceph-deploy disk zap ceph-node3 /dev/sdb
ceph-deploy disk zap ceph-node3 /dev/sdc
ceph-deploy disk zap ceph-node3 /dev/sdd
ceph-deploy disk zap ceph-node3 /dev/sde
ceph-deploy disk zap ceph-node3 /dev/sdf
ceph-deploy disk zap ceph-node4 /dev/sdb
ceph-deploy disk zap ceph-node4 /dev/sdc
ceph-deploy disk zap ceph-node4 /dev/sdd
ceph-deploy disk zap ceph-node4 /dev/sde
ceph-deploy disk zap ceph-node4 /dev/sdf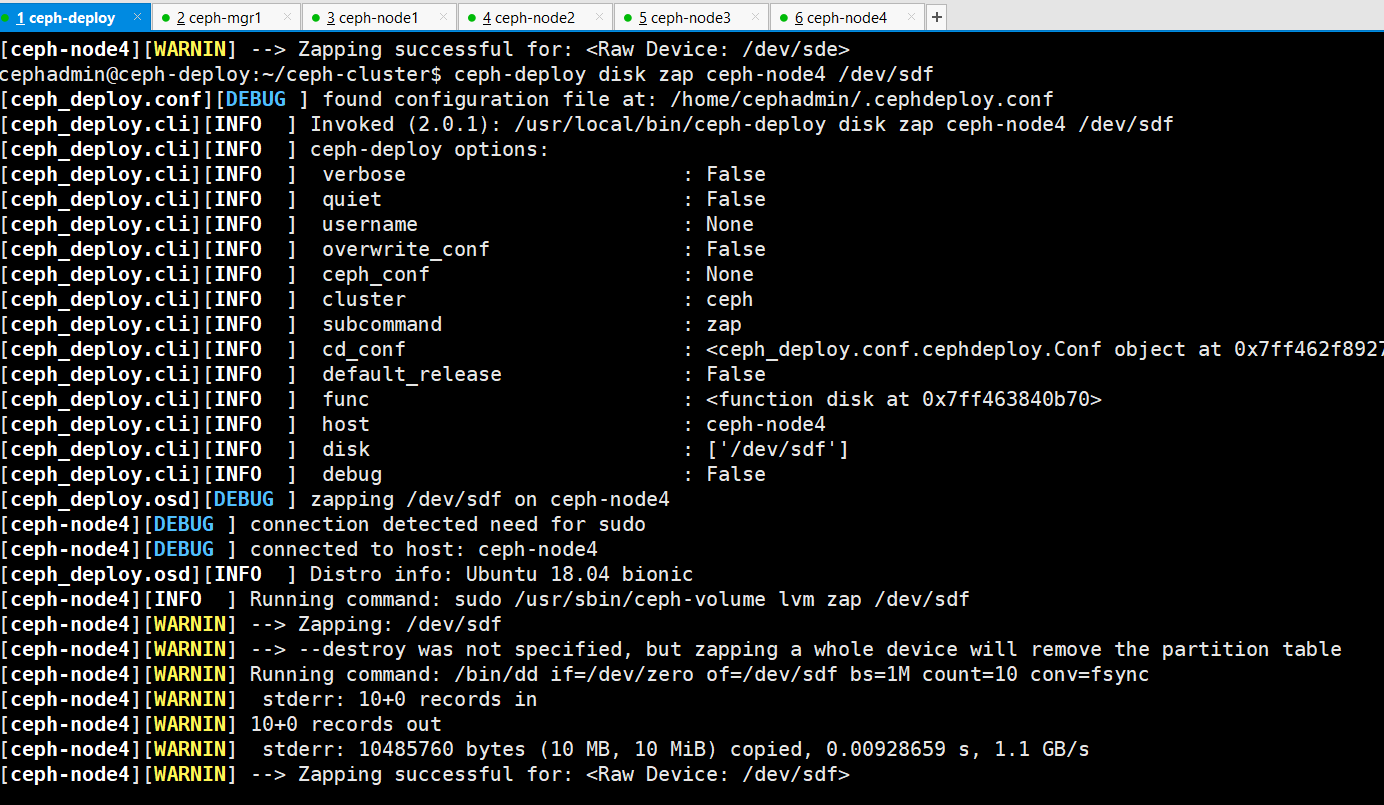
配置 OSD
数据分类保存方式
Data:即 ceph 保存的对象数据
Block: rocks DB 数据即元数据
block-wal:数据库的 wal 日志
单块磁盘:
- 机械硬盘或者SSD:
- data:即ceph保存的对象数据
- block:rocks DB数据即元数据
- block-wal:数据库的wal日志
两块磁盘:
- SSD:
- block:rocks DB数据即元数据
- block-wal:数据库的wal日志
- 机械硬盘
- data:即ceph保存的对象数据
三块硬盘:
- NVME:
- block:rocks DB数据即元数据
- SSD:
- block-wal:数据库的wal日志
- 机械硬盘:
- data:即ceph保存的对象数据
添加 OSD
ceph-deploy osd使用帮助
/path/to/data /path/to-device /path/to-wal-device 分别表示三种不同类型的块设备路径。如:HDD、SDD、NVME-SDD
cephadmin@ceph-deploy:~$ ceph-deploy osd --help
usage: ceph-deploy osd [-h] {list,create} ...
Create OSDs from a data disk on a remote host:
ceph-deploy osd create {node} --data /path/to/device
For bluestore, optional devices can be used::
ceph-deploy osd create {node} --data /path/to/data --block-db /path/to/db-device
ceph-deploy osd create {node} --data /path/to/data --block-wal /path/to/wal-device
ceph-deploy osd create {node} --data /path/to/data --block-db /path/to/db-device --block-wal /path/to/wal-device
For filestore, the journal must be specified, as well as the objectstore::
ceph-deploy osd create {node} --filestore --data /path/to/data --journal /path/to/journal
#使用filestor的数据和文件系统的日志的路径,journal是 systemd 的一个组件,用于捕获系统日志信息、内核日志信息、磁盘的日志信息等,
#--journal指定 ssd磁盘路径作为数据的缓存写入,可以加速数据的读写,--data指定hdd的osd数据写入路径。如果指定了--journal,那么先将数据先写入到ssd,然后再刷入到--data hdd磁盘中去。
For data devices, it can be an existing logical volume in the format of:
vg/lv, or a device. For other OSD components like wal, db, and journal, it
can be logical volume (in vg/lv format) or it must be a GPT partition.
positional arguments:
{list,create}
list List OSD info from remote host(s)
create Create new Ceph OSD daemon by preparing and activating a
device
optional arguments:
-h, --help show this help message and exit
创建osd
cephadmin@ceph-deploy:~/ceph-cluster$ pwd
/home/cephadmin/ceph-cluster
cephadmin@ceph-deploy:~/ceph-cluster$ ceph-deploy osd create ceph-node1 --data /dev/sdb
cephadmin@ceph-deploy:~/ceph-cluster$ ceph-deploy osd create ceph-node1 --data /dev/sdc
cephadmin@ceph-deploy:~/ceph-cluster$ ceph-deploy osd create ceph-node1 --data /dev/sdd
cephadmin@ceph-deploy:~/ceph-cluster$ ceph-deploy osd create ceph-node1 --data /dev/sde
cephadmin@ceph-deploy:~/ceph-cluster$ ceph-deploy osd create ceph-node1 --data /dev/sdf
cephadmin@ceph-deploy:~/ceph-cluster$ ceph-deploy osd create ceph-node2 --data /dev/sdb
cephadmin@ceph-deploy:~/ceph-cluster$ ceph-deploy osd create ceph-node2 --data /dev/sdc
cephadmin@ceph-deploy:~/ceph-cluster$ ceph-deploy osd create ceph-node2 --data /dev/sdd
cephadmin@ceph-deploy:~/ceph-cluster$ ceph-deploy osd create ceph-node2 --data /dev/sde
cephadmin@ceph-deploy:~/ceph-cluster$ ceph-deploy osd create ceph-node2 --data /dev/sdf
cephadmin@ceph-deploy:~/ceph-cluster$ ceph-deploy osd create ceph-node3 --data /dev/sdb
cephadmin@ceph-deploy:~/ceph-cluster$ ceph-deploy osd create ceph-node3 --data /dev/sdc
cephadmin@ceph-deploy:~/ceph-cluster$ ceph-deploy osd create ceph-node3 --data /dev/sdd
cephadmin@ceph-deploy:~/ceph-cluster$ ceph-deploy osd create ceph-node3 --data /dev/sde
cephadmin@ceph-deploy:~/ceph-cluster$ ceph-deploy osd create ceph-node3 --data /dev/sdf
cephadmin@ceph-deploy:~/ceph-cluster$ ceph-deploy osd create ceph-node4 --data /dev/sdb
cephadmin@ceph-deploy:~/ceph-cluster$ ceph-deploy osd create ceph-node4 --data /dev/sdc
cephadmin@ceph-deploy:~/ceph-cluster$ ceph-deploy osd create ceph-node4 --data /dev/sdd
cephadmin@ceph-deploy:~/ceph-cluster$ ceph-deploy osd create ceph-node4 --data /dev/sde
cephadmin@ceph-deploy:~/ceph-cluster$ ceph-deploy osd create ceph-node4 --data /dev/sdf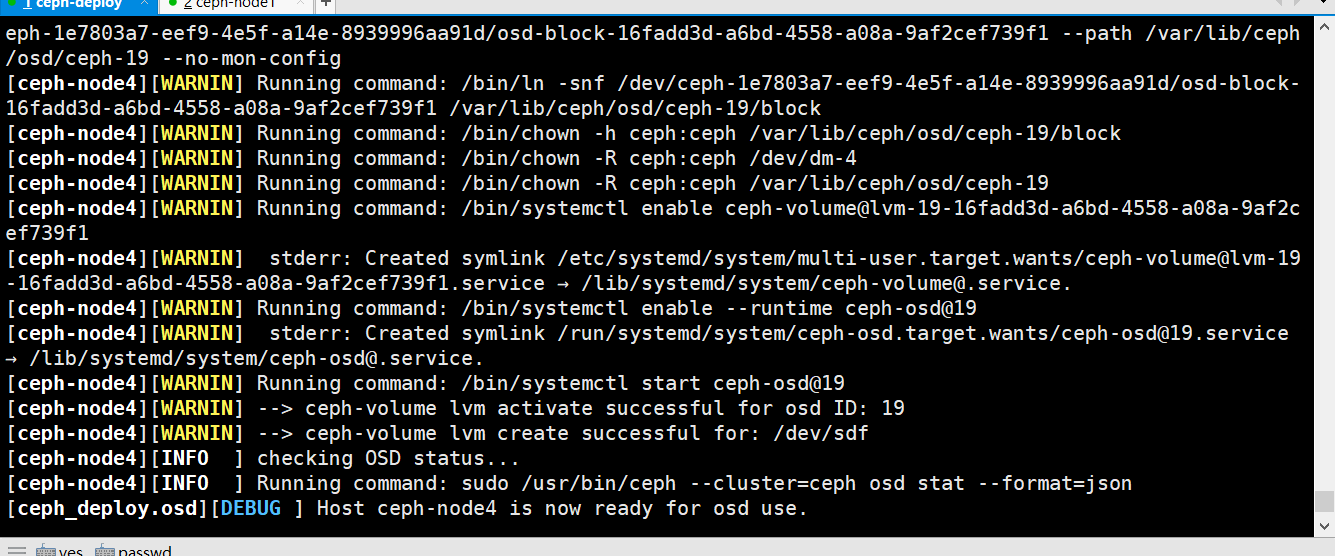
检查ceph集群状态
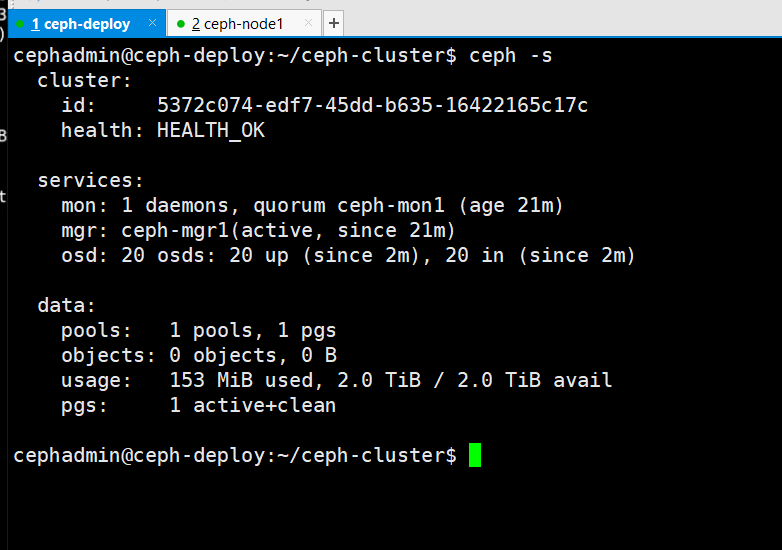
设置 OSD 服务自启动
默认就已经为自启动, node 节点添加完成后,可以重启服务器测试 node 服务器重启后,OSD是否会自动启动。
验证ceph-osd服务进程
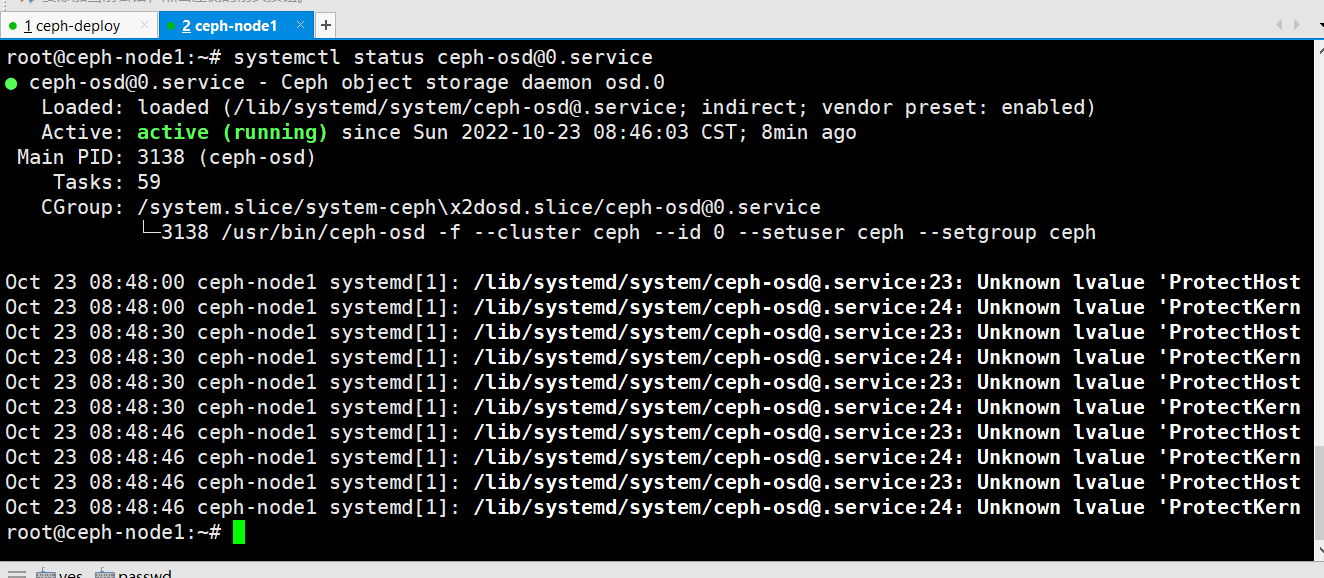
从 RADOS 移除 OSD
Ceph 集群中的一个 OSD 是一个 node 节点的服务进程且对应于一个物理磁盘设备,是一个专用的守护进程。在某 OSD 设备出现故障,或管理员出于管理之需确实要移除特定的 OSD设备时,需要先停止相关的守护进程,而后再进行移除操作。对于 Luminous 及其之后的版本来说,停止和移除命令的格式分别如下所示:
1、停用设备:
ceph osd out {osd-num}
2、停止进程:
sudo systemctl stop ceph-osd@{osd-num}
3、移除设备:
ceph osd purge {id} --yes-i-really-mean-it
若类似如下的 OSD 的配置信息存在于 ceph.conf 配置文件中,管理员在删除 OSD 之后手动将其删除。
不过,对于 Luminous 之前的版本来说,管理员需要依次手动执行如下步骤删除 OSD 设备:
1、于 CRUSH 运行图中移除设备:
ceph osd crush remove {name}
2、移除 OSD 的认证 key:
ceph auth del osd.{osd-num}
3、最后移除 OSD 设备:
ceph osd rm {osd-num}
测试上传与下载数据
存取数据时,客户端必须首先连接至 RADOS 集群上某存储池,然后根据对象名称由相关的CRUSH 规则完成数据对象寻址。于是,为了测试集群的数据存取功能,这里首先创建一个用于测试的存储池 mypool,并设定其 PG 数量为 32 个。
- PG是指定存储池存储对象的目录有多少个,PGP是存储池PG的OSD分布组合个数
- PG的增加会引起PG内的数据进行分裂,分裂到相同的OSD上新生成的PG当中
- PGP的增加会引起部分PG的分布进行变化,但是不会引起PG内对象的变动
cephadmin@ceph-deploy:~/ceph-cluster$ ceph -h #一个更底层的客户端命令
cephadmin@ceph-deploy:~/ceph-cluster$ rados -h #客户端命令
创建 pool:
cephadmin@ceph-deploy:~/ceph-cluster$ ceph osd pool create mypool 32 32 #32PG 和32PGP
pool 'mypool' created
查看创建的存储池
cephadmin@ceph-deploy:~/ceph-cluster$ ceph osd pool ls
device_health_metrics
mypool
cephadmin@ceph-deploy:~/ceph-cluster$ rados lspools
device_health_metrics
mypool
查看pg
cephadmin@ceph-deploy:~/ceph-cluster$ ceph pg ls-by-pool mypool|awk '{print $1,$2,$15}' #验证 PG 与 PGP 组合
PG OBJECTS ACTING
2.0 0 [8,10,3]p8
2.1 0 [15,0,13]p15
2.2 0 [5,1,15]p5
2.3 0 [17,5,14]p17
2.4 0 [1,12,18]p1
2.5 0 [12,4,8]p12
2.6 0 [1,13,19]p1
2.7 0 [6,17,2]p6
2.8 0 [16,13,0]p16
2.9 0 [4,9,19]p4
2.a 0 [11,4,18]p11
2.b 0 [13,7,17]p13
2.c 0 [12,0,5]p12
2.d 0 [12,19,3]p12
2.e 0 [2,13,19]p2
2.f 0 [11,17,8]p11
2.10 0 [15,13,0]p15
2.11 0 [16,6,1]p16
2.12 0 [10,3,9]p10
2.13 0 [17,6,3]p17
2.14 0 [8,13,17]p8
2.15 0 [19,1,11]p19
2.16 0 [8,12,17]p8
2.17 0 [6,14,2]p6
2.18 0 [18,9,12]p18
2.19 0 [3,6,13]p3
2.1a 0 [6,14,2]p6
2.1b 0 [11,7,17]p11
2.1c 0 [10,7,1]p10
2.1d 0 [15,10,7]p15
2.1e 0 [3,13,15]p3
2.1f 0 [4,7,14]p4
当前的 ceph 环境还没还没有部署使用块存储和文件系统使用 ceph,也没有使用对象存储的客户端,但是 ceph 的 rados 命令可以实现访问 ceph 对象存储的功能
上传文件
cephadmin@ceph-deploy:~/ceph-cluster$ sudo rados put msg1 /var/log/syslog --pool=mypool #把 syslog 文件上传到 mypool 并指定对象 id 为 msg1
列出文件:
cephadmin@ceph-deploy:~/ceph-cluster$ rados ls --pool=mypool
msg1
文件信息:
ceph osd map 命令可以获取到存储池中数据对象的具体位置信息:
cephadmin@ceph-deploy:~/ceph-cluster$ ceph osd map mypool msg1
osdmap e115 pool 'mypool' (2) object 'msg1' -> pg 2.c833d430 (2.10) -> up ([15,13,0], p15) acting ([15,13,0], p15)表示文件放在了存储池 id 为2的 c833d430 的 PG 上,10 为当前 PG 的 id, 2.10 表示数据是在 id 为 2 的存储池当中 id 为 10 的 PG 中存储,在线的 OSD 编号 15,13,0,主 OSD 为 15,活动的 OSD 15,13,10,三个 OSD 表示数据放一共 3 个副本,PG 中的 OSD 是 ceph 的 crush 算法计算出三份数据保存在哪些 OSD。
下载文件:
cephadmin@ceph-deploy:~/ceph-cluster$ sudo rados get msg1 --pool=mypool /opt/my.txt
cephadmin@ceph-deploy:~/ceph-cluster$ ll /opt/my.txt
-rw-r--r-- 1 root root 1606105 Oct 23 10:45 /opt/my.txt
修改文件:
cephadmin@ceph-deploy:~/ceph-cluster$ sudo rados put msg1 /etc/passwd --pool=mypool
cephadmin@ceph-deploy:~/ceph-cluster$ sudo rados get ms
g1 --pool=mypool /opt/2.txt
cephadmin@ceph-deploy:~/ceph-cluster$ tail /opt/2.txt
_apt:x:104:65534::/nonexistent:/usr/sbin/nologin
lxd:x:105:65534::/var/lib/lxd/:/bin/false
uuidd:x:106:110::/run/uuidd:/usr/sbin/nologin
dnsmasq:x:107:65534:dnsmasq,,,:/var/lib/misc:/usr/sbin/nologin
landscape:x:108:112::/var/lib/landscape:/usr/sbin/nologin
sshd:x:109:65534::/run/sshd:/usr/sbin/nologin
pollinate:x:110:1::/var/cache/pollinate:/bin/false
lxh:x:1000:1000:lxh,,,:/home/lxh:/bin/bash
cephadmin:x:2022:2022::/home/cephadmin:/bin/bash
ceph:x:64045:64045:Ceph storage service:/var/lib/ceph:/usr/sbin/nologin
删除文件:
cephadmin@ceph-deploy:~/ceph-cluster$ sudo rados rm msg1 --pool=mypool
cephadmin@ceph-deploy:~/ceph-cluster$ rados ls --pool=mypool本文来自博客园,作者:PunchLinux,转载请注明原文链接:https://www.cnblogs.com/punchlinux/p/17053827.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号