prometheus服务发现
服务发现的类型介绍
prometheus默认是采用pull方式拉取监控数据的,也就是定时去目标主机上抓取metrics数据,每一个被抓取的目标需要暴露一个HTTP接口,prometheus通过这个暴露的接口就可以获取到相应的指标数据,这种方式需要由目标服务决定采集的目标有哪些,通过配置在scrape_configs中的各种job来实现,无法动态感知新服务,如果后面增加了节点或者组件信息,就得手动修改promrtheus配置,并重启promethues,很不方便,所以出现了动态服务发现,动态服务发现能够自动发现集群中的新端点,并加入到配置中,通过服务发现,Prometheus能查询到需要监控的Target列表,然后轮询这些Target获取监控数据。
prometheus获取数据源target的方式有多种,如静态配置和动态服务发现配置,prometheus目前支持的服务发现有很多种,常用的主要分为以下几种:
https://prometheus.io/docs/prometheus/latest/configuration/configuration/#configuration-file
kubernetes_sd_configs: #基于 Kubernetes API实现的服务发现,让prometheus动态发现kubernetes中被监控的目标
static_configs: #静态服务发现,基于prometheus配置文件指定的监控目标
dns_sd_configs: #DNS服务发现监控目标
consul_sd_configs: #Consul服务发现,基于consul服务动态发现监控目标
file_sd_configs: #基于指定的文件实现服务发现,基于指定的文件发现监控目标
promethues的静态服务发现static_configs:每当有一个新的目标实例需要监控,都需要手动修改配置文件配置目标target。
promethues的consul服务发现consul_sd_configs:Prometheus一直监视consul服务,当发现在consul中注册的服务有变化,prometheus就会自动监控到所有注册到 consul中的目标资源
promethues的k8s服务发现kubernetes_sd_configs:Prometheus与Kubernetes的API进行交互,动态的发现Kubernetes中部署的所有可监控的目标资源。
relabeling标签重写与kubernetes_sd_configs
https://prometheus.io/docs/prometheus/latest/configuration/configuration/#kubernetes_sd_config
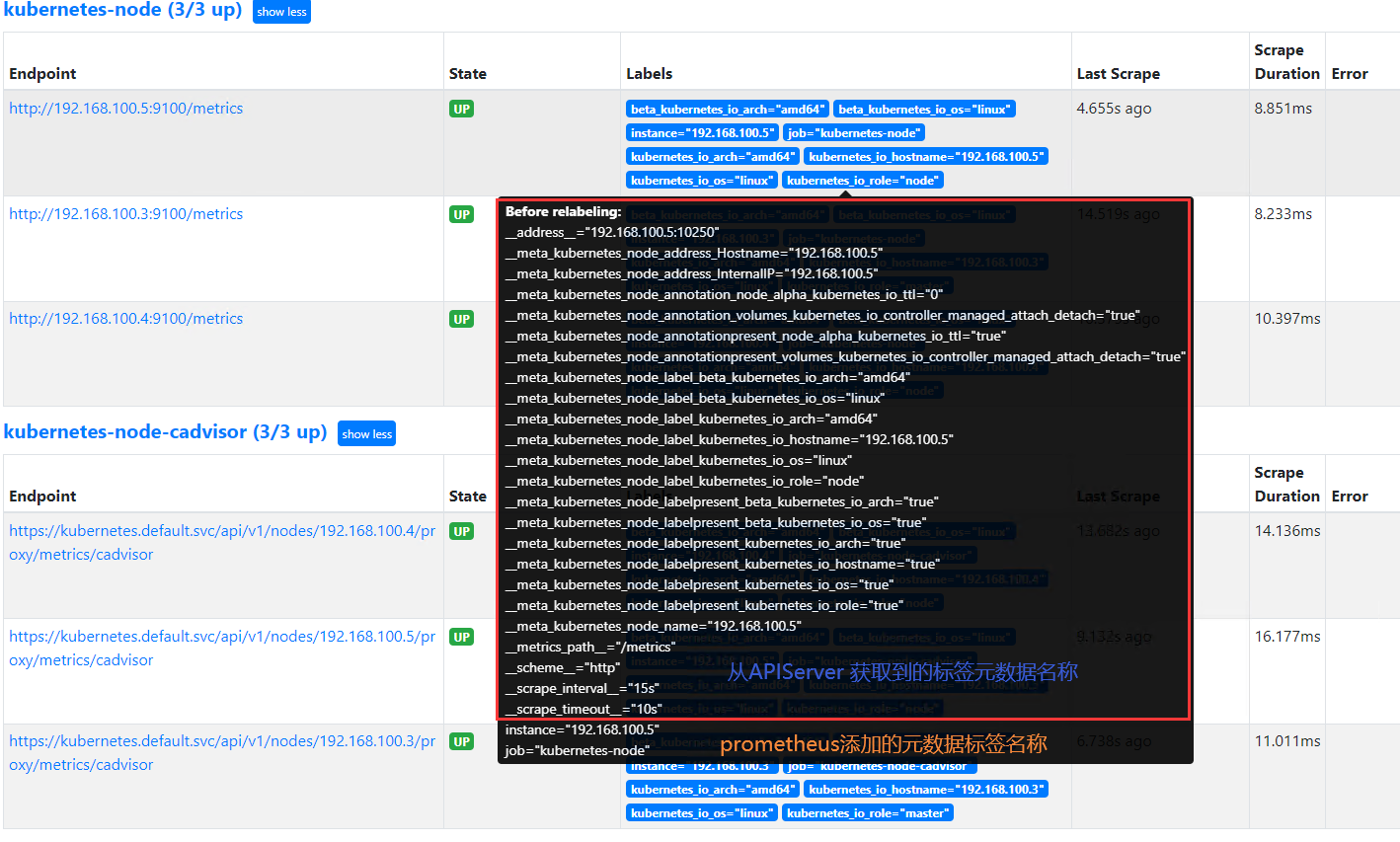
promethues 的 relabeling(重新修改标签)功能很强大,它能够在抓取到目标实例之前把目标实例的元数据标签动态重新修改,动态添加或者覆盖标签
prometheus 从 Kubernetes API 动态发现目标(targer)之后,在被发现的 target 实例中,都包含一些原始的Metadata 标签信息,默认的标签有:
address:以<host>:<port> 格式显示目标 targets 的地址
scheme:采集的目标服务地址的 Scheme 形式,HTTP 或者 HTTPS
metrics_path:采集的目标服务的访问路径
重新标记目的
为了更好的识别监控指标,便于后期调用数据绘图、告警等需求,prometheus 支持对发现的目标进行 label 修改,在两个阶段可以重新标记:
relabel_configs:在对target进行数据采集之前(比如在采集数据之前重新定义标签信息,如目的IP、目的端口等信息),可以使用relabel_configs添加、修改或删除一些标签、也可以只采集特定目标或过滤目标。
metric_relabel_configs:在对 target 进行数据采集之后,即如果是已经抓取到指标数据时,可以使用 metric_relabel_configs 做最后的重新标记和过滤。(使用较少)

- job_name: "prometheus-node"
static_configs:
- targets: ["192.168.100.4:9100","192.168.100.5:9100"]
- job_name: 'kubernetes-apiserver' #job名称
kubernetes_sd_configs: #基于kubernetes_sd_configs实现服务发现
- role: endpoints #发现endpoints
scheme: https #当前jod使用的发现协议
tls_config: #证书配置
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt #每个容器里的证书路径都在此
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token #容器里的token路径
relabel_configs: #重新re修改标签label配置configs
- source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name] #源标签,即对哪些标签进行操作
action: keep #action定义了relabel的具体动作,action支持多种
regex: default;kubernetes;https #指定匹配条件、只发现default命名空间的kubernetes服务后面的 endpoint并且是https协议
配置说明
kubernetes_sd_configs: 使用的k8s服务发现配置
role: 指定动态发现的k8s组件类型
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt。k8s为每个容器指定的默认证书的路径,与当前pod所在的node节点证书 /etc/kubernetes/ssl/ca.pem 内容一致。
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token。k8s每个容器指定集群用户的token
relabel_configs: 设置标签重写
source_labels:源标签,即对哪些标签进行操作
action:
label详解
-
可以基于已有的标签,生成一个标签
-
也可以创建新的标签
-
还可以过滤标签,不想采集哪些
-
哪些标签不要了也可以将其删除
source_labels: 源标签,没有经过 relabel 处理之前的标签名字
例如:endpoint的label名称

target_label: 通过 action 处理之后的新的标签名字
regex: 给定的值或正则表达式匹配,匹配源标签的值
replacement: 通过分组替换后标签(target_label)的值对应的/()/() $1:$2
action详解
https://prometheus.io/docs/prometheus/latest/configuration/configuration/#kubernetes_sd_config
replace: action默认为replace。替换标签值,根据 regex 正则匹配到源标签的值,使用 replacement 来引用表达式匹配的分组,创建新的标签
keep: 满足 regex 正则条件的实例进行采集,把 source_labels 中没有匹配到 regex 正则内容的 Target实例丢掉,即只采集匹配成功的实例。
drop: 满足 regex 正则条件的实例不采集,把 source_labels 中匹配到 regex 正则内容的 Target 实例丢掉,即只采集没有匹配到的实例。
hashmod:使用 hashmod 计算 source_labels 的 Hash 值并进行对比,基于自定义的模数取模,以实现对目标进行分类、重新赋值等功能:
scrape_configs:
- job_name: ip_job
relabel_configs:
- source_labels: [__address__]
modulus: 4
target_label: __ip_hash
action: hashmod
- source_labels: [__ip_hash]
regex: ^1$
action: keep
匹配 regex 所有标签名称,然后复制匹配标签的值进行分组,可以通过 replacement 分组引用(${1},${2},…)替代
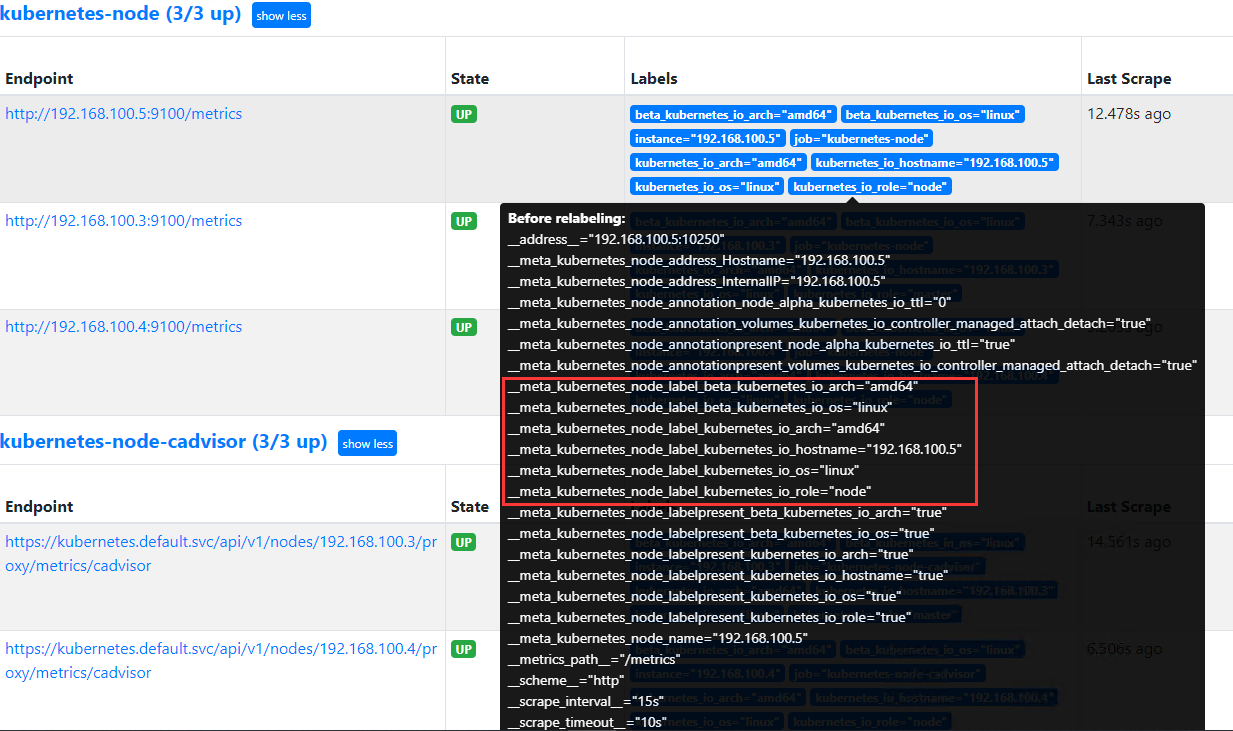
labelkeep:匹配 regex 所有标签名称,其它不匹配的标签都将从标签集中删除
labeldrop: 匹配 regex 所有标签名称,其它匹配的标签都将从标签集中删除
role详解
支持的发现目标类型
发现类型可以配置以下类型之一来发现目标:
https://prometheus.io/docs/prometheus/latest/configuration/configuration/#kubernetes_sd_config
node:node 节点
service:发现 service
pod:发现 pod
endpoints:基于 svc 发现 endpoints(pod)
Endpointslice: 对 endpoint 进行切片
ingress:
api-server的服务发现
apiserver 作为 Kubernetes 最核心的组件,它的监控也是非常有必要的,对于apiserver 的监控,可以直接通过 kubernetes 的 service 来获取
root@master1:~/yaml\# kubectl get svc -n default
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.100.0.1 <none> 443/TCP 12d
root@master1:~/yaml\# kubectl get ep -n default
NAME ENDPOINTS AGE
kubernetes 192.168.100.3:6443 12d
prometheus服务发现 apiserver 配置
- job_name: 'kubernetes-apiserver'
kubernetes_sd_configs:
- role: endpoints
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
relabel_configs:
- source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name]
action: keep
regex: default;kubernetes;https配置说明
regex: default;kubernetes;https #含义为匹配 default 的 namespace,svc 名称是 kubernetes,协议是 https,匹配成功后进行保留,并且把 regex 作为 source_labels 相对应的值。即 labels 为 key, regex 为value。
label 替换方式如下:
__meta_kubernetes_namespace=default, __meta_kubernetes_service_name=kubernetes, __meta_kubernetes_endpoint_port_name=https
最终,匹配到 api-server 的地址:
root@master1:~/yaml\# kubectl get ep -n default
NAME ENDPOINTS AGE
kubernetes 192.168.100.3:6443 12d
api-server 指标数据:
Apiserver 组件是 k8s 集群的入口,所有请求都是从 apiserver 进来的,所以对 apiserver 指标做监控可以用来判断集群的健康状况。
apiserver_request_total:
apiserver_request_total 为请求各个服务的访问详细统计
sum(rate(apiserver_request_total[10m])) by (resource,subresource,verb)
关于annotation_prometheus_io_scrape
在k8s中,基于prometheus的发现规则,需要在被发现的目的target定义注解匹配annotation_prometheus_io_scrape=true,且必须匹配成功该注解才会保留监控target,然后再进行数据抓取并进行标签替换,如annotation_prometheus_io_scheme标签为http或https:
- job_name: 'kubernetes-service-endpoints' #job 名称
kubernetes_sd_configs: #sd_configs 发现
- role: endpoints #角色,endpoints 发现
relabel_configs: #标签重写配置
#annotation_prometheus_io_scrape 的值为 true,保留标签然后再向下执行
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape]
action: keep
regex: true
#将__meta_kubernetes_service_annotation_prometheus_io_scheme 修改为__scheme__
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scheme]
action: replace
target_label: __scheme__
regex: (https?) #正则匹配协议 http 或 https(?匹配全面的字符 0 次或一次),即其它协议不替换
#将__meta_kubernetes_service_annotation_prometheus_io_path 替换为__metrics_path__
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_path]
action: replace
target_label: __metrics_path__
regex: (.+) #路径为为 1 到任意长度(.为匹配除\n 之外的任意单个字符,+ 为匹配一次或多次)
- source_labels: [__address__, __meta_kubernetes_service_annotation_prometheus_io_port]
action: replace
target_label: __address__
regex: ([^:]+)(?::\d+)?;(\d+)
replacement: $1:$2 #格式为地址:端口
#匹配 regex 所匹配的标签,然后进行应用:
- action: labelmap
regex: __meta_kubernetes_service_label_(.+) #通过正则匹配名称
#将__meta_kubernetes_namespace 替换为 kubernetes_namespace
- source_labels: [__meta_kubernetes_namespace]
action: replace
target_label: kubernetes_namespace
#将__meta_kubernetes_service_name 替换为 kubernetes_name
- source_labels: [__meta_kubernetes_service_name]
action: replace
target_label: kubernetes_service_name
kube-dns 的服务发现
coredns的部署yaml文件中,在serivce 配置中添加了两个prometheus 的annotations的标签注解,因此prometheus server可以根据这两个注解进行relabe标签重写,进行服务发现coredns。如果其他pod添加了annotations注解,但并没有prometheus mertrics port服务,即使发现了改pod,也无法采集对应的指标数据。
查看 kube-dns 状态
root@master1:~/yaml\# kubectl describe svc kube-dns -n kube-system
Name: kube-dns
Namespace: kube-system
Labels: addonmanager.kubernetes.io/mode=Reconcile
k8s-app=kube-dns
kubernetes.io/cluster-service=true
kubernetes.io/name=CoreDNS
Annotations: prometheus.io/port: 9153 #注解标签,用于 prometheus 匹配发现端口
prometheus.io/scrape: true #注解标签,用于 prometheus 匹配抓取数据
Selector: k8s-app=kube-dns
Type: ClusterIP
IP Family Policy: SingleStack
IP Families: IPv4
IP: 10.100.0.2
IPs: 10.100.0.2
Port: dns 53/UDP
TargetPort: 53/UDP
Endpoints: 10.200.166.166:53
Port: dns-tcp 53/TCP
TargetPort: 53/TCP
Endpoints: 10.200.166.166:53
Port: metrics 9153/TCP
TargetPort: 9153/TCP
Endpoints: 10.200.166.166:9153
Session Affinity: None
Events: <none>
查看coredns.yaml
root@master1:~# vim coredns.yaml
apiVersion: v1
kind: Service
metadata:
name: kube-dns
namespace: kube-system
annotations:
prometheus.io/port: "9153" #注解标签,用于 prometheus 匹配发现端口
prometheus.io/scrape: "true" #注解标签,用于 prometheus 匹配抓取数据
prometheus server配置文件添加针对coredns注解匹配
- job_name: 'kubernetes-service-endpoints' #job 名称
kubernetes_sd_configs: #sd_configs 发现
- role: endpoints #角色,endpoints 发现
relabel_configs: #标签重写配置
#annotation_prometheus_io_scrape 的值为 true,保留标签然后再向下执行
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape]
action: keep
regex: true
#将__meta_kubernetes_service_annotation_prometheus_io_scheme 修改为__scheme__
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scheme]
action: replace
target_label: __scheme__
regex: (https?) #正则匹配协议 http 或 https(?匹配全面的字符 0 次或一次),即其它协议不替换
#将__meta_kubernetes_service_annotation_prometheus_io_path 替换为__metrics_path__
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_path]
action: replace
target_label: __metrics_path__
regex: (.+) #路径为为 1 到任意长度(.为匹配除\n 之外的任意单个字符,+ 为匹配一次或多次)
- source_labels: [__address__, __meta_kubernetes_service_annotation_prometheus_io_port]
action: replace
target_label: __address__
regex: ([^:]+)(?::\d+)?;(\d+)
replacement: $1:$2 #格式为地址:端口
#匹配 regex 所匹配的标签,然后进行应用:
- action: labelmap
regex: __meta_kubernetes_service_label_(.+) #通过正则匹配名称
#将__meta_kubernetes_namespace 替换为 kubernetes_namespace
- source_labels: [__meta_kubernetes_namespace]
action: replace
target_label: kubernetes_namespace
#将__meta_kubernetes_service_name 替换为 kubernetes_name
- source_labels: [__meta_kubernetes_service_name]
action: replace
target_label: kubernetes_service_name
修改coredns副本数验证发现
新添加一个 node 节点或修改 deployment 控制器的副本数,以让 endpoint 数量发生变化,验证能否自动发现新添加的 pod:
root@master1:~/yaml\# kubectl edit -n kube-system deployments.apps coredns
replicas: 3
prometheus target页面新增coredns target
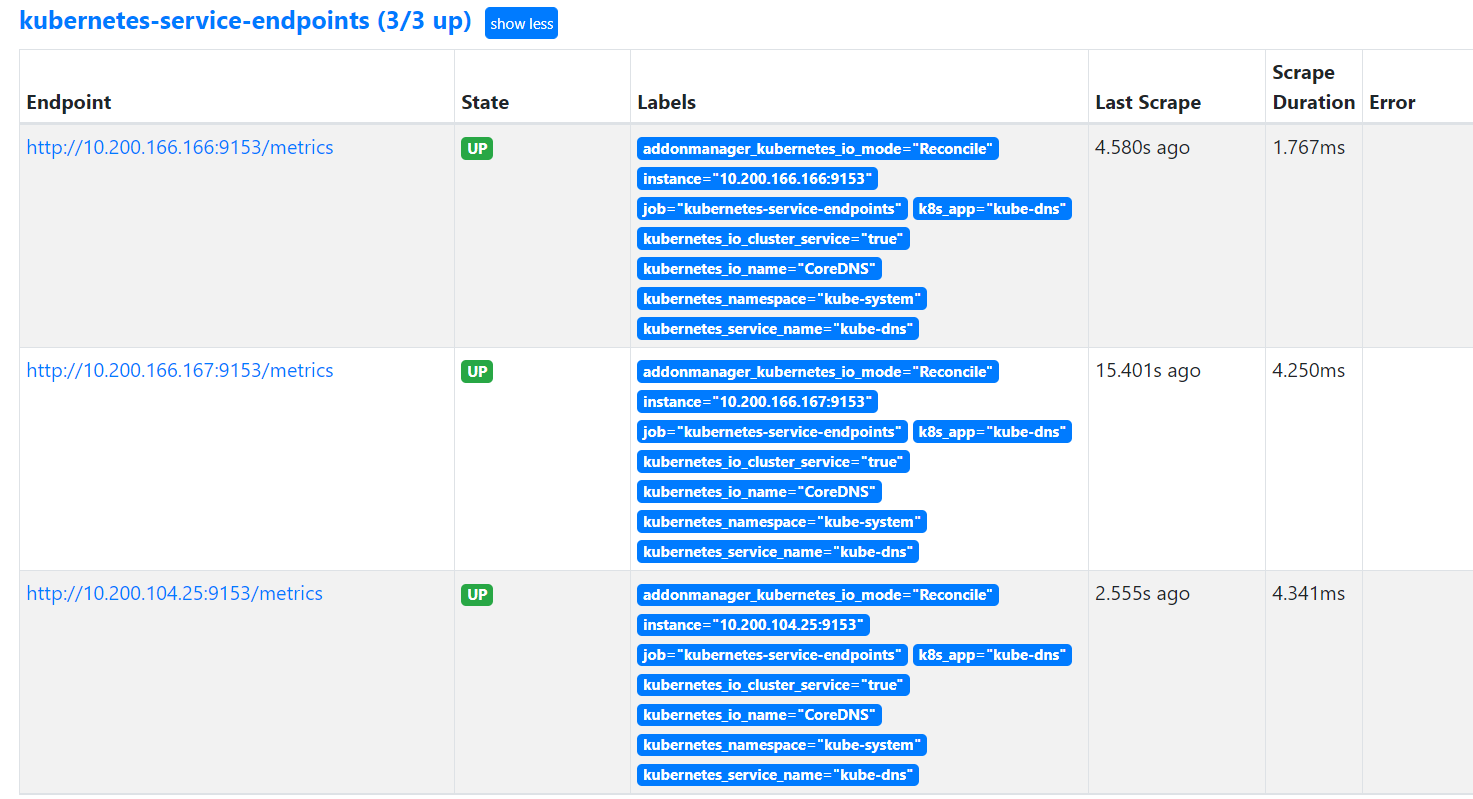
promQL测试查询coredns指标数据
grafana添加coredns dashboard模板,ID14981
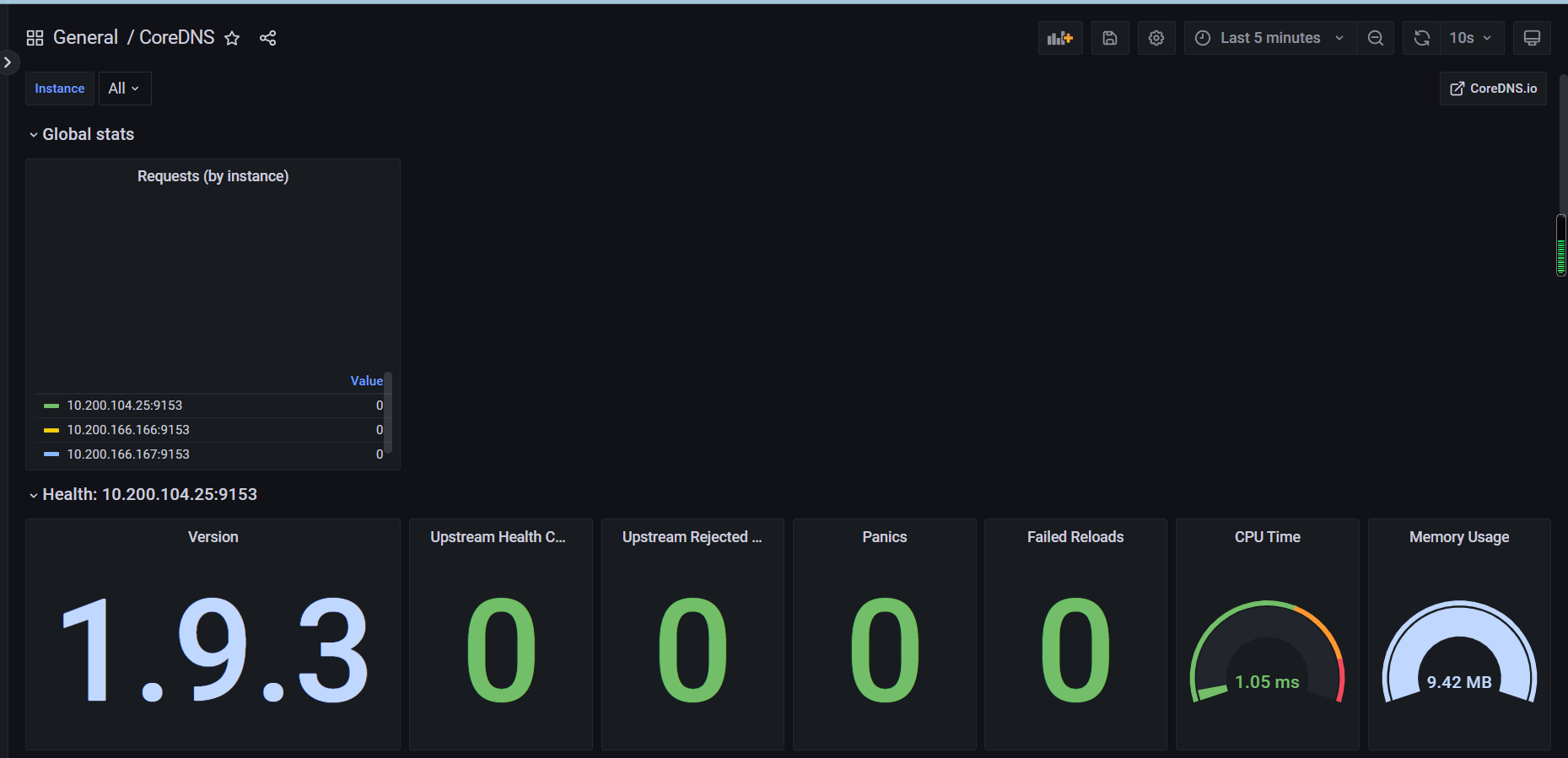
kubelet 的服务发现
kubelet服务带有metrics指标URI API,因此只要配置服务发现即可
参考官网:
https://prometheus.io/docs/prometheus/latest/configuration/configuration/#kubernetes_sd_config
使用role为node,默认采集地址的是k8s节点的kubelet服务,http://nodeip:10250
将schema修改为https,并添加集群证书认证否则无权限查看https://nodeip:10250/metrics
- job_name: 'kubelet'
kubernetes_sd_configs:
- role: node
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
root@master1:~/yaml\# kubectl apply -f prometheus-cfg.yaml
configmap/prometheus-config configured
root@master1:~/yaml\# kubectl delete pods prometheus-server-84c8755ccc-ndwtd
pod "prometheus-server-84c8755ccc-ndwtd" deleted
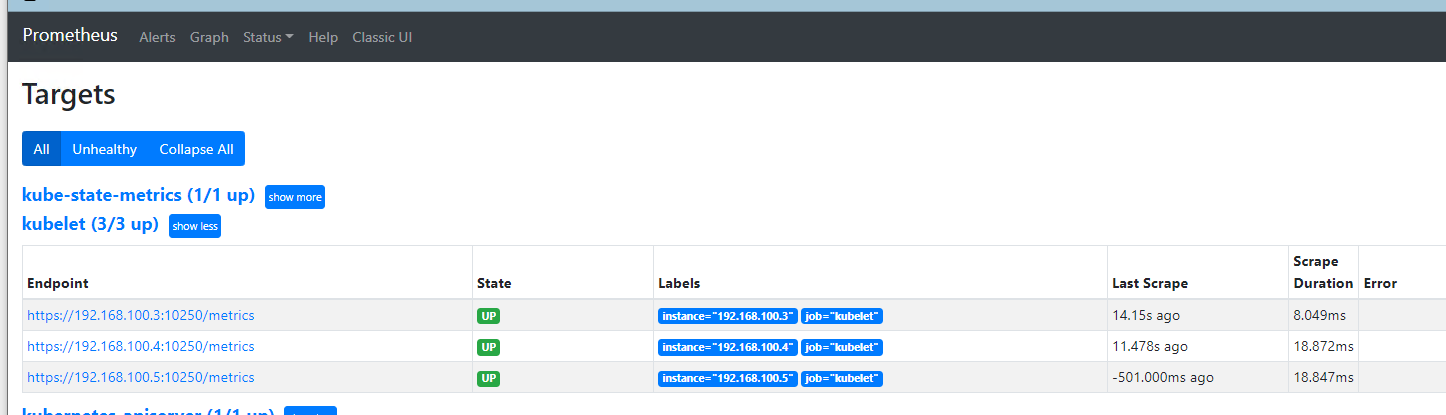
node 节点发现
prometheus server服务发现 配置prometheus.yml
发现node节点服务,思路主要就是将每个节点kubelet端口10250替换为node-exporter端口9100并将标签值进行替换
- job_name: 'kubernetes-node' #job name
kubernetes_sd_configs: #发现配置
- role: node #发现类型为node
relabel_configs: #标签重写配置
- source_labels: [__address__] #匹配node-exporter指标数据源标签
regex: '(.*):10250' #通过正则匹配后缀为:10250 的实例,10250 是 kubelet 端口
replacement: '${1}:9100' #重写为 IP:9100,即将端口替换为 prometheus node-exporter 的端口
target_label: __address__ #将[__address__]替换为__address__
action: replace #将[__address__] 的值依然赋值给__address__
#发现 lable 并引用
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
匹配的目的数据:
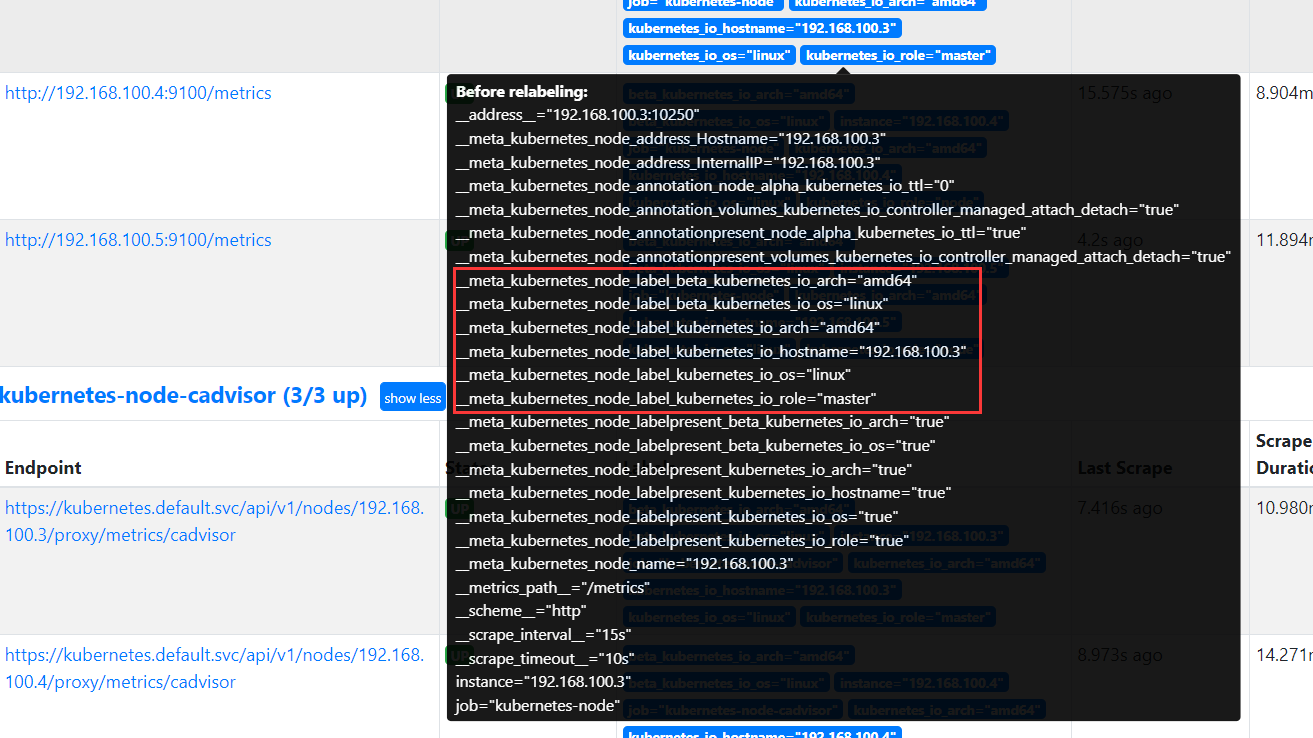
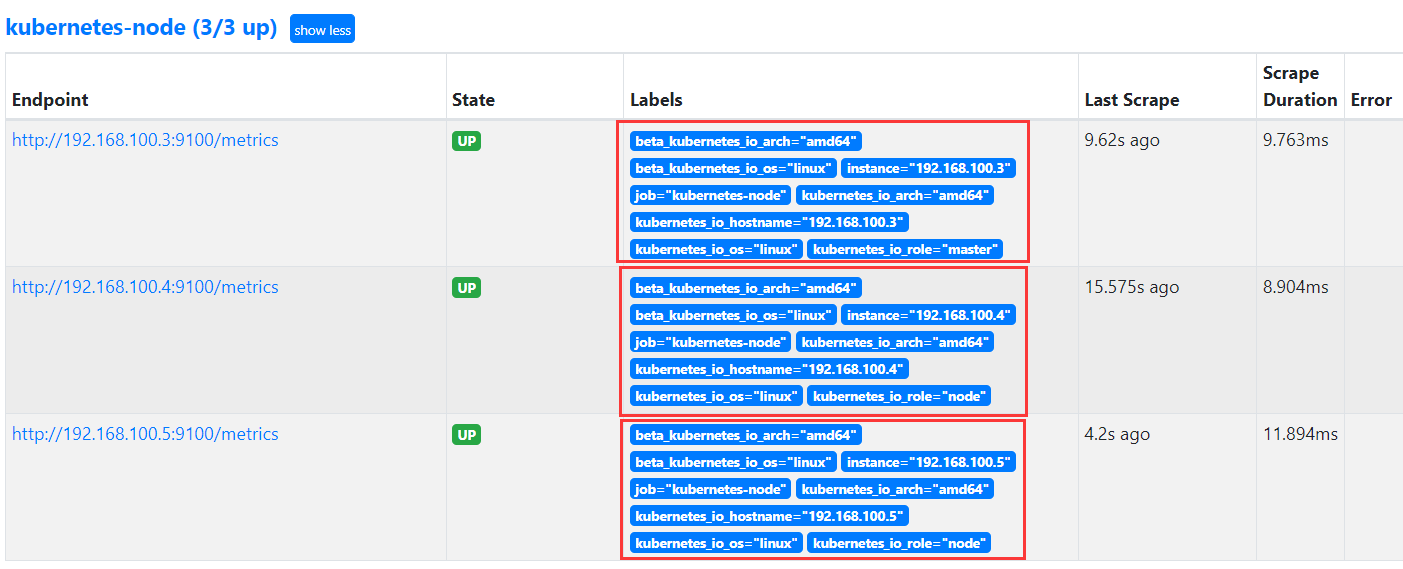
Cadvisor 发现
prometheus Server 配置 通过k8s default命名空间下的kubernetes svc进行服务发现apiserver的endpoint地址,并将metrics_name修改成apiserver的cadvisor API
- job_name: 'kubernetes-node-cadvisor' #job 名称
kubernetes_sd_configs: #基于 kubernetes_sd_configs 发现
- role: node #发现服务类型为node
scheme: https #采集的目标服务地址的 https 形式
tls_config: #证书配置
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt #默认k8s会将集群证书路径存放在容器的路径位置
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token #默认k8s会将token存放在容器的路径位置
relabel_configs: #标签重写配置
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
- target_label: __address__
replacement: kubernetes.default.svc:443 #replacement 指定替换后的标签(target_label)对应的值为 kubernetes.default.svc:443
- source_labels: [__meta_kubernetes_node_name] #将[__meta_kubernetes_node_name]重写为 __metrics_path__
regex: (.+) #至少 1 位长度以上
target_label: __metrics_path__
replacement: /api/v1/nodes/${1}/proxy/metrics/cadvisor #指定 cadvisord 的 API 路径
查看 cadvisor 数据:
$TOKEN 为k8s集群sa账户 secret中的token
kubectl describe secrets dashboard-admin-user |grep token
#使用curl指定k8s集群证书和sa账户token访问cadvisor指标数据
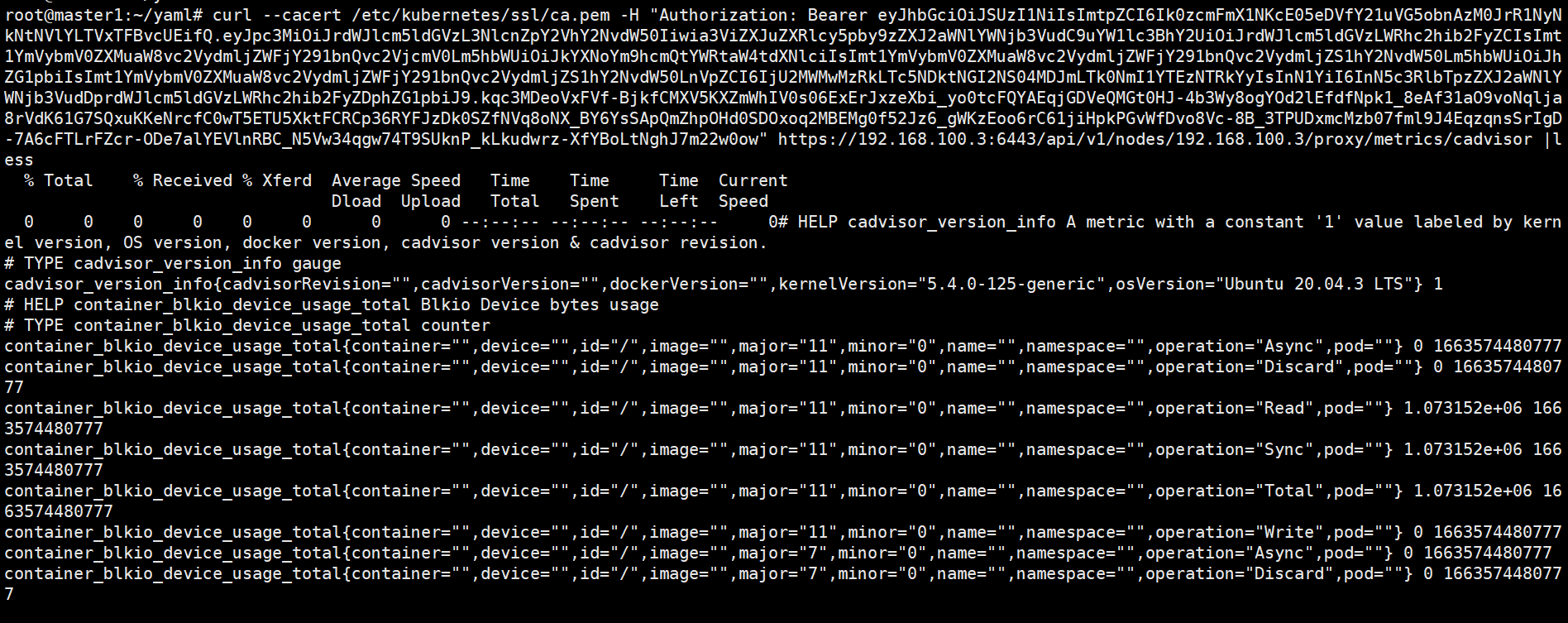
curl --cacert /etc/kubernetes/ssl/ca.pem -H "Authorization: Bearer $TOKEN" https://192.168.100.3:6443/api/v1/nodes/192.168.100.3/proxy/metrics/cadvisor 指定token和证书访问
curl --cacert /etc/kubernetes/ssl/ca.pem -H "Authorization: Bearer eyJhbGciOiJSUzI1NiIsImtpZCI6Ik0zcmFmX1NKcE05eDVfY21uVG5obnAzM0JrR1NyNkNtNVlYLTVxTFBvcUEifQ.eyJpc3MiOiJrdWJlcm5ldGVzL3NlcnZpY2VhY2NvdW50Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9uYW1lc3BhY2UiOiJrdWJlcm5ldGVzLWRhc2hib2FyZCIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VjcmV0Lm5hbWUiOiJkYXNoYm9hcmQtYWRtaW4tdXNlciIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VydmljZS1hY2NvdW50Lm5hbWUiOiJhZG1pbiIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VydmljZS1hY2NvdW50LnVpZCI6IjU2MWMwMzRkLTc5NDktNGI2NS04MDJmLTk0NmI1YTEzNTRkYyIsInN1YiI6InN5c3RlbTpzZXJ2aWNlYWNjb3VudDprdWJlcm5ldGVzLWRhc2hib2FyZDphZG1pbiJ9.kqc3MDeoVxFVf-BjkfCMXV5KXZmWhIV0s06ExErJxzeXbi_yo0tcFQYAEqjGDVeQMGt0HJ-4b3Wy8ogYOd2lEfdfNpk1_8eAf31aO9voNqlja8rVdK61G7SQxuKKeNrcfC0wT5ETU5XktFCRCp36RYFJzDk0SZfNVq8oNX_BY6YsSApQmZhpOHd0SDOxoq2MBEMg0f52Jz6_gWKzEoo6rC61jiHpkPGvWfDvo8Vc-8B_3TPUDxmcMzb07fml9J4EqzqnsSrIgD-7A6cFTLrFZcr-ODe7alYEVlnRBC_N5Vw34qgw74T9SUknP_kLkudwrz-XfYBoLtNghJ7m22w0ow" https://192.168.100.3:6443/api/v1/nodes/192.168.100.3/proxy/metrics/cadvisor
k8s内部实现pod发现
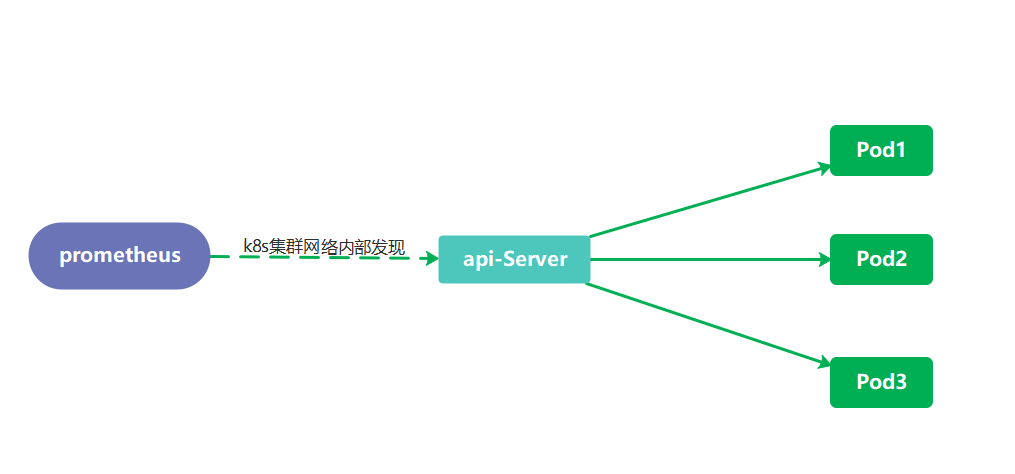
在内部直接发现 pod 并执行监控数据采集
- job_name: 'kubernetes-pods'
kubernetes_sd_configs:
- role: pod #发现服务类型
namespaces: #可选指定namepace,如果不指定就是发现所有的namespace中的pod
names:
- test
- default
relabel_configs:
- action: labelmap
regex: __meta_kubernetes_pod_label_(.+)
- source_labels: [__meta_kubernetes_namespace]
action: replace
target_label: kubernetes_namespace
- source_labels: [__meta_kubernetes_pod_name]
action: replace
target_label: kubernetes_pod_name
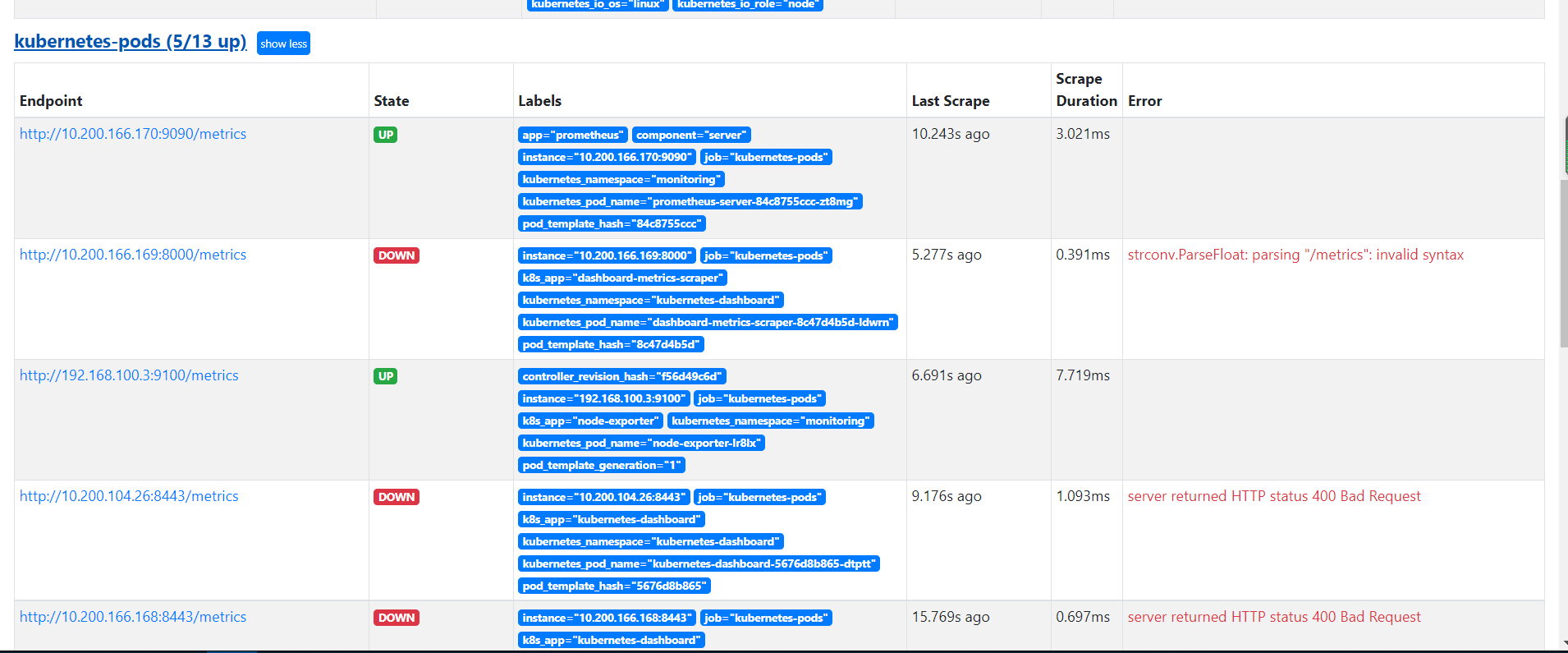
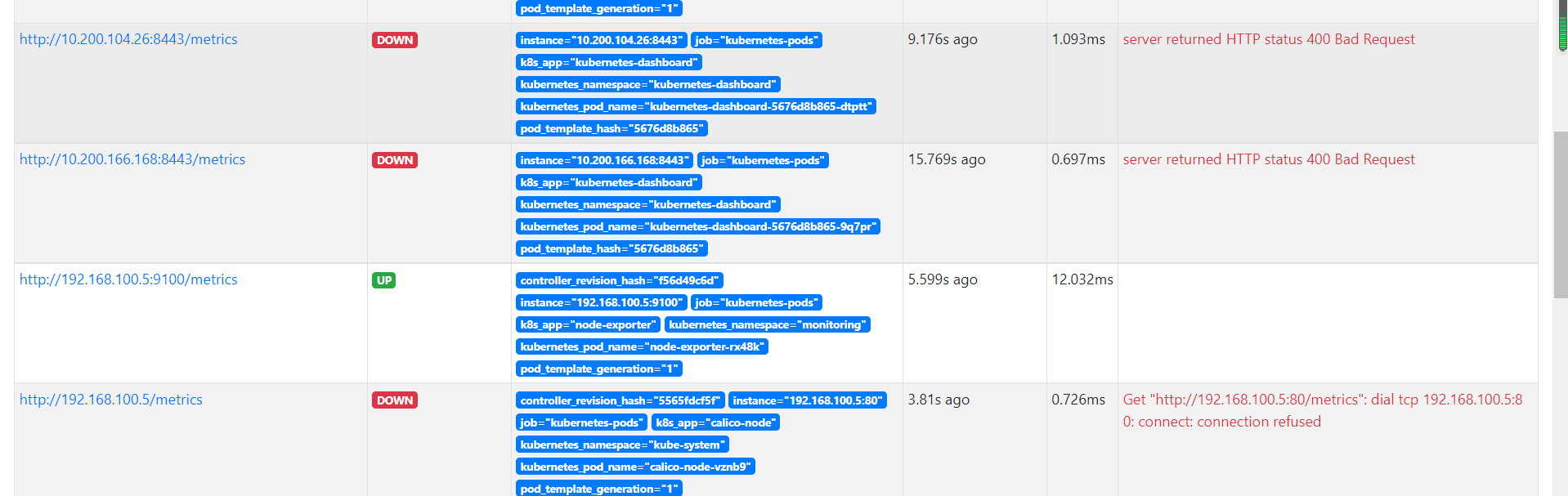
验证数据:
被发现的 podxv 需要提供 metrics 指标数据 API 接口,如果没有提供监控接口,会显示 DOWN。
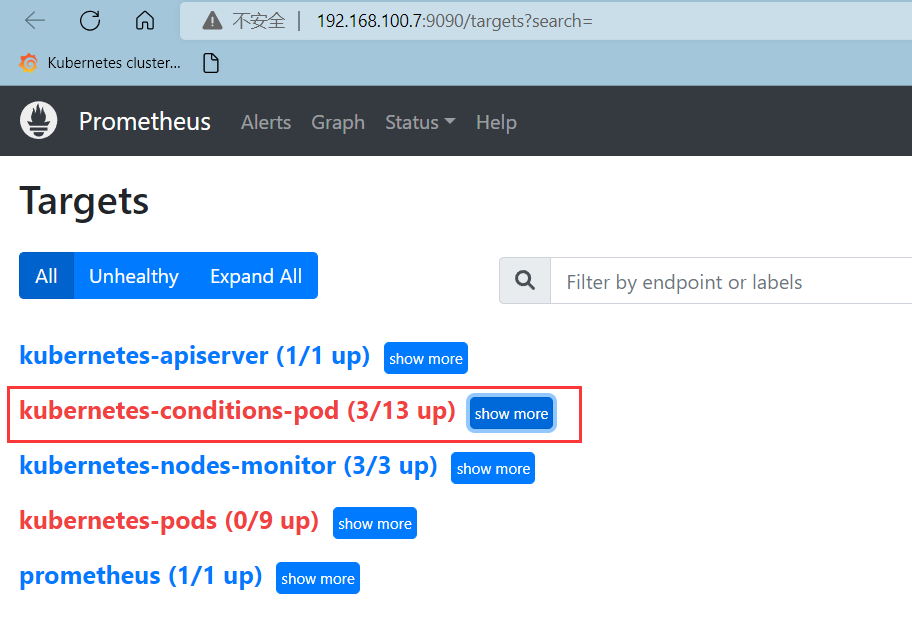
基于consul的服务发现consul_sd_configs
安装consul
consul官网:https://www.consul.io/
Consul 是分布式 k/v 数据存储集群,目前常用于服务的服务注册和发现。
官网下载
下载链接1https://www.consul.io/downloads
下载链接2https://releases.hashicorp.com/consul/
环境:
192.168.100.9、192.168.100.10、192.168.100.11
安装consul
root@consul1:/usr/local\# unzip consul_1.13.1_linux_amd64.zip
root@consul1:/usr/local\# mv consul /usr/local/bin/
root@consul1:/usr/local\# scp /usr/local/bin/consul 192.168.100.10:/usr/local/bin/
root@consul1:/usr/local\# scp /usr/local/bin/consul 192.168.100.11:/usr/local/bin/
创建consul数据目录和日志目录,三个节点分别创建
mkdir /data/consul/data -p
mkdir /data/consul/logs -p
consul命令参数:
consul agent -server #使用 server 模式运行 consul 服务
-bootstrap #首次部署使用初始化模式
-bind #设置群集通信的监听地址
-client #设置客户端访问的监听地址
-data-dir #指定数据保存路径
-ui #启用内置静态 web UI 服务器
-node #此节点的名称,群集中必须唯一
-datacenter=dc1 #集群名称,默认是 dc1
-join #加入到已有 consul 集群环境
-bootstrap-expect #在一个datacenter中期望提供的server节点数目,当该值提供的时候,consul一直等到达到指定sever数目的时候才会引导整个集群,该标记不能和bootstrap共用(推荐使用的方式)
-config-dir #配置文件目录,里面所有以.json结尾的文件都会被加载
-log-rotate-bytes=102400000 #指定日志大小,100MB(字节)
主节点配置
root@consul1:/data/consul/logs\# vim /etc/systemd/system/consul.service
[Unit]
Description=consul server
After=network.target
[Service]
Type=simple
User=root
ExecStart=/usr/local/bin/consul agent -server -bootstrap-expect=3 -bind=192.168.100.9 -client=192.168.100.9 -data-dir=/data/consul/data -ui -node=192.168.100.9 -datacenter=dc1 -log-rotate-bytes=102400000 -log-file=/data/consul/logs/
ExecReload=/bin/kill -HUP $MAINPID
KillSignal=SIGTERM
[Install]
WantedBy=multi-user.target
从节点配置
consul2配置
root@consul2:~\# vim /etc/systemd/system/consul.service
[Unit]
Description=consul server
After=network.target
[Service]
Type=simple
User=root
ExecStart=/usr/local/bin/consul agent -server -bootstrap-expect=3 -bind=192.168.100.10 -client=192.168.100.10 -data-dir=/data/consul/data -ui -node=192.168.100.10 -datacenter=dc1 -join=192.168.100.9 -log-rotate-bytes=102400000 -log-file=/data/consul/logs/
ExecReload=/bin/kill -HUP $MAINPID
KillSignal=SIGTERM
[Install]
WantedBy=multi-user.target
consul3配置
root@consul3:~\# cat /etc/systemd/system/consul.service
[Unit]
Description=consul server
After=network.target
[Service]
Type=simple
User=root
ExecStart=/usr/local/bin/consul agent -server -bootstrap-expect=3 -bind=192.168.100.11 -client=192.168.100.11 -data-dir=/data/consul/data -ui -node=192.168.100.11 -datacenter=dc1 -join=192.168.100.9 -log-rotate-bytes=102400000 -log-file=/data/consul/logs/
ExecReload=/bin/kill -HUP $MAINPID
KillSignal=SIGTERM
[Install]
WantedBy=multi-user.target
systemctl daemon-reload && systemctl start consul && systemctl enable consul
浏览器访问consul主节点:IP:8500
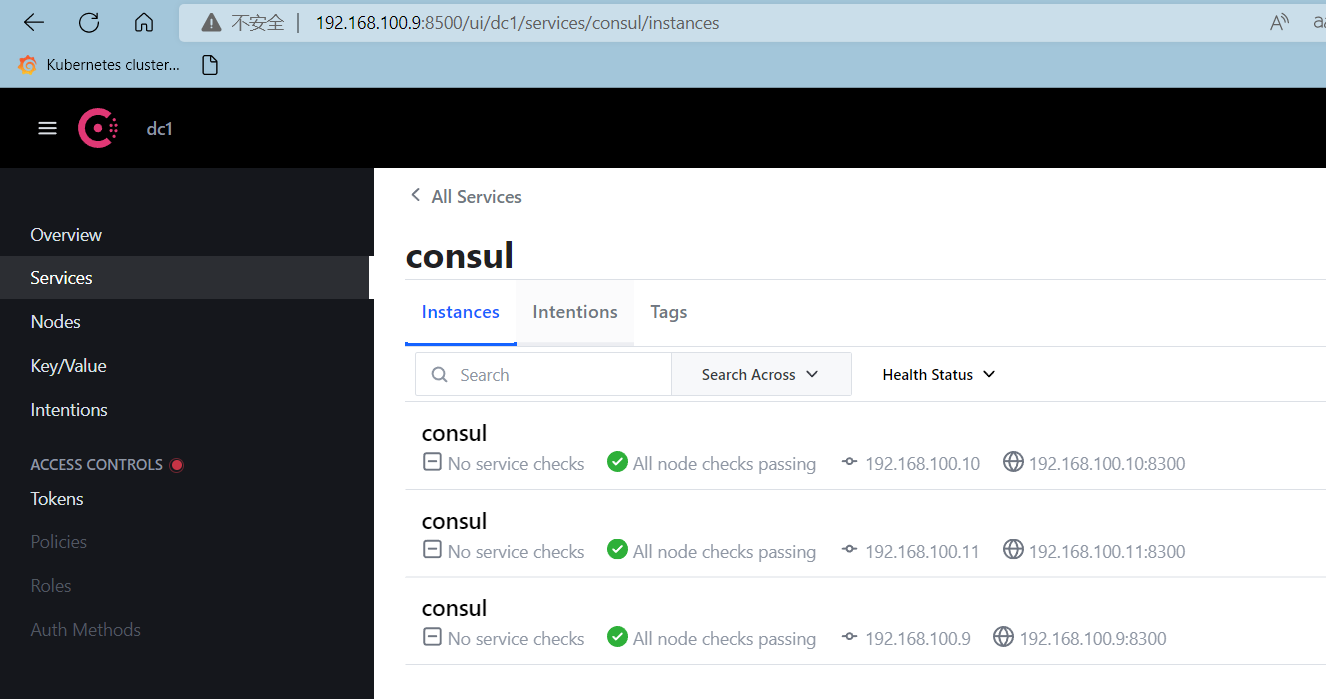
测试写入数据
1、服务发现node-exporter
通过 consul 的 API 写入数据,添加k8s三个prometheus 的node-exporter服务地址
curl -X PUT -d '{"id": "node-exporter1","name": "node-exporter1","address":"192.168.100.3","port":9100,"tags": ["node-exporter"],"checks": [{"http":"http://192.168.100.3:9100/","interval": "5s"}]}' http://192.168.100.9:8500/v1/agent/service/register
curl -X PUT -d '{"id": "node-exporter2","name": "node-exporter2","address":"192.168.100.4","port":9100,"tags": ["node-exporter"],"checks": [{"http":"http://192.168.100.4:9100/","interval": "5s"}]}' http://192.168.100.9:8500/v1/agent/service/register
curl -X PUT -d '{"id": "node-exporter3","name": "node-exporter3","address":"192.168.100.5","port":9100,"tags": ["node-exporter"],"checks": [{"http":"http://192.168.100.5:9100/","interval": "5s"}]}' http://192.168.100.9:8500/v1/agent/service/register
2、服务发现cadvisor
通过 consul 的 API 写入数据,添加k8s三个prometheus 的cadvisor服务地址
curl -X PUT -d '{"id": "cadvisor1","name": "cadvisor1","address":"192.168.100.3","port":8080,"tags": ["cadvisor"],"checks": [{"http":"http://192.168.100.3:8080/","interval": "5s"}]}' http://192.168.100.9:8500/v1/agent/service/register
curl -X PUT -d '{"id": "cadvisor2","name": "cadvisor2","address":"192.168.100.4","port":8080,"tags": ["cadvisor"],"checks": [{"http":"http://192.168.100.4:8080/","interval": "5s"}]}' http://192.168.100.9:8500/v1/agent/service/register
curl -X PUT -d '{"id": "cadvisor3","name": "cadvisor3","address":"192.168.100.5","port":8080,"tags": ["cadvisor"],"checks": [{"http":"http://192.168.100.5:8080/","interval": "5s"}]}' http://192.168.100.9:8500/v1/agent/service/register
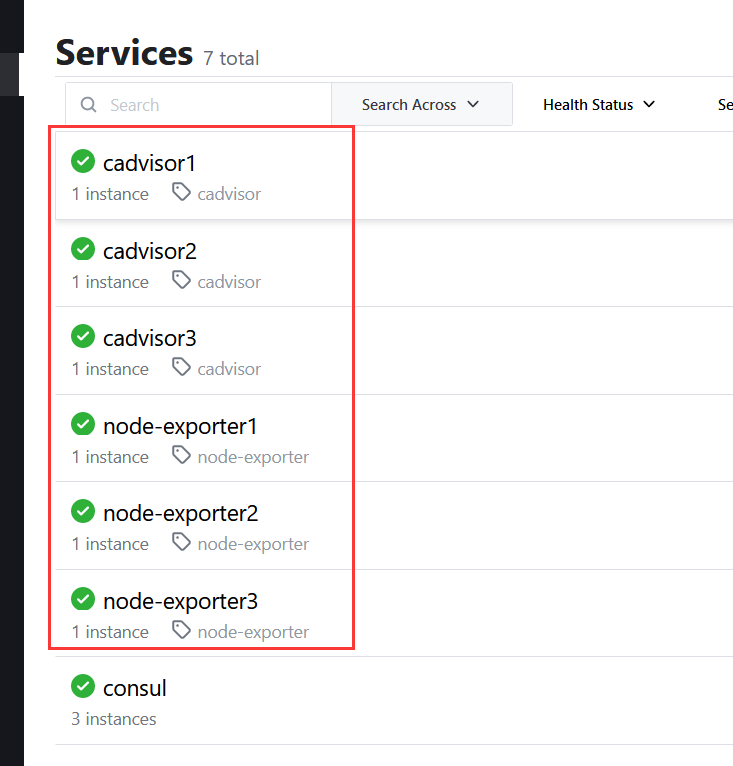
服务详细
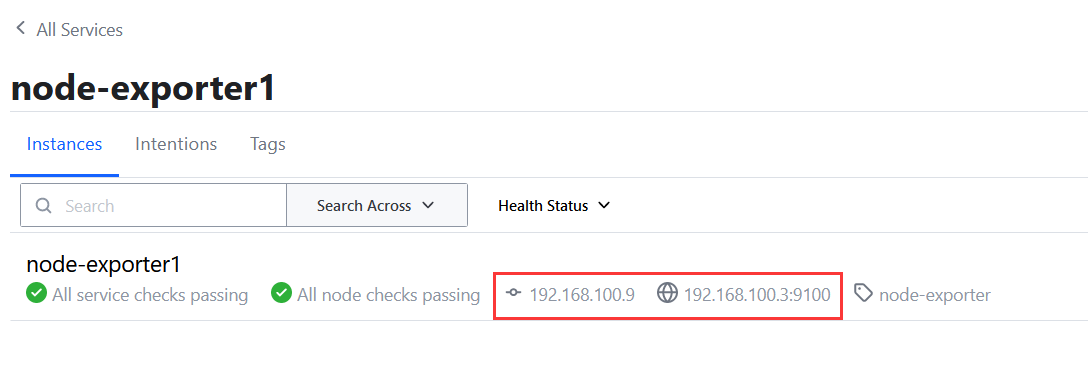
删除服务
PUT请求URI /v1/agent/service/deregister/{服务ID}
curl -XPUT http://192.168.100.9:8500/v1/agent/service/deregister/node-exporter3
配置prometheus到consul发现服务
prometheus官网:https://prometheus.io/docs/prometheus/latest/configuration/configuration/#consul_sd_config
主要配置字段
static_configs: #配置数据源
consul_sd_configs: #指定基于 consul 服务发现的配置
rebel_configs: #重新标记
services: [] #表示匹配 consul 中所有的 service
consul_sd_configs配置字段
metrics_path: /metrics #指定的是k8s中的node-exporter的metrics指标URI
scheme: http #指定的是k8s中node-exporter的scheme模式,不是consul的scheme
refresh_interval: 15s #间隔15s从consul服务发现,默认30s
honor_labels: true
#honor_labels 控制 Prometheus 如何处理已经存在于已抓取数据中的标签与 Prometheus 将附加服务器端的标签之间的冲突("job"和"instance"标签,手动配置的目标标签以及服务发现实现生成的标签)。如果 honor_labels 设置为"true",则保留已抓取数据的标签值并忽略冲突的 prometheus 服务器端标签来解决标签冲突,另外如果被采集端有标签但是值为空、则使用 prometheus 本地标签值,如果被采集端没有此标签、但是 prometheus 配置了,那也使用 prometheus 的配置的标签值。如果 honor_labels 设置为 "false" ,则通过将已抓取数据中的冲突标签重命名为 "exported_<original-label>"(例如"exported_instance","exported_job")然后附加服务器端标签来解决标签冲突。
1、k8s部署prometheus-server 的配置yaml
root@master1:~/yaml# cat prometheus-consul-cfg.yaml
kind: ConfigMap
apiVersion: v1
metadata:
labels:
app: prometheus
name: prometheus-config
namespace: monitoring
data:
prometheus.yml: |
global:
scrape_interval: 15s
scrape_timeout: 10s
evaluation_interval: 1m
scrape_configs:
- job_name: consul
honor_labels: true #则保留已抓取数据的标签值并忽略冲突的 prometheus 服务器端标签来解决标签冲突
metrics_path: /metrics #指定的是k8s中的node-exporter的metrics指标URI
scheme: http #指定的是k8s中node-exporter的scheme模式,不是consul的scheme
consul_sd_configs:
- server: 192.168.100.9:8500
services: []
- server: 192.168.100.10:8500
services: []
- server: 192.168.100.11:8500
services: []
- refresh_interval: 15s #间隔15s从consul服务发现,默认30s
relabel_configs:
- source_labels: ['__meta_consul_tags']
target_label: 'product' #将__meta_consul_tags替换为新的标签product
- source_labels: ['__meta_consul_dc']
target_label: 'idc' #将__meta_consul_dc标签替换为新的标签idc
- source_labels: ['__meta_consul_service']
regex: "consul" #取消发现consul的服务
action: drop
浏览器访问验证prometheus-server
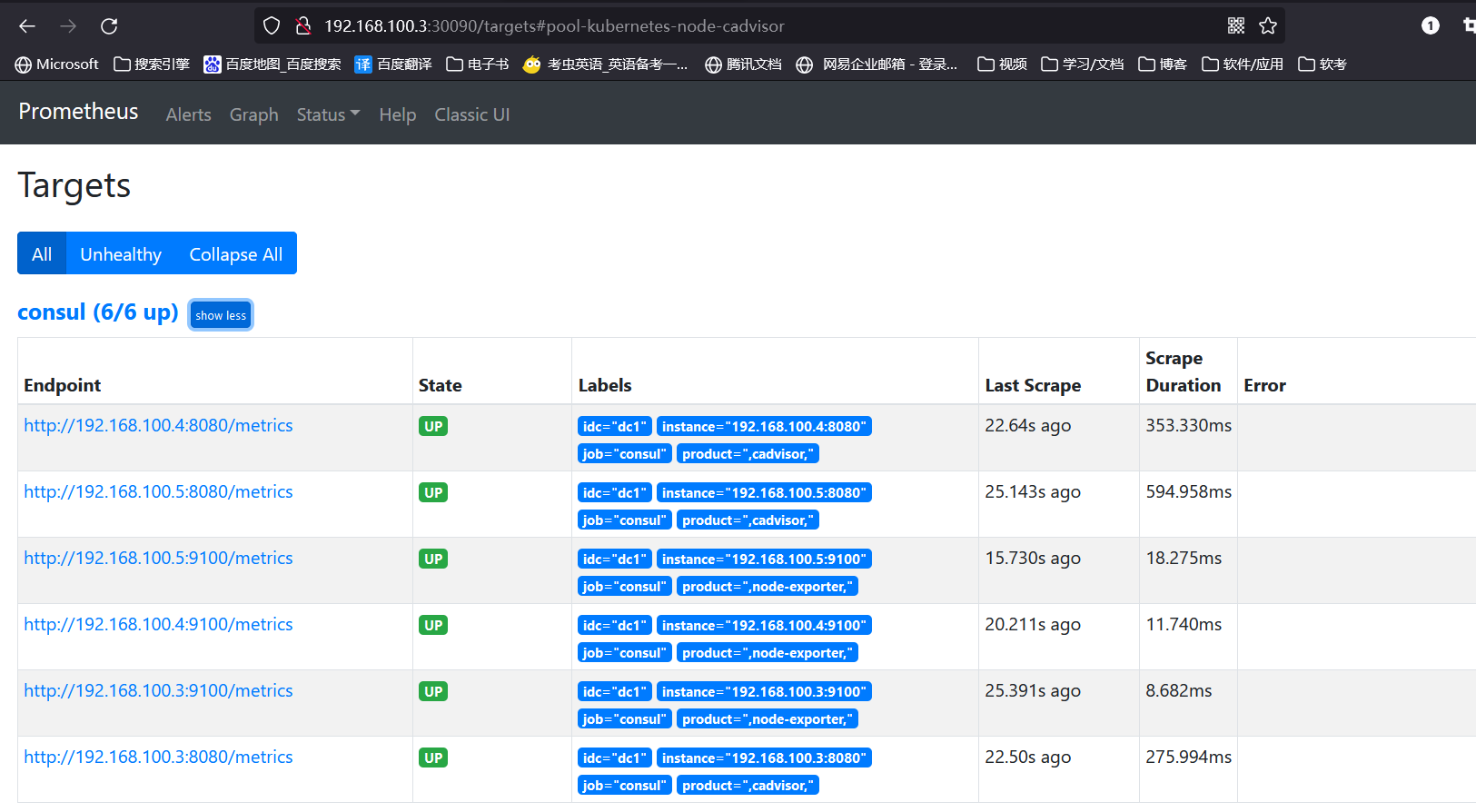
2、二进制部署prometheus-server 的配置文件
root@prometheus:/etc/profile.d\# cd /usr/local/prometheus
root@prometheus:/usr/local/prometheus\# vim prometheus.yml
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: "prometheus"
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ["localhost:9090"]
#配置consul服务发现,从而抓取监控指标
- job_name: consul
honor_labels: true
metrics_path: /metrics
scheme: http
consul_sd_configs:
- server: 192.168.100.9:8500
services: []
- server: 192.168.100.10:8500
services: []
- server: 192.168.100.11:8500
services: []
- refresh_interval: 15s
relabel_configs:
- source_labels: ['__meta_consul_tags']
target_label: 'product'
- source_labels: ['__meta_consul_dc']
target_label: 'idc'
- source_labels: ['__meta_consul_service']
regex: "consul"
action: drop
浏览器访问:
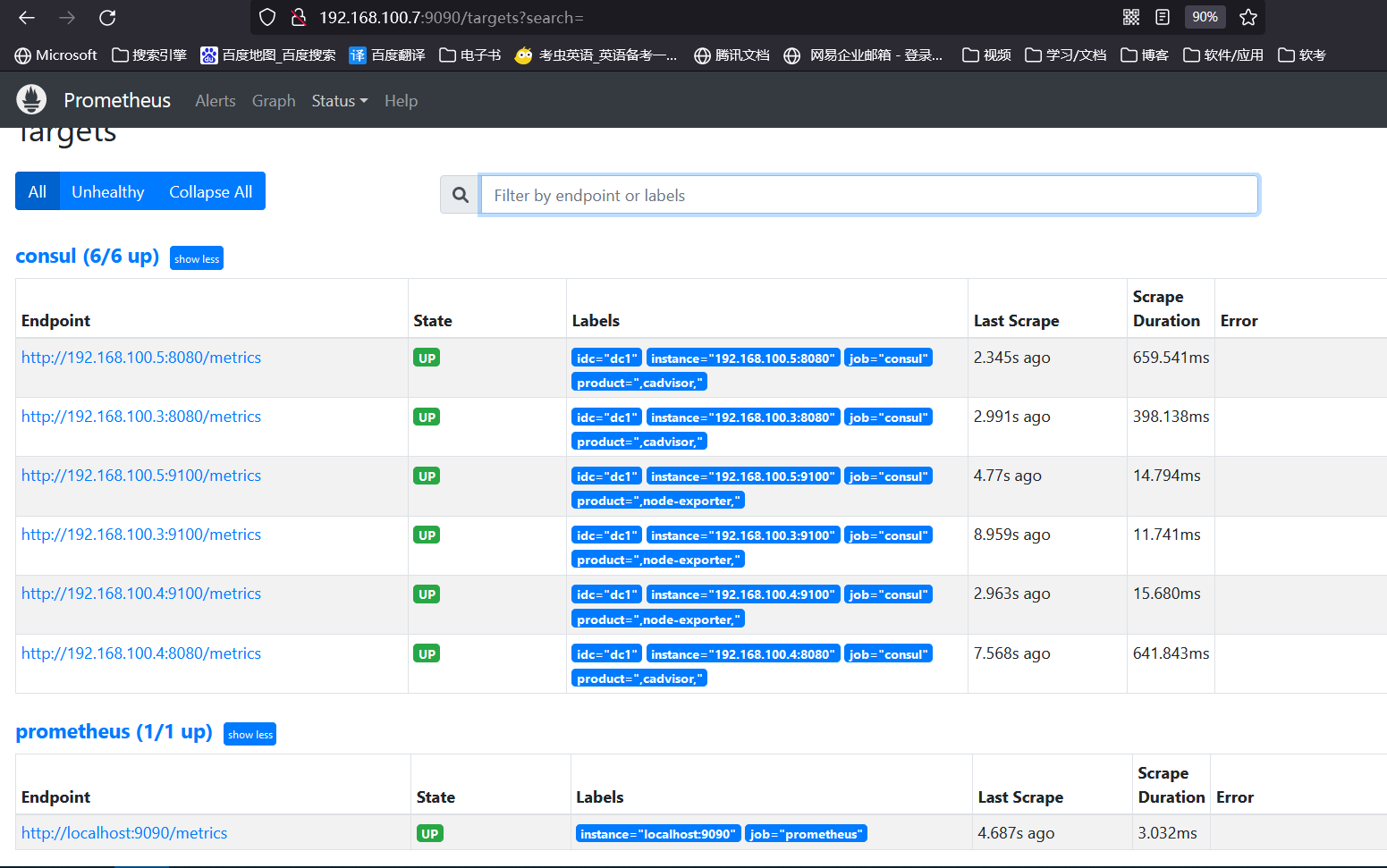
file_sd_configs
prometheus-server可以从指定的文件中动态发现监控指标服务,并且文件如果发生修改prometheus-server也无需重新服务,可以动态从文件中抓取获取到对应的target
https://prometheus.io/docs/prometheus/latest/configuration/configuration/#file_sd_config
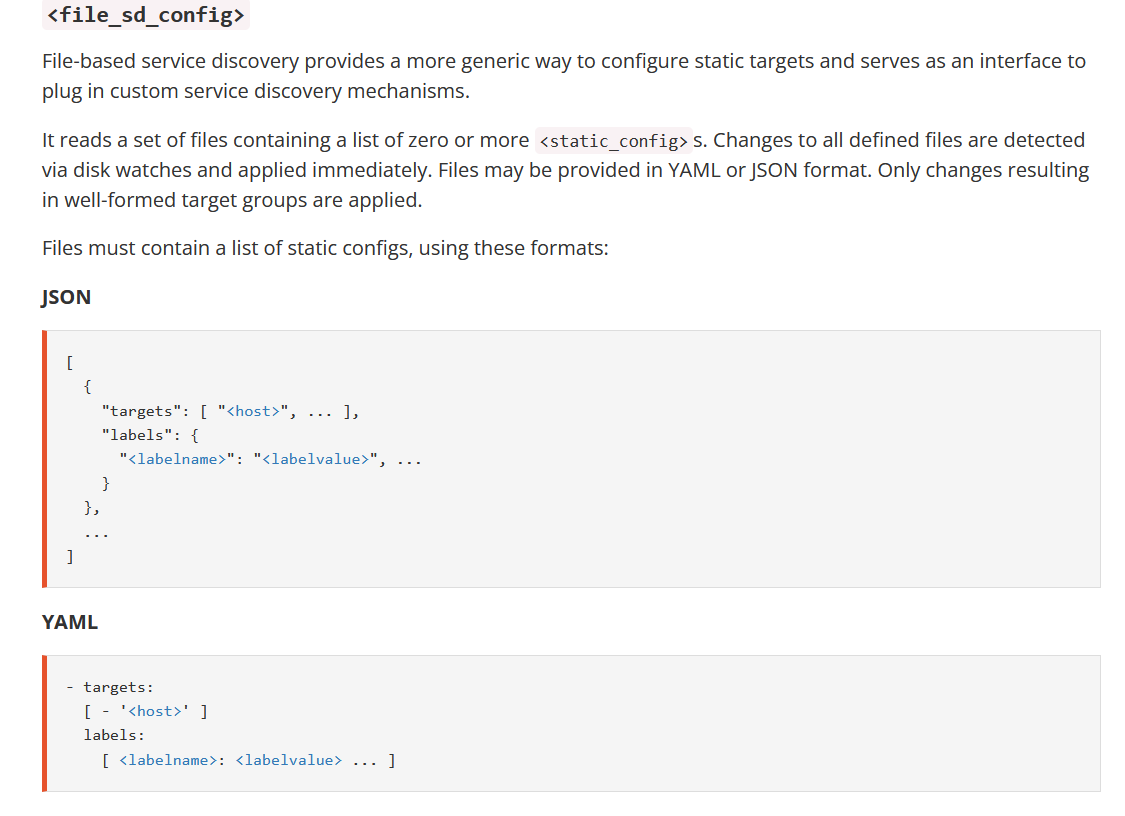
编辑 file_sd_configs 配置文件:
在prometheus目录下创建一个存放file_sd_configs目录
root@prometheus:/usr/local/prometheus\# mkdir file_sd
创建file_sd_configs 配置文件添加prometheus服务发现的target(node_exporter)
root@prometheus:/usr/local/prometheus\# vim file_sd/target.json
[
{
"targets": [ "192.168.100.3:9100", "192.168.100.4:9100", "192.168.100.5:9100" ]
}
]
创建file_sd_configs 配置文件添加prometheus服务发现的cadvisor
root@prometheus:/usr/local/prometheus\# vim file_sd/cadvisor.json
[
{
"targets": [ "192.168.100.3:8080", "192.168.100.4:8080", "192.168.100.5:8080" ]
}
]
root@prometheus:/usr/local/prometheus\# cat prometheus.yml
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: "prometheus"
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ["localhost:9090"]
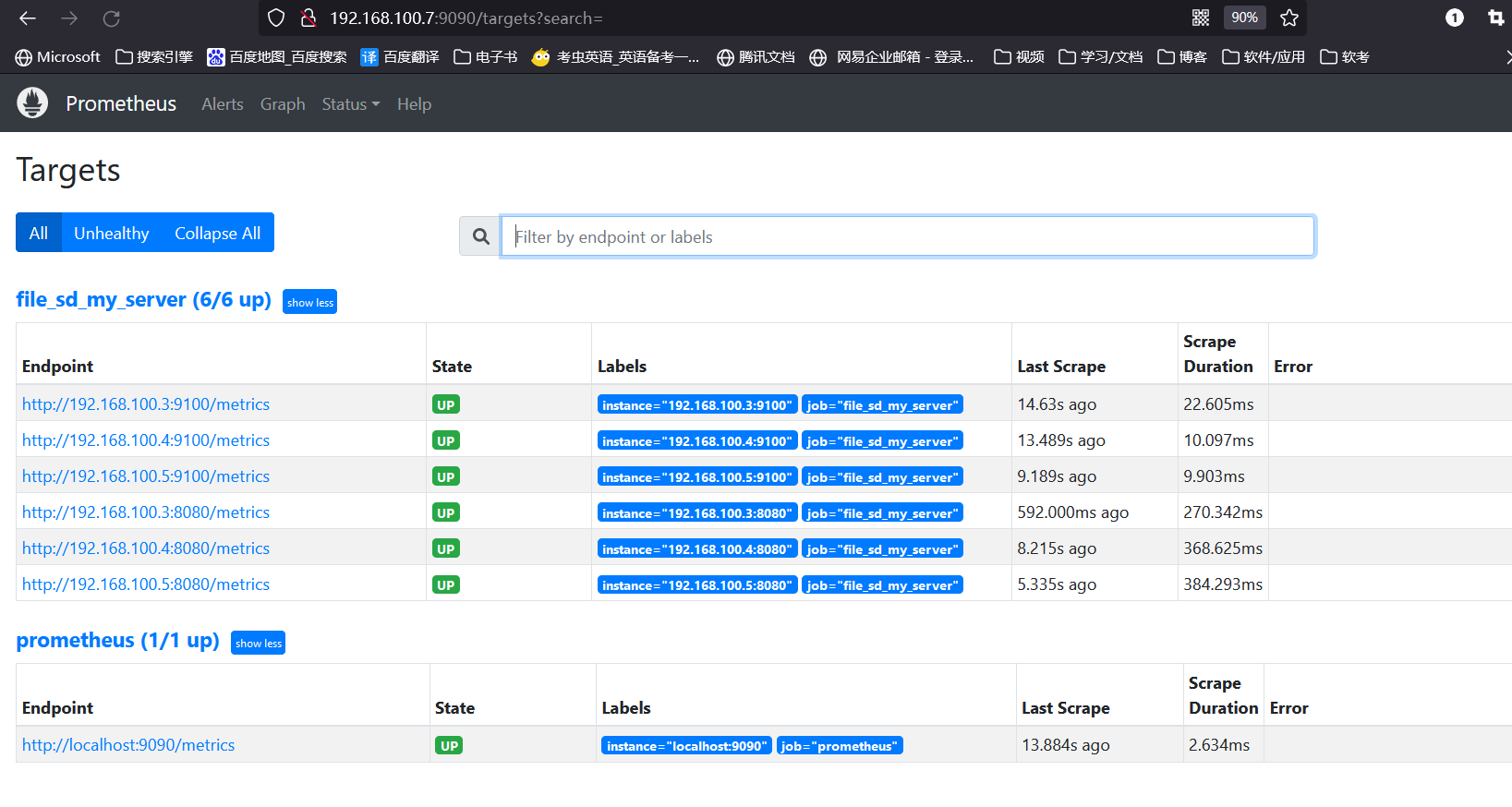
- job_name: "file_sd_my_server"
file_sd_configs:
- files:
- /usr/local/prometheus/file_sd/target.json #服务发现node-exporter
- /usr/local/prometheus/file_sd/cadvisor.json #服务发现cadvisor
refresh_interval: 10s #间隔10s从文件服务发现,默认5min
浏览器访问prometheus-server验证
DNS服务发现
https://prometheus.io/docs/prometheus/latest/configuration/configuration/#dns_sd_config
基于 DNS 的服务发现允许配置指定一组 DNS 域名,这些域名会定期查询以发现目标列表,域名需要可以被配置的 DNS 服务器解析为 IP。
此服务发现方法仅支持基本的 DNS A、AAAA 和 SRV 记录查询。
A 记录: 域名解析为 IP
SRV:SRV 记录了哪台计算机提供了具体哪个服务,格式为:自定义的服务的名字.协议的类型.域名(例如:_example-server._tcp.www.mydns.com)
prometheus 会对收集的指标数据进行重新打标,重新标记期间,可以使用以下元标签:
__meta_dns_name:产生发现目标的记录名称。
__meta_dns_srv_record_target: SRV 记录的目标字段
__meta_dns_srv_record_port: SRV 记录的端口字段
A记录服务发现
在prometheus-server添加hosts本地解析,模拟dns服务器
root@prometheus:~\# vim /etc/hosts
192.168.100.3 k8s.node1
192.168.100.4 k8s.node2
修改prometheus-server配置文件
root@prometheus:~\# cd /usr/local/prometheus
root@prometheus:/usr/local/prometheus# cat prometheus.yml
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: "prometheus"
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ["localhost:9090"]
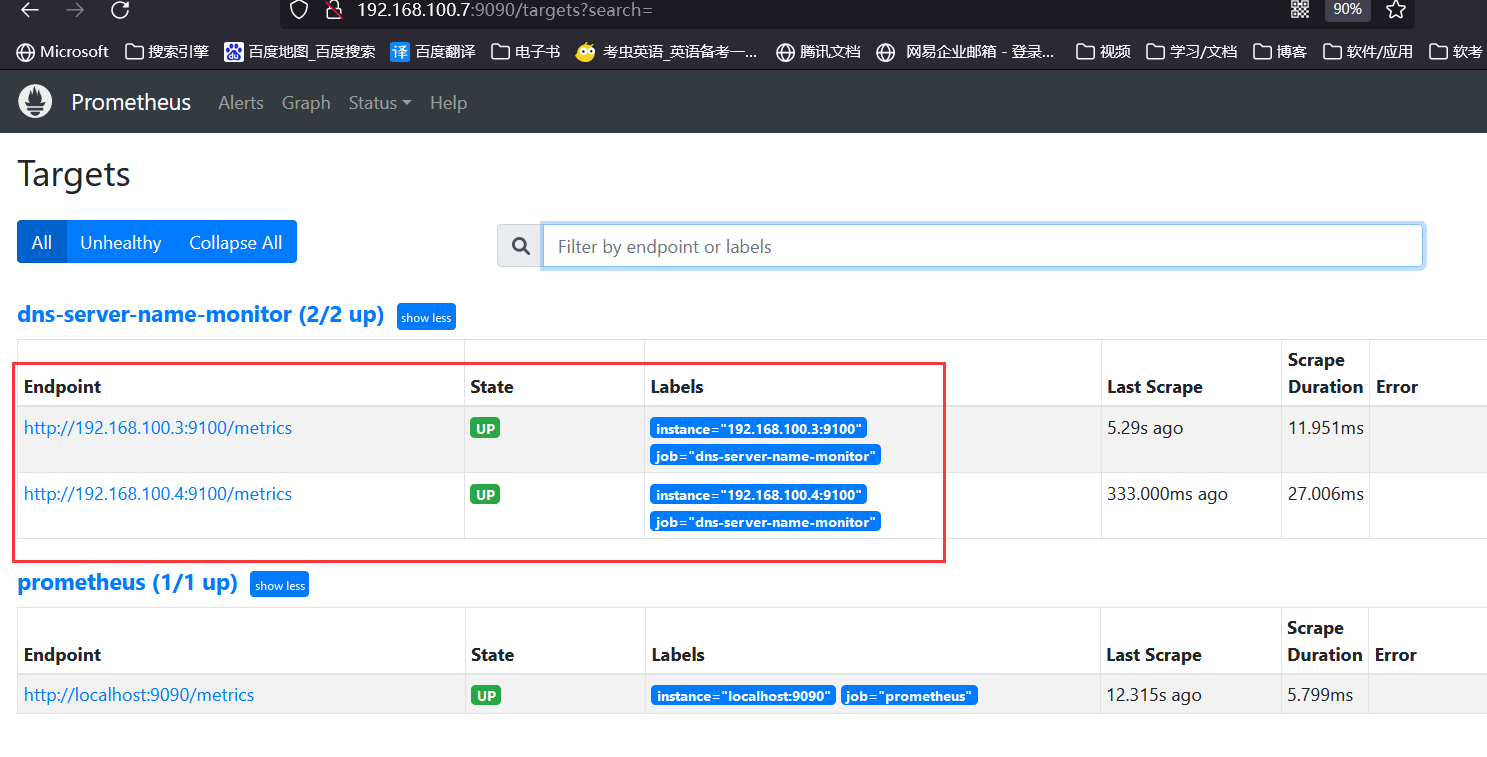
- job_name: 'dns-server-name-monitor'
metrics_path: "/metrics"
dns_sd_configs:
- names: ["k8s.node1", "k8s.node2"] #指定target监控节点
type: A #类型为A记录
port: 9100 #指定target node-exporter端口号
refresh_interval: 15s #间隔15s刷新发现服务,默认30s
SRV 服务发现
需要有 DNS 服务器实现域名解析
- job_name: 'dns-node-monitor-srv'
metrics_path: "/metrics"
dns_sd_configs:
- names: ["_prometheus._tcp.node.example.com"]
type: SRV
port: 9100
refresh_interval: 15s
kube-state-metrics 组件
github项目地址:https://github.com/kubernetes/kube-state-metrics
Kube-state-metrics: 通过监听 API Server 生成有关资源对象的状态指标,比如 Deployment、Node、Pod,需要注意的是 kube-state-metrics 的使用场景不是用于监控对方是否存活,而是用于周期性获取目标对象的 metrics 指标数据并在 web 界面进行显示或被 prometheus 抓取(如 pod 的状态是 running 还是 Terminating、 pod 的创建时间等) ,目前的 kube-state-metrics 收集的指标数据可参见官方的文档 ,https://github.com/kubernetes/kube-state-metrics/tree/master/docs ,并不会存储这些指标数据,所以可以使用 Prometheus 来抓取这些数据然后存储,主要关注的是业务相关的一些元数据,比如 Deployment、Pod、副本状态等,调度了多少个 replicas?现在可用的有几个?多少个 Pod 是 running/stopped/terminated 状态?Pod 重启了多少次?目前有多少 job 在运行中。
官方的定义:
kube-state-metrics is a simple service that listens to the Kubernetes API server and generates metrics about the state of the objects.
镜像名称:
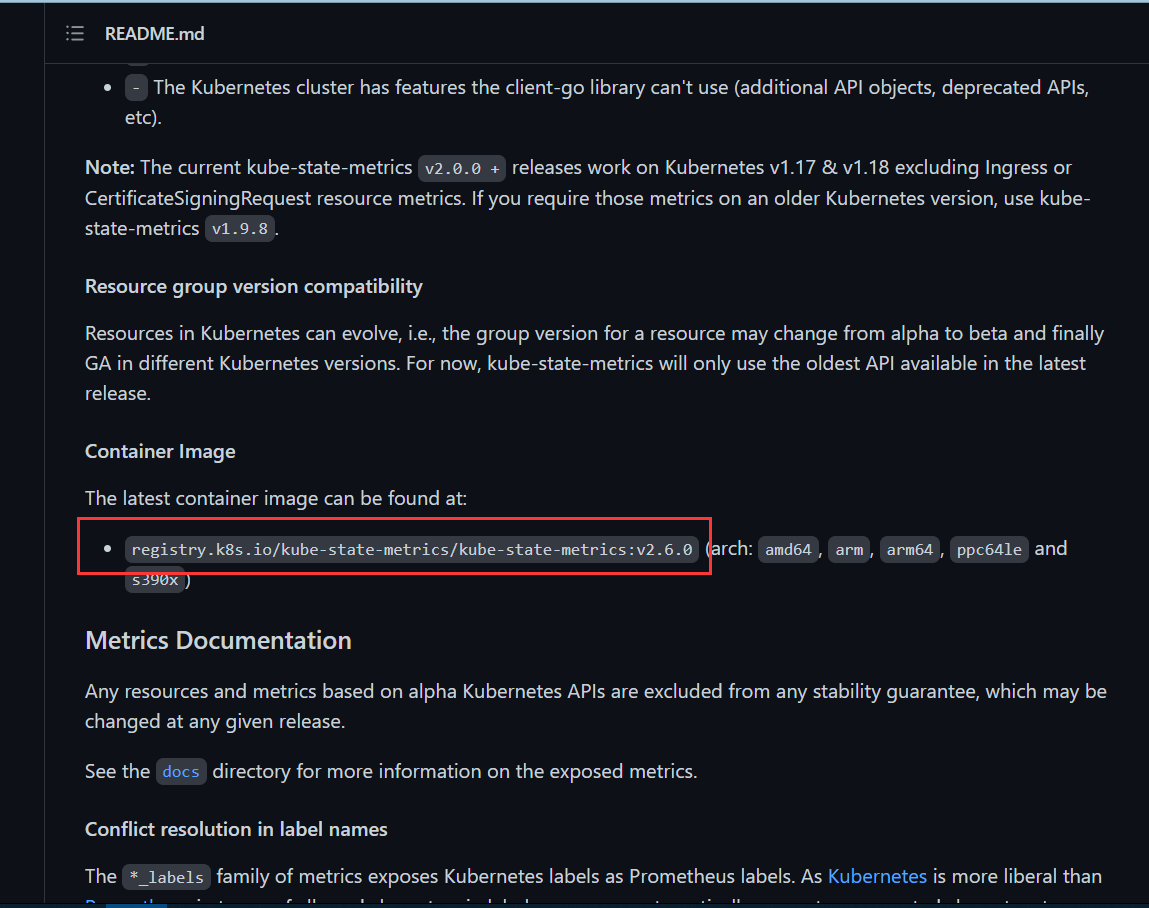
将官方镜像替换镜像为阿里云镜像
registry.k8s.io/kube-state-metrics/kube-state-metrics:v2.6.0
registry.cn-hangzhou.aliyuncs.com/liangxiaohui/kuberntes-state-metrics:v2.6.0
部署kube-state-metric
root@master1:~/yaml# cat kube-state-metrics-deploy.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: kube-state-metrics
namespace: kube-system
spec:
replicas: 1
selector:
matchLabels:
app: kube-state-metrics
template:
metadata:
labels:
app: kube-state-metrics
spec:
serviceAccountName: kube-state-metrics
containers:
- name: kube-state-metrics
image: registry.cn-hangzhou.aliyuncs.com/liangxiaohui/kuberntes-state-metrics:v2.6.0
ports:
- containerPort: 8080
---
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: kube-state-metrics
namespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: kube-state-metrics
rules:
- apiGroups: [""]
resources: ["nodes", "pods", "services", "resourcequotas", "replicationcontrollers", "limitranges", "persistentvolumeclaims", "persistentvolumes", "namespaces", "endpoints"]
verbs: ["list", "watch"]
- apiGroups: ["extensions"]
resources: ["daemonsets", "deployments", "replicasets"]
verbs: ["list", "watch"]
- apiGroups: ["apps"]
resources: ["statefulsets"]
verbs: ["list", "watch"]
- apiGroups: ["batch"]
resources: ["cronjobs", "jobs"]
verbs: ["list", "watch"]
- apiGroups: ["autoscaling"]
resources: ["horizontalpodautoscalers"]
verbs: ["list", "watch"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: kube-state-metrics
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: kube-state-metrics
subjects:
- kind: ServiceAccount
name: kube-state-metrics
namespace: kube-system
---
apiVersion: v1
kind: Service
metadata:
annotations:
prometheus.io/scrape: 'true'
name: kube-state-metrics
namespace: kube-system
labels:
app: kube-state-metrics
spec:
type: NodePort
ports:
- name: kube-state-metrics
port: 8080
targetPort: 8080
nodePort: 31666
protocol: TCP
selector:
app: kube-state-metrics
root@master1:~/yaml\# kubectl get pods -n kube-system |grep kube-state-metrics
kube-state-metrics-55c776795d-chvg8 1/1 Running 0 3m31s
k8s内置prometheus-server配置采集指标
root@master1:~/yaml# vim prometheus-cfg.yml
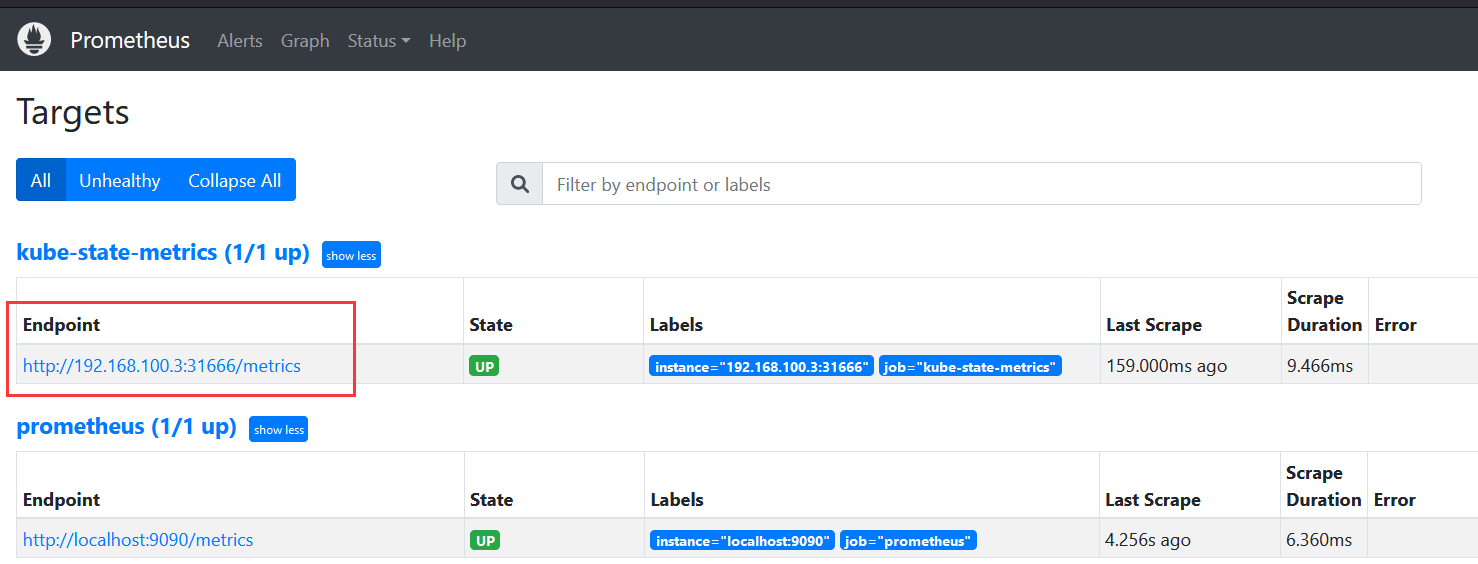
- job_name: "kube-state-metrics"
static_configs:
- targets: ["192.168.100.3:31666"]
root@master1:~/yaml# kubectl apply -f prometheus-cfg.yaml
root@master1:~/yaml# kubectl delete pods prometheus-server-84c8755ccc-tgwm6 #重启pod
浏览器访问验证
grafana导入dashboard模板
ID:13824
master和node节点数量的指标修改
count(node_load1{kubernetes_io_role="master"})
count(node_load1{kubernetes_io_role="node"})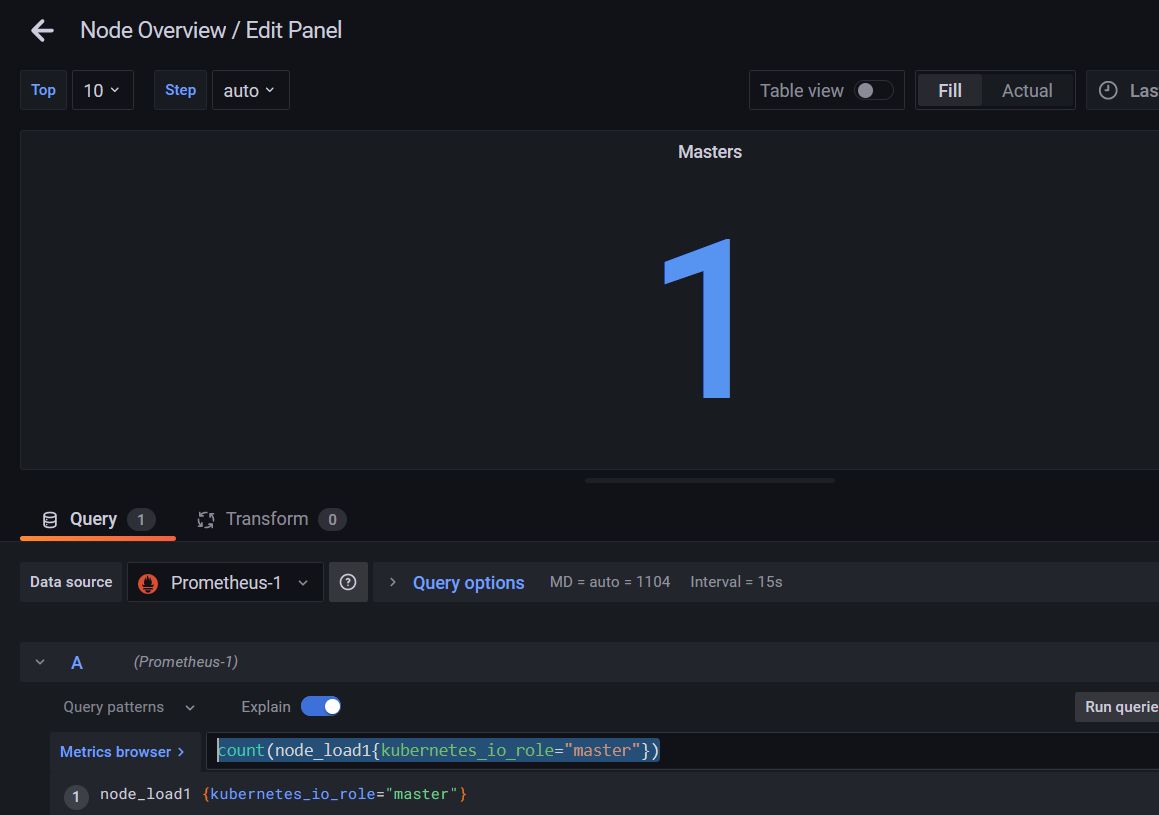

ID:14518
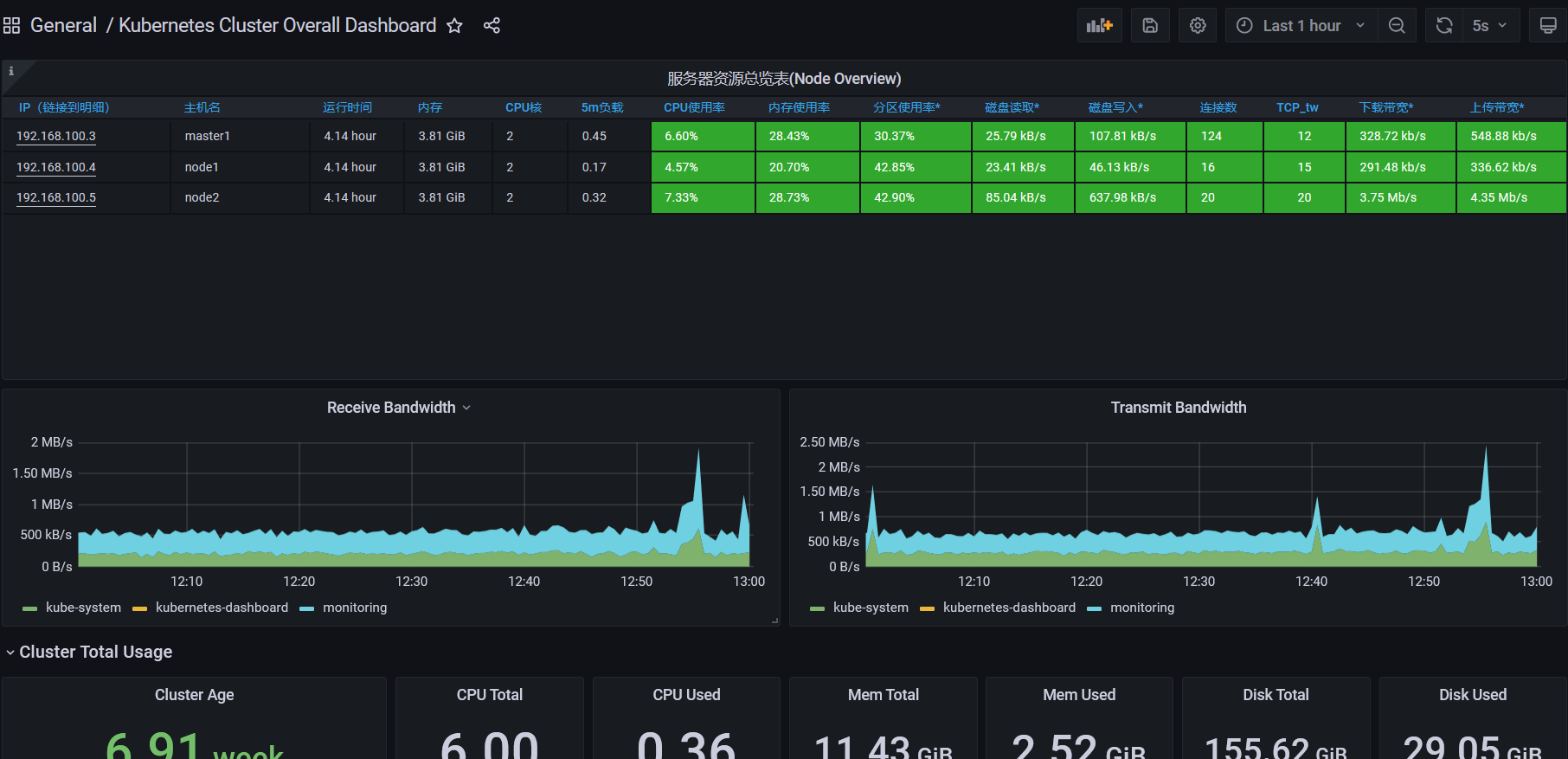
本文来自博客园,作者:PunchLinux,转载请注明原文链接:https://www.cnblogs.com/punchlinux/p/16773486.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号