部署ELK及kafka日志收集k8s容器环境
部署zookeeper
准备三个节点系统并安装jdk
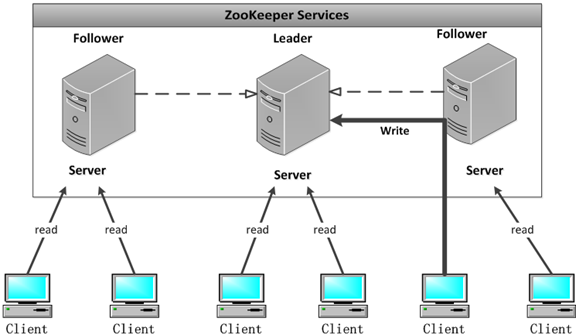
结构图:
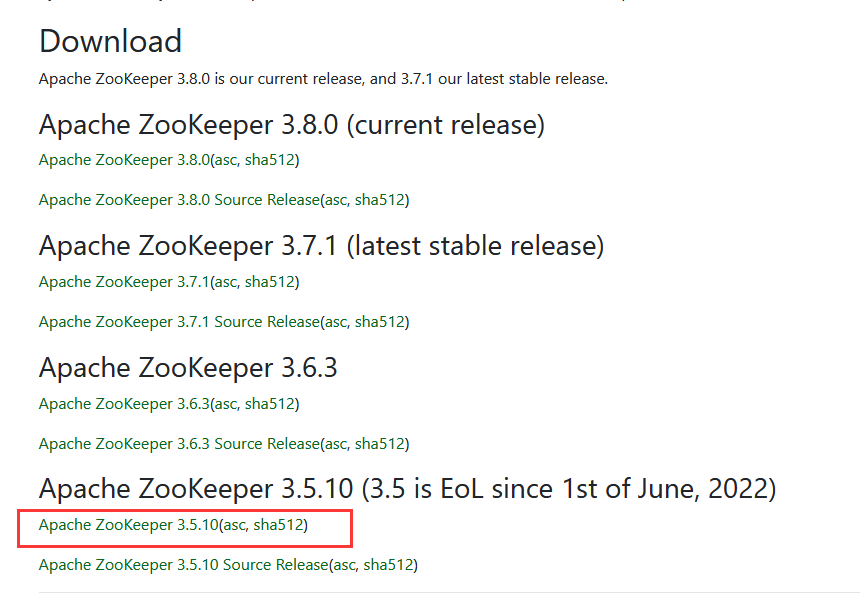
官网下载地址:
https://zookeeper.apache.org/releases.html
安装JDK环境
部署zookeeper节点1
[root@zookeeper1 bin]# vim /etc/profile
export ZOOKEEPER_HOME=/usr/local/zookeeper-3.5.10
export PATH=$JAVA_HOME/bin:$JRE_HOME/bin:$ZOOKEEPER_HOME/bin:$PATH
[root@zookeeper1 local]# tar xf apache-zookeeper-3.5.10-bin.tar.gz
[root@zookeeper1 local]# mv apache-zookeeper-3.5.10-bin zookeeper-3.5.10
[root@zookeeper1 local]# cd zookeeper-3.5.10/
#创建myid
[root@zookeeper2 zookeeper-3.5.10]# mkdir {data,logs}
[root@zookeeper3 zookeeper-3.5.10]# cd data/
[root@zookeeper data]# echo 0 > myid
#配置文件
[root@zookeeper1 bin]# cd ../conf/
[root@zookeeper1 conf]# cp zoo_sample.cfg zoo.cfg
[root@zookeeper1 conf]# vim zoo.cfg
dataDir=/usr/local/zookeeper-3.5.10/data
dataLogDir=/usr/local/zookeeper-3.5.10/logs
clientPort=2181
server.0=192.168.119.100:2288:3388
server.1=192.168.119.101:2288:3388
server.2=192.168.119.102:2288:3388
#启动
[root@zookeeper1 bin]# zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper-3.5.10/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[root@zookeeper1 bin]# lsof -i:2181
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
java 3100 root 52u IPv6 31864 0t0 TCP *:eforward (LISTEN)
部署zookeeper节点2
配置文件一致,创建data和logs目录并创建myid
[root@zookeeper2 ~]# mkdir -p /usr/local/zookeeper-3.5.10/{data,logs}
[root@zookeeper2 ~]# echo 1 > /usr/local/zookeeper-3.5.10/data/myid
[root@zookeeper2 ~]# cd /usr/local/zookeeper-3.5.10/conf/
[root@zookeeper2 conf]# scp root@192.168.119.100:/usr/local/zookeeper-3.5.10/conf/zoo.cfg ./
[root@zookeeper2 conf]# zkServer.sh start
部署zookeeper节点3
配置文件一致,创建data和logs目录并创建myid
[root@zookeeper3 ~]# mkdir -p /usr/local/zookeeper-3.5.10/{data,logs}
[root@zookeeper3~]# echo 2 > /usr/local/zookeeper-3.5.10/data/myid
[root@zookeeper3 ~]# cd /usr/local/zookeeper-3.5.10/conf/
[root@zookeeper3 conf]# scp root@192.168.119.100:/usr/local/zookeeper-3.5.10/conf/zoo.cfg ./
[root@zookeeper3 conf]# zkServer.sh start
查看各个节点zookeeper状态
[root@zookeeper conf]# for n in {100..102};do ssh 192.168.119.$n "sh /usr/local/zookeeper-3.5.10/bin/zkServer.sh status";done
/usr/bin/java
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper-3.5.10/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost. Client SSL: false.
Mode: follower
/usr/bin/java
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper-3.5.10/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost. Client SSL: false.
Mode: leader
/usr/bin/java
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper-3.5.10/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost. Client SSL: false.
Mode: follower
部署Kafka
官网下载:
https://kafka.apache.org/downloads.html
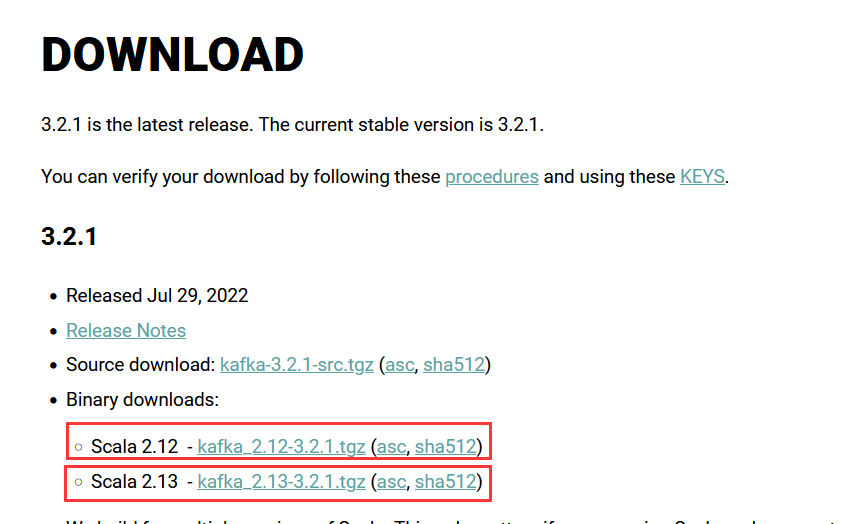
解压
[root@zookeeper1 local]# tar xf kafka_2.12-3.0.0.tgz
[root@zookeeper1 local]# ln -s kafka_2.12-3.0.0 kafka
目录介绍
[root@zookeeper1 local]# cd kafka
[root@zookeeper1 kafka]# ll
total 64
drwxr-xr-x 3 root root 4096 Sep 9 2021 bin #启动脚本
drwxr-xr-x 3 root root 4096 Sep 9 2021 config #配置文件
drwxr-xr-x 2 root root 8192 Aug 11 15:35 libs #第三方扩展jar包
-rw-r--r-- 1 root root 14521 Sep 9 2021 LICENSE
drwxr-xr-x 2 root root 262 Sep 9 2021 licenses
-rw-r--r-- 1 root root 28184 Sep 9 2021 NOTICE
drwxr-xr-x 2 root root 44 Sep 9 2021 site-docs
配置主机名解析,否则本地kafka连接失败
[root@zookeeper1 config]# cat /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.100.101 zookeeper1
192.168.100.102 zookeeper2
192.168.100.103 zookeeper3
配置kafka server1服务端
[root@zookeeper1 kafka]# cd config/
[root@zookeeper1 config]# vim server.properties
#broker 的全局唯一编号,每个kafka节点不能重复,只能是数字。
broker.id=0
#处理网络请求的线程数量
num.network.threads=3
#用来处理磁盘IO的线程数量
num.io.threads=8
#发送套接字的缓冲区大小
socket.send.buffer.bytes=102400
#接收套接字的缓冲区大小
socket.receive.buffer.bytes=102400
#请求套接字的缓冲区大小
socket.request.max.bytes=104857600
#kafka 运行日志(数据)存放的路径,路径不需要提前创建,kafka自动创建,可以配置多个磁盘路径,路径与路径之间可以用","分隔
log.dirs=/usr/local/kafka/data
#topic 在当前broker上的分区个数
num.partitions=1
#用来恢复和清理data下数据的线程数量
num.recovery.threads.per.data.dir=1
#每个topic创建时的副本数,默认时1个副本
offsets.topic.replication.factor=1
#segment文件保留的最长时间,超时将被删除
log.retention.hours=168
#每个segment文件的大小,默认最大1G
log.segment.bytes=1073741824
#检查过期数据的时间,默认5分钟检查一次是否数据过期
log.retention.check.interval.ms=300000
#配置连接Zookeeper集群地址(在zk根目录下创建/kafka,方便管理)
zookeeper.connect=zookeeper1:2181,zookeeper2:2181,zookeeper3:2181/kafka
创建kafka数据目录
[root@zookeeper1 kafka]# mkdir /usr/local/kafka/data
设置kafka环境变量
[root@zookeeper1 kafka]# vim /etc/profile
#kafka
export KAFKA_HOME=/usr/local/kafka
export PATH=$PATH:$KAFKA_HOME/bin
[root@zookeeper1 kafka]# . /etc/profile
配置其他server节点,修改broker.id即可,其他配置保持一致
配置kafka server2服务端
[root@zookeeper1 kafka]# cd config/
[root@zookeeper1 config]# vim server.properties
#broker 的全局唯一编号,每个kafka节点不能重复,只能是数字。
broker.id=1
配置kafka server3服务端
[root@zookeeper1 kafka]# cd config/
[root@zookeeper1 config]# vim server.properties
#broker 的全局唯一编号,每个kafka节点不能重复,只能是数字。
broker.id=2
启动和关闭kafka server
启动kafka服务端前,必须安装和启动zookeeper。
启动kafka server。所有节点kafka都启动
[root@zookeeper1 kafka]# kafka-server-start.sh -daemon /usr/local/kafka/config/server.propertieskafka-server-start.sh #kafka服务端启动脚本
-daemon #后台启动
server.properties #指定kafka服务端配置文件路径
关闭kafka server
[root@zookeeper1 kafka]# kafka-server-stop.sh
部署Elasticsearch
官网下载ES的RPM包
https://www.elastic.co/cn/downloads/elasticsearch
node1配置
[root@els elasticsearch]# vim /etc/elasticsearch/elasticsearch.yml
cluster.name: cluster1 #集群名称,同一集群内所有节点名称要一模一样
node.name: node-1 #节点名称,同一集群内所有节点的名称不能重复
path.data: /data/elasticsearch #修改es数据存储位置,建议是存储在数据盘
path.logs: /var/log/elasticsearch #修改es日志存储路径
network.host: 192.168.100.70 #监听在哪个IP地址,建议是内网网卡地址
http.port: 9200 #监听端口
discovery.seed_hosts: ["192.168.100.70", "192.168.100.71", "192.168.100.72"]
#集群发现节点配置,如果集群节点较多,可以只填写主节点和本机地址
cluster.initial_master_nodes: ["192.168.100.70", "192.168.100.71", "192.168.100.72"]
#在首次初始化集群启动时,参与选举master的节点。(仅在第一次启动)
action.destructive_requires_name: true
#禁止ES批量通配删除索引,每次删除精确指定索引名称
将配置文件拷贝到其他节点服务器上:
[root@es1 ~]# scp /etc/elasticsearch/elasticsearch.yml 192.168.100.71: /etc/elasticsearch/
node2修改配置
从节点1拷贝过来的es配置文件需要修改用户组权限
[root@es2 elasticsearch]# chown -R root.elasticsearch elasticsearch.yml[root@els2 elasticsearch]# vim /etc/elasticsearch/elasticsearch.yml
cluster.name: cluster1
network.host: 192.168.100.71
node.name: node-2
discovery.zen.ping.unicast.hosts: ["192.168.100.70", "192.168.100.71", "192.168.100.72"]
node3修改配置
从节点1拷贝过来的es配置文件需要修改用户组权限
[root@es3 elasticsearch]# chown -R root.elasticsearch elasticsearch.yml[root@els2 elasticsearch]# vim /etc/elasticsearch/elasticsearch.yml
cluster.name: cluster1
network.host: 192.168.100.72
node.name: node-3
discovery.zen.ping.unicast.hosts: ["192.168.100.70", "192.168.100.71", "192.168.100.72"]
启动服务
所有节点执行
systemctl start elasticsearch.service
安装es-head
查看ES数据方便,操作相对容易,需要nodejs环境
github下载地址
https://github.com/mobz/elasticsearch-head/releases
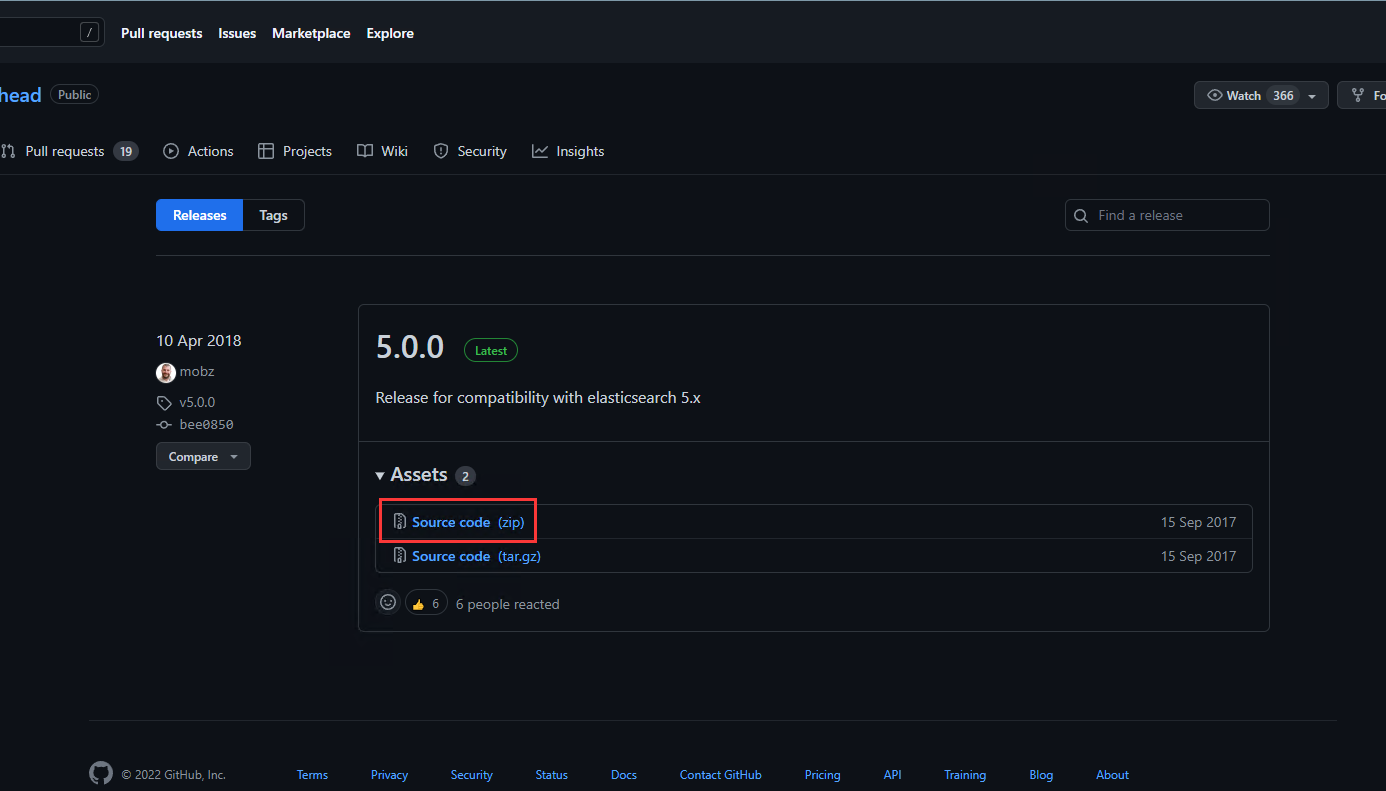
安装es-head
修改elasticsearch.yml的配置
#设置跨越可以访问
http.cors.enabled: true
http.cors.allow-origin: "*"
下载nodejs
https://nodejs.org/en/download/
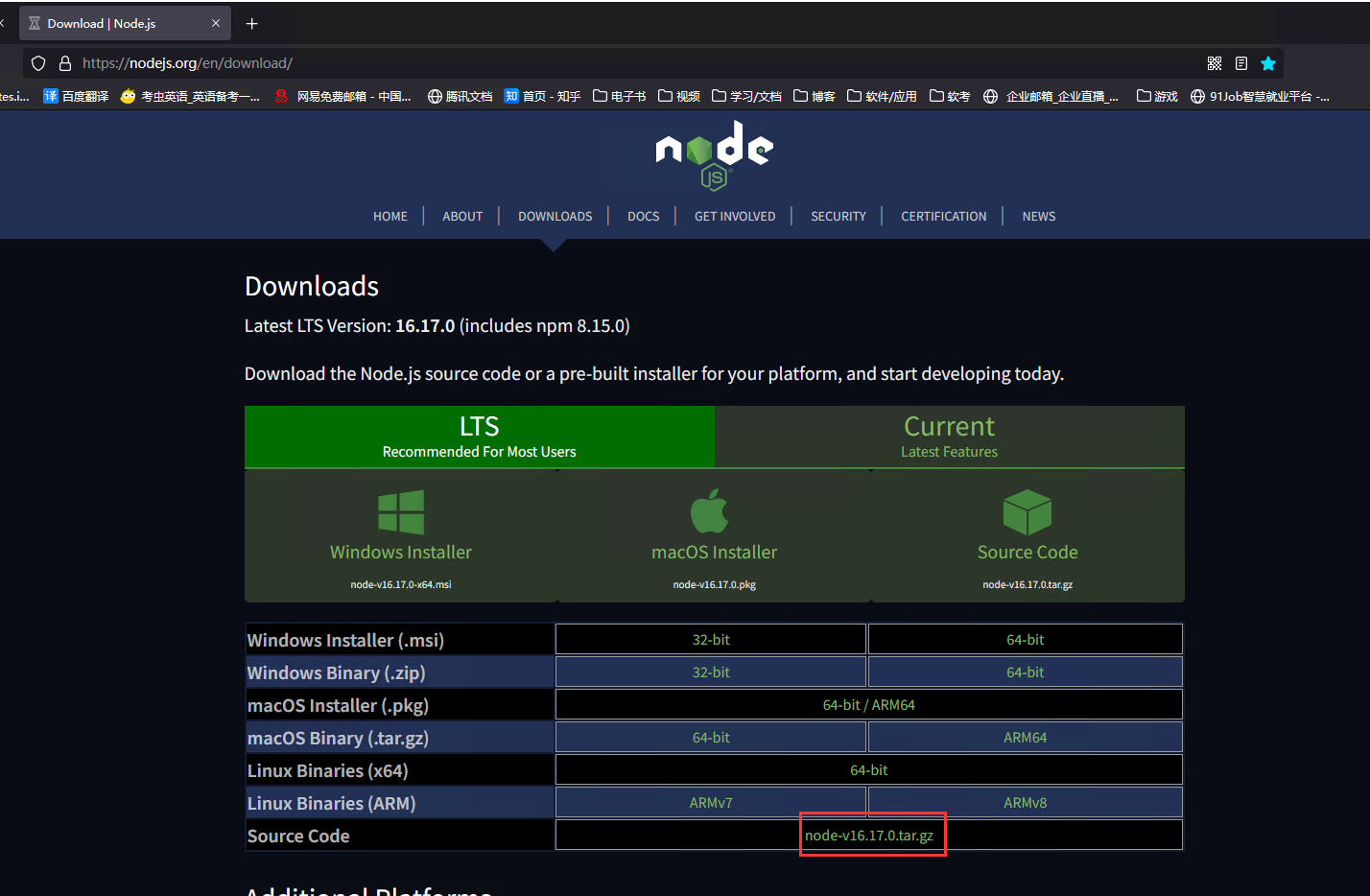
安装es-head
#[root@zookeeper1 es-head]#wget https://npm.taobao.org/mirrors/node/latest-v4.x/node-v4.4.7-linux-x64.tar.gz
[root@zookeeper1 local]# unzip elasticsearch-head-5.0.0.zip
[root@zookeeper1 es-head]# mv elasticsearch-head-master /opt/es-head
[root@zookeeper1 local]# tar xf node-v16.15.1-linux-x64.tar.xz
[root@zookeeper1 es-head]# mv node-v16.15.1-linux-x64 /opt/node
添加nodejs环境变量
[root@ zookeeper1 es-head]#vim /etc/profile
export NODE_HOME=/opt/node
export PATH=$PATH:$NODE_HOME/bin
export NODE_PATH=$NODE_HOME/lib/node_modules
设置npm阿里云镜像加速
[root@zookeeper1 es-head]# npm config set registry https://registry.npmmirror.com
安装npm、yarn和grunt-cli
[root@zookeeper1 packages]# cd /opt/es-head/
[root@zookeeper1 es-head]# npm install -g npm
[root@zookeeper1 es-head]# npm install -g grunt-cli
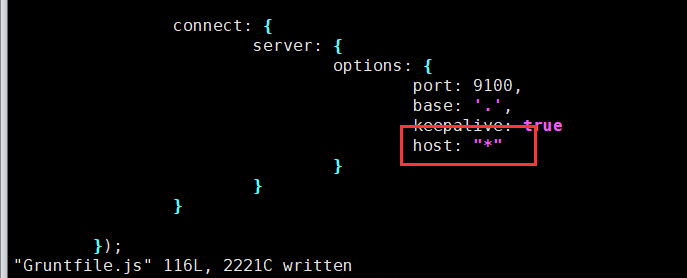
修改Gruntfile.js文件设置es-head开放监听
[root@zookeeper1 es-head]# grunt -version
grunt-cli v1.4.3
[root@zookeeper1 es-head]# vim Gruntfile.js
connect: {
server: {
options: {
port: 9100,
base: '.',
keepalive: true,
host: "*"
}
修改app.js脚本指定es服务地址和端口
[root@zookeeper1 es-head]# vim _site/app.js
执行npm install安装npm模块
[root@zookeeper1es-head]# npm install
安装失败:
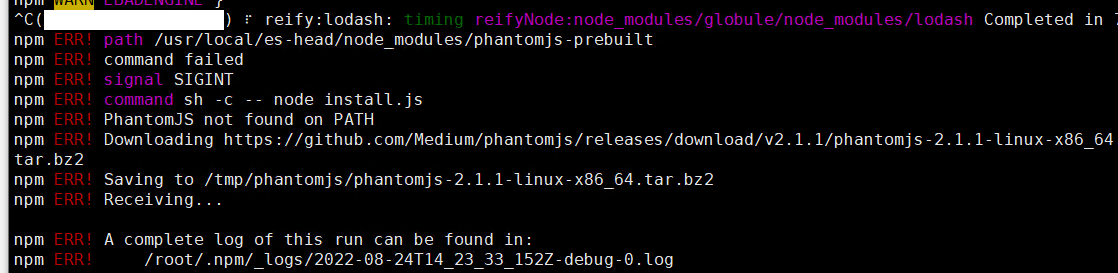
解决方法:
手动下载phantomjs-2.1.1-linux-x86_64.tar.bz2,到提示目录
[root@zookeeper1 es-head]# cd /tmp/phantomjs/
[root@zookeeper1 es-head]#weget https://bitbucket.org/ariya/phantomjs/downloads/phantomjs-2.1.1-linux-x86_64.tar.bz2
启动es-head
[root@zookeeper1 es-head]#grunt server &
Running "connect:server" (connect) task
Waiting forever...
Started connect web server on http://localhost:9100
通过浏览器访问“本地地址:9100”访问页面
添加es-head启动脚本
[root@zookeeper1 ~]# vim /usr/local/bin/grunt.sh
#!/bin/bash
cd /usr/local/es-head/
grunt server &
安装kibana
[root@es1 ~]# rpm -ivh kibana-7.12.1-x86_64.rpm
配置kibana
[root@kibana ~]# grep "^[a-Z]" /etc/kibana/kibana.yml
server.port: 5601 #kibana默认监听端口
server.host: "192.168.100.73" #kibana监听地址段
server.name: "kibana" #kibana主机名
elasticsearch.hosts: ["http://192.168.100.101:9200","http://192.168.100.102:9200"] #ES地址,kibana丛 es节点获取数据
i18n.locale: "zh-CN" #kibana汉化
启动kibana
[root@es1 ~]# systemctl start kibana
配置收集k8s容器日志
1、containerd容器日志路径及日志配置
日志路径:/var/log/pods/$CONTAINER_NAMEs;
同时kubelet也会在/var/log/containers目录下创建软链接指向/var/log/pods/$CONTAINER_NAMEs
日志配置参数
配置文件
/etc/systemd/system/kubelet.service
配置参数:
- --container-log-max-files=5 \
--container-log-max-size="100Mi" \
--logging-format="json" \
2、docker容器日志路径即日志配置
日志路径:/var/lib/docker/containers/$CONTAINERID
同时kubelet会在/var/log/pods和/var/log/containers创建软连接指向/var/lib/docker/containers/$CONTAINERID
日志配置参数
配置文件
/etc/docker/daemon.json
配置参数:
"log-driver": "json-file",
"log-opts": {
"max-file": "5",
"max-size": "100m"
}
基于daemonset收集日志
基于daemonset运行日志收集服务,主要收集以下类型日志:
1、k8s的node节点收集,基于daemonset部署日志收集进程,实现json-file类型(标准输出/dev/stdout、错误输出/dev/stderr)日志收集,即应用程序产生的标准输出和错误输出的日志。
2、k8s宿主机系统日志等以日志文件形式保存的日志
流程图
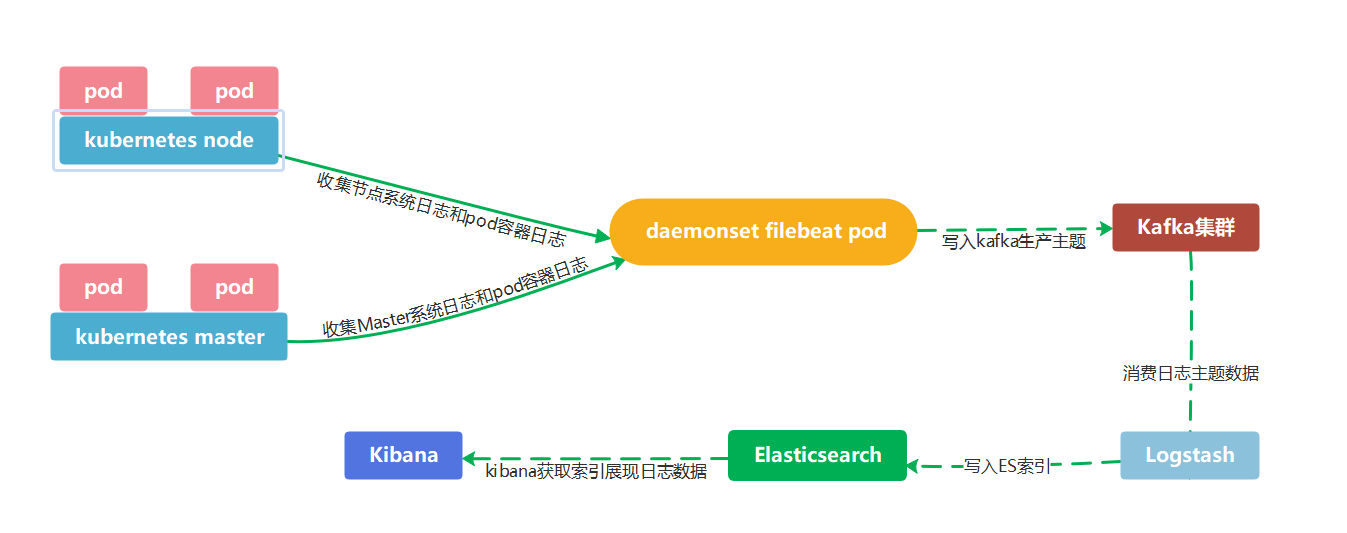
1、使用filebeat收集日志
容器节点部署filebeat容器,监听所有容器和宿主机的日志
配置filebeat
root@deploy:/dockerfile/project/elk# cat filebeat.yml
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/*.log
tags: ["syslog"]
- type: log
enabled: true
paths:
- /var/log/pods/*/*/*.log
tags: ["applog"]
output.kafka:
hosts: ${KAFKA_SERVER} #逗号分隔多个kafka集群
topic: ${TOPIC_ID}
partition.round_robin:
reachable_only: false
required_acks: 1
compression: gzip
max_message_bytes: 1000000
创建filebeat dockerfile
root@deploy:/dockerfile/project/elk# cat Dockerfile
FROM elastic/filebeat:7.12.1
USER root
WORKDIR /usr/share/filebeat
ADD filebeat.yml /usr/share/filebeat/
构建容器脚本:
root@deploy:/dockerfile/project/elk# cat build.sh
#!/bin/bash
TAG=$1
docker build -t harbor.cncf.net/project/filebeat-kafka:${TAG} .
docker push harbor.cncf.net/project/filebeat-kafka:${TAG}
创建filebeat k8s yaml资源
root@deploy:/dockerfile/project/elk# cat daemonset-filebeat.yaml
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: filebeat-elasticsearch
namespace: kube-system
labels:
k8s-app: filebeat-logging
spec:
selector:
matchLabels:
name: filebeat-elasticsearch
template:
metadata:
labels:
name: filebeat-elasticsearch
spec:
tolerations:
# this toleration is to have the daemonset runnable on master nodes
# remove it if your masters can't run pods
- key: node-role.kubernetes.io/master
operator: Exists
effect: NoSchedule
containers:
- name: filebeat-elasticsearch
image: harbor.cncf.net/project/filebeat-kafka:1.0.6
env:
- name: "KAFKA_SERVER"
value: "192.168.100.101:9092,192.168.100.102:9092,192.168.100.103:9092"
- name: "TOPIC_ID"
value: "elklog"
# resources:
# limits:
# cpu: 1000m
# memory: 1024Mi
# requests:
# cpu: 500m
# memory: 1024Mi
volumeMounts:
- name: varlog #定义宿主机系统日志挂载路径
mountPath: /var/log #宿主机系统日志挂载点
- name: varlibdockercontainers #定义容器日志挂载路径,和filebeat配置文件中的收集路径保持一直
#mountPath: /var/lib/docker/containers #docker挂载路径
mountPath: /var/log/pods #containerd挂载路径,此路径与filebeat的日志收集路径必须一致
readOnly: false
terminationGracePeriodSeconds: 30
volumes:
- name: varlog
hostPath:
path: /var/log #宿主机系统日志
- name: varlibdockercontainers
hostPath:
#path: /var/lib/docker/containers #docker的宿主机日志路径
path: /var/log/pods #containerd的宿主机日志路径
root@deploy:/dockerfile/project/elk# kubectl apply –f daemonset-filebeat.yaml
创建容器
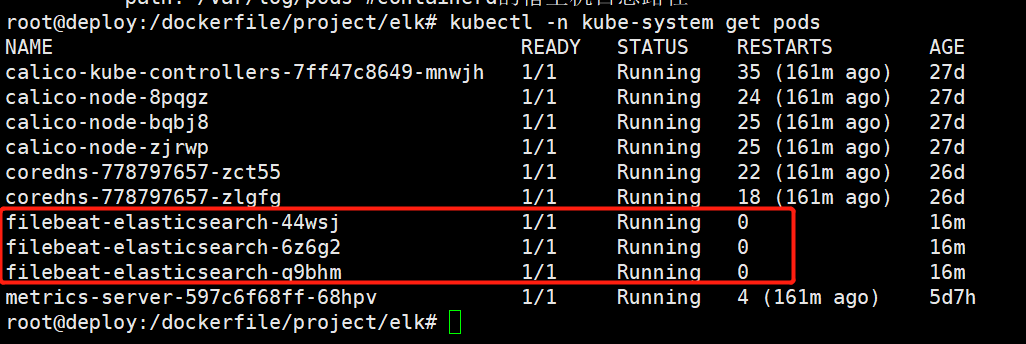
2、从kafka集群中查看验证filebeat收集的日志
使用kafkatools查看从filebeat收集日志后调用kafka创建的主题数据
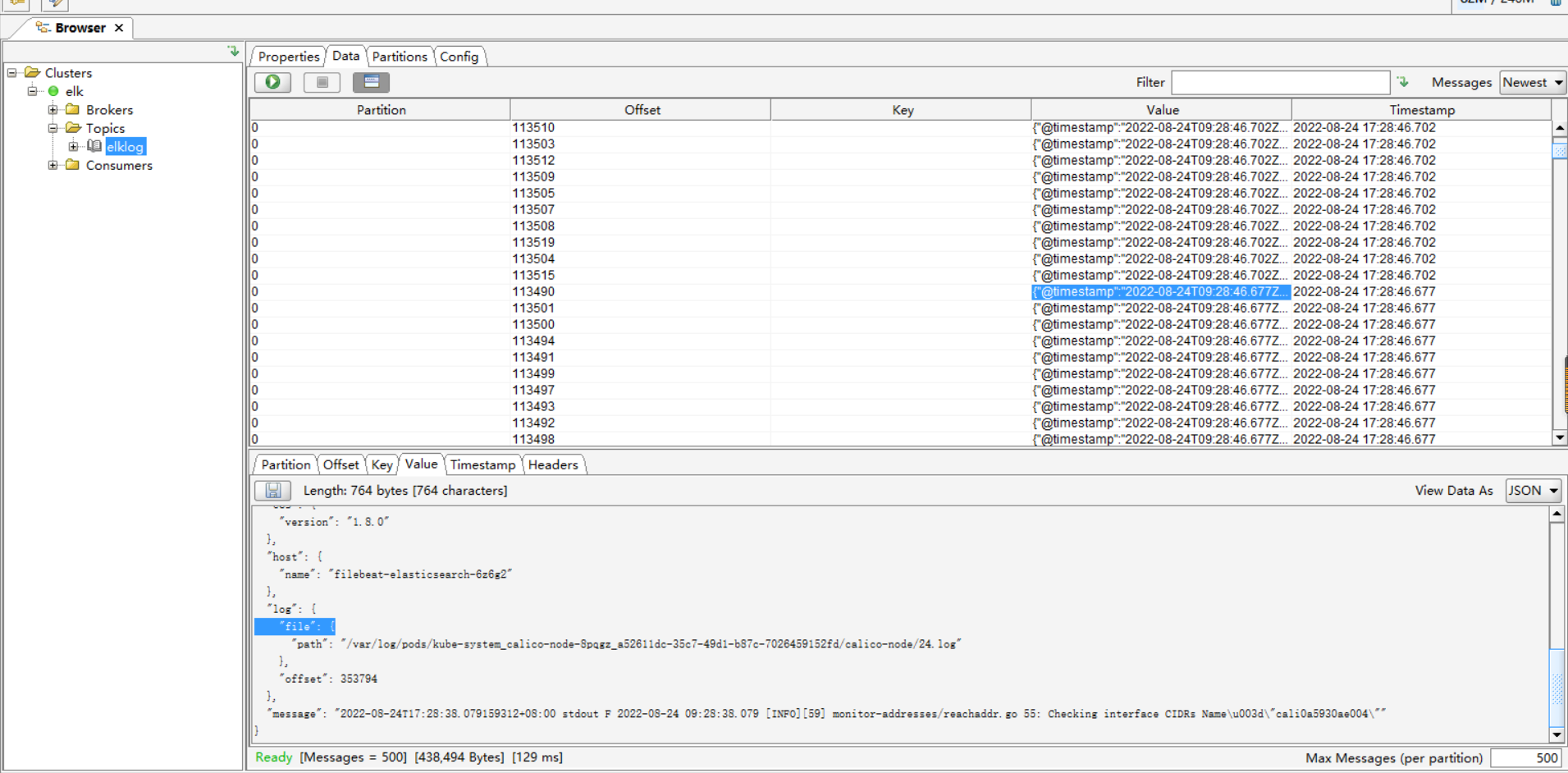
3、配置和部署logstash
logstash节点安装和配置从kafka集群主题获取日志数据
root@kibana:~# cat /etc/logstash/conf.d/k8s_log.conf
input {
kafka {
bootstrap_servers => "192.168.100.101:9092,192.168.100.102:9092,192.168.100.103:9092" #生产者kafka地址
topics => ["elklog"] #消费主题
codec => "json"
}
}
output {
if "syslog" in [tags] {
elasticsearch {
hosts => ["http://192.168.100.70:9200","192.168.100.71:9200"]
manage_template => false
index => "syslog-%{+yyyy.MM.dd}"
}
}
if "applog" in [tags] {
elasticsearch {
hosts => ["http://192.168.100.70:9200","192.168.100.71:9200"]
manage_template => false
index => "applog-%{+yyyy.MM.dd}"
}
}
}
启动logstash
root@kibana:~# systemctl start logstash.service
root@kibana:~# systemctl enable logstash.service
查看logstash启动日志
root@kibana:~# tail -f /var/log/logstash/logstash-plain.log 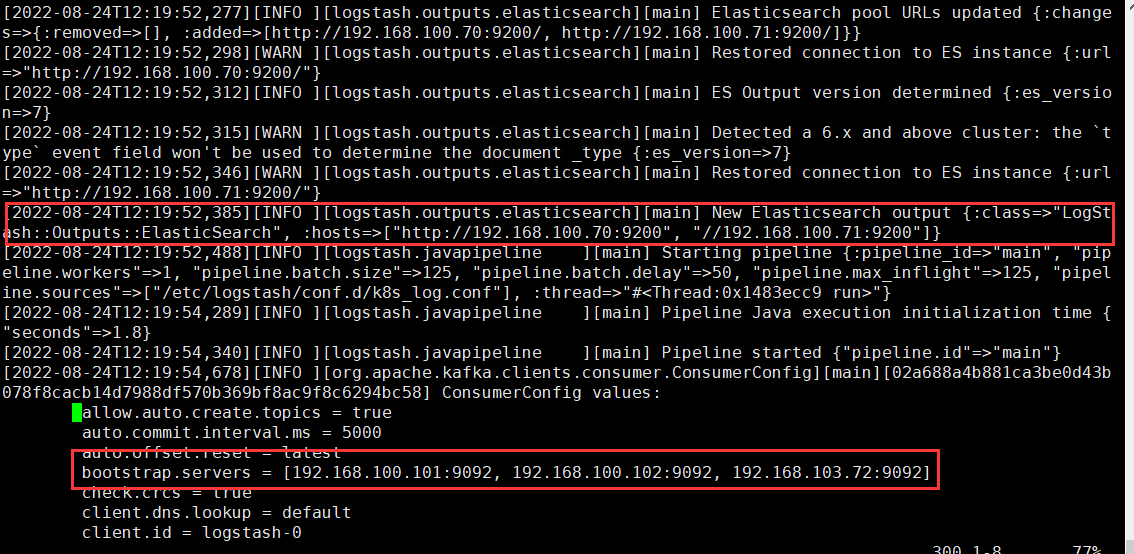
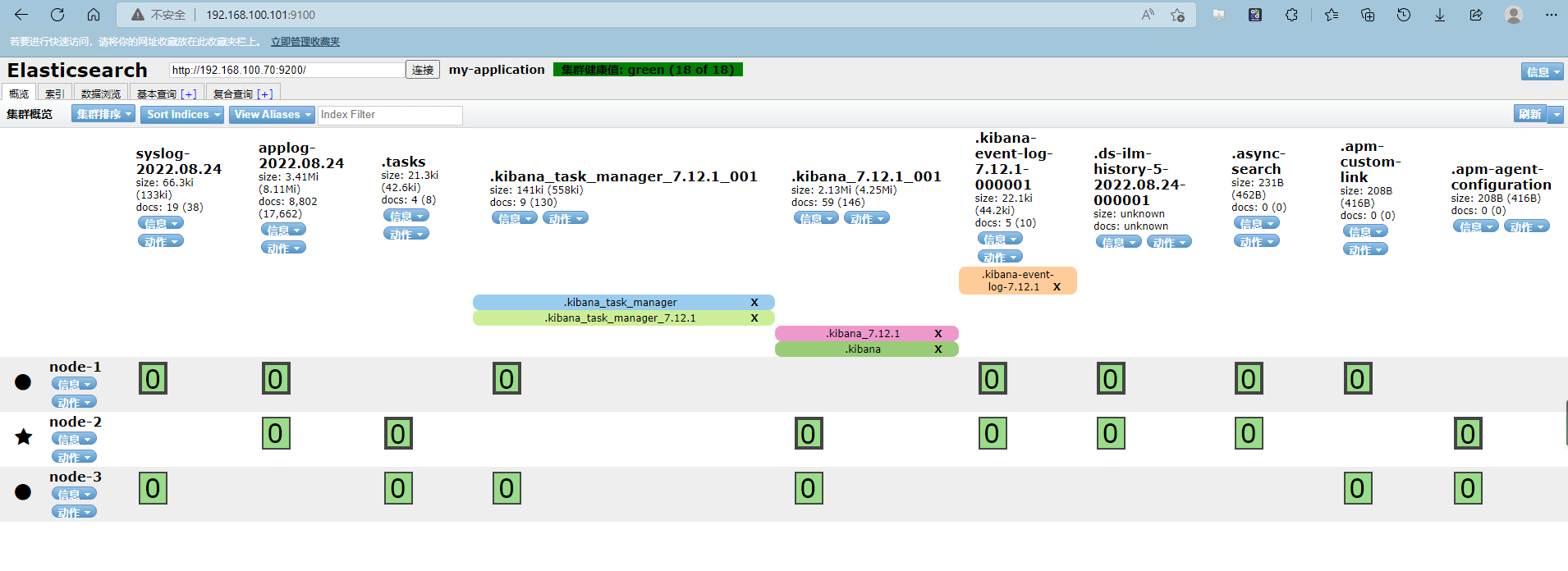
验证elasticsearch索引数据是否入库
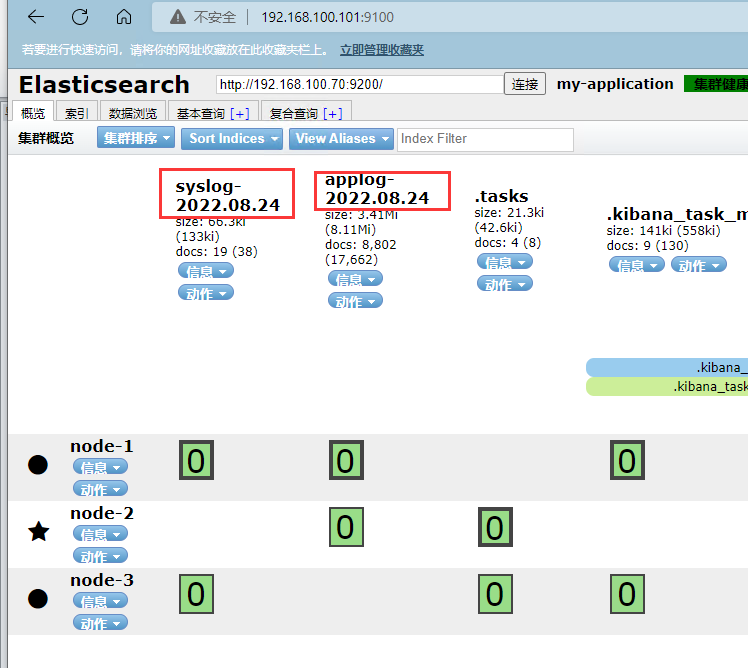
两个syslog和applog索引均入库
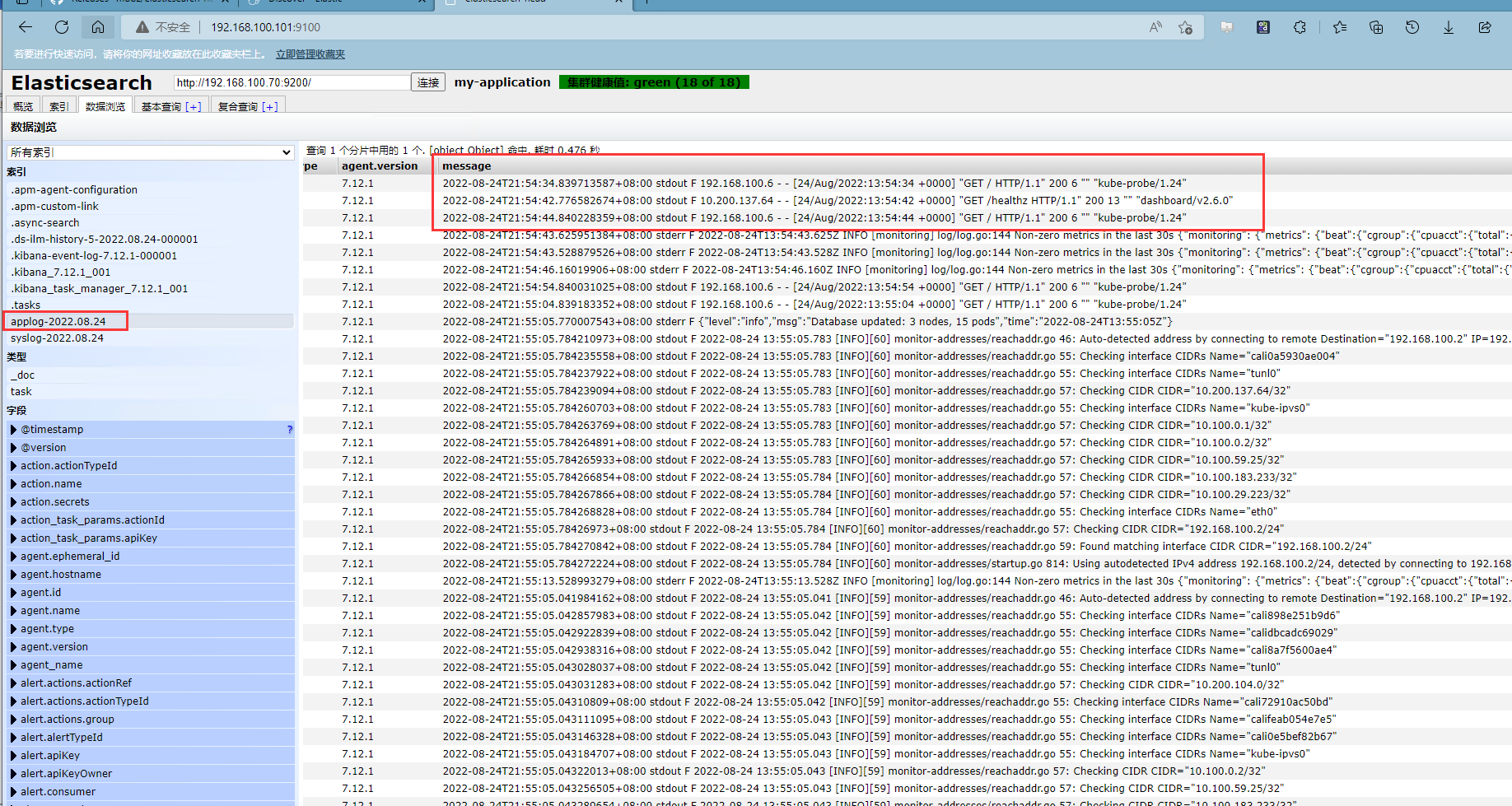
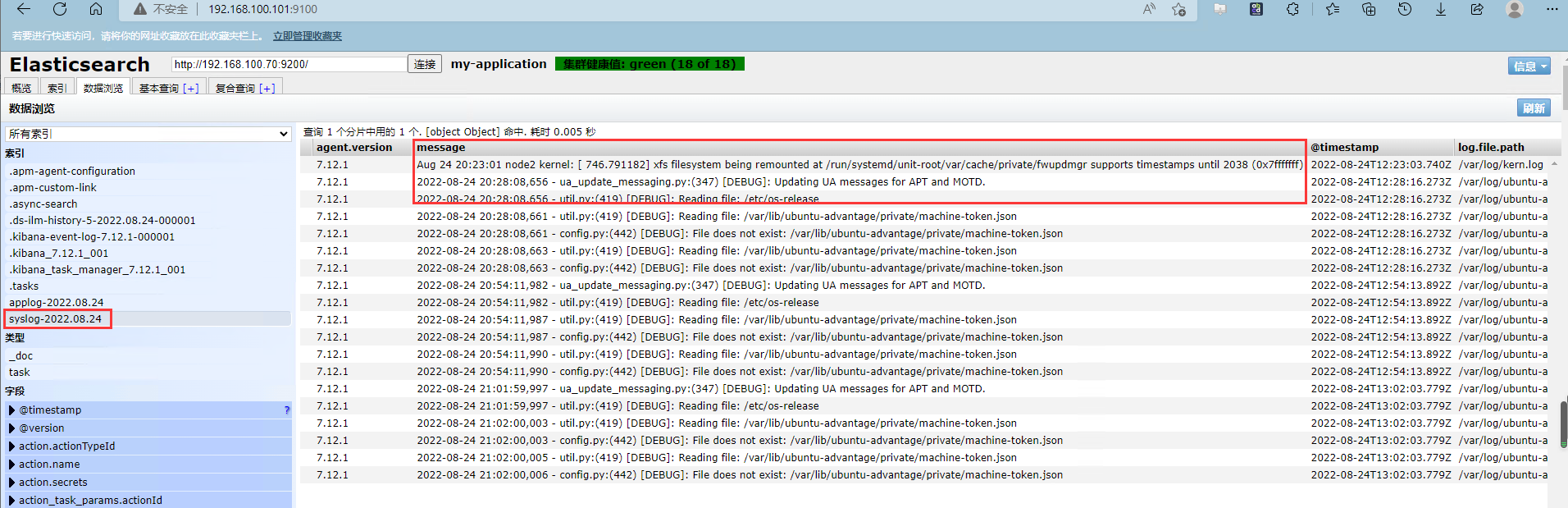
kibana添加日志索引
左侧导航栏选择发现,点击索引模式,创建索引模式
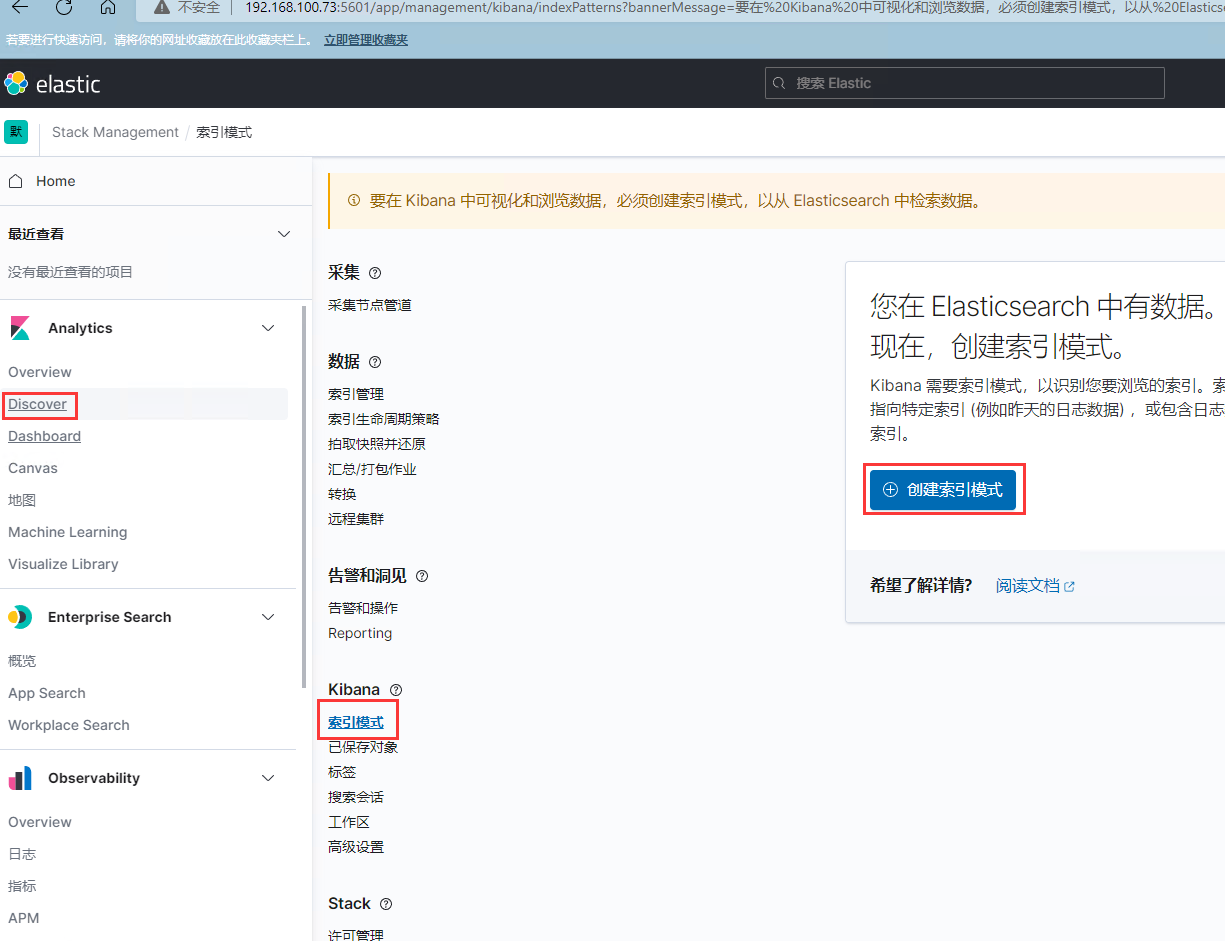
输入索引的名称匹配elasticsearch中的索引日志名称
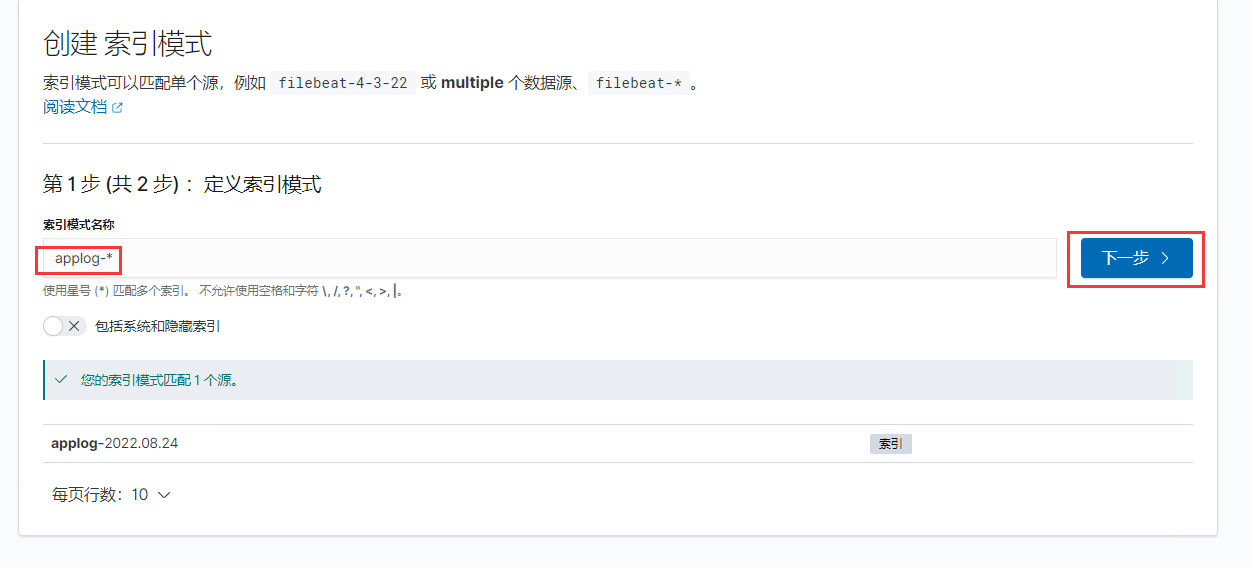
输入索引的前缀名称,再使用模糊匹配通配符“*”的方式,匹配索引名称后缀的时间日期。最后选择下一步
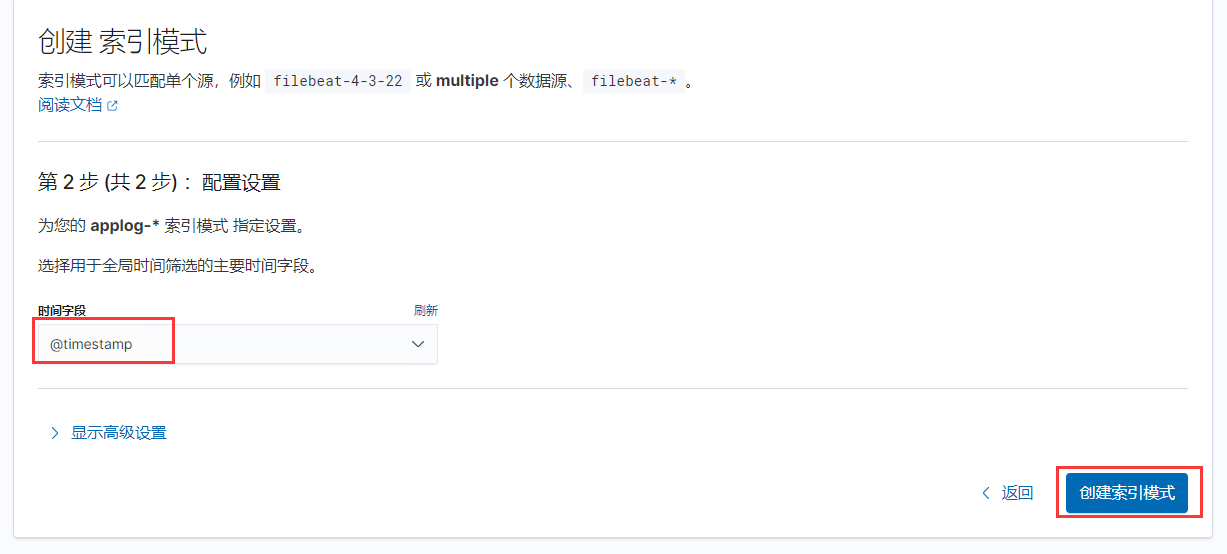
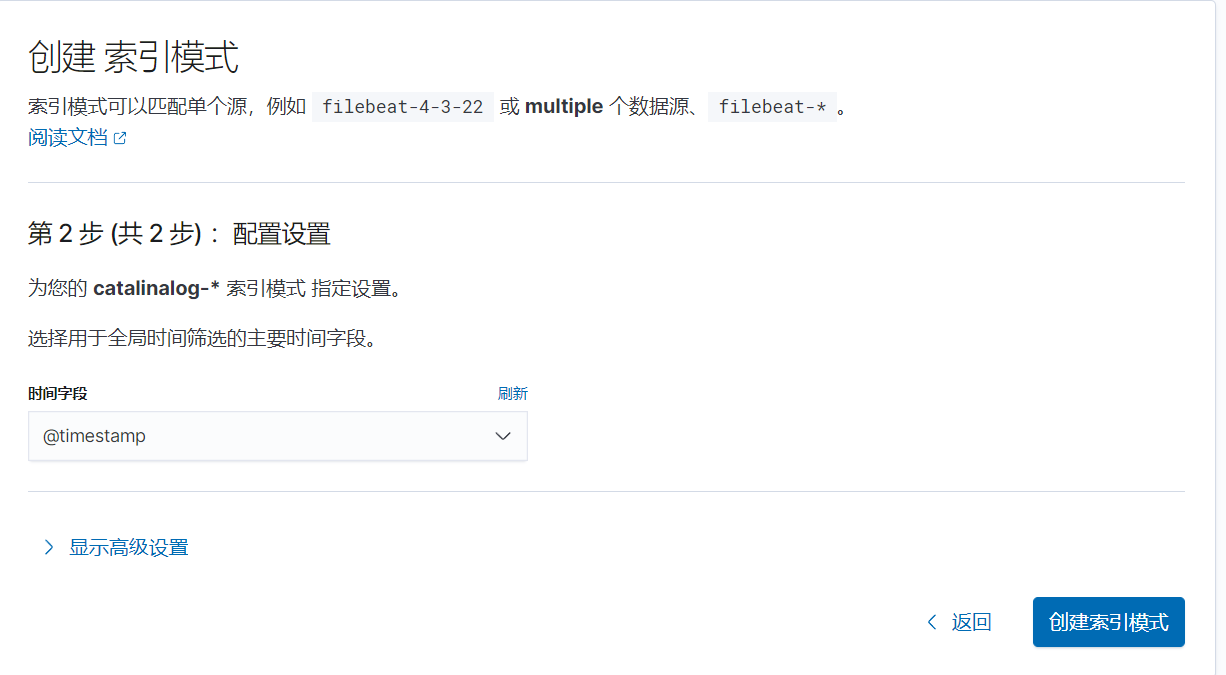
第二步选择时间字段为@timestamp时间戳格式,然后选择创建索引模式
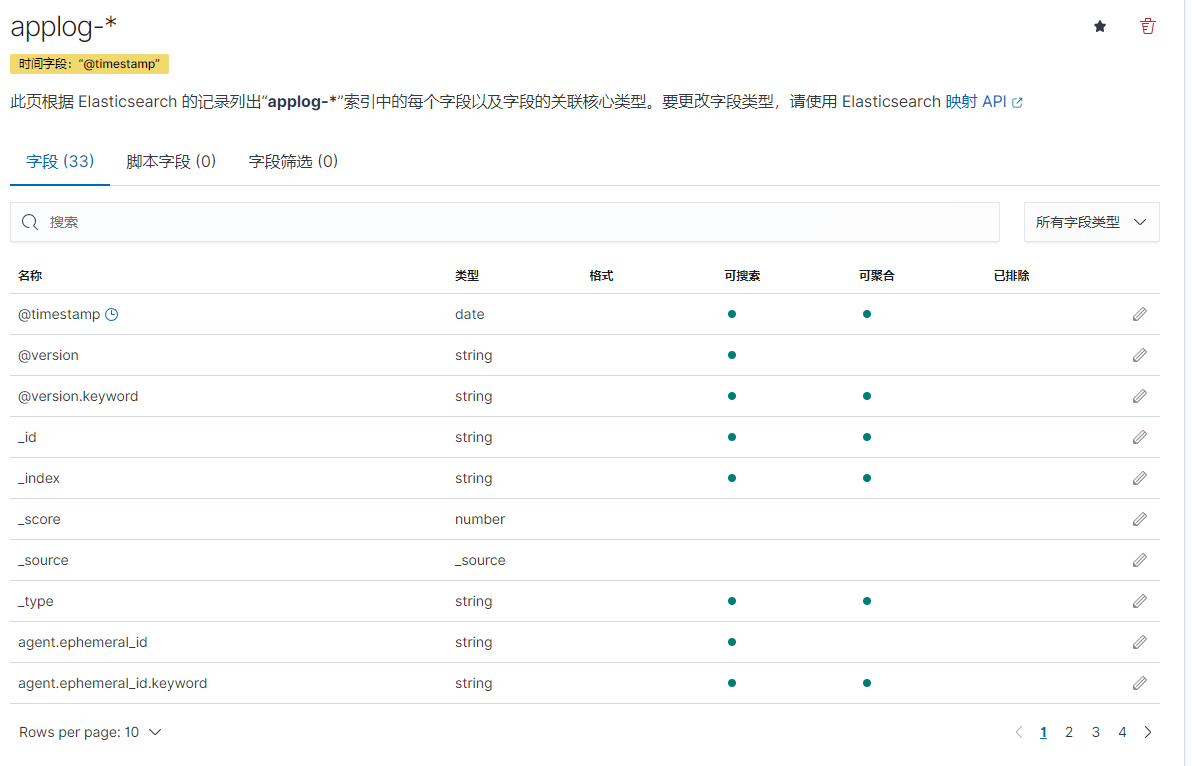
以此类推,添加syslog索引
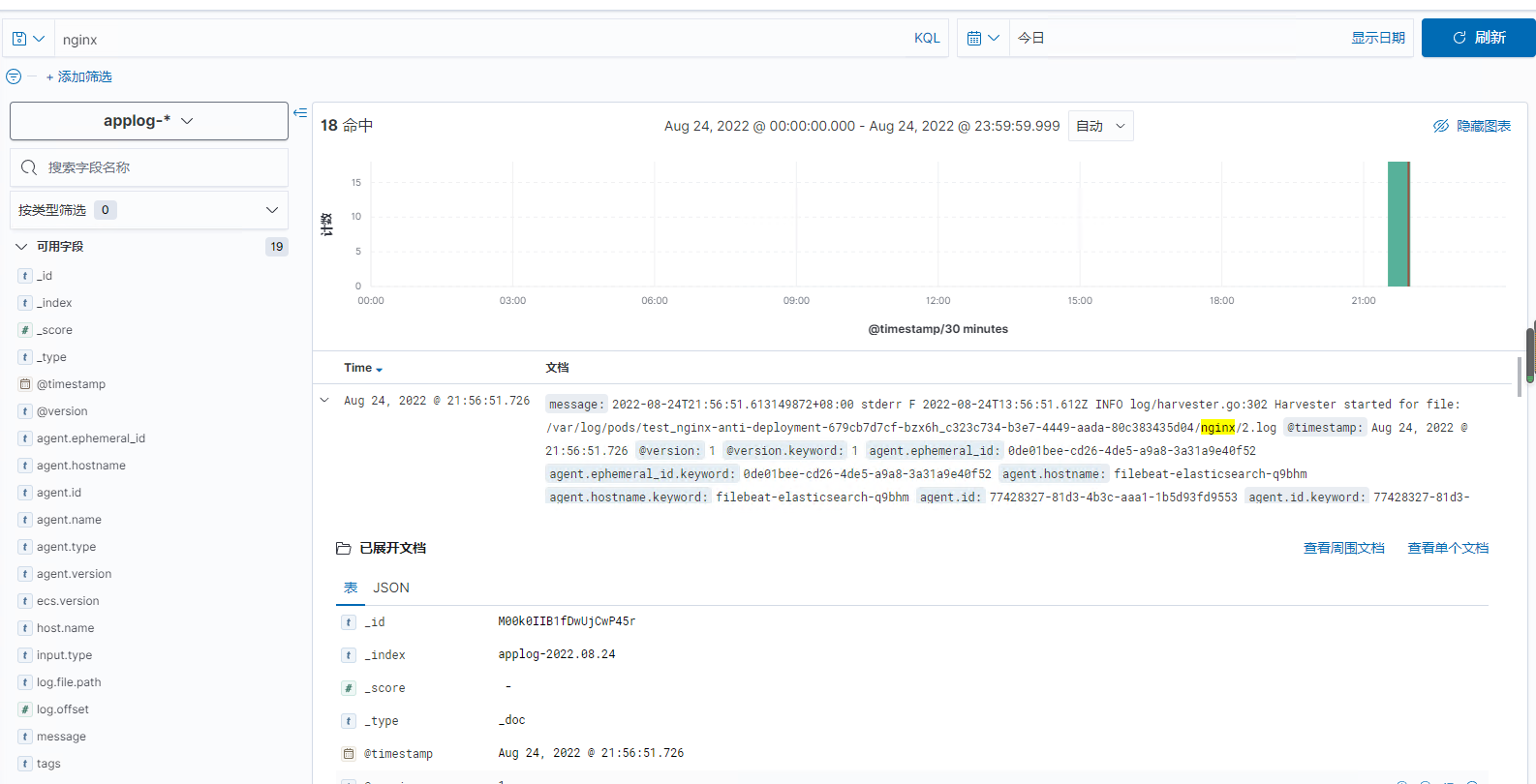
返回“发现”页面,索引日志成功显示
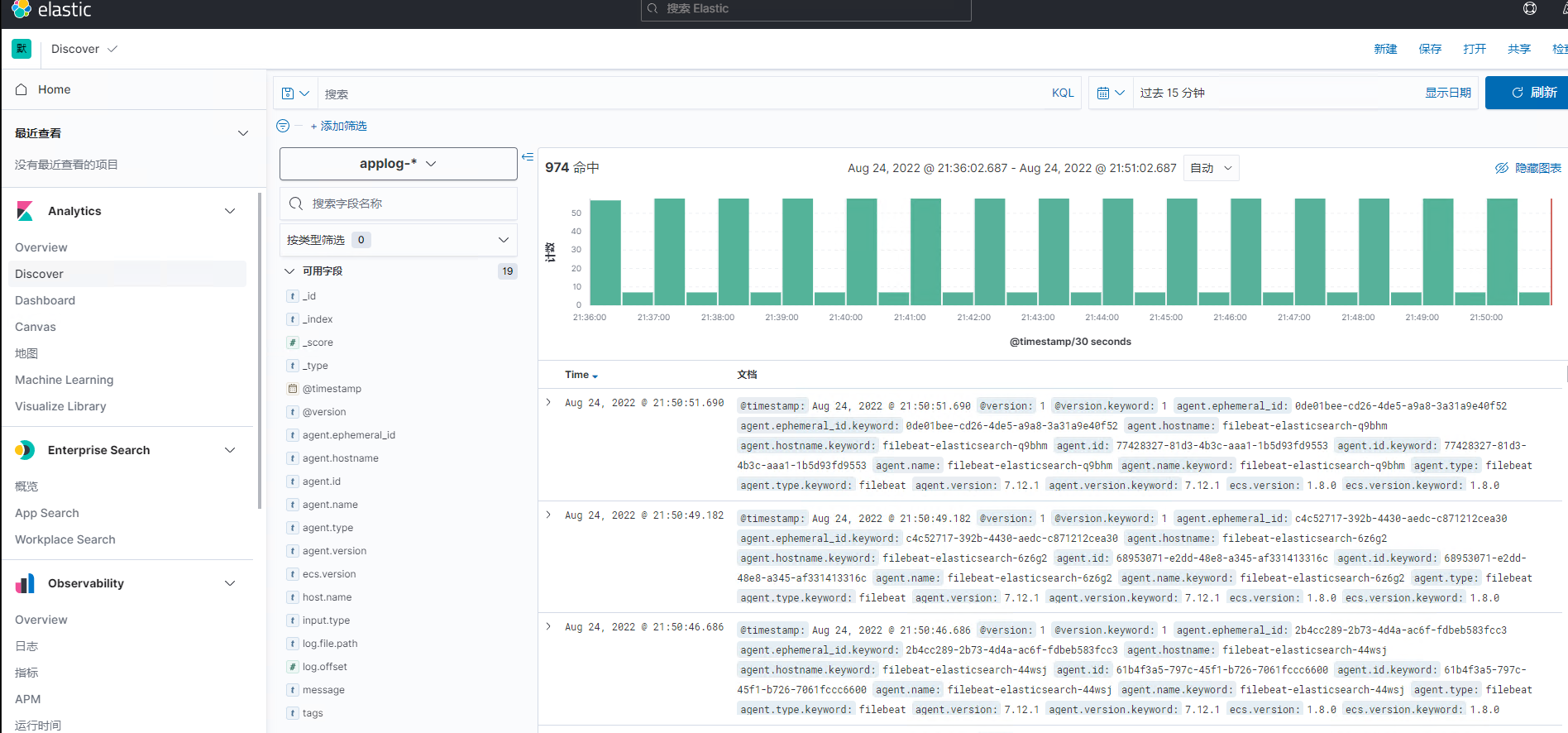
能够查看到容器的日志
sidecar模式收集日志
使用sidcar容器(一个pod多容器)收集当前pod内一个或者多个业务容器的日志(通常基于emptyDir实现业务容器与sidcar之间的日志共享)。
1、配置filebeat的配置文件
root@deploy:/dockerfile/project/elk# cat filebeat.yml
filebeat.inputs:
- type: log
enabled: true
paths:
- /usr/local/tomcat/logs/catalina.out #获取tomat catalina.out日志
tags: ["catalinalog"]
- type: log
enabled: true
paths:
- /usr/local/tomcat/logs/localhost_access_log.*.txt #获取tomcat访问日志
tags: ["accesslog"]
output.kafka:
hosts: ${KAFKA_SERVER}
topic: ${TOPIC_ID}
partition.round_robin:
reachable_only: false
required_acks: 1
compression: gzip
max_message_bytes: 1000000
2、构建filebeat容器镜像
root@deploy:/dockerfile/project/elk# vim Dockerfile
FROM elastic/filebeat:7.12.1
USER root
WORKDIR /usr/share/filebeat
ADD filebeat.yml /usr/share/filebeat/
3、创建镜像构建脚本
root@deploy:/dockerfile/project/elk# vim build.sh
#!/bin/bash
TAG=$1
docker build -t harbor.cncf.net/project/filebeat-sidecar-kafka:${TAG} .
docker push harbor.cncf.net/project/filebeat-sidecar-kafka:${TAG}
4、构建tomcat容器镜像
root@deploy:/dockerfile/tomcat# cat Dockerfile
FROM harbor.cncf.net/baseimages/jdk:1.8.191
MAINTAINER LXH
ADD apache-tomcat-8.5.43.tar.gz /usr/local
RUN ln -sv /usr/local/apache-tomcat-8.5.43 /usr/local/tomcat
ADD start.sh /usr/local/tomcat/bin
ENTRYPOINT ["/usr/local/tomcat/bin/start.sh"]
5、创建tomcat服务启动脚本
root@deploy:/dockerfile/tomcat# cat start.sh
#!/bin/bash
/usr/local/tomcat/bin/catalina.sh start
tail -f /usr/local/tomcat/logs/catalina.out
6、创建tomcat站点文件
root@deploy:/dockerfile/tomcat# cat apache-tomcat-8.5.43/webapps/myapp/index.html
test page
7、打包tomcat服务
root@deploy:/dockerfile/tomcat# tar zcvf apache-tomcat-8.5.43.tar.gz apache-tomcat-8.5.43 
8、创建镜像构建脚本
root@deploy:/dockerfile/tomcat# cat build.sh
#!/bin/bash
DIR=$(pwd)
docker build -t harbor.cncf.net/web/tomcat:8.5.43 $DIR
docker push harbor.cncf.net/web/tomcat:8.5.4
将tomcat和filebeat镜像构建后创建kafka主题
9、kafka创建主题
[root@zookeeper1 bin]# kafka-topics.sh --bootstrap-server zookeeper1:9092 --create --partitions 1 --replication-factor 3 --topic tomcat
Created topic tomcat.
[root@zookeeper1 bin]# kafka-topics.sh --bootstrap-server zookeeper1:9092 --topic tomcat --describe 
10、创建k8s资源文件
root@deploy:/dockerfile/project/elk# cat tomcat.yaml
kind: Deployment
apiVersion: apps/v1
metadata:
labels:
app: tomcat
name: tomcat-deployment
namespace: test
spec:
replicas: 3
selector:
matchLabels:
app: tomcat
template:
metadata:
labels:
app: tomcat
spec:
containers:
- name: filebeat-sidecar-container
image: harbor.cncf.net/project/filebeat-sidecar-kafka:1.0.1
imagePullPolicy: IfNotPresent
env:
- name: "KAFKA_SERVER"
value: "192.168.100.101:9092,192.168.100.102:9092,192.168.100.103:9092"
- name: "TOPIC_ID"
value: "tomcat"
volumeMounts:
- name: applogs
mountPath: /usr/local/tomcat/logs
- name: tomcat-container
image: harbor.cncf.net/web/tomcat:8.5.43
imagePullPolicy: Always
ports:
- containerPort: 8080
protocol: TCP
name: http
resources:
limits:
cpu: 1
memory: "512Mi"
requests:
cpu: 500m
memory: "512Mi"
volumeMounts:
- name: applogs
mountPath: /usr/local/tomcat/logs
startupProbe:
httpGet:
path: /myapp/index.html
port: 8080
initialDelaySeconds: 5 #首次检测延迟5s
failureThreshold: 3 #从成功转为失败的次数
periodSeconds: 3 #探测间隔周期
readinessProbe:
httpGet:
path: /myapp/index.html
port: 8080
initialDelaySeconds: 5
periodSeconds: 3
timeoutSeconds: 5
successThreshold: 1
failureThreshold: 3
livenessProbe:
httpGet:
path: /myapp/index.html
port: 8080
initialDelaySeconds: 5
periodSeconds: 3
timeoutSeconds: 5
successThreshold: 1
failureThreshold: 3
volumes:
- name: applogs #定义通过emptyDir实现业务容器与sidecar容器的日志共享,以让sidecar收集业务容器中的日志
emptyDir: {}
root@deploy:/dockerfile/project/elk# kubectl apply -f tomcat.yaml

查看tomcat的容器服务日志
root@deploy:/dockerfile/project/elk# kubectl logs -f tomcat-deployment-5b4cd4f98c-qnkz6 -c tomcat-container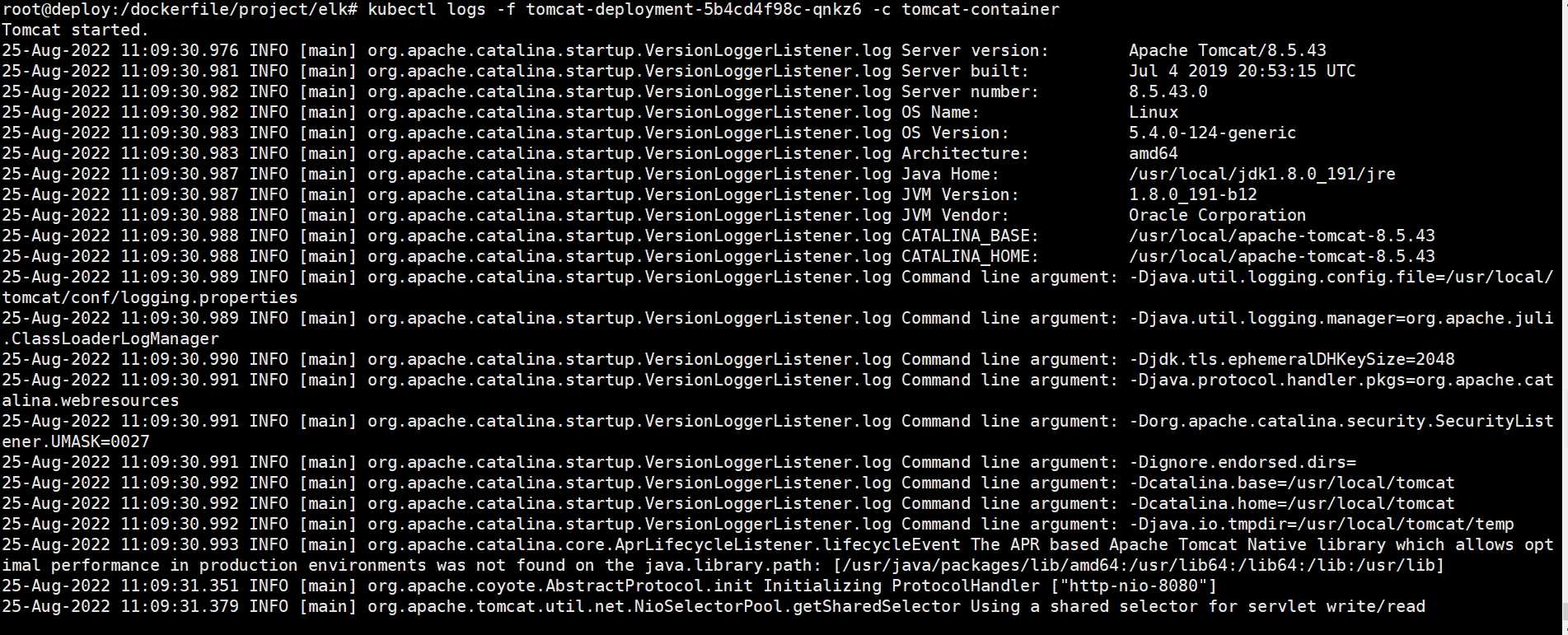
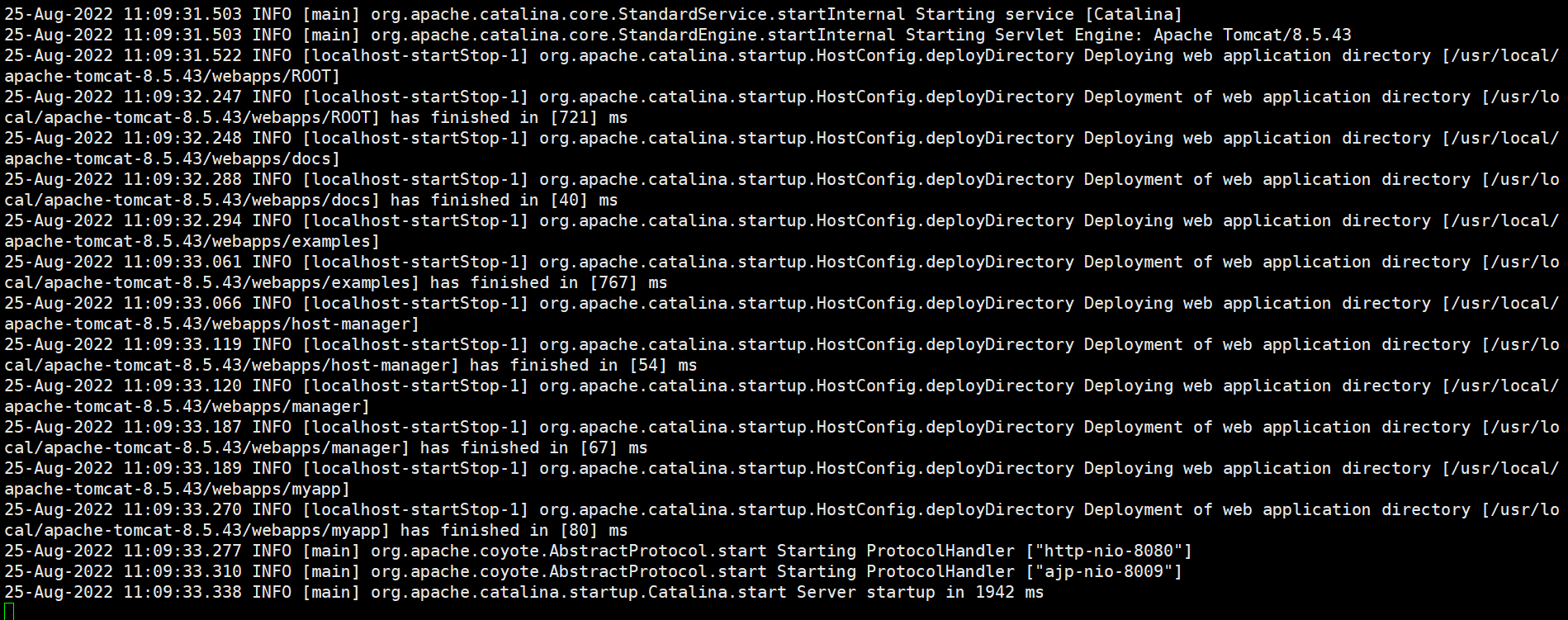
查看filebeat的容器服务日志
root@deploy:/dockerfile/project/elk# kubectl logs -f tomcat-deployment-5b4cd4f98c-qnkz6 -c filebeat-sidecar-container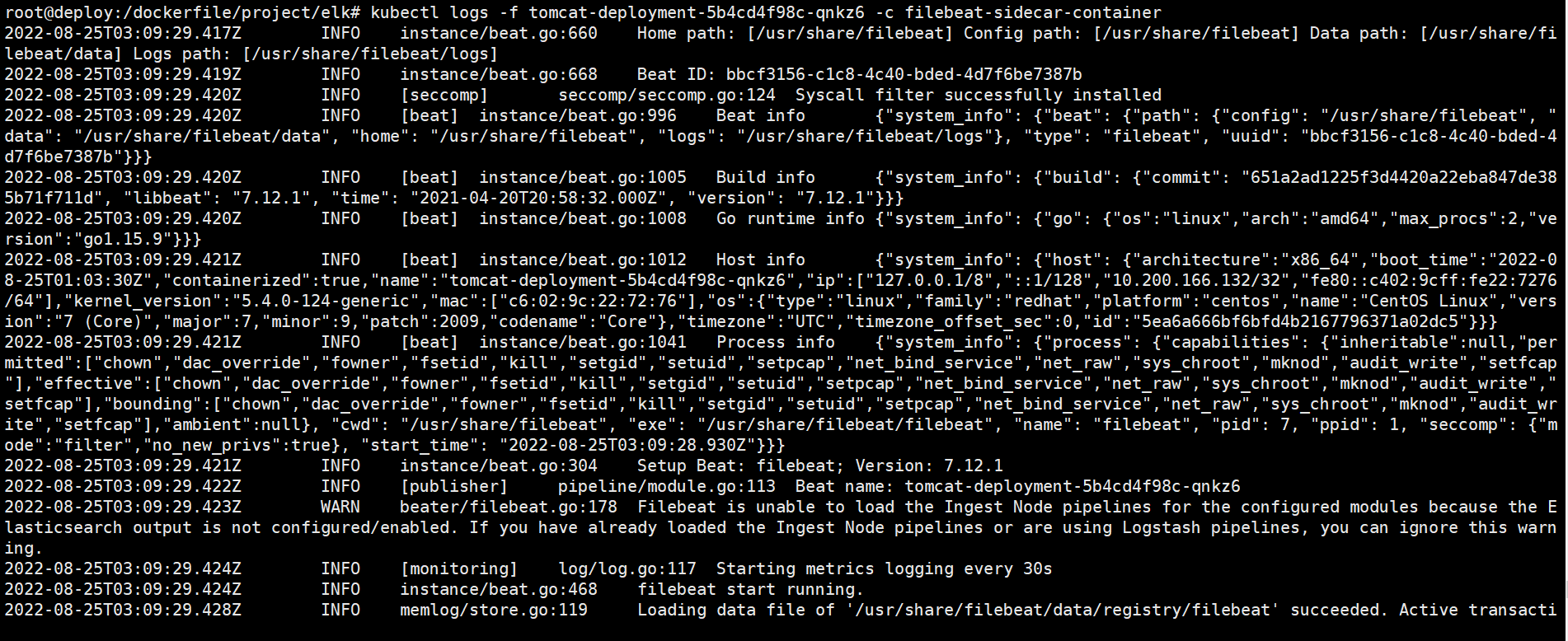
11、创建tomcat svc,暴露tomcat端口
root@deploy:/dockerfile/project/elk# cat tomcat-service.yaml
kind: Service
apiVersion: v1
metadata:
labels:
app: tomcat-service
name: tomcat-service
namespace: test
spec:
type: NodePort
ports:
- name: http
port: 8080
protocol: TCP
targetPort: 8080
nodePort: 30080
selector:
app: tomcat
12、浏览器访问测试

13、查看kafka主题数据
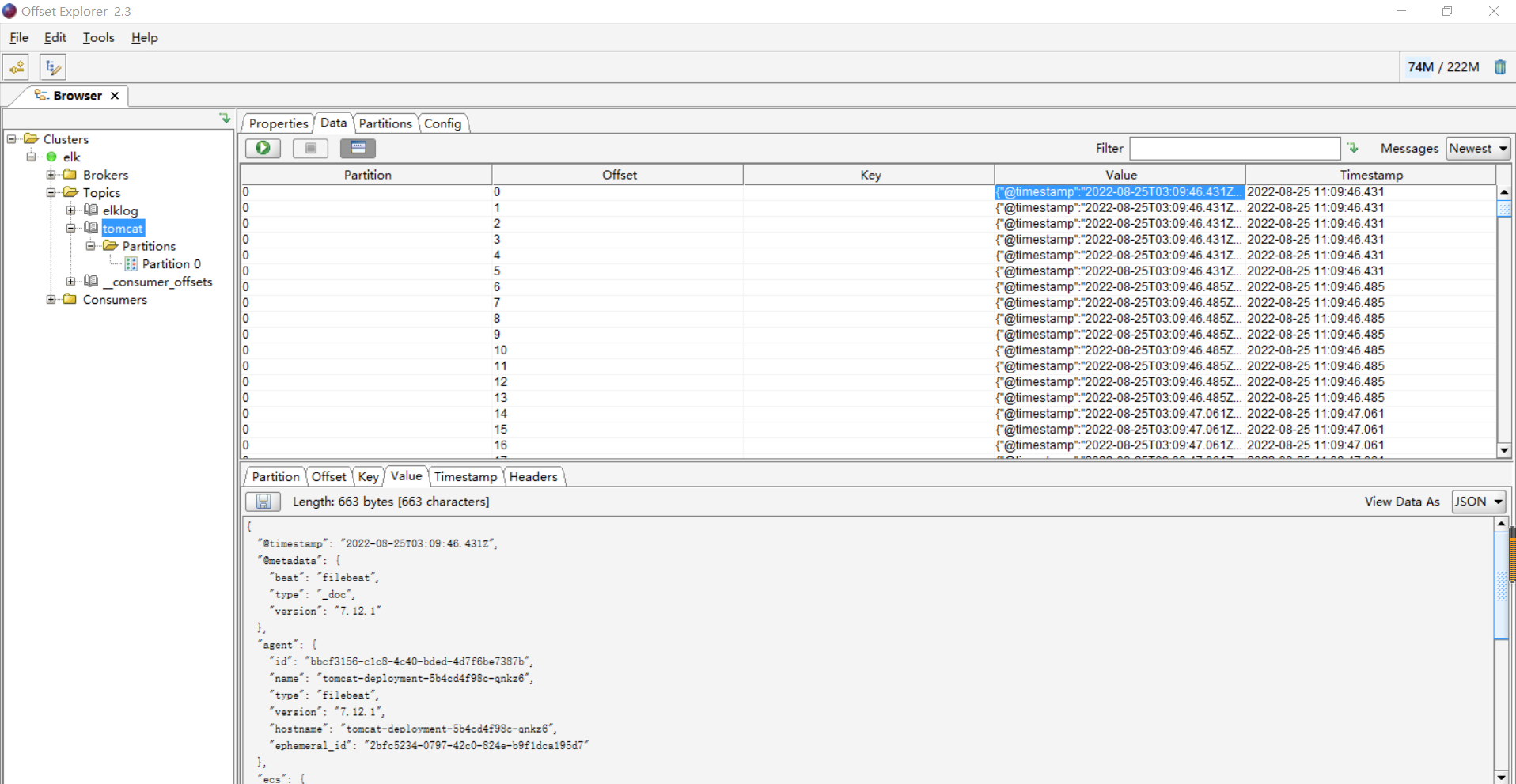
14、配置logstash
root@kibana:~# vim /etc/logstash/conf.d/tomcat.conf
input {
kafka {
bootstrap_servers => "192.168.100.101:9092,192.168.100.102:9092,192.168.100.103:9092" #生产者kafka地址
topics => ["tomcat"] #消费主题
codec => "json"
}
}
output {
if "catalinalog" in [tags] {
elasticsearch {
hosts => ["http://192.168.100.70:9200","192.168.100.71:9200","192.168.100.72:9200"]
manage_template => false
index => "catalinalog-%{+yyyy.MM.dd}"
}
}
if "accesslog" in [tags] {
elasticsearch {
hosts => ["http://192.168.100.70:9200","192.168.100.71:9200","192.168.100.72:9200"]
manage_template => false
index => "accesslog-%{+yyyy.MM.dd}"
}
}
}
重启logstash
root@kibana:~# systemctl restart logstash.service
查询logstash服务日志
root@kibana:~# tail -f /var/log/logstash/logstash-plain.log 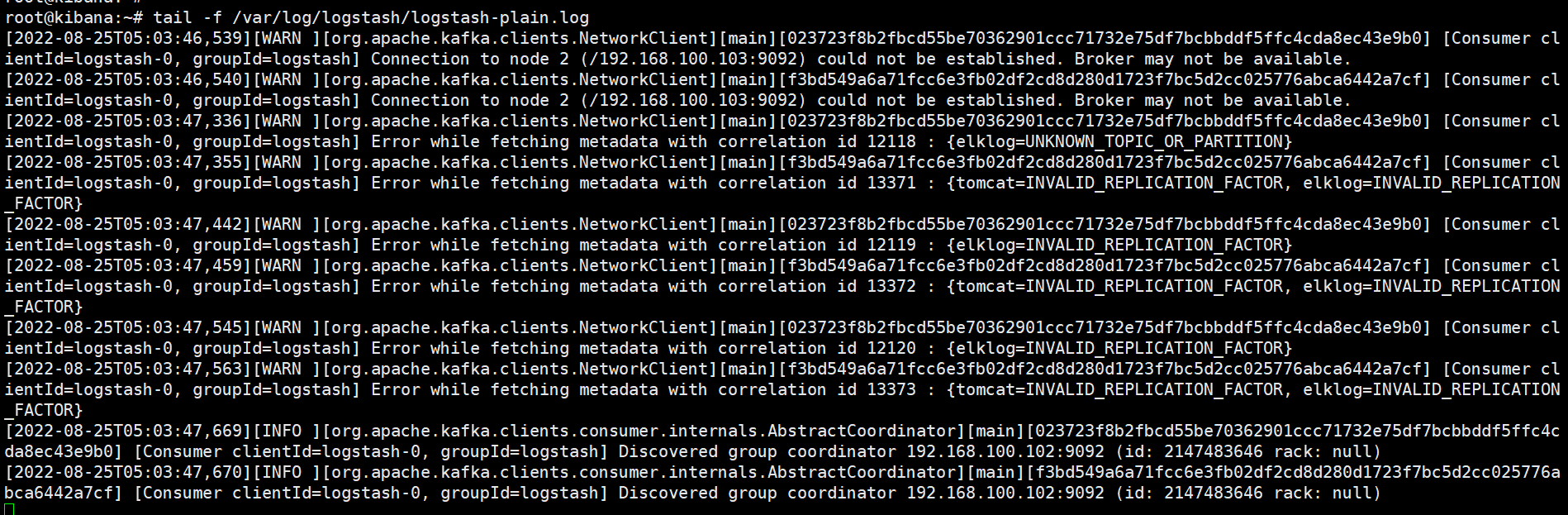
登录es-head,查看日志索引数据是否入库
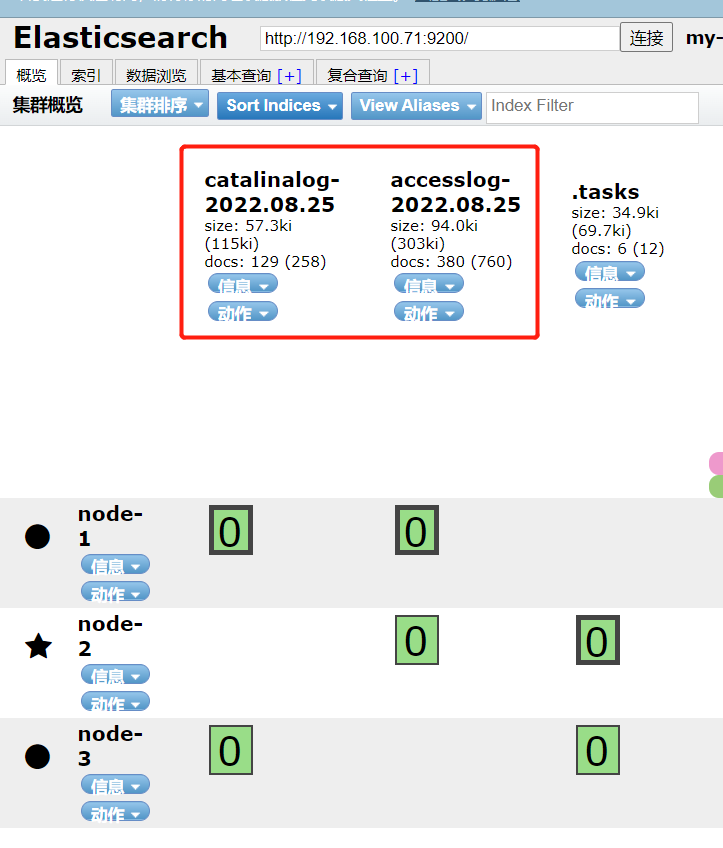
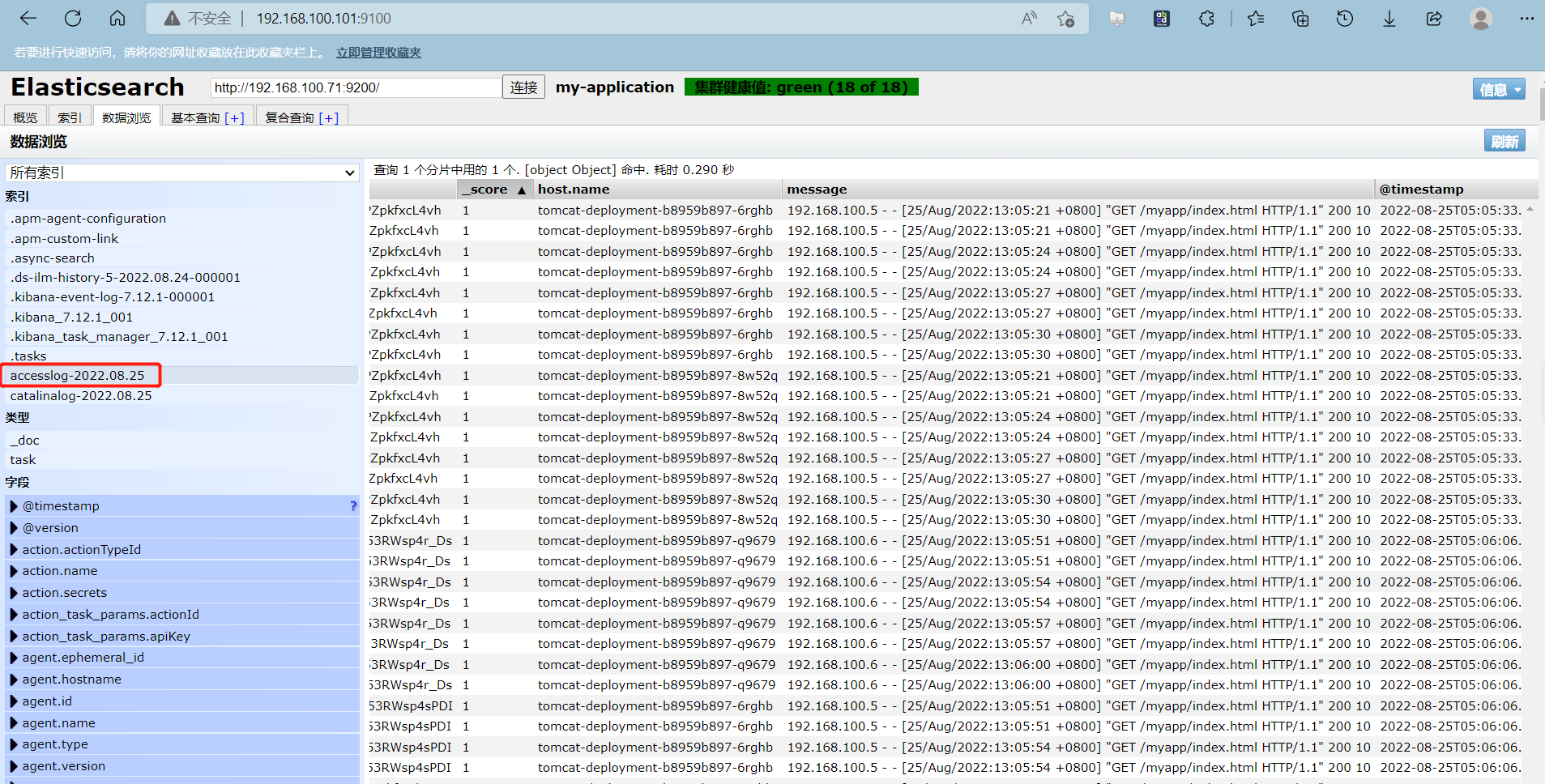
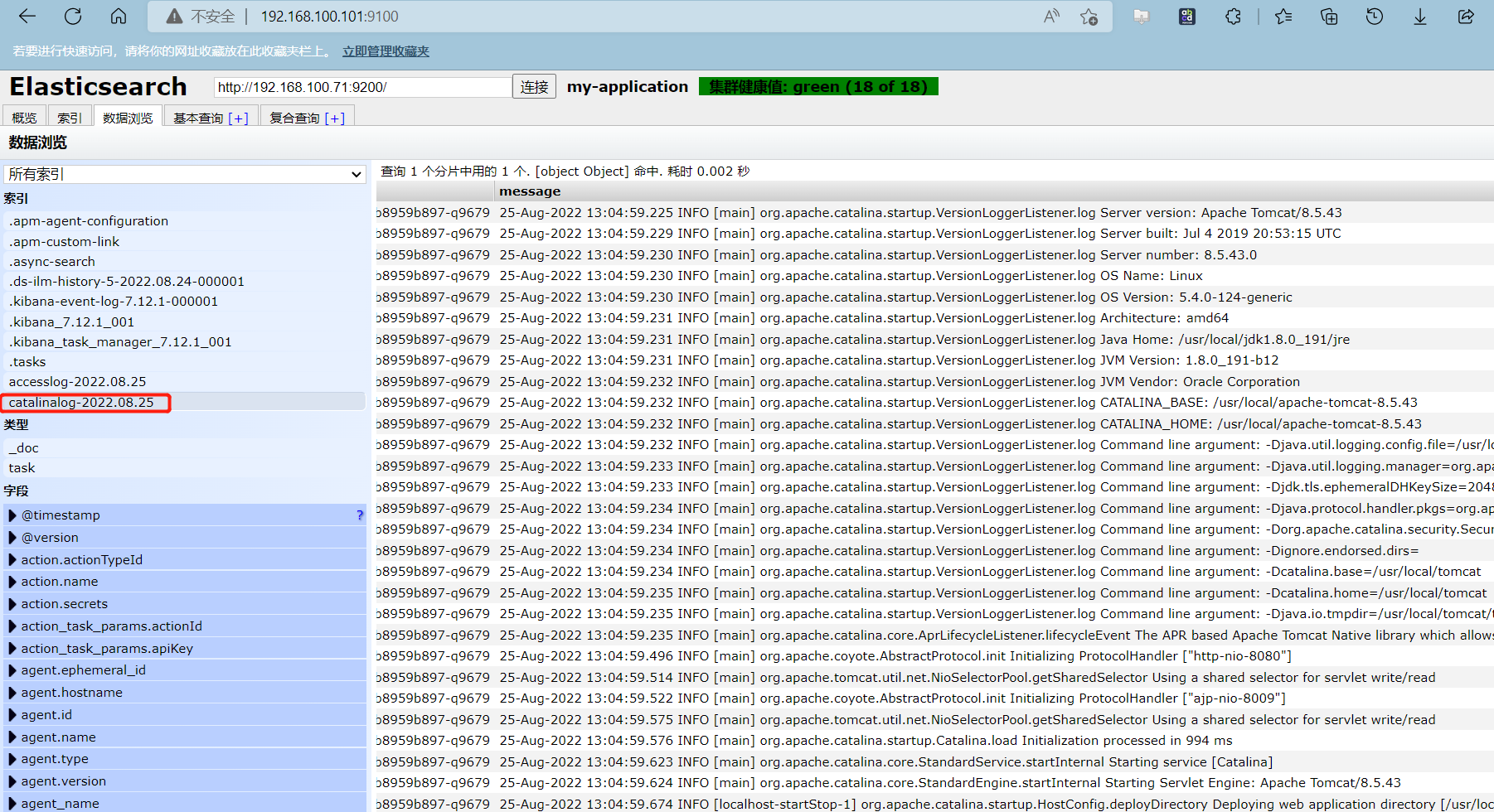
15、kibana创建索引模式
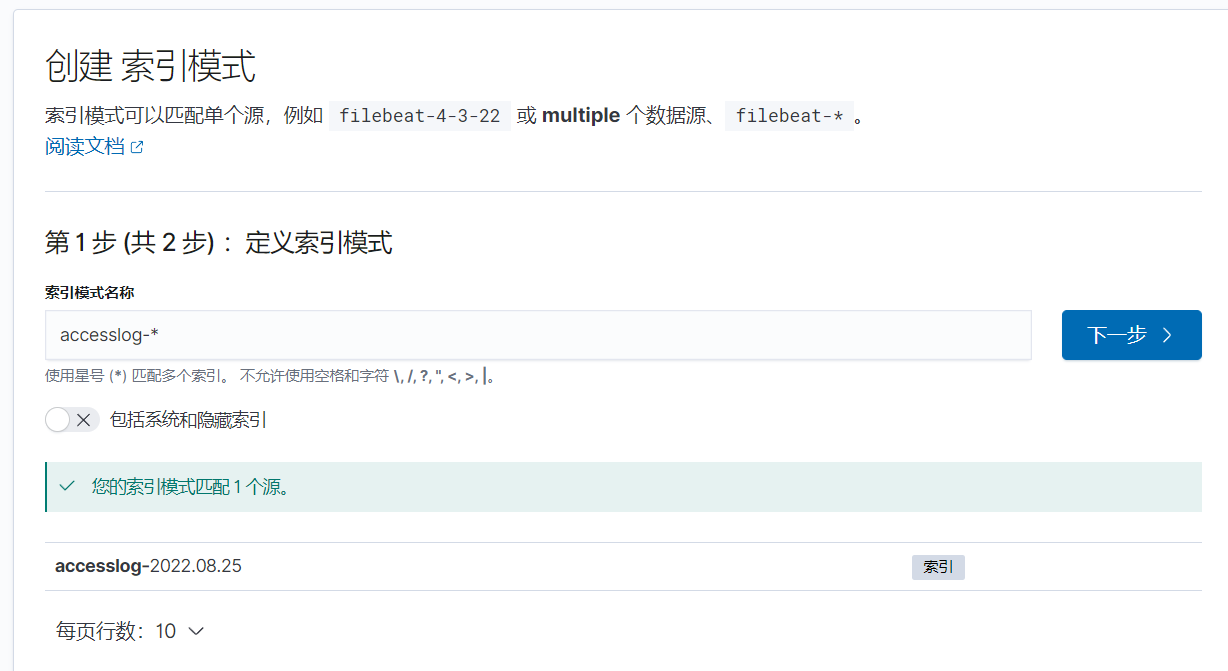
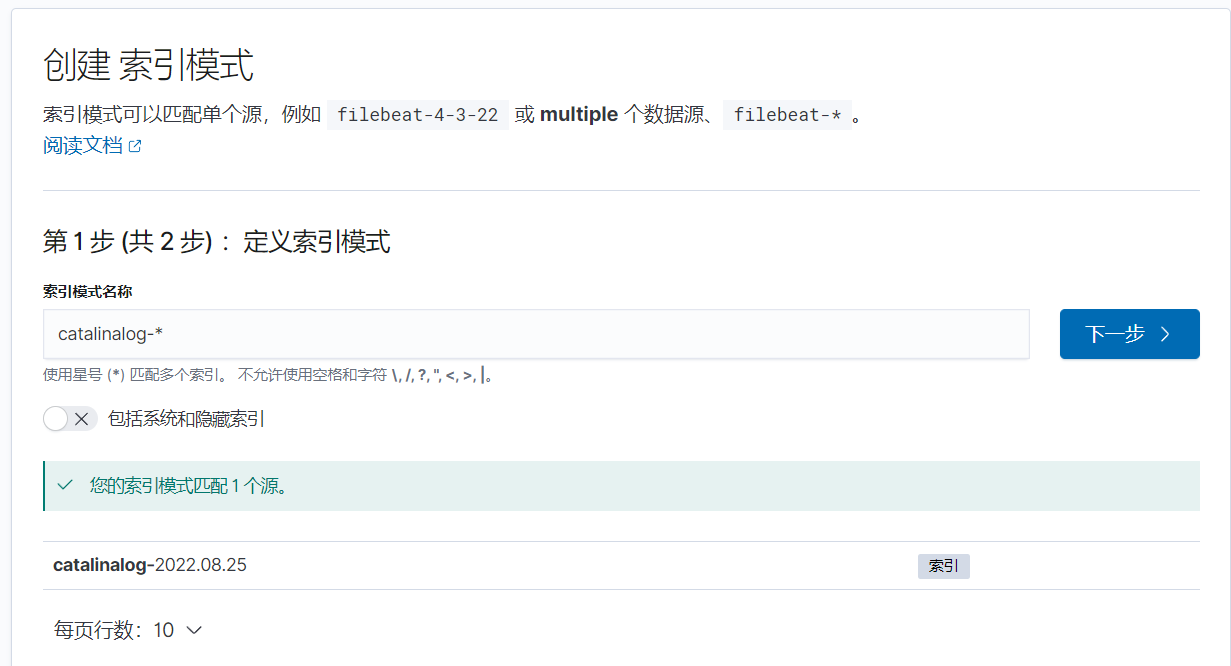
索引模式均为时间戳字段
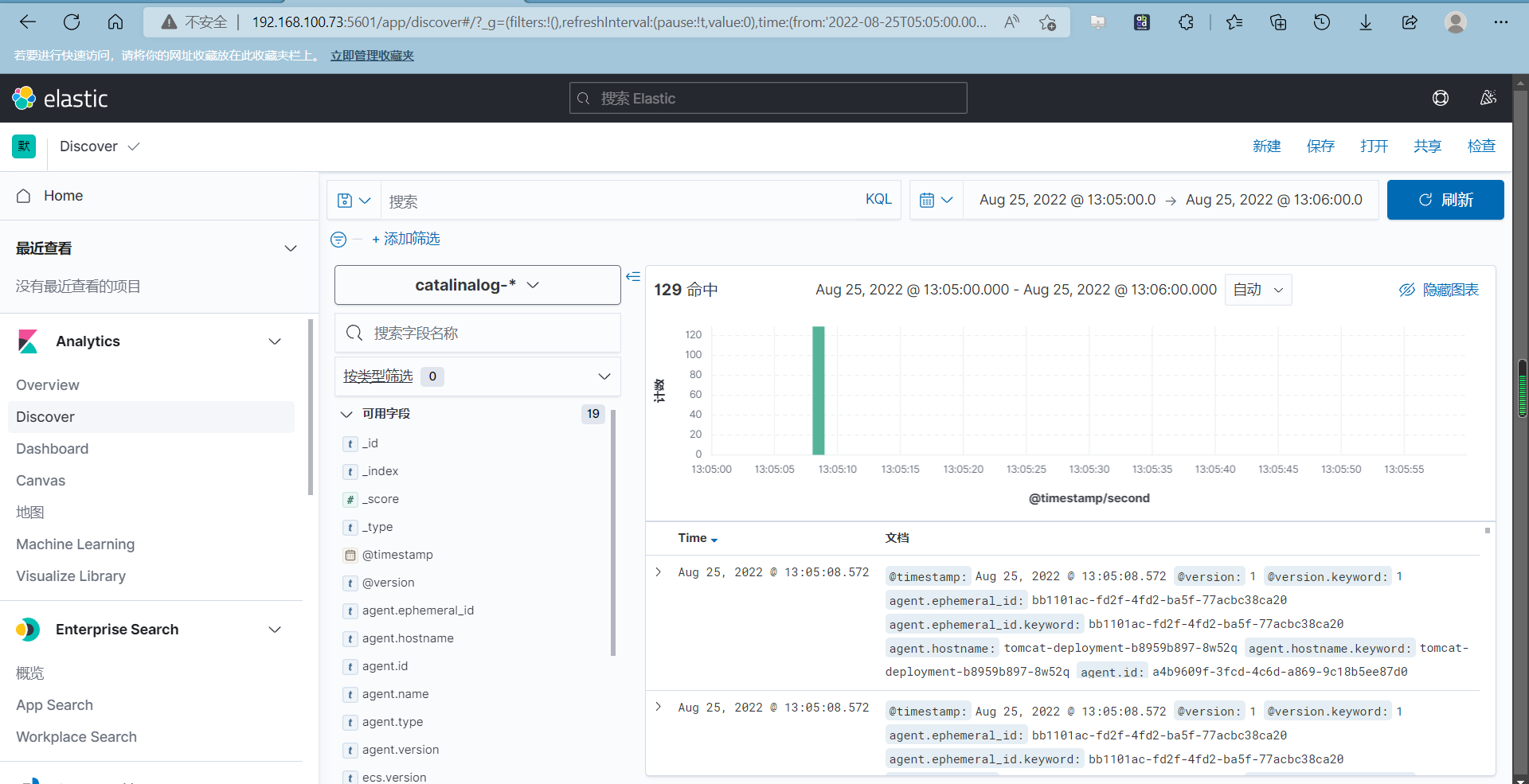
查看索引模式两个日志
catalina.out日志
access日志
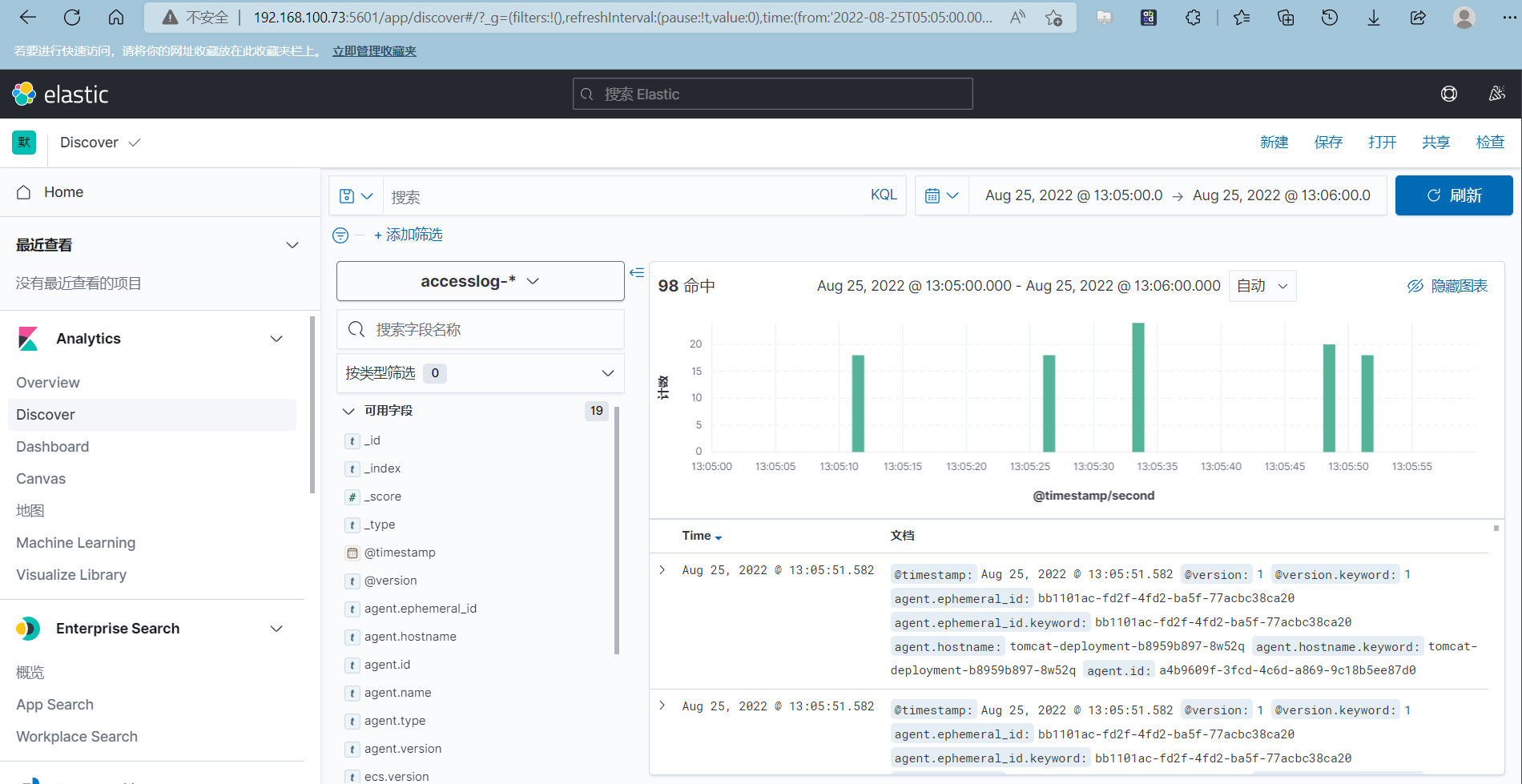
可以查看具体某个pod的日志
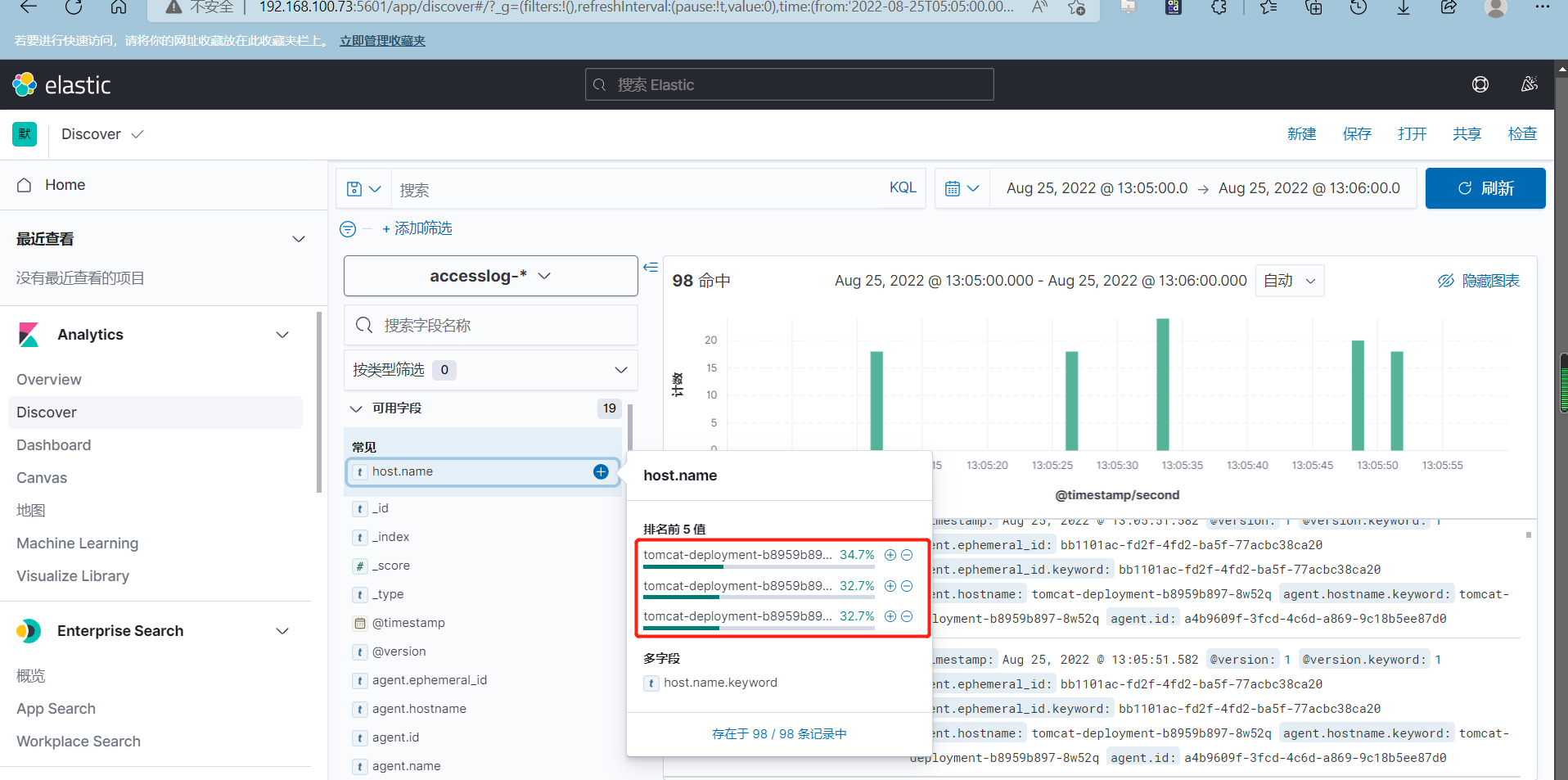
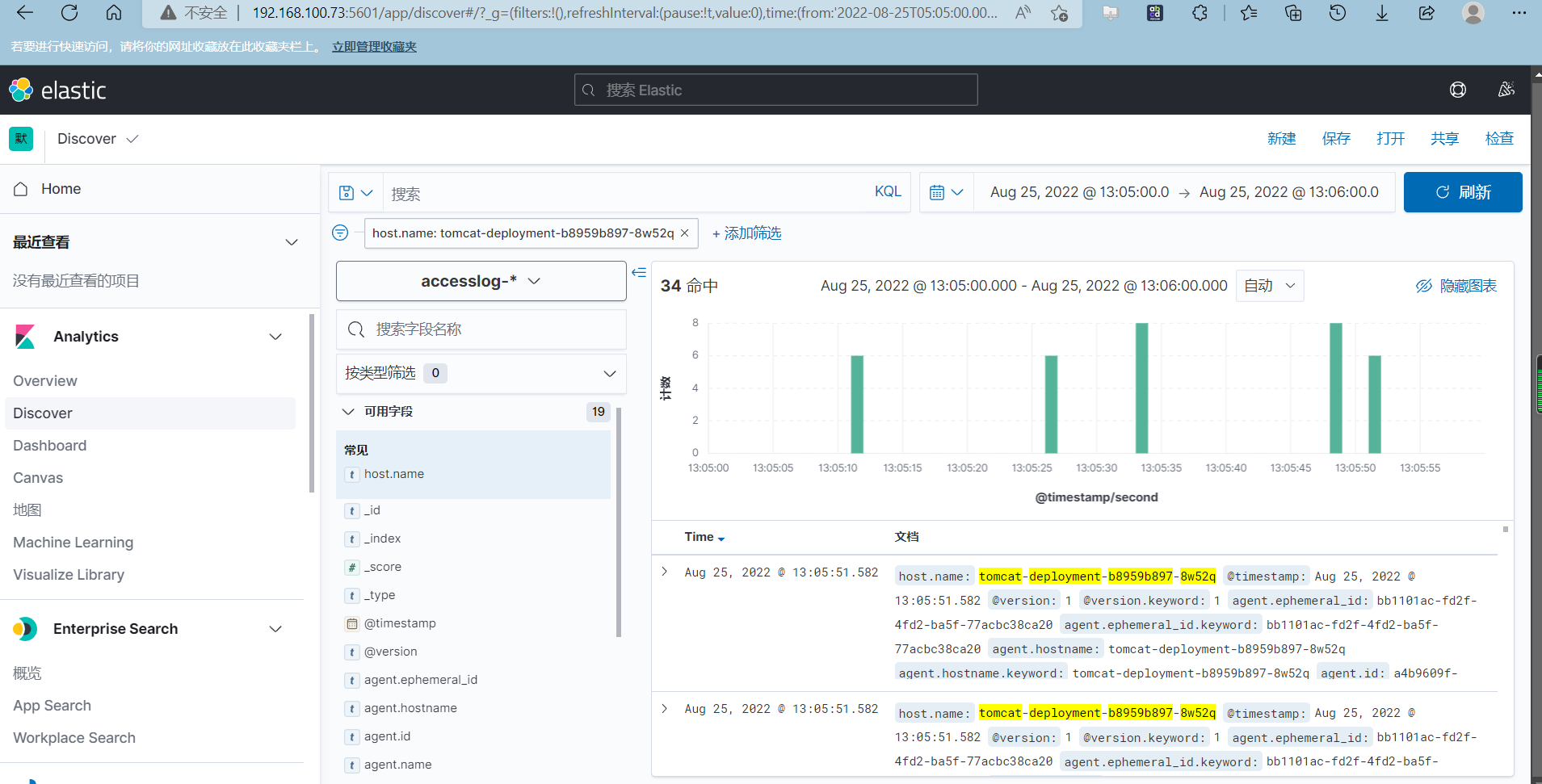
本文来自博客园,作者:PunchLinux,转载请注明原文链接:https://www.cnblogs.com/punchlinux/p/16625870.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号