K8S nodeSelector、nodeName、node亲和与反亲和
POD调度
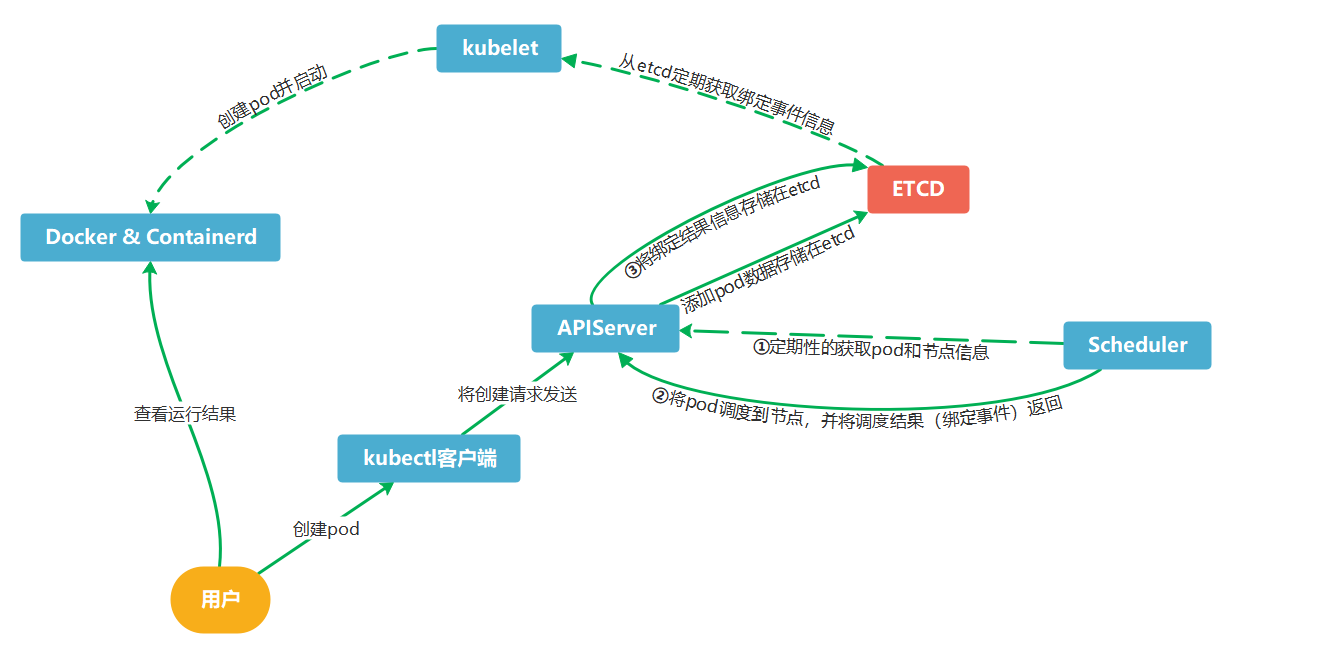
Pod调度过程:
用户使用kubectl创建pod yaml或者命令,kubectl将请求发送给api-server,apiserver获得请求后将pod相关数据存储到etcd数据库。这时scheduler定期性的从api-server获取到pod信息并将pod绑定到对应node节点,随后将绑定到pod的node节点信息一并返回给api-server,api-server从scheduler获取到绑定事件信息后,将结果存储在ETCD。最后由kubelet定期从etcd获取pod绑定事件,再调度docker或者container进行创建容器。
官方文档:
https://kubernetes.io/zh-cn/docs/concepts/scheduling-eviction/assign-pod-node/
你可以约束一个Pod以便限制 其只能在特定的节点上运行,或优先在特定的节点上运行。有几种方法可以实现这点,推荐的方法都是用标签选择算符来进行选择。通常这样的约束不是必须的,因为调度器将自动进行合理的放置(比如,将Pod分散到节点上,而不是将Pod放置在可用资源不足的节点上等等)。但在某些情况下,你可能需要进一步控制Pod被部署到哪个节点。例如,确保Pod最终落在连接了SSD的机器上,或者将来自两个不同的服务且有大量通信的Pods被放置在同一个可用区。
nodeSelector节点标签
nodeSelector 使用key和value对应标签内容。决定pod调度到那些指定的节点
Deployment:
apiVersion: apps/v1
kind: Deployment
metadata:
creationTimestamp: null
labels:
app: web
name: web
spec:
replicas: 2
selector:
matchLabels:
app: web
strategy: {}
template:
metadata:
creationTimestamp: null
labels:
app: web
spec:
containers:
- image: nginx:1.17
name: nginx
imagePullPolicy: IfNotPresent
nodeSelector:
env_role: prod
创建节点标签
192.168.100.6为prod标签分组,192.168.100.5为dev标签分组
root@deploy:~/yaml/podscheduler# kubectl label nodes 192.168.100.6 env_role=prod
node/192.168.100.6 labeled
root@deploy:~/yaml/podscheduler# kubectl label nodes 192.168.100.5 env_role=dev
node/192.168.100.5 labeled
查看所有节点标签
kubectl get nodes --show-labels
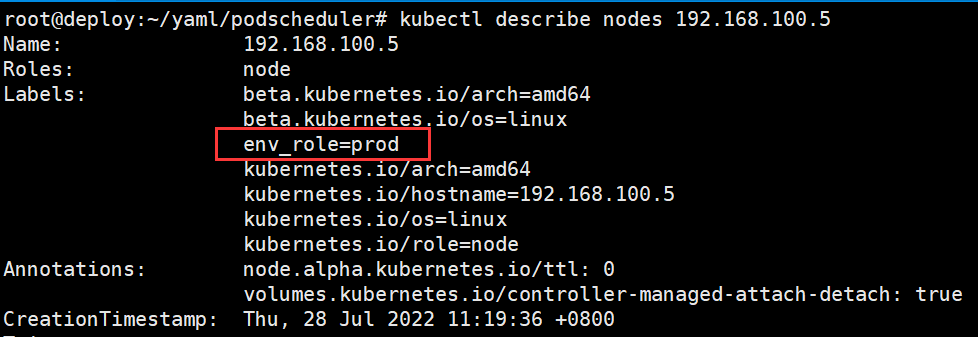
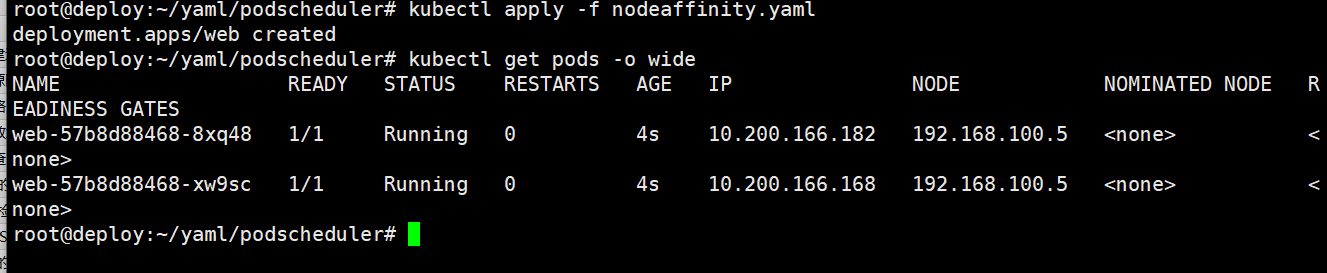
查看pod调度结果,两个副本pod都调度在192.168.100.6
root@deploy:~/yaml/podscheduler# kubectl get pods -o wide
删除节点标签,则在key后加一个-
[root@master ~]# kubectl label node 192.168.100.6 env_role-
[root@master ~]# kubectl label node 192.168.100.5 env_role-
修改节点标签
[root@master ~]# kubectl label node 192.168.100.5 env_role=prod --overwrite 
nodeName调度
使用nodeName,指定节点名称,调度在该节点下
Deployment:
root@deploy:~/yaml/podscheduler# cat nodename.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: web
name: web
namespace: test
spec:
replicas: 2
selector:
matchLabels:
app: web
template:
metadata:
labels:
app: web
spec:
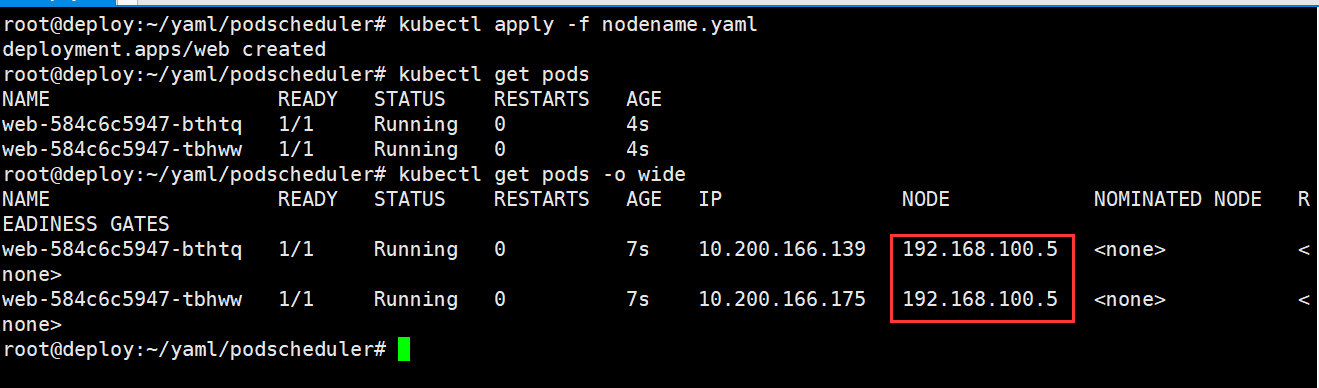
nodeName: 192.168.100.5 #调度Pod到特定的节点
containers:
- image: nginx
name: nginx
imagePullPolicy: IfNotPresent
查看调度结果
节点亲和性和反亲和性
节点亲和性nodeAffinity类似于nodeSelector,根据节点上标签约束对Pod调度到那些节点
(1)硬亲和性,requiredDuringSchedulingIgnoredDuringExecution
必须满足pod调度匹配条件,如果不满足则不进行调度
(2)软亲和性
倾向满足pod调度匹配条件,不满足的情况下会调度的不符合条件的Node上
(3)操作符
In:标签的值存在匹配列表中(匹配成功就调度到目的node,实现node亲和)
NotIn:标签的值不存在指定的匹配列表中(不会调度到目的node,实现反亲和)
Gt:标签的值大于某个值(字符串)
Lt:标签的值小于某个值(字符串)
Exists:指定的标签存在
DoesNotExist:某个标签不存在
affinity与nodeSelector对比:
1、亲和与反亲和对目的标签的选择匹配不仅仅支持and,还支持In、NotIn、Exists、DoesNotExist、Gt、Lt。
2、可以设置软匹配和硬匹配,在软匹配下,如果调度器无法匹配节点,仍然将pod调度到其它不符合条件的节点。
3、还可以对pod定义亲和策略,比如允许哪些pod可以或者不可以被调度至同一台node。
亲和性
硬亲和性:
示例:
root@deploy:~/yaml/podscheduler# cat nodeaffinity.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: web
name: web
spec:
replicas: 2
selector:
matchLabels:
app: web
template:
metadata:
labels:
app: web
spec:
containers:
- image: nginx
name: nginx
imagePullPolicy: IfNotPresent
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions: #env_role和disktype两个key必须满足才可以调度
- key: env_role #多个value只要有一个匹配则就认为key匹配成功
operator: In
values:
- dev
- test
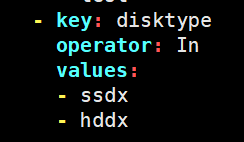
- key: disktype #多个value只要有一个匹配则就认为key匹配成功
operator: In
values:
- ssd
- hdd
匹配规则:
如果定义一个亲和性nodeSelectorTerms(条件)中通过一个matchExpressions基于列表指定了多个operator条件,则只要满足其中一个条件,就会被调度到相应的节点上,即or的关系,即如果nodeSelectorTerms下面有多个条件的话,只要满足任何一个条件就可以了。
如果定义一个亲和性nodeSelectorTerms中都通过一个matchExpressions(匹配表达式)指定多个key匹配条件,则所有的key的目的条件都必须满足才会调度到对应的节点,即and的关系,即果matchExpressions有多个key选项的话,则必须同时满足所有这些key的条件才能正常调度。
查看节点标签
root@deploy:~/yaml/podscheduler# kubectl get nodes --show-labels

查看pod详细信息
由于node亲和性中节点标签disktype不匹配节点亲和性定义的values,需要env_role和disktype两个key匹配成功,才能调度,因此调度失败。
root@deploy:~/yaml/podscheduler# kubectl describe pods web-7bd676b5cb-776bw
修改节点亲和性disktype key定义的value,则匹配成功
软亲和性
weight:匹配权重,weight值越大优先级越高,越优先匹配调度
示例:
查看节点标签
100.5标签为disktype=hddx,env_role=dev
100.6标签为disktype=sddx,env_role=prod
root@deploy:~/yaml/podscheduler# kubectl get nodes --show-labels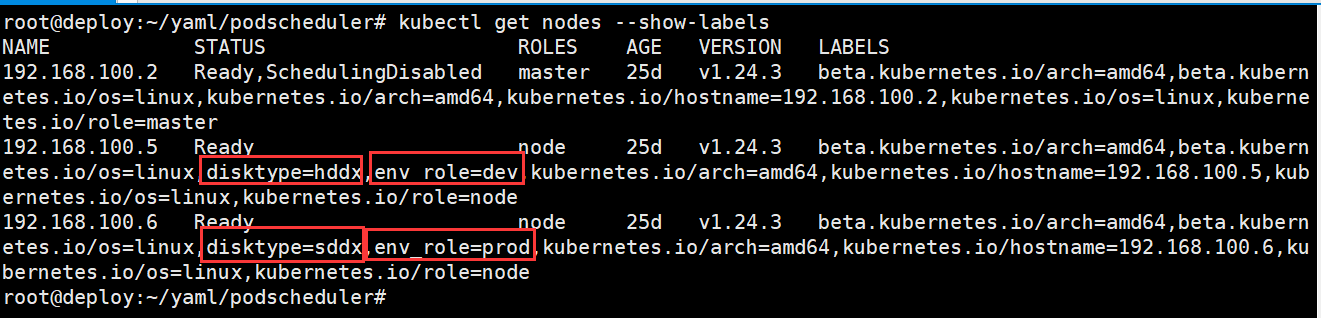
deployment软亲和
root@deploy:~/yaml/podscheduler# cat nodeaffinity.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: web
name: web
spec:
replicas: 2
selector:
matchLabels:
app: web
template:
metadata:
labels:
app: web
spec:
containers:
- image: nginx
name: nginx
imagePullPolicy: IfNotPresent
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions: #env_role和disktype两个key必须满足才可以进行调度判断
- key: env_role #如果该key匹配节点标签,则不会调度到对应节点
operator: NotIn
values:
- dev
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100 #软亲和匹配条件1,权重100优先级
preference:
matchExpressions:
- key: env_role
operator: In
values:
- test
- weight: 50 #软亲和匹配条件1,权重50优先级
preference:
matchExpressions:
- key: disktype
operator: In
values:
- sddx
最终pod调度在标签为disktype=sddx的节点192.168.100.6上

反亲和性
反亲和性的操作符为NotIn,如果匹配到对应的节点标签,则不会将pod调度到该节点上,反之,会调度其他节点。
root@deploy:~/yaml/podscheduler# cat nodeaffinity.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: web
name: web
spec:
replicas: 2
selector:
matchLabels:
app: web
template:
metadata:
labels:
app: web
spec:
containers:
- image: nginx
name: nginx
imagePullPolicy: IfNotPresent
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions: #env_role和disktype两个key必须满足才可以进行调度判断
- key: env_role #如果该key匹配节点标签,则不会调度到对应节点
operator: NotIn
values:
- dev
- test
- key: disktype #如果该key匹配节点标签,则不会调度到对应节点
operator: In
values:
- ssdx
- hdd
查看节点标签
100.5标签为disktype=hddx,env_role=dev
100.6标签为disktype=sddx,env_role=prod
root@deploy:~/yaml/podscheduler# kubectl get nodes --show-labels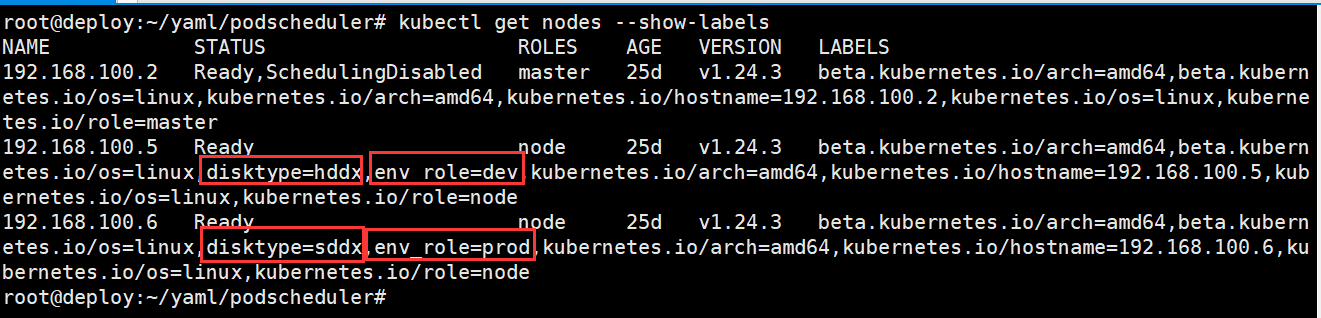
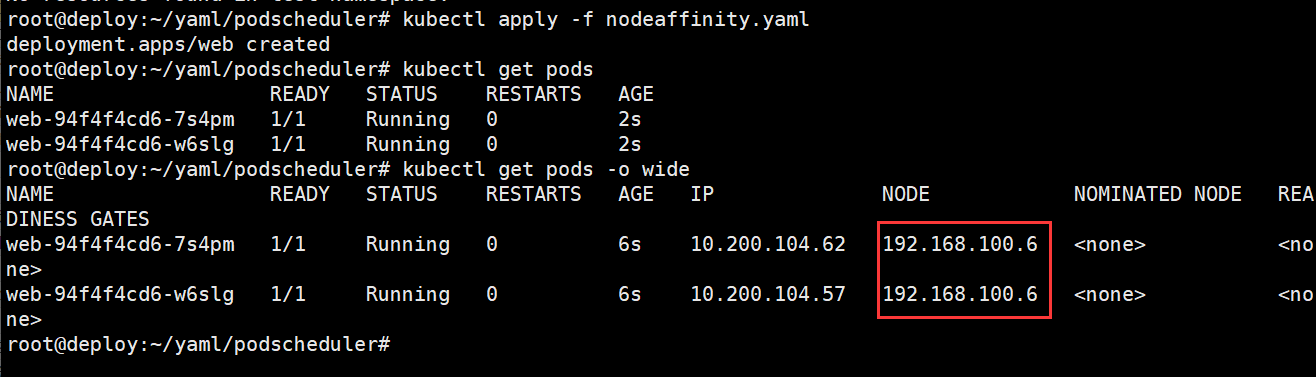
查看节点调度
节点反亲和性NotIn匹配到100.5的标签env_role=dev,因此将pod调度到其他节点
pod间亲和性和反亲和性
Pod亲和性与反亲和性可以基于已经在node节点上运行的Pod的标签来约束新创建的Pod可以调度到的目的节点,注意不是基于node上的标签而是使用的已经运行在node上的pod标签匹配。
其规则的格式为如果node节点A已经运行了一个或多个满足调度新创建的Pod B的规则,那么新的Pod B在亲和的条件下会调度到A节点之上,而在反亲和性的情况下则不会调度到A节点至上
其中规则表示一个具有可选的关联命名空间列表的LabelSelector,之所以Pod亲和与反亲和需可以通过LabelSelector选择namespace,是因为Pod是命名空间限定的而node不属于任何nemespace所以node的亲和与反亲和不需要namespace,因此作用于Pod标签的标签选择算符必须指定选择算符应用在哪个命名空间。
从概念上讲,node节点是一个拓扑域(具有拓扑结构的域),比如k8s集群中的单台node节点、一个机架、 云供应商可用区、云供应商地理区域等,可以使用topologyKey来定义亲和或者反亲和的颗粒度是node级别还是可用区级别,以便kubernetes调度系统用来识别并选择正确的目的拓扑域。
Pod亲和性与反亲和性的合法操作符(operator)有:
In、NotIn、Exists、DoesNotExist。
在Pod亲和性和反亲和性配置中,在requiredDuringSchedulingIgnoredDuringExecution和preferredDuringSchedulingIgnoredDuringExecution中,topologyKey不允许为空(Empty topologyKey is not allowed.)。
对于requiredDuringSchedulingIgnoredDuringExecution要求的Pod反亲和性,准入控制器LimitPodHardAntiAffinityTopology被引入以确保topologyKey只能是 kubernetes.io/hostname,如果希望topologyKey也可用于其他定制拓扑逻辑,可以更改准入控制器或者禁用。
除上述情况外,topologyKey可以是任何合法的标签键。
yaml示例:
apiVersion: v1
kind: Pod
metadata:
name: with-pod-affinity
spec:
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: security
operator: In
values:
- S1
topologyKey: topology.kubernetes.io/zone
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100
podAffinityTerm:
labelSelector:
matchExpressions:
- key: security
operator: In
values:
- S2
topologyKey: topology.kubernetes.io/zone
namespace:
- test
containers:
- name: with-pod-affinity
image: k8s.gcr.io/pause:2.0
root@deploy:~/yaml/podscheduler# kubectl apply -f podaffinity.yaml
更实际的用例
Pod 间亲和性与反亲和性在与更高级别的集合(例如 ReplicaSet、StatefulSet、 Deployment等)一起使用时,它们可能更加有用。这些规则使得你可以配置一组工作负载,使其位于相同定义拓扑(例如,节点)中。
在下面的Redis缓存Deployment示例中,副本上设置了标签app=store。 podAntiAffinity规则告诉调度器避免将多个带有app=store标签的副本部署到同一节点上。因此,每个独立节点上会创建一个缓存实例。
apiVersion: apps/v1
kind: Deployment
metadata:
name: redis-cache
spec:
selector:
matchLabels:
app: store
replicas: 3
template:
metadata:
labels:
app: store
spec:
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- store
topologyKey: "kubernetes.io/hostname"
containers:
- name: redis-server
image: redis:3.2-alpine
下面的Deploymen用来提供Web服务器服务,会创建带有标签app=web-store的副本。Pod亲和性规则告诉调度器将副本放到运行有标签包含app=store Pod的节点上。Pod反亲和性规则告诉调度器不要在同一节点上放置多个app=web-store的服务器。
apiVersion: apps/v1
kind: Deployment
metadata:
name: web-server
spec:
selector:
matchLabels:
app: web-store
replicas: 3
template:
metadata:
labels:
app: web-store
spec:
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- web-store
topologyKey: "kubernetes.io/hostname"
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- store
topologyKey: "kubernetes.io/hostname"
containers:
- name: web-app
image: nginx:1.16-alpine
亲和性
软亲和
示例:
1、先创建一个应用,pod标签为app: web
root@deploy:~/yaml/podscheduler# cat podaffinity.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: web
name: web
namespace: test
spec:
replicas: 1
selector:
matchLabels:
app: web
template:
metadata:
labels:
app: web
spec:
containers:
- image: nginx
name: nginx
imagePullPolicy: IfNotPresent
当前pod调度在100.6节点

编写pod软亲和,匹配app: web标签pod,将新创建的pod调度在该pod标签上的节点
root@deploy:~/yaml/podscheduler# cat podaffinitypreexecution.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: nginx-lable
name: nginx-deployment
namespace: test
spec:
replicas: 2
selector:
matchLabels:
app: nginx-lable
template:
metadata:
labels:
app: nginx-lable
spec:
containers:
- image: nginx
name: nginx
imagePullPolicy: IfNotPresent
affinity:
podAffinity: #Pod亲和
preferredDuringSchedulingIgnoredDuringExecution: #软亲和,能匹配成功就调度到一个topology,匹配不成功会由kubernetes自行调度。
- weight: 100
podAffinityTerm:
labelSelector: #标签选择
matchExpressions: #正则匹配
- key: app
operator: In
values:
- web
topologyKey: kubernetes.io/hostname
namespaces:
- test
验证:
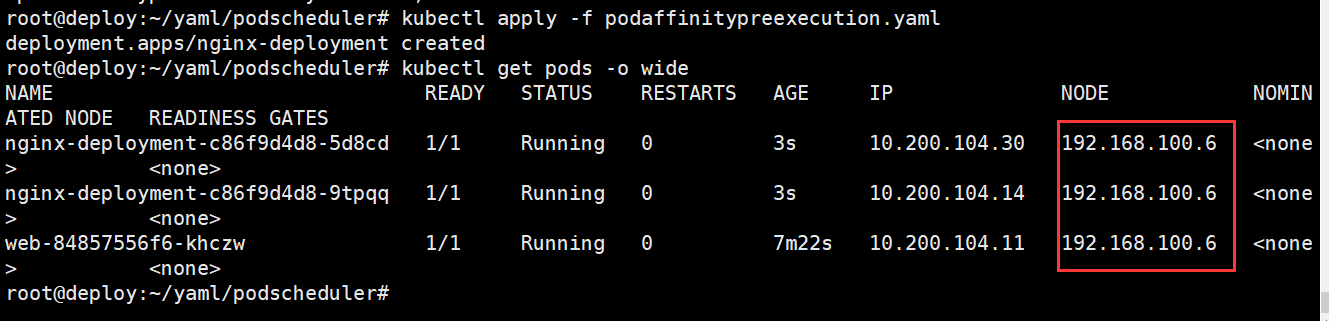
新创建的pod调度在了标签为app: web的pod上的100.6节点服务器
硬亲和
示例:
1、先创建一个应用,pod标签为app: web
root@deploy:~/yaml/podscheduler# cat podaffinity.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: web
name: web
namespace: test
spec:
replicas: 1
selector:
matchLabels:
app: web
template:
metadata:
labels:
app: web
spec:
containers:
- image: nginx
name: nginx
imagePullPolicy: IfNotPresent
当前pod调度在100.6节点

编写pod硬亲和,匹配app: web标签pod,将新创建的pod调度在该pod标签上的节点
root@deploy:~/yaml/podscheduler# cat podaffinityrequire.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: nginx-lable
name: nginx-require-deployment
namespace: test
spec:
replicas: 2
selector:
matchLabels:
app: nginx-lable
template:
metadata:
labels:
app: nginx-lable
spec:
containers:
- image: nginx
name: nginx
imagePullPolicy: IfNotPresent
affinity:
podAffinity: #Pod亲和
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector: #标签选择
matchExpressions: #正则匹配
- key: app
operator: In
values:
- web
topologyKey: kubernetes.io/hostname
namespaces:
- test
验证:
新创建的pod调度在了标签为app: web的pod上的100.6节点服务器
反亲和
基于硬反亲或软反亲和实现多个pod调度不在一个node
硬反亲和
示例:
1、先创建一个应用,pod标签为app: web
root@deploy:~/yaml/podscheduler# cat podaffinity.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: web
name: web
namespace: test
spec:
replicas: 1
selector:
matchLabels:
app: web
template:
metadata:
labels:
app: web
spec:
containers:
- image: nginx
name: nginx
imagePullPolicy: IfNotPresent
当前pod调度在100.6节点

编写pod硬反亲和,如果匹配app: web标签pod,将新创建的pod调度在其他节点非pod标签匹配的节点
root@deploy:~/yaml/podscheduler# cat podantiaffinityrequire.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: nginx-lable
name: nginx-anti-require-deployment
namespace: test
spec:
replicas: 2
selector:
matchLabels:
app: nginx-lable
template:
metadata:
labels:
app: nginx-lable
spec:
containers:
- image: nginx
name: nginx
imagePullPolicy: IfNotPresent
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- web
topologyKey: "kubernetes.io/hostname"
验证:
新创建的pod调度在了其他k8s集群node节点,非在匹配pod标签所在的运行的节点

软反亲和
示例:
1、先创建一个应用,pod标签为app: web
root@deploy:~/yaml/podscheduler# cat podaffinity.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: web
name: web
namespace: test
spec:
replicas: 1
selector:
matchLabels:
app: web
template:
metadata:
labels:
app: web
spec:
containers:
- image: nginx
name: nginx
imagePullPolicy: IfNotPresent
当前pod调度在100.6节点

编写pod软反亲和,如果匹配app: web标签pod,将新创建的pod调度在其他节点非pod标签匹配的节点
root@deploy:~/yaml/podscheduler# cat podantiaffinitypreexecution.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: nginx-lable
name: nginx-anti-deployment
namespace: test
spec:
replicas: 2
selector:
matchLabels:
app: nginx-lable
template:
metadata:
labels:
app: nginx-lable
spec:
containers:
- image: nginx
name: nginx
imagePullPolicy: IfNotPresent
affinity:
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100
podAffinityTerm:
labelSelector:
matchExpressions:
- key: app
operator: In
values:
- web
topologyKey: kubernetes.io/hostname
验证:
新创建的pod调度在了其他k8s集群node节点,非在匹配pod标签所在的运行的节点

污点和污点容忍
污点
1、基本介绍
污点
Taint污点:节点不做普通分配调度,是属于节点属性。用于node节点排斥 Pod调度,与亲和的作用是完全相反的,即taint的node和pod是排斥调度关系。
nodeAffinity是Pod的一种属性,用于Pod过滤特定的节点 。
Taint(污点),则相反,用于节点允许特定Pod在本机运行,未匹配的Pod则不能在该节点运行。
污点容忍
容忍(toleration),用于Pod容忍node节点的污点信息,即node有污点信息也会将新的pod调度到node。
污点和容忍度相互配合,可以用来避免Pod被分配到不合适的节点上。每个节点上都可以应用一个或多个污点,这表示对于那些不能容忍这些污点的Pod,是不会被该节点接受的。
2、场景
专用节点
配置特点硬件节点
基于Taint驱逐
3、使用命令
(1)查看节点污点
[root@master ~]# kubectl describe node worker01 |grep -i taint
Taints: <none>
[root@master ~]# kubectl describe node master |grep -i taint
Taints: node-role.kubernetes.io/master:NoSchedule
operator可选值:
Equal,默认值,容忍度和污点的键值对相同,则“匹配”。
Exists,此时容忍度不能指定value,只要污点中存在key,则容忍度和污点相“匹配”
operator的默认值是 Equal。
一个容忍度和一个污点相“匹配”是指它们有一样的键名和效果,并且:
如果operator是Exists(此时容忍度不能指定value),或者
如果operator是Equal ,则它们的value应该相等
污点值(effect)有三个
NoSchedule:表示k8s将不会将Pod调度到具有该污点的Node上
PreferNoSchdule:尽量不被调度。系统会尽量避免将Pod调度到存在其不能容忍污点的节点上,但这不是强制的。
NoExecute:表示k8s将不会将Pod调度到具有该污点的Node上,同时会将Node上已经存在的Pod强制驱逐出去
空:则可以与所有键名key1第一个key的效果匹配
注意:如果容忍度的key为空且operator为Exists,表示这个容忍度与任意的key、value和effect都匹配,即这个容忍度能容忍任意taint。
(2)为节点添加污点
语法:kubectl taint node [节点名称] key=value:污点三个值
添加worker01节点的污点,防止该节点被pod调度
[root@master ~]# kubectl taint node worker01 env_role=yes:NoSchedule
node/worker01 tainted
[root@master ~]# kubectl describe node worker01 |grep Taint
Taints: env_role=yes:NoSchedule
#创建deployment,并分配5个副本
[root@master ~]# kubectl create deployment web --image=nginx
deployment.apps/web created
[root@master ~]# kubectl scale deployment --replicas=5
#worker01没有被调度
[root@master ~]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
web-96d5df5c8-jlrn8 1/1 Running 0 106s 10.224.30.71 worker02 <none> <none>
web-96d5df5c8-l5d4m 1/1 Running 0 106s 10.224.30.69 worker02 <none> <none>
web-96d5df5c8-ldxpq 1/1 Running 0 106s 10.224.30.72 worker02 <none> <none>
web-96d5df5c8-s557c 1/1 Running 0 2m17s 10.224.30.68 worker02 <none> <none>
web-96d5df5c8-t7xjg 1/1 Running 0 106s 10.224.30.70 worker02 <none> <none>
(3)删除污点
[root@master ~]# kubectl taint node worker01 env_role:NoSchedule-
node/worker01 untainted
污点容忍
节点如果配置了污点容忍,则pod的调度规则就是有几率会被其所调度,即使污点的value设置了NoSchedule。
污点容忍的配置主要是在yaml文件中,添加tolerations选项,key和value则是针对node节点中的污点key和value,并非节点的label
污点容忍示例:
Deployment:operator为“equal”匹配key和value
apiVersion: apps/v1
kind: Deployment
metadata:
creationTimestamp: null
labels:
app: web
name: web
spec:
replicas: 2
selector:
matchLabels:
app: web
strategy: {}
template:
metadata:
creationTimestamp: null
labels:
app: web
spec:
containers:
- image: nginx:1.17
name: nginx
imagePullPolicy: IfNotPresent
tolerations:
- key: "key1"
operator: "Equal"
value: "value1"
effect: "NoSchedule"
operator为“Exists”,存在key即容忍节点污点
apiVersion: apps/v1
kind: Deployment
metadata:
creationTimestamp: null
labels:
app: web
name: web
spec:
replicas: 2
selector:
matchLabels:
app: web
strategy: {}
template:
metadata:
creationTimestamp: null
labels:
app: web
spec:
containers:
- image: nginx:1.17
name: nginx
imagePullPolicy: IfNotPresent
tolerations:
- key: "key1"
operator: "Exists"
effect: "NoSchedule"
设置maser节点污点容忍,在master节点部署pod
查看master污点
root@deploy:/daemonset# kubectl get nodes
NAME STATUS ROLES AGE VERSION
192.168.100.2 Ready,SchedulingDisabled master 11d v1.24.3
192.168.100.5 Ready node 11d v1.24.3
192.168.100.6 Ready node 11d v1.24.3
root@deploy:/daemonset# kubectl describe node 192.168.100.2|grep -i taint
Taints: node.kubernetes.io/unschedulable:NoSchedule
apiVersion: apps/v1
kind: DaemonSet
metadata:
labels:
app: web
name: web
spec:
selector:
matchLabels:
app: web
template:
metadata:
labels:
app: web
spec:
containers:
- image: nginx
name: nginx
imagePullPolicy: IfNotPresent
tolerations:
- key: "node.kubernetes.io/unschedulable"
operator: "Exists"
effect: "NoSchedule"
多个容忍度和多个污点“匹配”
可以给一个节点添加多个污点,也可以给一个Pod添加多个容忍度设置。 Kubernetes处理多个污点和容忍度的过程就像一个过滤器:从一个节点的所有污点开始遍历,过滤掉那些Pod中存在与之相匹配的容忍度的污点。余下未被过滤的污点的effect值决定了Pod是否会被分配到该节点,特别是以下情况:
- 如果未被过滤的污点中存在至少一个effect值为NoSchedule的污点,则Kubernetes不会将Pod分配到该节点。
- 如果未被过滤的污点中不存在effect值为NoSchedule的污点,但是存在effect 值为PreferNoSchedule的污点,则Kubernetes会尝试不将Pod分配到该节点。
- 如果未被过滤的污点中存在至少一个effect值为NoExecute的污点,则Kubernetes不会将Pod分配到该节点(如果Pod还未在节点上运行),或者将Pod从该节点驱逐(如果Pod已经在节点上运行)。
示例:
设置多个污点:
[root@master ~]# kubectl taint nodes node1 host=node1:NoSchedule
[root@master ~]# kubectl taint nodes node1 host=node1:NoExecute
[root@master ~]# kubectl taint nodes node1 app=web:NoSchedule
[root@master ~]# kubectl taint nodes node2 host=node2:NoSchedule
apiVersion: v1
kind: Pod
metadata:
name: nginx
labels:
env: test
spec:
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent
tolerations:
- key: "host"
operator: "Equal"
value: "node1"
effect: "NoSchedule"
- key: "host"
operator: "Equal"
value: "node2"
effect: "NoExecute"
cordon和uncordon
cordon,标记node为不可调度,node将无法创建新的pod。
uncordon,取消标记为cordon的node
[root@master10 podschedule]# kubectl cordon node11
node/node11 cordoned
[root@master10 podschedule]# kubectl uncordon node11
node/node11 uncordoned 
drain驱逐
drain,驱逐node上pod,同时标记node为不可调度。
在对节点执行维护(例如内核升级、硬件维护等)之前,可以使用 kubectl drain 从节点安全地逐出所有Pods。安全的驱逐过程允许Pod的容器体面地终止,并确保满足指定的PodDisruptionBudgets
kubectl drain <node name>
默认不驱逐DaemonSet控制的pod,使用--ignore-daemonsets驱逐DaemonSet控制的pod
还可以使用以下选项驱逐特定pod:
--pod-selector='': Label selector to filter pods on the node
-l, --selector='': Selector (label query) to filter on
节点压力驱逐
介绍
https://kubernetes.io/zh/docs/concepts/scheduling-eviction/node-pressure-eviction/
节点压力驱逐是由各kubelet进程主动终止Pod,以回收节点上的内存、磁盘空间等资源的过程,kubelet监控当前node节点的CPU、内存、磁盘空间和文件系统的inode等资源,当这些资源中的一个或者多个达到特定的消耗水平,kubelet就会主动地将节点上一个或者多个Pod强制驱逐,以防止当前node节点资源无法正常分配而引发的OOM(OutOfMemory)。
节点压力驱逐的阈值查看:
kubelet配置文件:
root@master1:~# vim /var/lib/kubelet/config.yaml
…
evictionHard:
memory.available: 300Mi #节点上的可用内存已满足驱逐条件
#节点的根文件系统或镜像文件系统上的可用磁盘空间和inode已满足驱逐条件
imagefs.available: 15%
nodefs.available: 10%
nodefs.inodesFree: 5%
…
kubernetes的pod驱逐基于QoS(服务质量等级) , Qos等级包括目前包括以下三个:
1、Guaranteed:pods中的资源限制limits和request的值相等,等级最高、最后被驱逐。
例如:
containers:
- image: nginx
name: nginx
imagePullPolicy: IfNotPresent
resources:
requests:
memory: "256Mi"
cpu: "500m"
limits:
memory: "256Mi"
cpu: "500m"
2、Burstable:pods中的资源限制imit和request不相等,等级折中、中间被驱逐
例如:
containers:
- image: nginx
name: nginx
imagePullPolicy: IfNotPresent
resources:
requests:
memory: "512Mi"
cpu: "1000m"
limits:
memory: "256Mi"
cpu: "500m"
3、BestEffort:pods中没有资源限制,即resources为空,等级最低、最先被驱逐
驱逐条件
驱逐条件的形式为 [eviction-signal][operator][quantity],其中
eviction-signal:kubelet捕获node节点驱逐触发信号,进行判断是否驱逐,比如通过cgroupfs获取memory.available的值来进行下一步匹配。
operator:操作符,通过操作符对比条件是否匹配资源量是否触发驱逐
quantity:使用量,即基于指定的资源使用值进行判断,如memory.available: 300Mi、nodefs.available: 10%等。
例如,如果一个节点的总内存为10Gi 并且希望在可用内存低于1Gi时触发驱逐,则可以将驱逐条件定义为memory.available<10% 或memory.available< 1G。 不能同时使用二者。
当内存可以用空间低于10%或低于1G就会触发驱逐信号
软驱逐:
软驱逐不会立即驱逐pod,可以自定义宽限期,在条件持续到宽限期还没有恢复,kubelet再强制杀死pod并触发驱逐:
软驱逐条件:
eviction-soft:软驱逐触发条件,比如memory.available < 1.5Gi,如果驱逐条件持续时长超过指定的宽限期,可以触发Pod驱逐。
eviction-soft-grace-period:软驱逐宽限期,如memory.available=1m30s,定义软驱逐条件在触发Pod驱逐之前必须保持多长时间。
eviction-max-pod-grace-period:终止pod的宽限期,即在满足软驱逐条件而终止Pod时使用的最大允许宽限期(以秒为单位)。
硬驱逐
硬驱逐条件没有宽限期,当达到硬驱逐条件时,kubelet会强制立即杀死pod并驱逐:
kubelet具有以下默认硬驱逐条件(可以自行调整):
memory.available<100Mi
nodefs.available<10%
imagefs.available<15%
nodefs.inodesFree<5%(Linux 节点)
本文来自博客园,作者:PunchLinux,转载请注明原文链接:https://www.cnblogs.com/punchlinux/p/16625700.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号