k8s构建zookeeper集群
介绍
ZooKeeper是Apache软件基金会的一个软件项目,它为大型分布式计算提供开源的分布式配置服务、同步服务和命名注册。
ZooKeeper的架构通过冗余服务实现高可用性。
Zookeeper的设计目标是将那些复杂且容易出错的分布式一致性服务封装起来,构成一个高效可靠的原语集,并以一系列简单易用的接口提供给用户使用。
一个典型的分布式数据一致性的解决方案,分布式应用程序可以基于它实现诸如数据发布/订阅、负载均衡、命名服务、分布式协调/通知、集群管理、Master 选举、分布式锁和分布式队列等功能。
读写数据流程
1、读数据流程
当Client向zookeeper发出读请求时,无论是Leader还是Follower,都直接返回查询结果
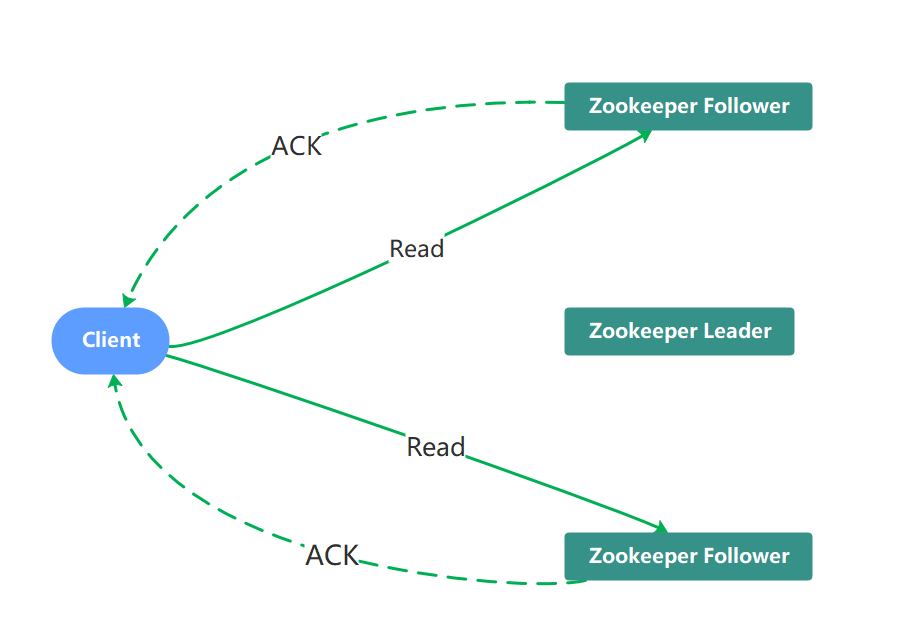
Zookeeper并不保证读取的是最新数据
如果是对zk进行读取操作,读取到的数据可能是过期的旧数据,不是最新的数据。
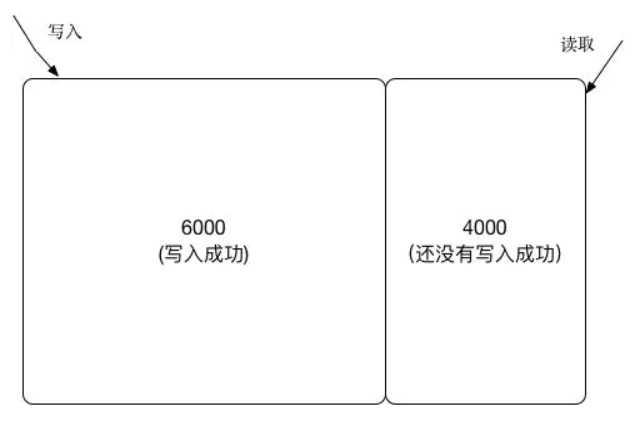
如果一个zk集群有10000台节点,当进行写入的时候,如果已经有6K个节点写入成功,zk就认为本次写请求成功。但是这时候如果一个客户端读取的刚好是另外4K个节点的数据,那么读取到的就是旧的过期数据。
2、写数据流程
zookeeper写入操作分为两种情况,这两种情况有略微的区别。
① 写入请求直接发送到leader节点;
② 写入请求发送到Follower节点。
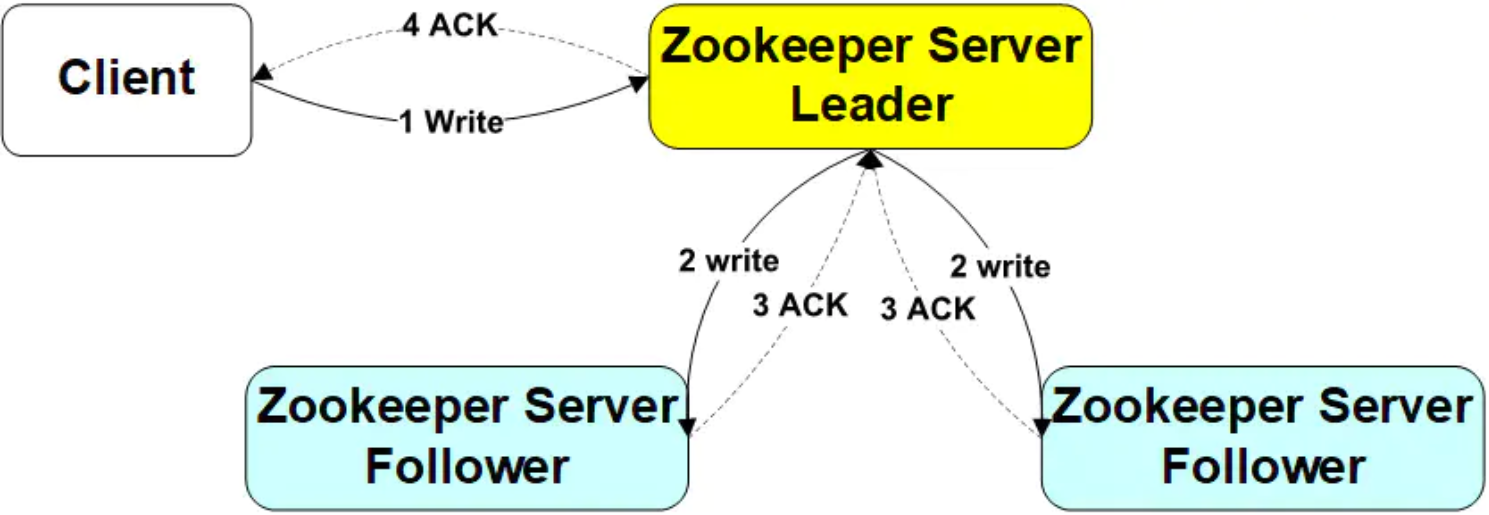
(1)写入请求直接发送到Leader节点时的操作步骤如下:
①Client向Leader发出写请求。
②Leader将数据写入到本节点,并将数据发送到所有的Follower节点;
③等待Follower节点返回;
④当Leader接收到一半以上节点(包含自己)返回写成功的信息之后,返回写入成功消息给client;
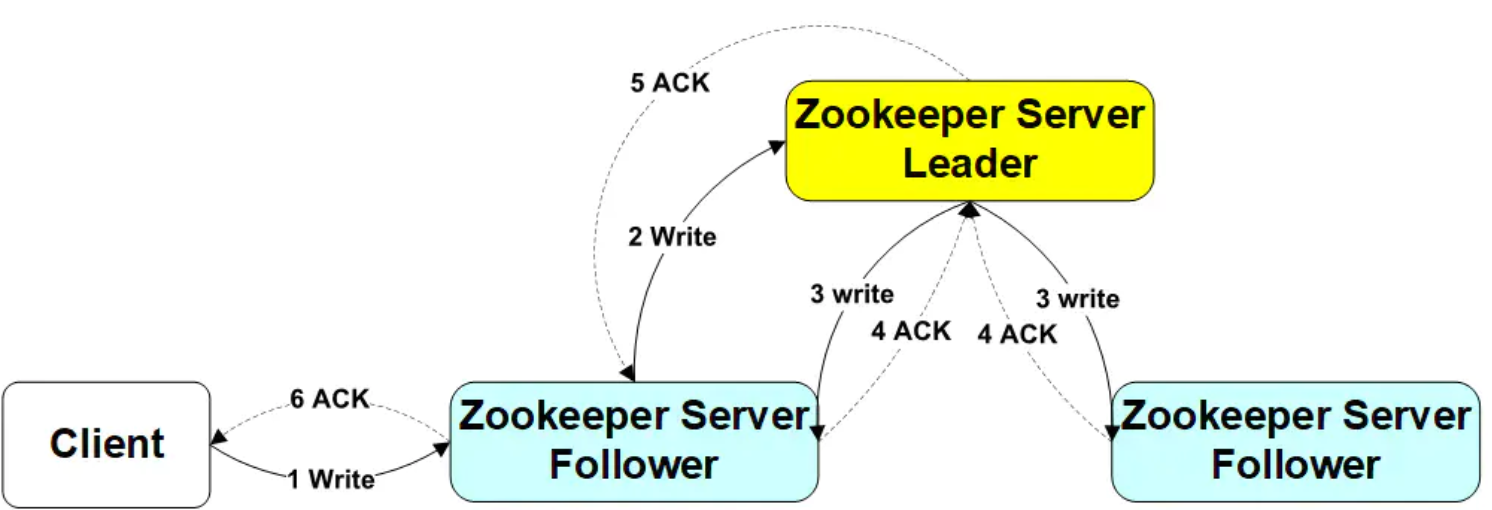
(2)写入请求发送到Follower节点的操作步骤如下:
①Client向Follower发出写请求
②Follower节点将请求转发给Leader
③Leader将数据写入到本节点,并将数据发送到所有的Follower节点
④等待Follower节点返回
⑤当Leader接收到一半以上节点(包含自己)返回写成功的信息之后,返回写入成功消息给原来的Follower
⑥原来的Follower返回写入成功消息给Client
Leader选举原理
zookeeper的leader选举存在两个阶段,一个是服务器启动时leader选举,另一个是运行过程中leader服务器宕机。在分析选举原理前,先介绍几个重要的参数。
服务器 ID(myid):编号越大在选举算法中权重越大
事务ID(zxid):值越大说明数据越新,权重越大
逻辑时钟(epoch-logicalclock):同一轮投票过程中的逻辑时钟值是相同的,每投完一次值会增加
选举状态:
LOOKING: 竞选状态
FOLLOWING: 随从状态,同步leader状态,参与投票
OBSERVING: 观察状态,同步leader状态,不参与投票
LEADING: 领导者状态
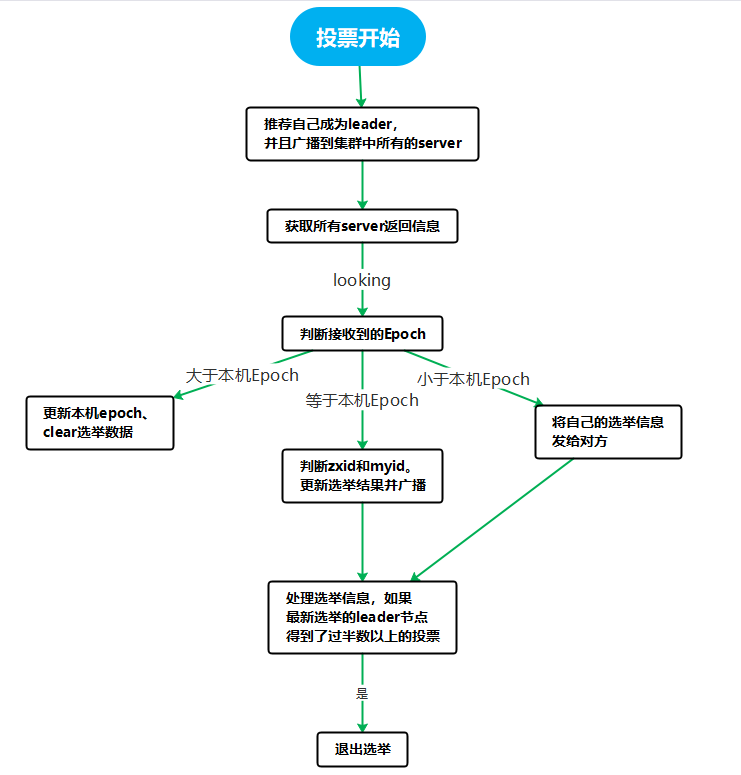
1、服务器启动时的leader选举
每个节点启动的时候都LOOKING观望状态,接下来就开始进行选举主流程。这里选取三台机器组成的集群为例。第一台服务器server启动时,无法进行leader选举,当第二台服务器server2启动时,两台机器可以相互通信,进入leader选举过程。
(1)每台server发出一个投票,由于是初始情况,server1和server2都将自己作为leader服务器进行投票,每次投票包含所推举的服务器myid、zxid、epoch,使用(myid,zxid)表示,此时server1投票为(1,0),server2 投票为(2,0),然后将各自投票发送给集群中其他机器。
(2)接收来自各个服务器的投票。集群中的每个服务器收到投票后,首先判断该投票的有效性,如检查是否是本轮投票(epoch)、是否来自LOOKING状态的服务器。
(3)分别处理投票。针对每一次投票,服务器都需要将其他服务器的投票和自己的投票进行对比,对比规则如下:
- 优先比较epoch
- 检查zxid,zxid比较大的服务器优先作为leader
- 如果zxid相同,那么就比较myid,myid较大的服务器作为leader服务器
(4)统计投票。每次投票后,服务器统计投票信息,判断是都有过半机器接收到相同的投票信息。server1、server2都统计出集群中有两台机器接受了(2,0)的投票信息,此时已经选出了server2为leader节点。
(5)改变服务器状态。一旦确定了leader,每个服务器响应更新自己的状态,如果是follower,那么就变更为FOLLOWING,如果是Leader,变更为 LEADING。此时server3继续启动,直接加入变更自己为FOLLOWING。
2、运行过程中的leader选举
当集群中leader服务器出现宕机或者不可用情况时,整个集群无法对外提供服务,进入新一轮的leader选举。
(1)变更状态。leader挂后,其他非Oberver服务器将自身服务器状态变更为LOOKING。
(2)每个server发出一个投票。在运行期间,每个服务器上zxid可能不同。
(3)处理投票。规则同启动过程。
(4)统计投票。与启动过程相同。
(5)改变服务器状态。与启动过程相同。
构建zookeeper集群案例
流程图
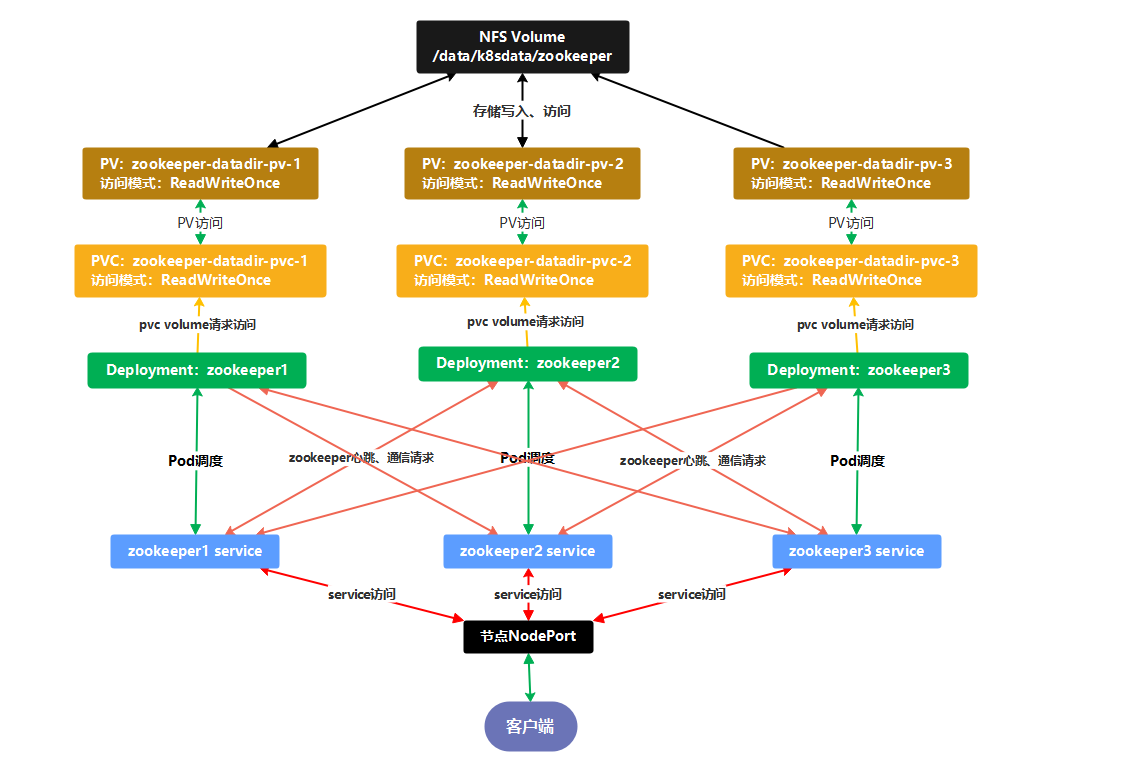
zookeeper镜像构建
1、创建zookeeper集群配置文件模板
创建zoo.cfg文件
root@master1:/dockerfile/project/zookeeper/conf# cat zoo.cfg
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/usr/local/zookeeper/data
dataLogDir=/usr/local/zookeeper/wal
#snapCount=100000
autopurge.purgeInterval=1
clientPort=2181
quorumListenOnAllIPs=true
日志配置文件
root@master1:/dockerfile/project/zookeeper/conf# cat log4j.properties
# Define some default values that can be overridden by system properties
zookeeper.root.logger=INFO, CONSOLE, ROLLINGFILE
zookeeper.console.threshold=INFO
zookeeper.log.dir=/usr/local/zookeeper/log
zookeeper.log.file=zookeeper.log
zookeeper.log.threshold=INFO
zookeeper.tracelog.dir=/usr/local/zookeeper/log
zookeeper.tracelog.file=zookeeper_trace.log
#
# ZooKeeper Logging Configuration
#
# Format is "<default threshold> (, <appender>)+
# DEFAULT: console appender only
log4j.rootLogger=${zookeeper.root.logger}
# Example with rolling log file
#log4j.rootLogger=DEBUG, CONSOLE, ROLLINGFILE
# Example with rolling log file and tracing
#log4j.rootLogger=TRACE, CONSOLE, ROLLINGFILE, TRACEFILE
#
# Log INFO level and above messages to the console
#
log4j.appender.CONSOLE=org.apache.log4j.ConsoleAppender
log4j.appender.CONSOLE.Threshold=${zookeeper.console.threshold}
log4j.appender.CONSOLE.layout=org.apache.log4j.PatternLayout
log4j.appender.CONSOLE.layout.ConversionPattern=%d{ISO8601} [myid:%X{myid}] - %-5p [%t:%C{1}@%L] - %m%n
#
# Add ROLLINGFILE to rootLogger to get log file output
# Log DEBUG level and above messages to a log file
log4j.appender.ROLLINGFILE=org.apache.log4j.RollingFileAppender
log4j.appender.ROLLINGFILE.Threshold=${zookeeper.log.threshold}
log4j.appender.ROLLINGFILE.File=${zookeeper.log.dir}/${zookeeper.log.file}
# Max log file size of 10MB
log4j.appender.ROLLINGFILE.MaxFileSize=10MB
# uncomment the next line to limit number of backup files
log4j.appender.ROLLINGFILE.MaxBackupIndex=5
log4j.appender.ROLLINGFILE.layout=org.apache.log4j.PatternLayout
log4j.appender.ROLLINGFILE.layout.ConversionPattern=%d{ISO8601} [myid:%X{myid}] - %-5p [%t:%C{1}@%L] - %m%n
#
# Add TRACEFILE to rootLogger to get log file output
# Log DEBUG level and above messages to a log file
log4j.appender.TRACEFILE=org.apache.log4j.FileAppender
log4j.appender.TRACEFILE.Threshold=TRACE
log4j.appender.TRACEFILE.File=${zookeeper.tracelog.dir}/${zookeeper.tracelog.file}
log4j.appender.TRACEFILE.layout=org.apache.log4j.PatternLayout
### Notice we are including log4j's NDC here (%x)
log4j.appender.TRACEFILE.layout.ConversionPattern=%d{ISO8601} [myid:%X{myid}] - %-5p [%t:%C{1}@%L][%x] - %m%n
创建zookeeper生成集群配置文件脚本
root@master1:/dockerfile/project/zookeeper# cat entrypoint.sh
#!/bin/bash
echo ${MYID:-0} > /usr/local/zookeeper/data/myid
#k8s zookeeper集群service名称
servers=(zookeeper1 zookeeper2 zookeeper3)
if [ -n "$servers" ]; then
for list in "${!servers[@]}"; do
printf "\nserver.%s = %s:2888:3888" "$((1 + $list))" "${servers[$list]}" >> /usr/local/zookeeper/conf/zoo.cfg
done
fi
exec "$@"
创建集群状态检查脚本
root@master1:/dockerfile/project/zookeeper# cat bin/zkReady.sh
#!/bin/bash
/usr/local/zookeeper/bin/zkServer.sh status | egrep 'Mode: (standalone|leader|follower|observing)'
创建dockerfile镜像文件
root@master1:/dockerfile/project/zookeeper# cat Dockerfile
FROM harbor.cncf.net/baseimages/jdk:1.8.191
ENV ZK_VERSION 3.5.10
COPY apache-zookeeper-3.5.10-bin.tar.gz /usr/local
RUN mkdir -p /usr/local/zookeeper/data /usr/local/zookeeper/wal /usr/local/zookeeper/log
RUN cd /usr/local/ && \
tar xf apache-zookeeper-3.5.10-bin.tar.gz -C /usr/local/zookeeper/ --strip-component=1 && \
rm -rf apache-zookeeper-3.5.10-bin.tar.gz
COPY conf /usr/local/zookeeper/conf/
COPY bin/zkReady.sh /usr/local/zookeeper/bin/
COPY entrypoint.sh /
ENV PATH=/usr/local/zookeeper/bin:${PATH} \
ZOO_LOG_DIR=/usr/local/zookeeper/log \
ZOO_LOG4J_PROP="INFO, CONSOLE, ROLLINGFILE" \
JMXPORT=9010
ENTRYPOINT [ "/entrypoint.sh" ]
CMD [ "zkServer.sh", "start-foreground" ]
EXPOSE 2181 2888 3888 9010
创建镜像构建脚本:
root@master1:/dockerfile/project/zookeeper# cat build-command.sh
#!/bin/bash
TAG=$1
nerdctl build -t harbor.cncf.net/project/zookeeper:${TAG} .
nerdctl push harbor.cncf.net/project/zookeeper:${TAG}
所有文件如下:
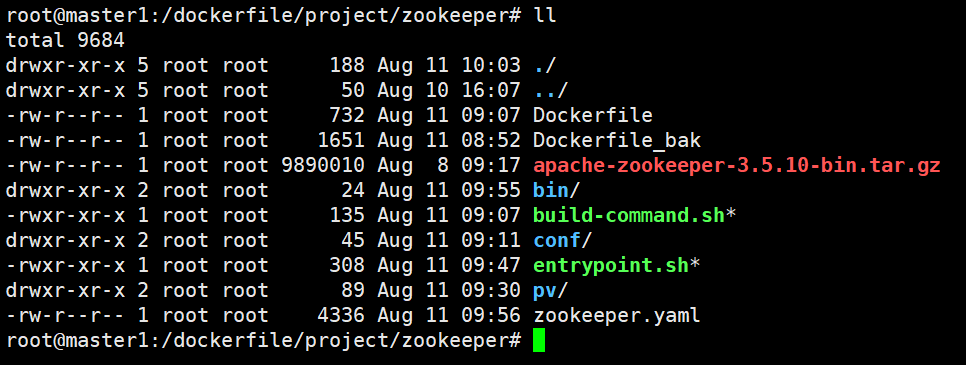
构建zookeeper镜像
root@master1:/dockerfile/project/zookeeper# ./build-command.sh 1.1.4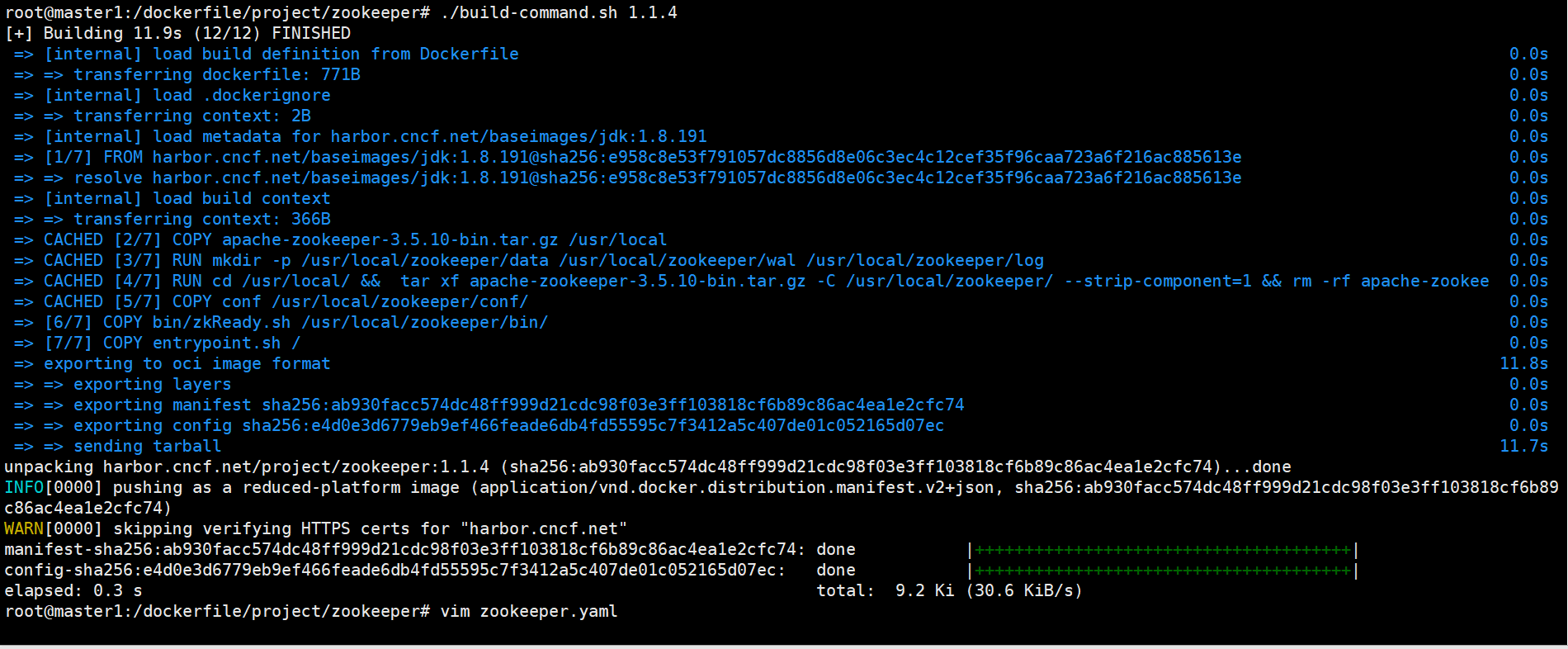
harbor仓库查看
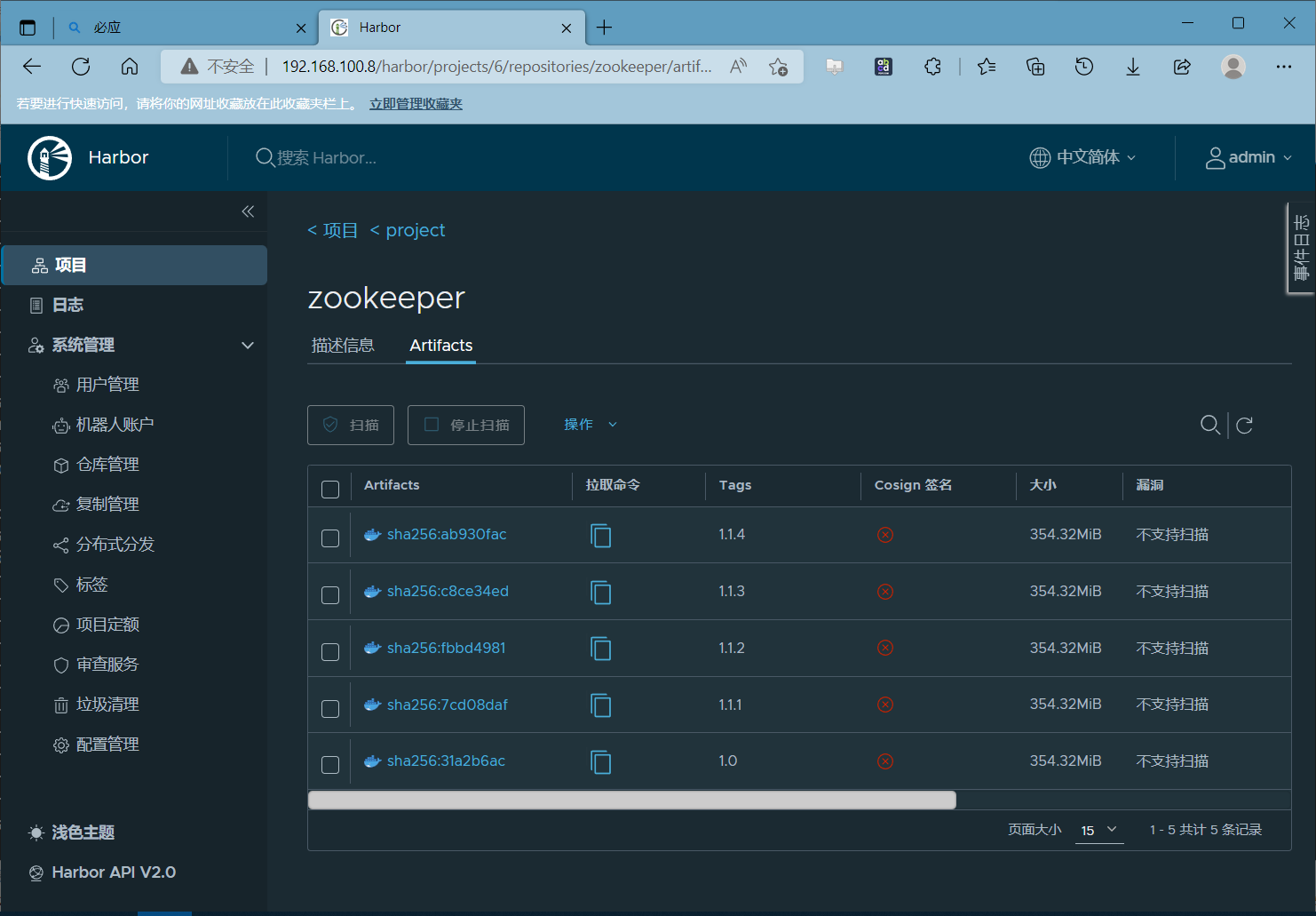
k8s资源构建
1、配置nfs server
先创建nfs文件共享目录
root@harbor:~# mkdir /data/k8sdata/zookeeper/zookeeper-datadir-{1..3} -p
配置目录共享
root@harbor:/data/k8sdata/zookeeper# cat /etc/exports
/data/k8sdata *(rw,sync,no_root_squash)
root@harbor:/data/k8sdata/zookeeper# exportfs -r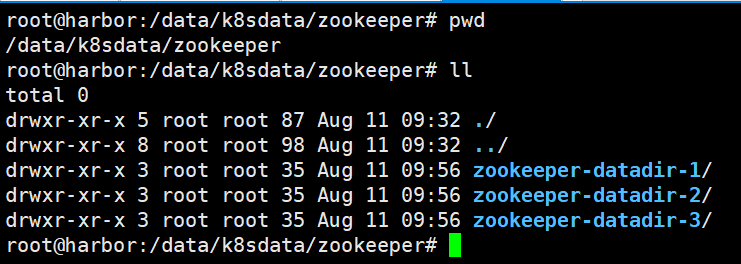
创建zookeeper集群pv
root@master1:/dockerfile/project/zookeeper/pv# cat zookeeper-persistentvolume.yaml
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: zookeeper-datadir-pv-1
spec:
capacity:
storage: 20Gi
accessModes:
- ReadWriteOnce
nfs:
server: 192.168.100.15
path: /data/k8sdata/zookeeper/zookeeper-datadir-1
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: zookeeper-datadir-pv-2
spec:
capacity:
storage: 20Gi
accessModes:
- ReadWriteOnce
nfs:
server: 192.168.100.15
path: /data/k8sdata/zookeeper/zookeeper-datadir-2
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: zookeeper-datadir-pv-3
spec:
capacity:
storage: 20Gi
accessModes:
- ReadWriteOnce
nfs:
server: 192.168.100.15
path: /data/k8sdata/zookeeper/zookeeper-datadir-3
root@master1:/dockerfile/project/zookeeper/pv# kubectl apply -f zookeeper-persistentvolume.yaml
创建zookeeper pvc
root@master1:/dockerfile/project/zookeeper/pv# cat zookeeper-persistentvolumeclaim.yaml
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: zookeeper-datadir-pvc-1
namespace: test
spec:
accessModes:
- ReadWriteOnce
volumeName: zookeeper-datadir-pv-1
resources:
requests:
storage: 10Gi
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: zookeeper-datadir-pvc-2
namespace: test
spec:
accessModes:
- ReadWriteOnce
volumeName: zookeeper-datadir-pv-2
resources:
requests:
storage: 10Gi
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: zookeeper-datadir-pvc-3
namespace: test
spec:
accessModes:
- ReadWriteOnce
volumeName: zookeeper-datadir-pv-3
resources:
requests:
storage: 10Gi
查看pvc构建绑定pv
root@master1:/dockerfile/project/zookeeper/pv# kubectl apply -f zookeeper-persistentvolumeclaim.yaml
persistentvolumeclaim/zookeeper-datadir-pvc-1 created
persistentvolumeclaim/zookeeper-datadir-pvc-2 created
persistentvolumeclaim/zookeeper-datadir-pvc-3 created
root@master1:/dockerfile/project/zookeeper/pv# kubectl get pvc
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
zookeeper-datadir-pvc-1 Bound zookeeper-datadir-pv-1 20Gi RWO 8s
zookeeper-datadir-pvc-2 Bound zookeeper-datadir-pv-2 20Gi RWO 8s
zookeeper-datadir-pvc-3 Bound zookeeper-datadir-pv-3 20Gi RWO 8s
创建zookeeper k8s资源清单文件 deployment和service
root@master1:/dockerfile/project/zookeeper# cat zookeeper.yaml
#所有zookeeper节点内网访问client
apiVersion: v1
kind: Service
metadata:
name: zookeeper
namespace: test
spec:
ports:
- name: client
port: 2181
selector:
app: zookeeper
---
#对外访问zookeeper1
apiVersion: v1
kind: Service
metadata:
name: zookeeper1
namespace: test
spec:
type: NodePort
ports:
- name: client
port: 2181
nodePort: 32181
- name: followers
port: 2888
- name: election
port: 3888
selector:
app: zookeeper
server-id: "1"
---
#对外访问zookeeper2
apiVersion: v1
kind: Service
metadata:
name: zookeeper2
namespace: test
spec:
type: NodePort
ports:
- name: client
port: 2181
nodePort: 32182
- name: followers
port: 2888
- name: election
port: 3888
selector:
app: zookeeper
server-id: "2"
---
#对外访问zookeeper3
apiVersion: v1
kind: Service
metadata:
name: zookeeper3
namespace: test
spec:
type: NodePort
ports:
- name: client
port: 2181
nodePort: 32183
- name: followers
port: 2888
- name: election
port: 3888
selector:
app: zookeeper
server-id: "3"
---
#创建zookeeper1
kind: Deployment
apiVersion: apps/v1
metadata:
name: zookeeper1
namespace: test
spec:
replicas: 1
selector:
matchLabels:
app: zookeeper
template:
metadata:
labels:
app: zookeeper
server-id: "1"
spec:
volumes:
- name: data
emptyDir: {}
- name: wal
emptyDir:
medium: Memory #预写日志数据持久化到内存
containers:
- name: server
image: harbor.cncf.net/project/zookeeper:1.1.4
imagePullPolicy: IfNotPresent
env:
- name: MYID
value: "1"
- name: JVMFLAGS
value: "-Xmx2G"
ports:
- containerPort: 2181
- containerPort: 2888
- containerPort: 3888
volumeMounts:
- mountPath: "/usr/local/zookeeper/data"
name: zookeeper-datadir-pvc-1
volumes:
- name: zookeeper-datadir-pvc-1
persistentVolumeClaim:
claimName: zookeeper-datadir-pvc-1
---
#创建zookeeper2实例
kind: Deployment
apiVersion: apps/v1
metadata:
name: zookeeper2
namespace: test
spec:
replicas: 1
selector:
matchLabels:
app: zookeeper
template:
metadata:
labels:
app: zookeeper
server-id: "2"
spec:
volumes:
- name: data
emptyDir: {}
- name: wal
emptyDir:
medium: Memory
containers:
- name: server
image: harbor.cncf.net/project/zookeeper:1.1.4
imagePullPolicy: IfNotPresent
env:
- name: MYID
value: "2"
- name: JVMFLAGS
value: "-Xmx2G"
ports:
- containerPort: 2181
- containerPort: 2888
- containerPort: 3888
volumeMounts:
- mountPath: "/usr/local/zookeeper/data"
name: zookeeper-datadir-pvc-2
volumes:
- name: zookeeper-datadir-pvc-2
persistentVolumeClaim:
claimName: zookeeper-datadir-pvc-2
---
#创建zookeeper3实例
kind: Deployment
apiVersion: apps/v1
metadata:
name: zookeeper3
namespace: test
spec:
replicas: 1
selector:
matchLabels:
app: zookeeper
template:
metadata:
labels:
app: zookeeper
server-id: "3"
spec:
volumes:
- name: data
emptyDir: {}
- name: wal
emptyDir:
medium: Memory
containers:
- name: server
image: harbor.cncf.net/project/zookeeper:1.1.4
imagePullPolicy: IfNotPresent
env:
- name: MYID
value: "3"
- name: JVMFLAGS
value: "-Xmx2G"
ports:
- containerPort: 2181
- containerPort: 2888
- containerPort: 3888
volumeMounts:
- mountPath: "/usr/local/zookeeper/data"
name: zookeeper-datadir-pvc-3
volumes:
- name: zookeeper-datadir-pvc-3
persistentVolumeClaim:
claimName: zookeeper-datadir-pvc-3
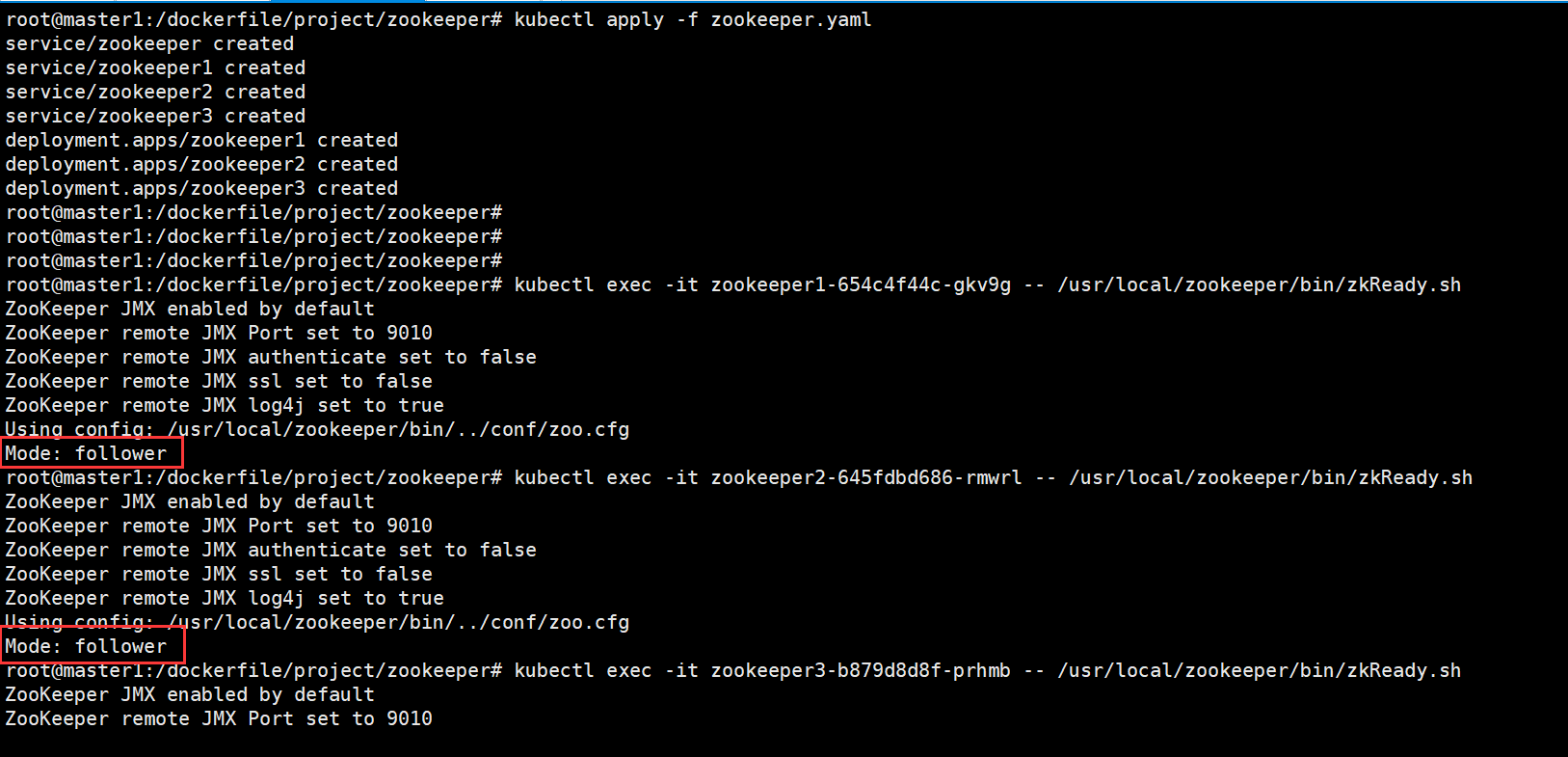
root@master1:/dockerfile/project/zookeeper# kubectl apply -f zookeeper.yaml
service/zookeeper created
service/zookeeper1 created
service/zookeeper2 created
service/zookeeper3 created
deployment.apps/zookeeper1 created
deployment.apps/zookeeper2 created
deployment.apps/zookeeper3 created
查看service

查看pod
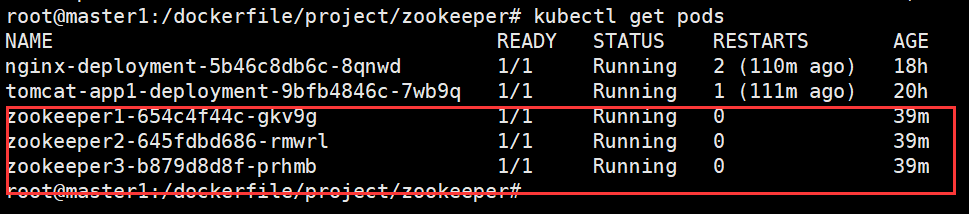
观察验证zookeeper集群模式,leader和follower
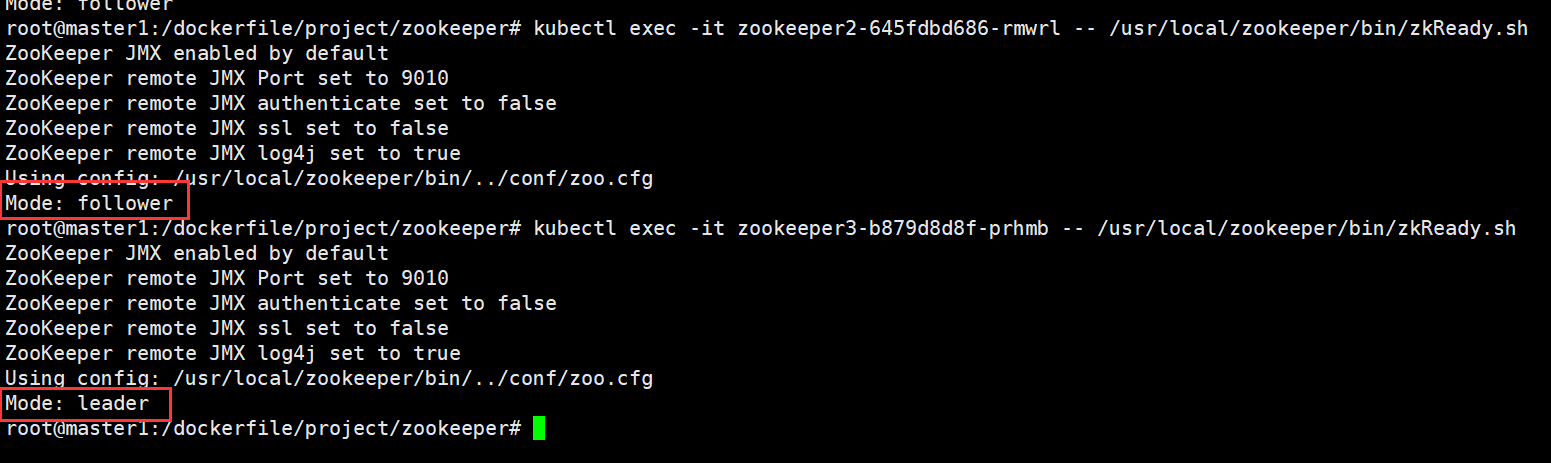
观察验证zookeeper集群模式,leader和follower
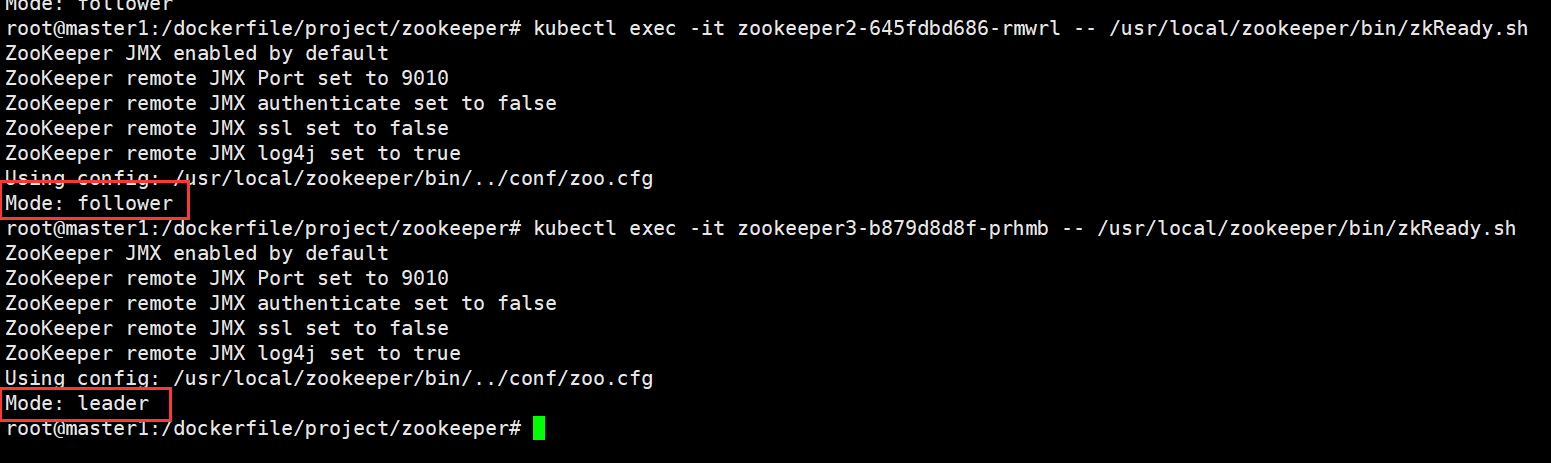
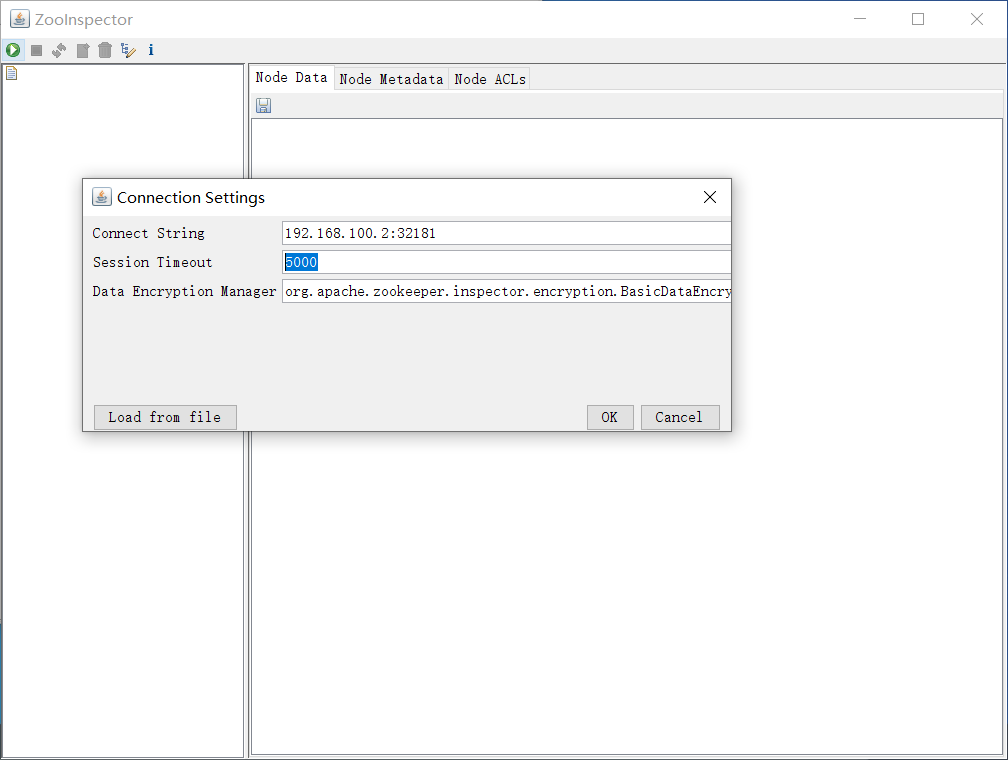
客户端链接测试
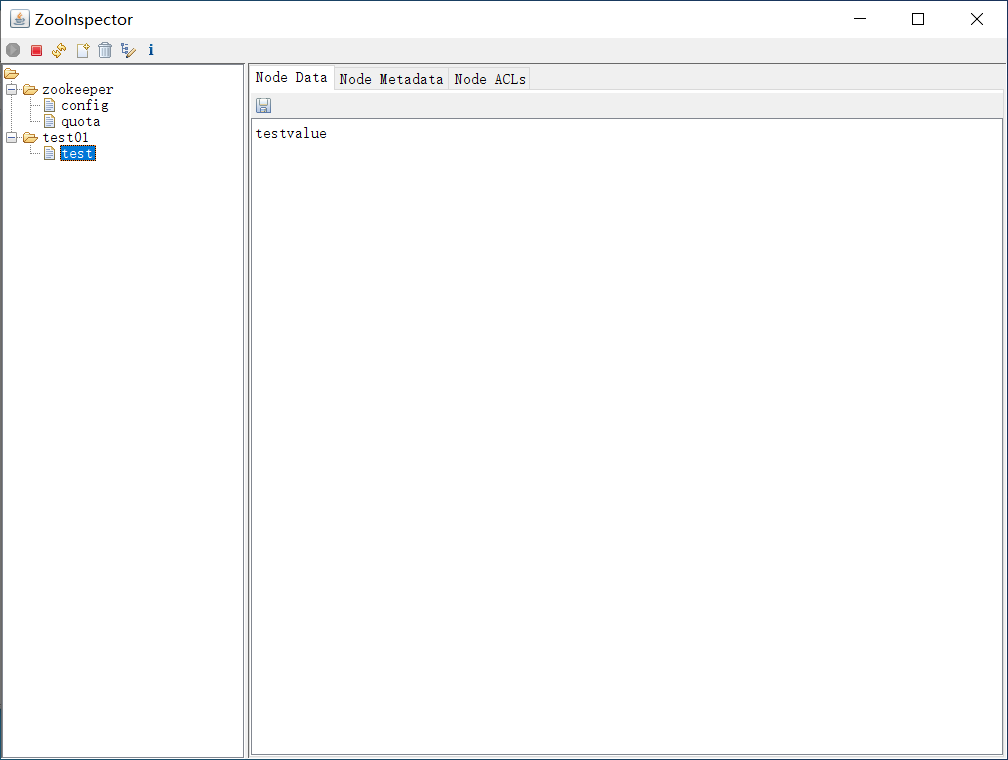
创建节点测试
本文来自博客园,作者:PunchLinux,转载请注明原文链接:https://www.cnblogs.com/punchlinux/p/16575844.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号