etcd的备份和恢复-基于快照
概述
etcd是一款开源、高度一致的分布式键值(key-value)存储系统。
etcd使用Go语言编写的。
etcd机器之间的通信通过Raft共识算法处理。
etcd是CoreOS公司于2013年6月发起的开源项目,于2018年12月正式加 入云原生计算基金会(CNCF-Cloud Native Computing Foundation),并由CNCF支持。
官网:https://etcd.io
github地址:https://github.com/etcd-io/etcd
官方硬件推荐:https://etcd.io/docs/v3.5/op-guide/hardware
官方文档:https://etcd.io/docs/v3.5/op-guide/maintenance
ETCD具有如下属性:
完全复制:集群中的每个节点都可以使用完整的存档
高可用性:Etcd可用于避免硬件的单点故障或网络问题
一致性:每次读取都会返回跨多主机的最新写入
简单:包括一个定义良好、面向用户的API(GRPC)
安全:实现了带有可选的客户端证书身份验证的自动化TLS
快速:每秒10000次写入的基准速度
可靠:使用Raft算法实现了存储的合理分布式Etcd的工作原理
ETCD 特点
- 读写性能强:按照官网给出的Benchmark,在2CPU、8G内存、SSD磁盘这样的配置下,单节点的写性能可以达到16K QPS, 而先写后读也能达到12K QPS。这个性能还是相当可观的。
- 简单:安装配置简单,而且提供了 HTTP API 进行交互,使用也很简单。
- 支持HTTPS:更安全可靠。
- 跨平台支持:支持不同系统。
- 二进制文件小和社区活跃。
ETCD的数据备份与恢复
手动恢复etcd集群
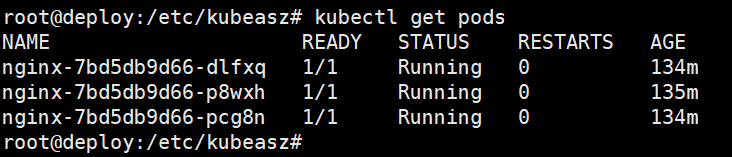
查看k8s pod
创建备份目录
root@etcd1:~# mkdir /backup
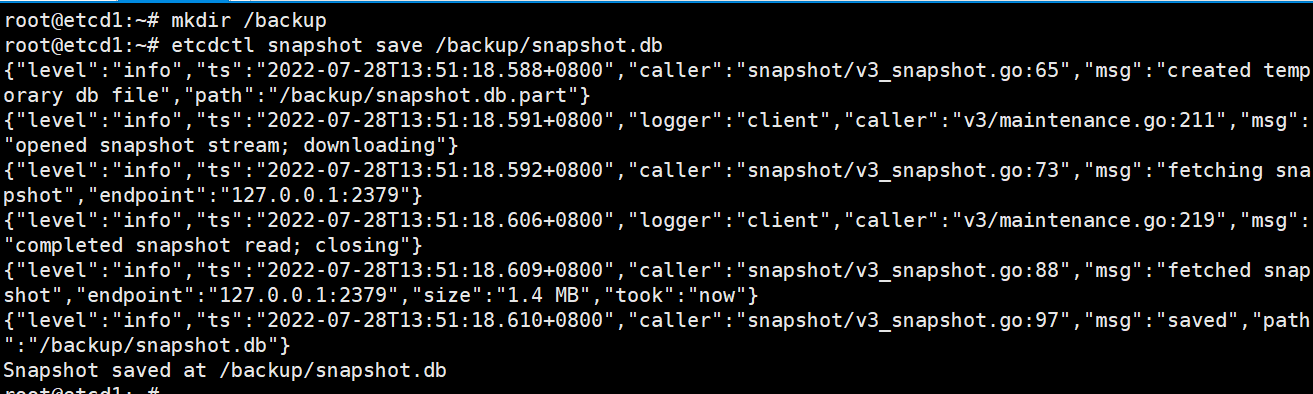
创建数据备份
root@etcd1:~# etcdctl snapshot save /backup/snapshot.db
{"level":"info","ts":"2022-07-28T13:51:18.588+0800","caller":"snapshot/v3_snapshot.go:65","msg":"created temporary db file","path":"/backup/snapshot.db.part"}
{"level":"info","ts":"2022-07-28T13:51:18.591+0800","logger":"client","caller":"v3/maintenance.go:211","msg":"opened snapshot stream; downloading"}
{"level":"info","ts":"2022-07-28T13:51:18.592+0800","caller":"snapshot/v3_snapshot.go:73","msg":"fetching snapshot","endpoint":"127.0.0.1:2379"}
{"level":"info","ts":"2022-07-28T13:51:18.606+0800","logger":"client","caller":"v3/maintenance.go:219","msg":"completed snapshot read; closing"}
{"level":"info","ts":"2022-07-28T13:51:18.609+0800","caller":"snapshot/v3_snapshot.go:88","msg":"fetched snapshot","endpoint":"127.0.0.1:2379","size":"1.4 MB","took":"now"}
{"level":"info","ts":"2022-07-28T13:51:18.610+0800","caller":"snapshot/v3_snapshot.go:97","msg":"saved","path":"/backup/snapshot.db"}
Snapshot saved at /backup/snapshot.db
删除deployment模拟故障
root@deploy:/etc/kubeasz# kubectl delete deployments.apps nginx
节点1恢复
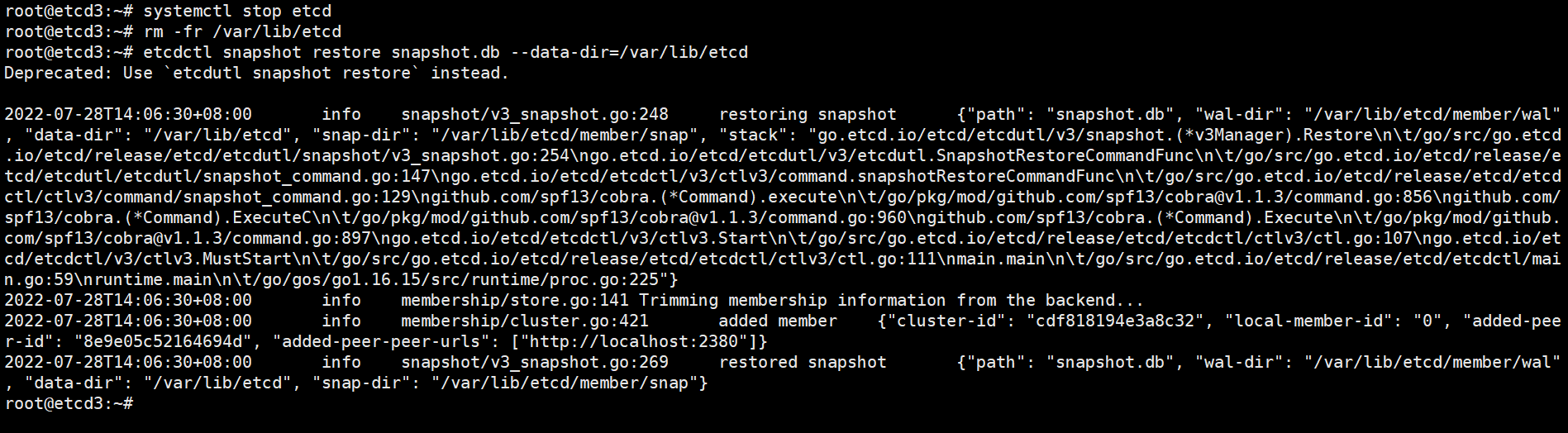
root@etcd1:~# systemctl stop etcd
root@etcd1:~# rm -fr /var/lib/etcd/
root@etcd1:~# etcdctl snapshot restore /backup/snapshot.db \
--name etcd-192.168.100.8 \
--initial-cluster=etcd-192.168.100.10=https://192.168.100.10:2380,etcd-192.168.100.8=https://192.168.100.8:2380,etcd-192.168.100.9=https://192.168.100.9:2380 \
--initial-cluster-token=etcd-cluster-0 \
--initial-advertise-peer-urls=https://192.168.100.8:2380 \
--data-dir=/var/lib/etcd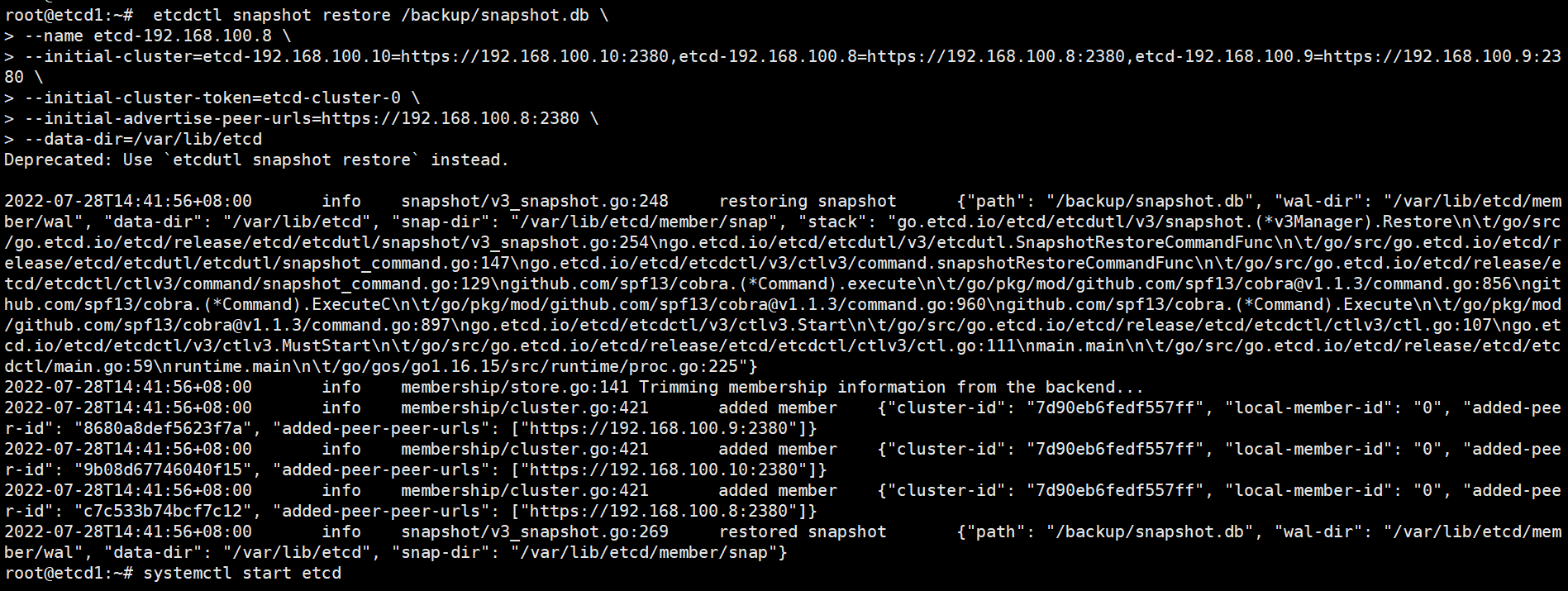
节点2恢复
root@etcd2:~# systemctl stop etcd
root@etcd2:~# rm -fr /var/lib/etcd/
root@etcd2:~# etcdctl snapshot restore /root/snapshot.db \
--name etcd-192.168.100.9 \
--initial-cluster=etcd-192.168.100.10=https://192.168.100.10:2380,etcd-192.168.100.8=https://192.168.100.8:2380,etcd-192.168.100.9=https://192.168.100.9:2380 \
--initial-cluster-token=etcd-cluster-0 \
--initial-advertise-peer-urls=https://192.168.100.9:2380 \
--data-dir=/var/lib/etcd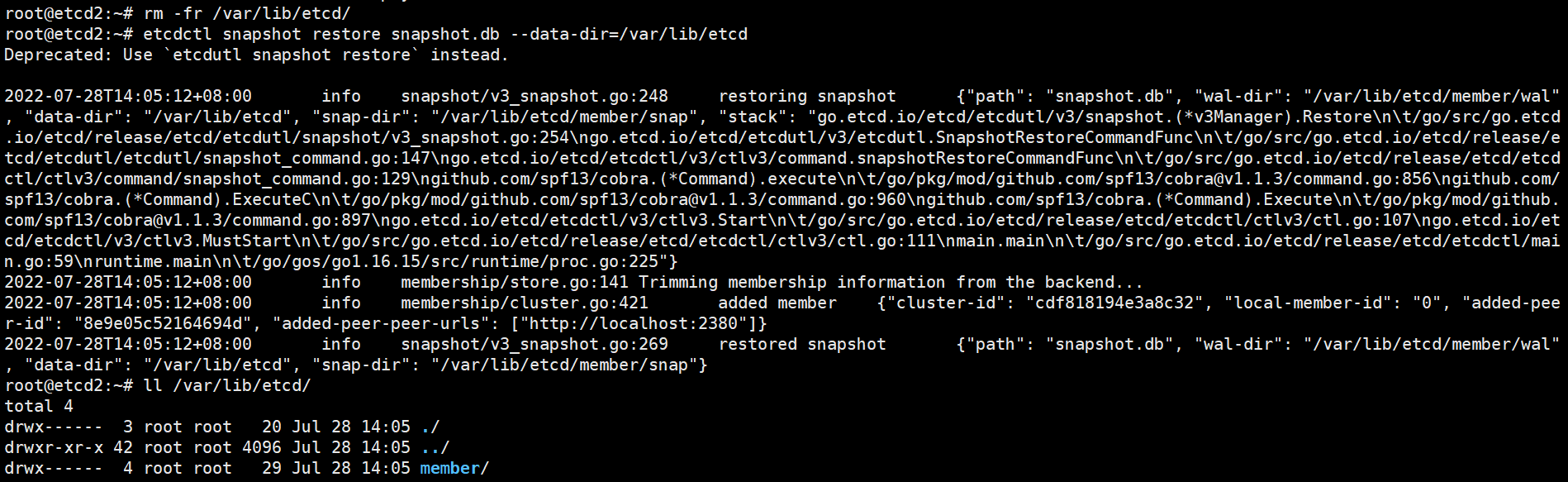
节点3恢复
root@etcd3:~# systemctl stop etcd
root@etcd3:~# rm -fr /var/lib/etcd
root@etcd3:~# etcdctl snapshot restore /root/snapshot.db \
--name etcd-192.168.100.10 \
--initial-cluster=etcd-192.168.100.10=https://192.168.100.10:2380,etcd-192.168.100.8=https://192.168.100.8:2380,etcd-192.168.100.9=https://192.168.100.9:2380 \
--initial-cluster-token=etcd-cluster-0 \
--initial-advertise-peer-urls=https://192.168.100.10:2380 \
--data-dir=/var/lib/etcd
集群节点同时启动etcd
systemctl start etcd
查看etcd集群状态
root@etcd1:~# export NODE_IPS="192.168.100.8 192.168.100.9 192.168.100.10"
root@etcd1:~# for n in ${NODE_IPS};do etcdctl --endpoints=https://${n}:2379 --cacert=/etc/kubernetes/ssl/ca.pem --cert=/etc/kubernetes/ssl/etcd.pem --key=/etc/kubernetes/ssl/etcd-key.pem --write-out=table endpoint status;done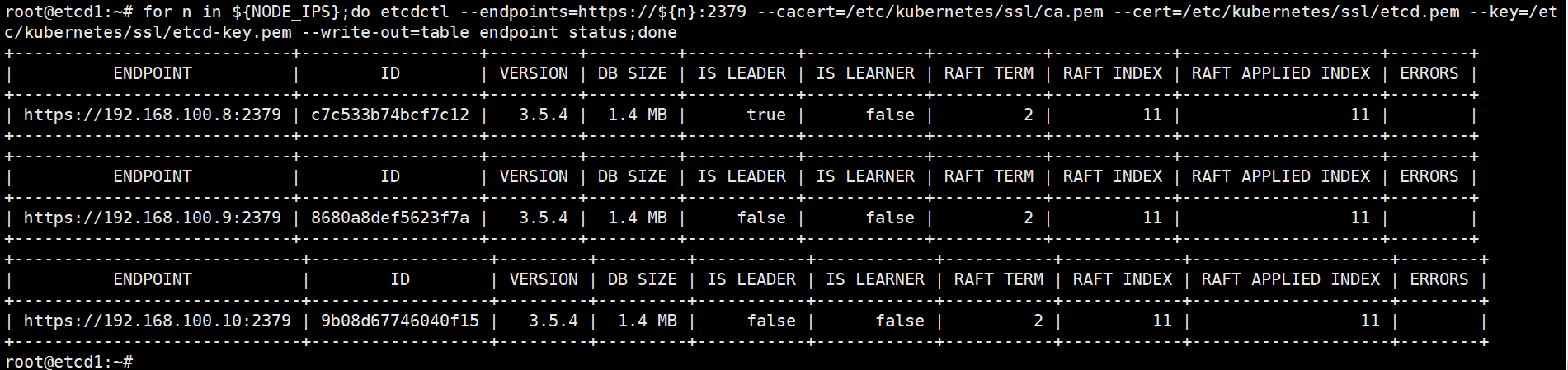
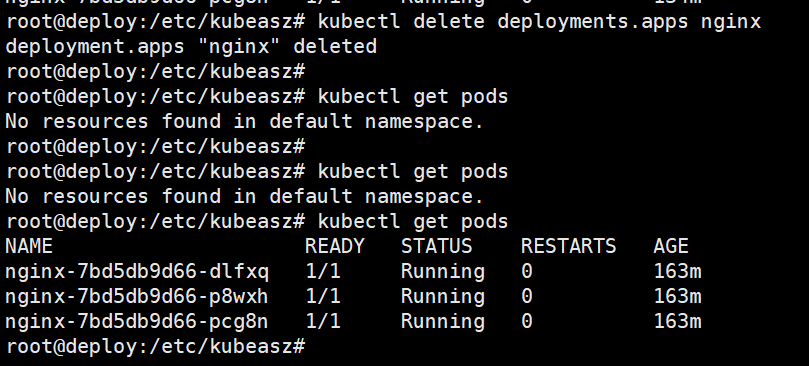
验证k8s pod是否恢复
kubeasz 集群备份与恢复
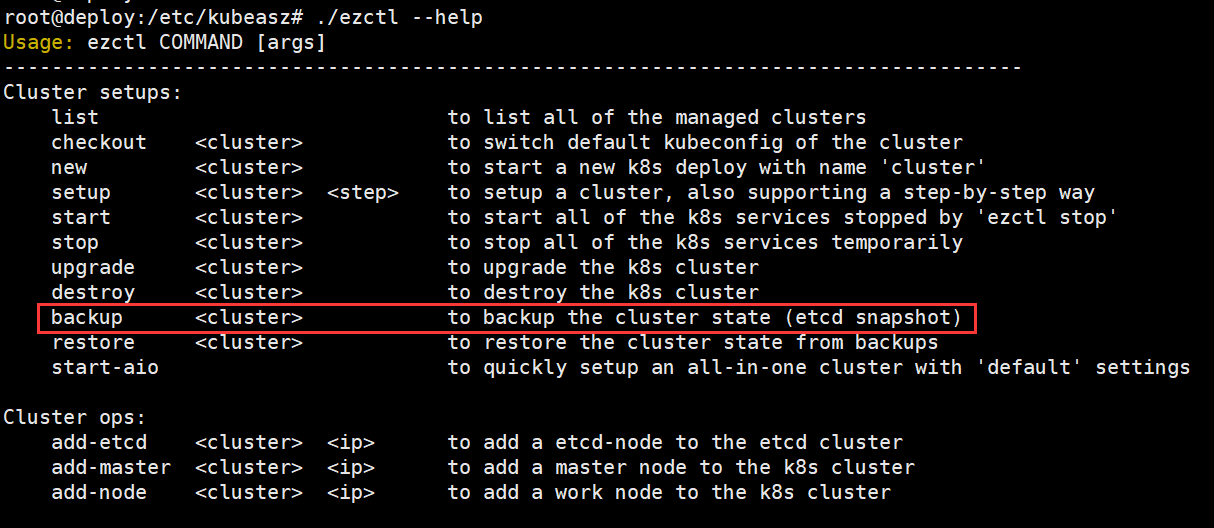
查看ezctl帮助信息
查看k8s pod
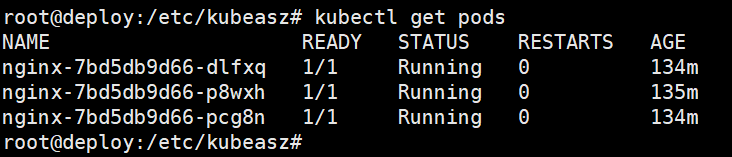
1、备份数据
使用ezctl备份etcd数据
root@deploy:/etc/kubeasz# ./ezctl backup k8s-cluster1
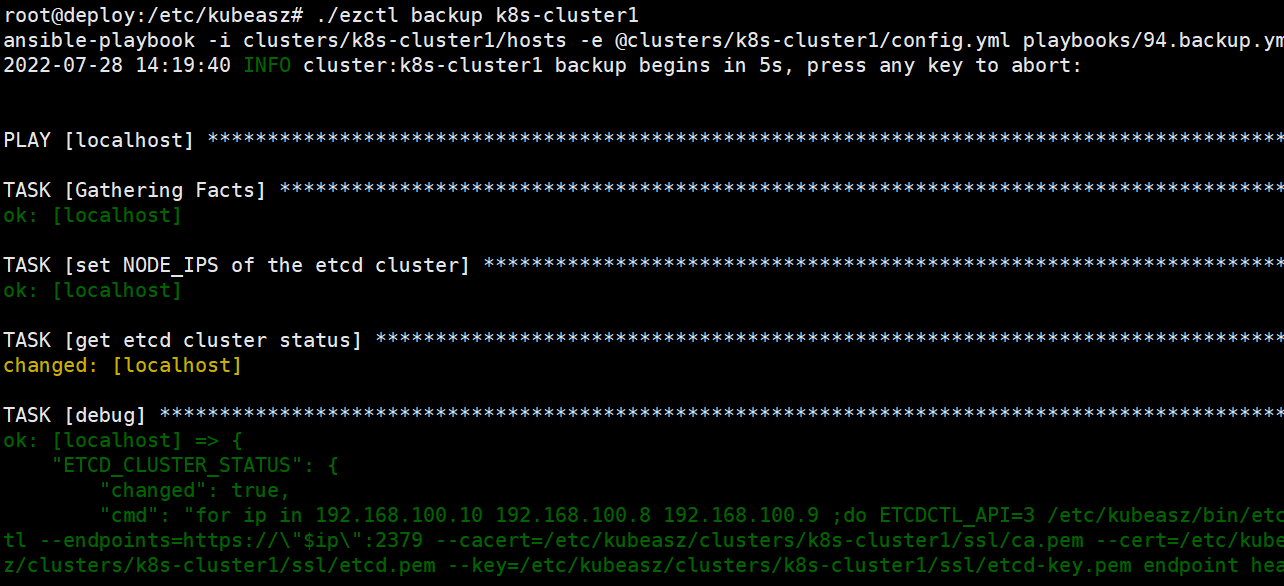
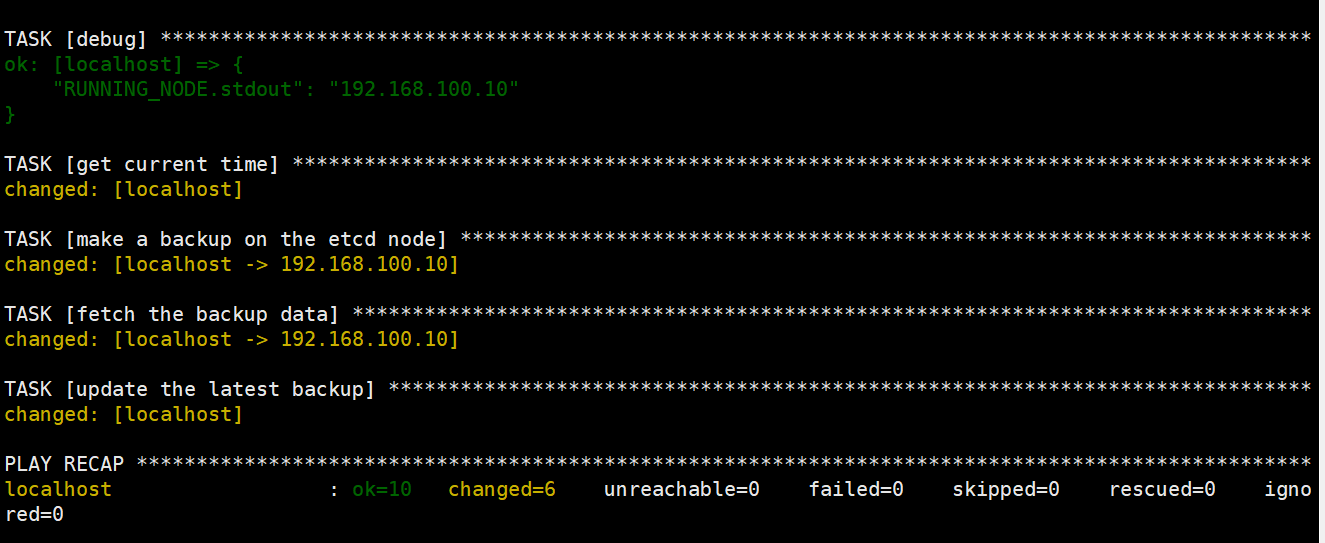
etcd数据备份到集群目录下的backup文件目录

etcd数据恢复机制:以当前时间戳命名最新的备份,并拷贝一份命名为snapshot.db作为最新恢复使用。ansible剧本具体实现
ansible备份剧本:
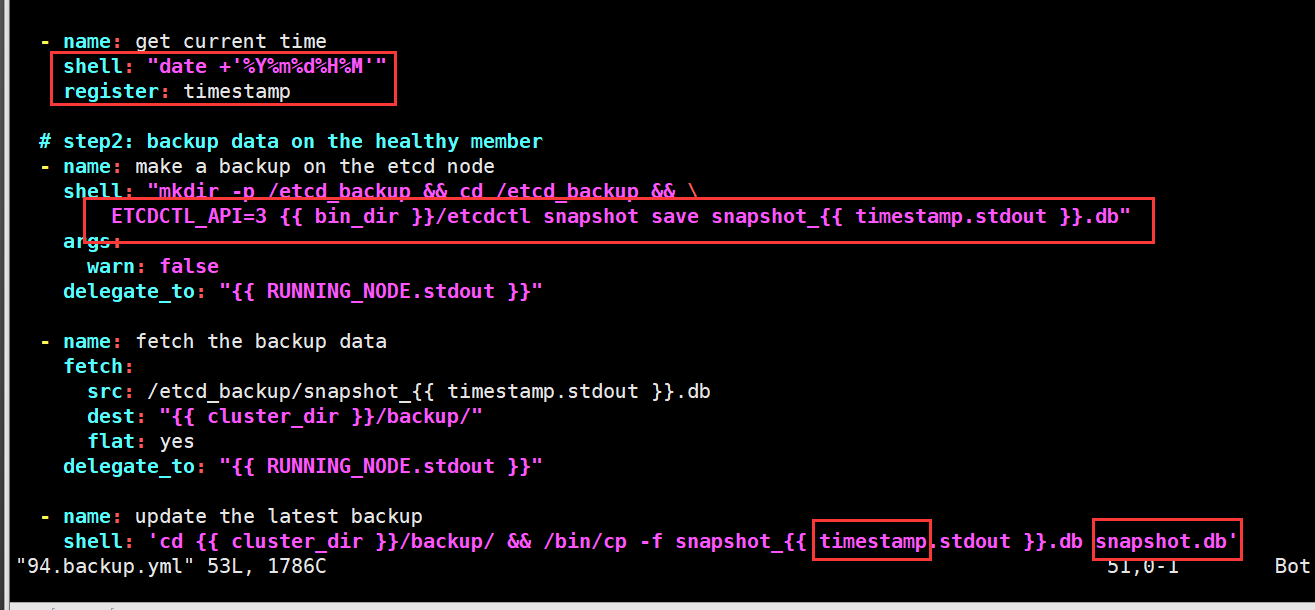

ansible恢复剧本:
/etc/kubeasz/roles/cluster-restore/tasks/main.yaml
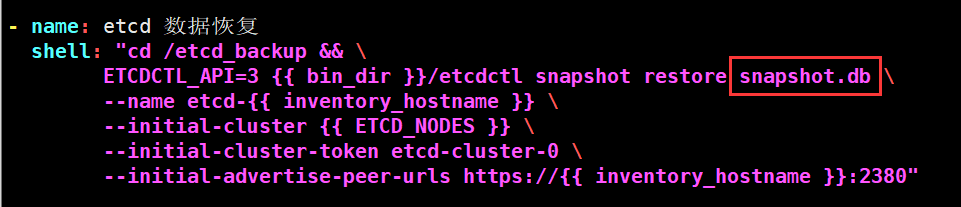
2、恢复数据
删除deployment模拟故障
root@deploy:/etc/kubeasz# kubectl delete deployments.apps nginx
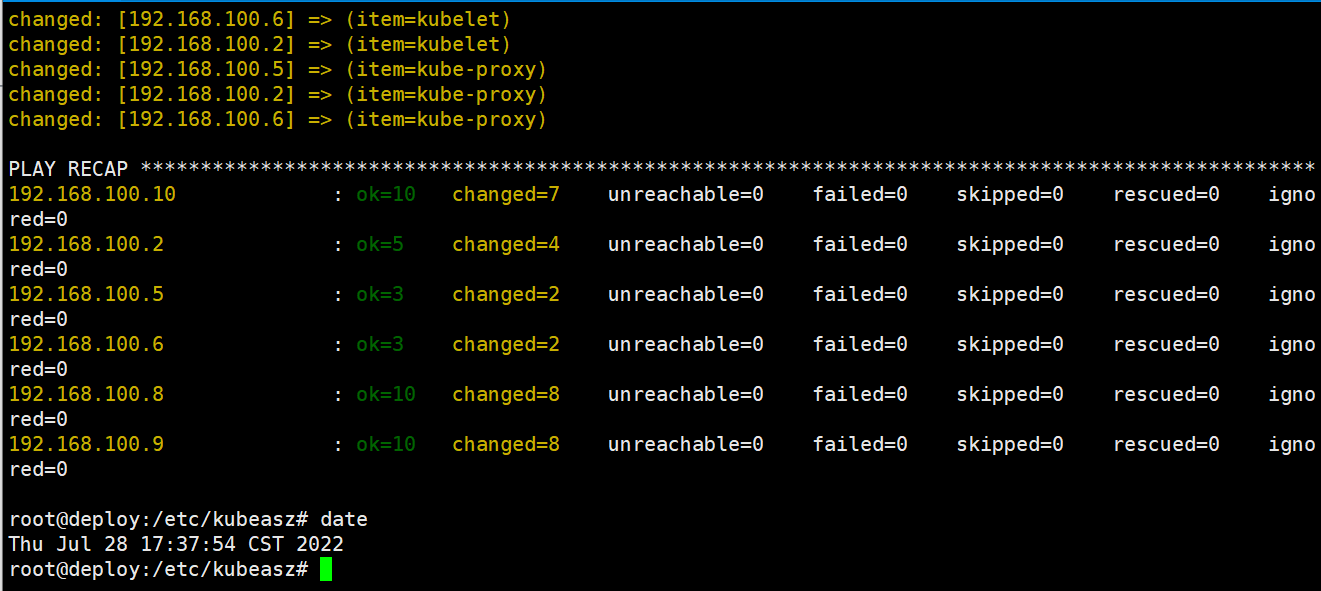
使用ezctl脚本自动化恢复etcd数据。恢复的数据是使用snapshot.db最新的备份进行恢复
root@deploy:/etc/kubeasz# ./ezctl restore k8s-cluster1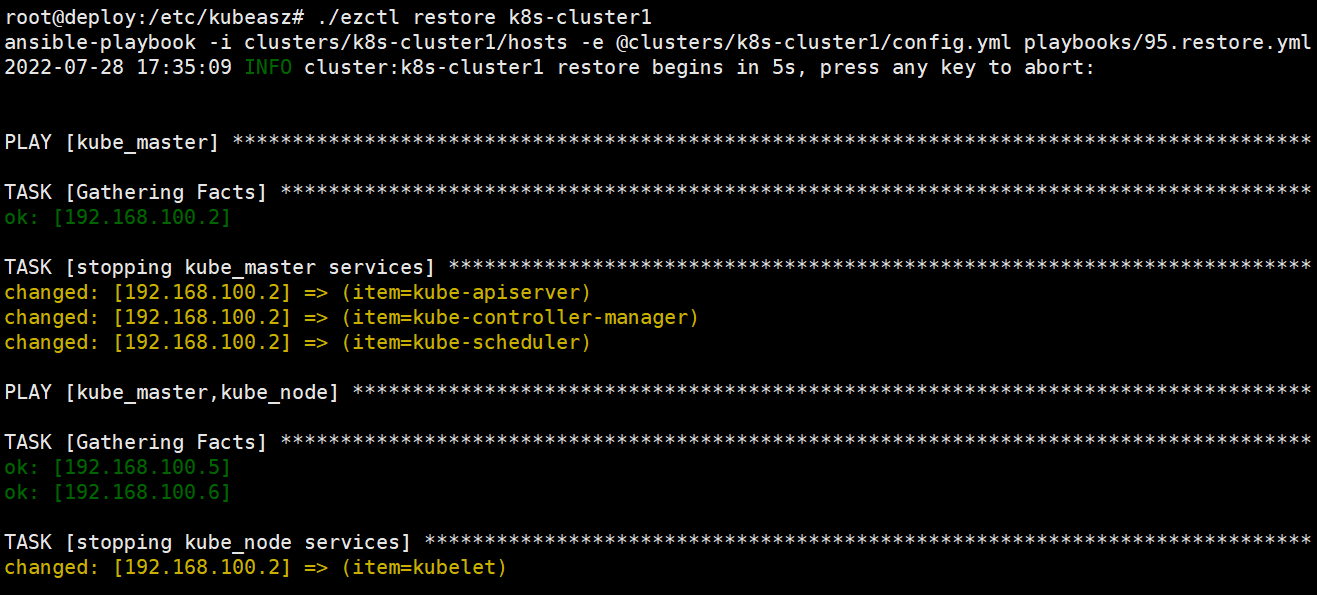
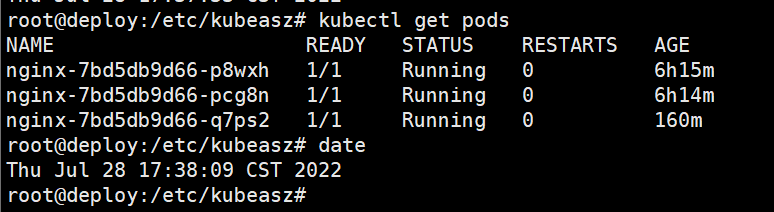
也可以根据历史备份的数据进行恢复
将过去的时间备份复制重新命名为snapshot.db作为脚本进行备份
root@deploy:/etc/kubeasz/clusters/k8s-cluster1/backup# cp snapshot_202207281742.db snapshot.db
root@deploy:/etc/kubeasz# ./ezctl restore k8s-cluster1
本文来自博客园,作者:PunchLinux,转载请注明原文链接:https://www.cnblogs.com/punchlinux/p/16531033.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号