

【代码回溯】回避反DDoS攻击重定向机制的python爬虫代码
人在江湖飘,总是会忘记很多旧事。
有些代码写完以后,下次见面变成了陌路之客。
---------------HLK
这里是代码回溯专题,主要是回忆我自己写的代码及原理,让自己不会忘记曾经写下的东西。
那么书接上回的爬虫程序,由于最近"爬某网站的图片"时,该网站开始使用了反DDos攻击的重定向机制,
所以导致用正常的requests.get方法没法取到代码,爬虫代码得绕一个大弯子了。
问:为什么正常的requests.get方法没法取到代码?
他们的反DDos攻击重定向机制的具体表现是:
打开网站后你会看到如下图所示的图片,然后过了数秒之后,网页才会正常显示出来。
而requests.get的请求速度很快,所以爬取下来的代码上只有下图的内容而没有真正的网站内容…
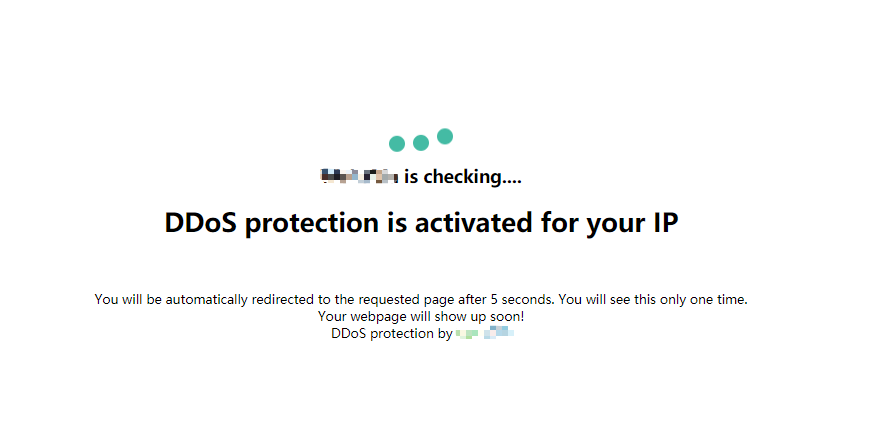
对策:对请求部分进行修改,改为使用selenium进行浏览器模拟,然后延时一段时间,等到真正的页面加载出来后再获取网页内容。
1、配置selenium的driver(驱动),模拟浏览器访问网站
2、使用time.sleep进行一段时间的延时
3、获取网页源码
-
详细的操作说明
------------------------------------------------------
关于selenium:
selenium是一个用于Web应用程序测试的工具,其测试直接运行在浏览器中,就像真正的用户在操作一样。
支持的浏览器包括IE(7, 8, 9, 10, 11),Mozilla Firefox,Safari,Google Chrome,Opera,Edge等
本文在使用selenium库时,需要另外下载对应的浏览器驱动进行使用。
这个是Chrome的驱动地址:http://npm.taobao.org/mirrors/chromedriver/
请尽量与自己电脑浏览器的版本保持接近或一致,以确保爬出来的结果与在浏览器中所看到的结果接近或一致。
驱动的zip文件下载好后,直接解压即可,运行selenium库时需要将其中的chromedriver.exe 的绝对地址填写在函数中。
------------------------------------------------------
首先,本文用的组件为
请求库 selenium.webdriver
解析库 BeautifulSoup
时间控制库 time
所以请在py文件的最开头输入
from selenium import webdriver from bs4 import BeautifulSoup import time
如果没有这三个库的话,请提前下载好。
---------------------------------------------------------------------------------------------------------
1、配置selenium的driver(驱动),模拟浏览器访问网站(本文使用的是Chrome作为浏览器对象,如想选择其他浏览器对象,请自行百度具体方法)
首先,最基础的代码是这三句。
browser = webdriver.Chrome("E:\\scrapy_result\\chromedriver.exe") #声明浏览器对象,注意括号内要填入chromedriver.exe的绝对地址(上方红字有提到过) browser.get(url) #访问网页
2、使用time.sleep进行一段时间的延时
保守情况下,延时一般设置为60s比较好。具体情况根据 网页的真正内容完全加载出来所需的用时 来判断
time.sleep(60) #延时60秒
3、获取网页源码
page_content = browser.page_source #读取浏览器的网页源码
这么一来,网站源码便又输入到了参数page_content之中了。
解析部分就如之前的爬虫程序大致一样,调整所需参数即可~~
如有需要,请查看我的上一篇爬虫博客: 【代码回溯】最简单的一个python爬虫代码 https://www.cnblogs.com/pumpkinhlk/p/15161760.html
-----------------------------------------------------------------------------------------------------------
Debug报错:
[WinError 10061] "由于目标计算机积极拒绝,无法连接”
原因不明,查了很多博客,内容大致是“代理问题”。
除此之外,
下面这篇博客中使用的针对[WinError 10060]的对策,貌似对于[WinError 10061]也有一定的效果
https://www.cnblogs.com/si-dian/p/12196931.html
而本人则是在selenium访问的时候加上了try except机制,是程序在报错以后延迟数秒,然后再次访问该网页,结果也获得了不错的效果(到目前为止,WinError 10061的错误没有再次出现过了)
下方会有总的请求代码。
-----------------------------------------------------------------------------------------------------------
那么以上就是分步解析了,总的请求代码是这样的(无函数无类):
browser = webdriver.Chrome("E:\\scrapy_result\\chromedriver.exe") try: browser.get(url) time.sleep(60) print("保存源码") page_content = browser.page_source except WindowsError or OSError: print("系统调用返回源码失败,10秒后重试") time.sleep(10) #延迟10s browser.quit() browser.get(url) #重新访问网页 time.sleep(60) print("保存源码") page_content = browser.page_source browser.quit()

