SQLite 事务
事务定义了一组 SQL 命令的边界,这组命令或者作为一个整体被全部执行,或者都不执行,这被称为数据库完整性的原子性原则。这种关系的典型例子就是银行转账,假设银行程序从一个账户向另一个账户转账,转账程序通过如下方式进行:首先将第一个账户的钱转入第二个账户,然后从第一个账户删除对应的数目;或者首先从第一个账户删除要转账的数目,然后向第二个账户插入对应的数目。无论哪种方式,都是通过两步完成的:先插入,后删除;或者先删除,后插入。
但是在转账期间,如果数据库服务器突然奔溃或电力中断,第二个操作没有完成怎么办?要么这笔钱存在于两个账户(第一种方式),要么这笔钱在两个账户中都不存在(第二种方式)。无论发生哪种情况,总有人无法接受。数据库也处于不一致的状态,关键是这两步操作必须要同时被执行或者一步都不执行。这就是事务的本质。
一、事务的范围
事务由 3 个命令控制:begin、commit 和 rollback。begin 开始一个事务,begin 之后的所有操作都可以取消,如果连接中止前没有发出 commit,也会被取消。commit 提交事务开始后所执行的所有操作。类似地,rollback 还原 begin 之后的所有操作。例如:
1
|
BEGIN;
|
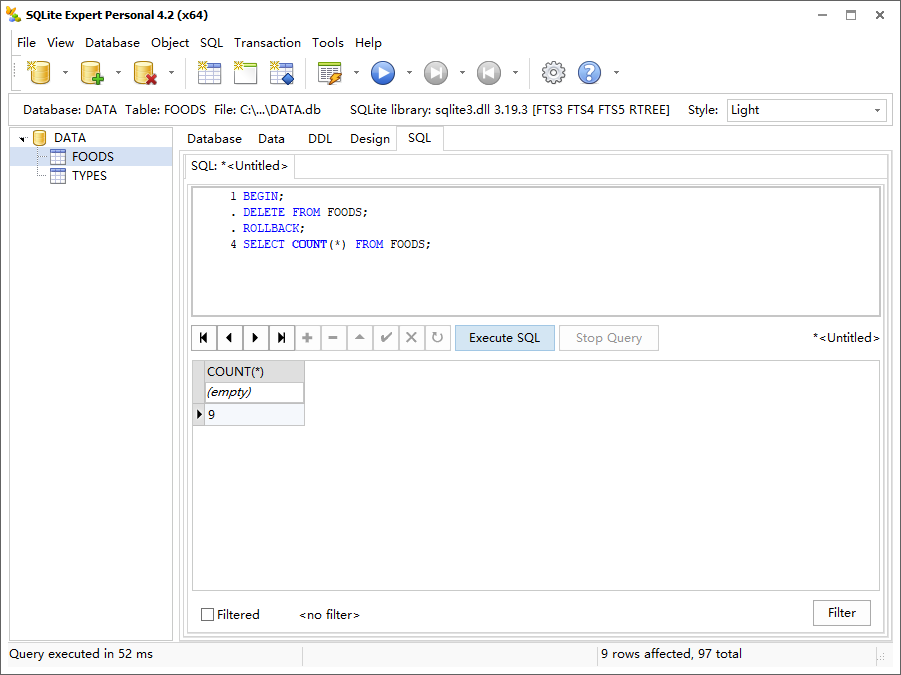
上面开始了一个事务,先删除了 FOODS 表的所有行,但是又用 rollback 进行了回滚。在执行 SELECT 时发现表中没有发生任何改变。
默认情况下,SQLite 中每条 SQL 语句自成事务(自动给提交模式)。也就是说,如果你没有使用 begin...commit/rollback 定义事务的范围,SQLite 默认每条单独的 SQL 命令就是有 begin...commit/rollback 的事务。这种情况下,所有成功完成的命令都自动提交。同样,所有遇见错误的命令都回滚。这种操作模式(隐式事务)也称为自动提交模式:SQLite 以自动提交模式运行单个命令,如果命令没有失败,那它将自动提交。
SQLite 也支持 savepoint 和 release 命令,这些命令扩展了事务的灵活性,包含多个语句的工作体可以设置 savepoint,回滚可以返回到某个 savepoint。创建 savepoint 和启动 savepoint 命令一样简单,如下所示:
1
|
savepoint justincase;
|
如果意识到需要返回到某个地方,不用回滚整个事务,可以使用如下命名回滚:
1
|
rollback [transaction] to justincase;
|
本例使用 justincase 作为 savepoint 名称,你也可以使用其他名称。
二、冲突解决
如前所述,违反约束会导致事务的中止。在对数据进行很多修改的过程中,命令中止会造成什么后果?大多数数据库(管理系统)都是简单地将前面所做的修改全部取消。这也是数据库处理违反约束的方式。
SQLite 有其独特的方法允许你指定不同的方式来处理约束违反(或者说从约束违反中恢复),这种功能被称为冲突解决,如下例所示:
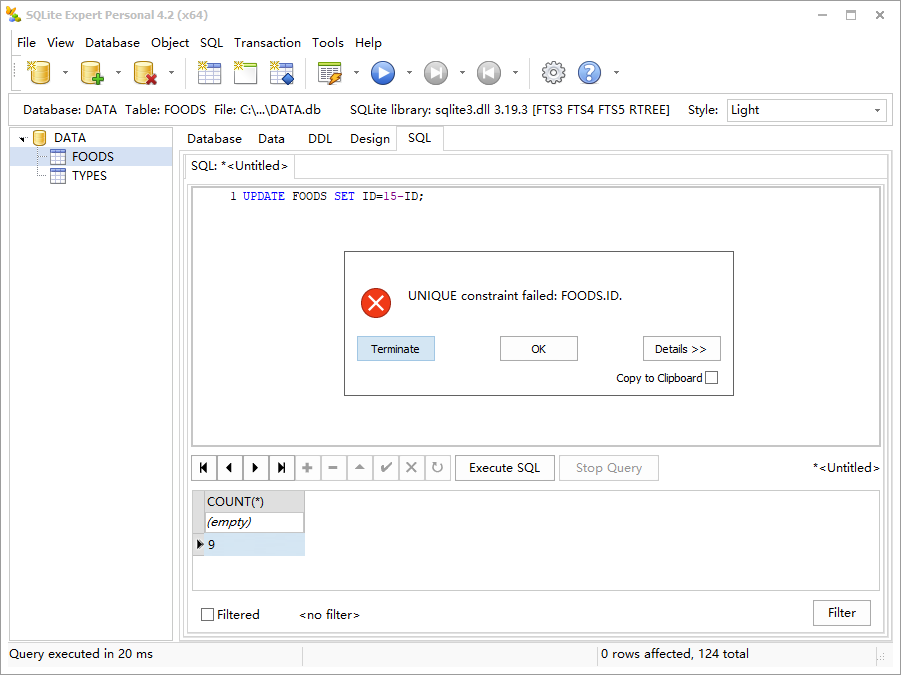
当 UPDATE 语句执行到第 6 个记录时,它视图将 ID 更新为 15-6=9,但是 ID 为 9 的记录已经存在,违反了唯一性约束。因此,该命令终止。但是在违反约束前,SQLite 已经更新了 5 个记录。应该如何处理?默认行为是终止命令并回滚所有的修改,保存事务的完整性。
如果你想让已经修改的 5 个记录继续保留,该怎么办?其实只需要使用恰当的冲突解决方案就行。SQLite 提供 5 种可能的冲突解决方案或策略,它们可以用来解决冲突(约束违反):replace、ignore、fail、abort 和 rollback。这 5 种方法定义了错误容忍范围或敏感度:从最宽松的 replace,到最严格的 rollback。这些解决方法的定义如下(按严重度排序):
-
replace:当违反了唯一性约束时,SQLite 将造成这种违反的记录删除,以插入或修改的新记录替代,SQL 继续执行,且不报错。如果违反了 NOT NULL 约束,使用该字段的默认值替代 NULL。如果该字段没有默认值,SQLite 应用 abort 策略。有一点要特别注意,当冲突解决策略为了满足约束而删除记录时,该行的删除触发器不会被触发。这种行为可能在将来的版本中改变。
-
ignore:当约束违反发生时,SQLite 允许命令继续执行,违反约束的行保持不变。而它之前和之后的记录都继续修改。也就是说,所有会触发约束违反的行都不动,保持原貌,命令继续处理其他的,且不报错。
-
fail:当约束违反发生时,SQLite 终止命令,但是不恢复约束违反之前已经修改的记录。也就是说,在约束违反发生前的改变都保留。例如,如果 UPDATE 命令在第 100 行违反约束,那么前 99 行已经修改的记录不会回滚。但是对第 100 行和之外的改变不会发生,因为命令已经终止了。
-
abort:当约束违反发生时,SQLite 恢复命令所做的所有改变并终止命令。abort 是 SQLite 中所有操作的默认解决方法,也是 SQL 标准定义的行为。注意:abort 也是最昂贵的冲突解决策略——要求额外的工作,设置要求没有冲突发生。
-
rollback:当约束违反发生时,SQLite 执行回滚——终止当前命令和整个事务。最终结果就是当前命令所做的改变和事务中之前命令的改变都被回滚。这也是最严格的冲突解决方法,单个约束违反导致事务中执行的所有操作都回滚。
冲突解决方法既可以在 SQL 命令中指定,也可以在表和索引的定义中执行。具体地讲,冲突解决方法可以在 insert、update、create table 和 create index 中指定。此外,它在触发器中也有具体含义。冲突解决方法在 insert 和 update 中的语法形式如下:
1
|
insert or resolution into table (column_list) values (value_list);
|
冲突解决策略紧跟在 insert 或 update 命令后面,并加上前缀 or。insert 或 replae 表达式可以缩写成 replace。这与其他数据库中的 “merge” 或 “upsert” 行为类似。
前面的 UPDATE 例子中,已经更新的 5 行要回滚,因为使用了默认的 abort 冲突解决方法。如果要继续保留已更新的行,可以使用 fail 冲突解决方法。下面的例子说明了如何使用。为了不影响原始表 FOODS,我们可以将 FOODS 表的数据复制到新表 TEST 中,并用表 TEST 做实验。FOODS 表建表语句和复制语句如下:
1
|
-- 创建 FOODS 表,插入数据
|
1
|
-- 复制 FOODS 表数据到 TEST 表中
|

数据复制到新表 TEST 后,可以在 TEST 表中添加一个名为 MODIFIED 的字段,默认值是 N。在 UPDATE 语句中,将其更新为 Y 以追踪哪些记录在约束违反发生前更新了。使用 fail 冲突解决方法时,这些更新将保留,可以追踪之后有多少记录被更新了。
1
|
CREATE UNIQUE INDEX TEST_IDX ON TEST(ID);
|
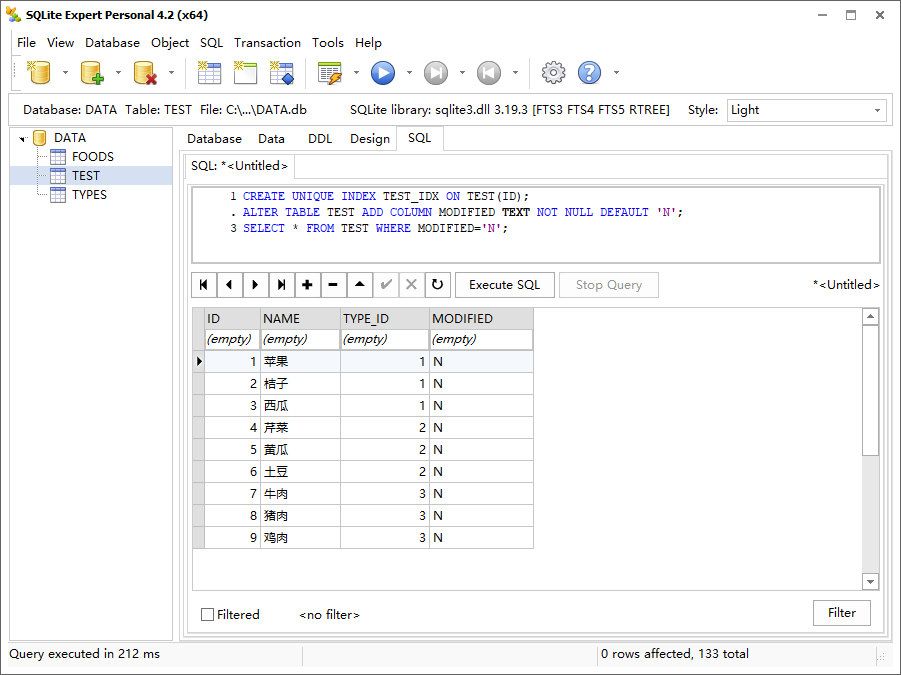
好了,现在可以使用 fail 冲突解决方法来追踪被更新的记录了。更新报错,然后查询修改状态为 N 的数据,和预期一致。
1
|
UPDATE OR FAIL TEST SET ID=15-ID, MODIFIED='Y';
|
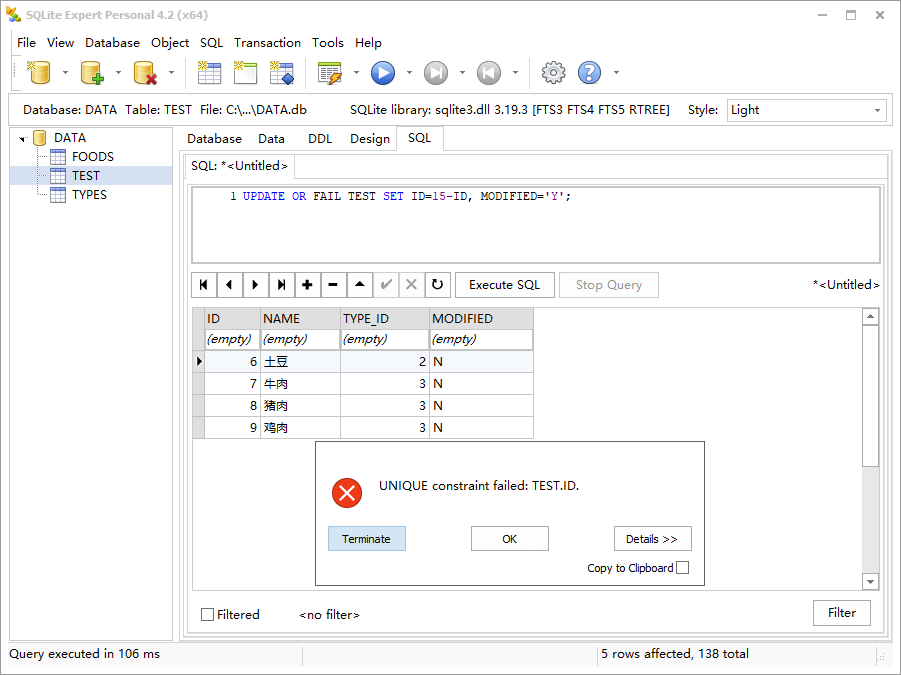
1
|
SELECT * FROM TEST WHERE MODIFIED='Y';
|
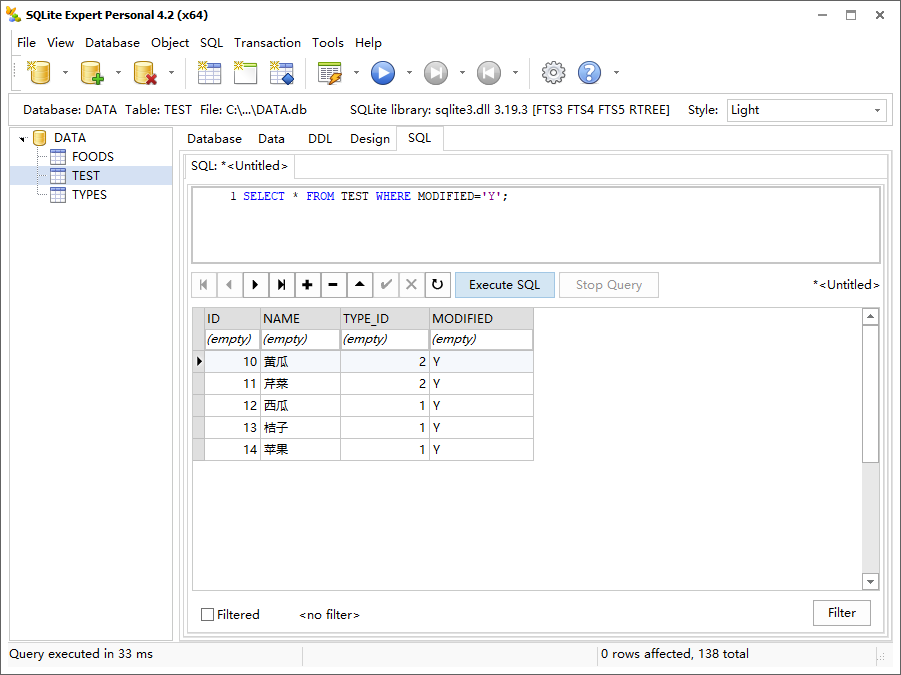
注意:fail 需要额外考虑。记录更新的顺序是不确定的,也就是说,你无法确定记录在表中的顺序或者 SQLite 以何种顺序处理它们。你可能假设它遵从 rowid 字段顺序,但是事实并不总是这样,文档中从未这样说过。再次重申,与任何数据库工作时,不要假设有某种隐式的顺序。如果你正在使用 fail,很多情况下,使用 ignore 会更好。ignore 会完成工作,修改所有可以修改的记录,而不是从第一个约束违反处跳出。
在表内定义时,可以为单个字段指定冲突解决方法,例如:
1
|
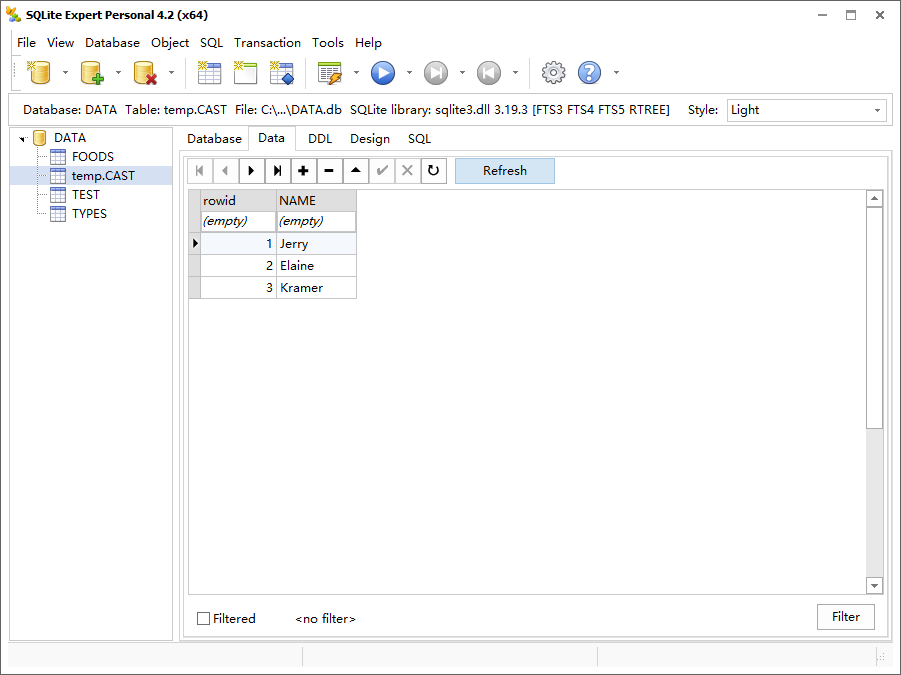
CREATE TEMP TABLE CAST(NAME TEXT UNIQUE ON CONFLICT ROLLBACK);
|
CAST 表只有一个字段 NAME,该字段具有唯一约束性,冲突解决方法设置为 ROLLBACK。
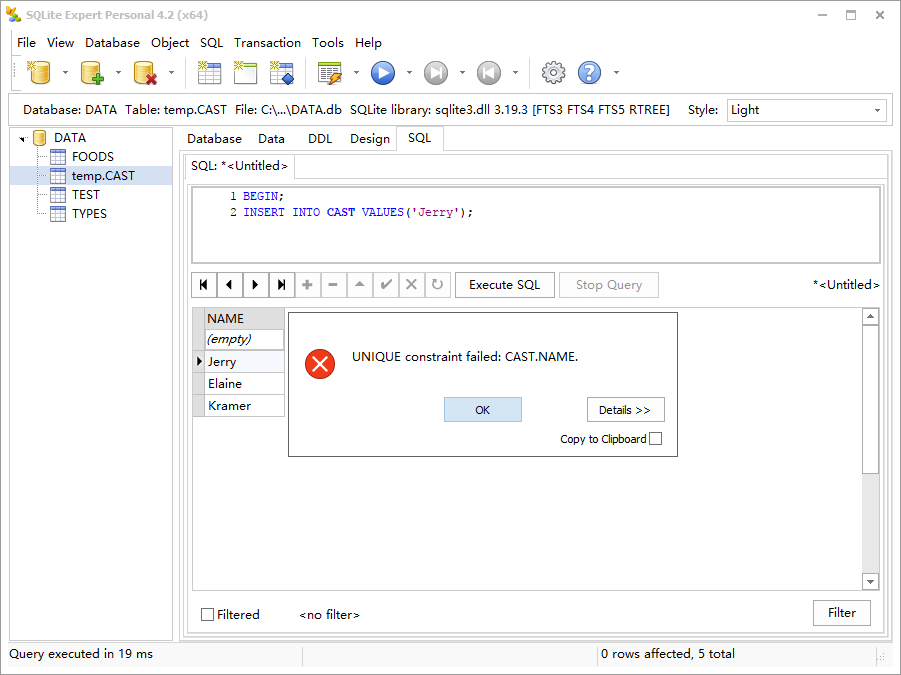
任何触发该字段约束的 insert 或 update 语句都由 rollback 冲突解决来裁决,而不是默认的 abort。结果不仅是该语句被回滚,而且该语句所在的整个事务都将回滚。
1
|
BEGIN;
|
1
|
COMMIT;
|
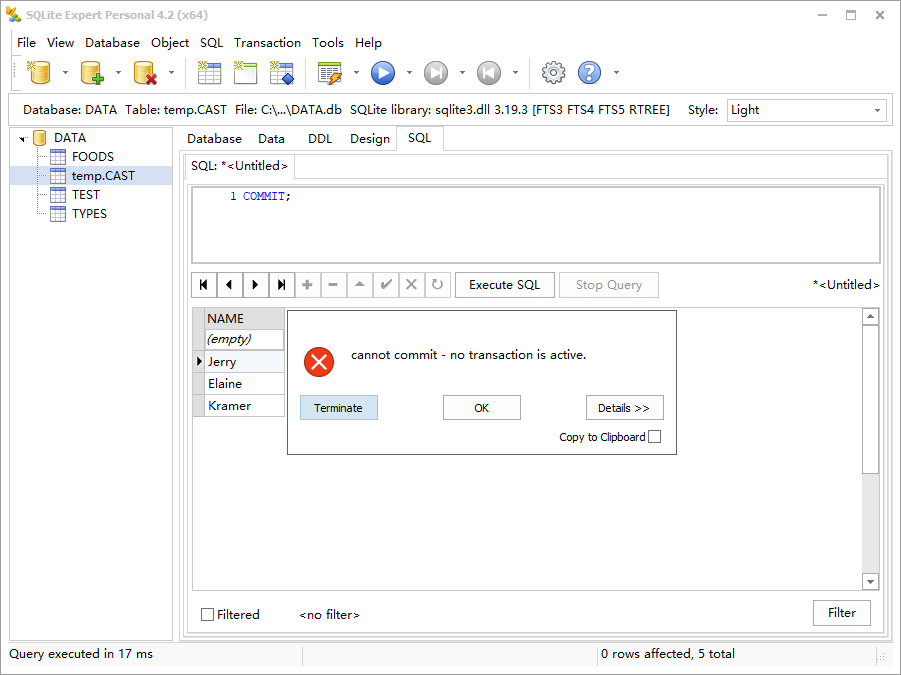
本例中的 commit 失败是因为 NAME 字段的冲突解决方法已经终止了事务。create index 的工作方式类似。当某些字段是约束违反的源头时,表或索引内的冲突解决方法将默认的 abort 改变为这些字段上定义的冲突解决方法。
需要注意的是:冲突解决方法是语句级的(DML),可以覆盖对象级(DDL)定义的。以前面为例:
1
|
BEGIN;
|
replace 冲突解决方法可以覆盖 CAST.NAME 中定义的 rollback 冲突解决方法。
三、数据库锁
在 SQLite 中,锁和事务是紧密联系的。要有效地使用事务,需要了解一些关于如何加锁的知识。SQLiite 采用粗粒度的锁。当一个连接要写数据库时,所有其他的连接被锁住,直到写连接结束它的事务。SQLite 有一个加锁表,用来帮助不同的写数据库都能在最后一刻再加锁,以保证最大的并发性。
SQLite 使用锁逐步提升机制,为了写数据库,连接需要逐级获得排它锁。SQLiite 有 5 种不同的锁状态:未加锁(unlocked)、共享(shared)、预留(reserved)、未决(pending)和排它(exclusive)。每个数据库连接在同一时刻只能处于其中一个状态,每个状态(未加锁状态除外)都有一种锁与之对应。
最初的状态是未加锁状态,在此状态下,连接还没有访问数据库。当连接一个数据库,甚至已经用 BEGIN 开始了一个事务时,连接都还处于未加锁状态。
未加锁的下一个状态是共享状态。为了能够从数据库种读(不是写)数据,连接必须首先进入共享状态,也就是说,首先要获得一个共享锁。多个连接可以同时获得并保持共享锁,也就是说,多个连接可以同时从同一个数据库中读数据。但哪怕只有一个共享锁还没有释放,也不允许任何连接写数据库。
如果一个连接想要写数据库,它必须首先获得一个预留锁。一个数据库同时只能有一个预留锁,该预留锁可以与共享锁共存,它是写数据库的第一阶段。预留锁既不阻止其他拥有共享锁的连接继续读取数据库,也不阻止其他连接获得新的共享锁。
一旦一个连接获得了预留锁,它就可以开始处理数据库修改操作了,尽管这些修改只能在缓冲区中进行,而不是实际写到磁盘,对读出内容所做的修改保存在内存缓冲区中。
当连接想要提交修改(事务)时,需要将预留锁提升为排它锁。为了得到排它锁,还必须首先将预留锁提升为未决锁。获得未决锁之后,其他连接就不能再获得新的共享锁了,但已经拥有共享锁的连接仍然可以继续正常读数据库。此时,拥有未决锁的连接等待其他拥有共享锁的连接完成工作并释放其共享锁。
一旦所有的其他共享锁都被释放,拥有未决锁的连接就可以将其锁提升至排它锁,此时就可以自由地对数据库进行修改。所有以前缓存的修改都会被写到数据库文件中。
四、死锁
虽然你可能觉得前面关于锁的讨论很有趣,但是你可以能也在考虑为什么锁如此重要?为什么需要了解锁的机制呢?如果不了解你正在做什么,你可能会陷入死锁。
考虑下表的情况,两个连接 A 和 B 完全不知道对方在同一时刻对同一数据库进行操作。连接 A 启动第一个命令,B 启动第二、第三个命令,A 启动第四个,如此等等。
| 假设的死锁情况 | ||
| 执行顺序 | 连接A | 连接B |
| 1 | sqlite> begin; | |
| 2 | sqlite> begin; | |
| 3 | sqlite> insert into foo values('x') | |
| 4 | sqlite> select * from foo; | |
| 5 | sqlite> commit; | |
| 6 | SQL error:database is locked | |
| 7 | sqlite> insert into foo values('x') | |
| 8 | SQL error:database is locked | |
两个连接都在死锁中结束。B 首先尝试写数据库,也就拥有了一个未决锁。A 再视图写,但当其 insert 语句视图将共享锁提升为预留锁时失败。
为了方便讨论,在此假设连接 A 和 B 都一直在等待数据库可写。那么此时,其他的连接都被锁在外面。如果试图打开第三个连接,它甚至不能读数据库。因为 B 拥有未决锁(它能阻止其他连接获得共享锁)。那么此时,不仅 A 和 B 死锁了,而且它们也将其他人锁在数据库外。基本上,有共享锁和未决锁的那些连接如果不想放弃控制,其他所有的进程都不能再操作此数据库了。
如何避免死锁?当然不能让 A 和 B 坐在会议室通过彼此的律师谈判解决,因为它们甚至不知道彼此的存在。答案时采用正确的事务类型来完成工作。
五、事务的类型
SQLite 有三种不同的事务类型,它们以不同的锁状态启动事务。事务可以开始于:deferred、immediate 或 exclusive。事务类型在 begin 命令中指定:
1
|
begin [ deferred | immediate | exclusive ] transaction;
|
一个 deferred 直到必须使用时才获取锁。因此,对于延迟事务,begin 语句本身不会做什么事情——它从未锁定状态开始。这是默认的情况。如果仅仅用 begin 开始一个事务,那么事务就是延迟的,停留在未锁定状态。多个连接可以在同一时刻未创建任何锁的情况下开始延迟事务。这种情况下,第一个对数据库的读操作获取共享锁,类似地,第一个对数据库的写操作试图获取预留锁。
由 begin 开始的 immediate 事务在 begin 执行时试图获取预留锁。如果成功,begin immediate 保证没有其他的连接可以写数据库。正如你知道的,其他的连接可以继续对数据库进行读操作,但是,预留锁会阻止其他新的读取数据库。预留锁的另一个结果是没有其他连接能成功启动 begin immediate 或者 begin exclusive 命令,当其他连接执行上述命令时,SQLite 会返回 SQLITE_BUSY 错误。这时你可以对数据库进行修改操作,但是你还不能提交,当调用 commit 时,会返回 SQLITE_BUSY 错误。这意味着还有其他的读事务没有完成,需要等它们执行完后才能提交事务。
exclusive 事务会试着获取对数据库的排它锁。这与 immediate 的工作方式类似,但是一旦成功,exclusive 事务保证数据库中没有其他的活动连接,所以就可对数据库进行任意的读写操所。
前面例子的问题在于两个连接最终都想写数据库,但是它们都没有放弃各自原来的锁,最终,共享锁导致了问题。如果两个连接都以 begin immediate 开始事务,那么死锁就不会发生。在这种情况下,在同一时刻只能有一个连接进入 begin immediate,其他的连接就得等待。必须等待的连接将会不断尝试以确保它最终能开始 immediate 事务。如果所有想对数据库进行写操作的连接使用 begin immediate 和 begin exclusive,那它就提供了一种同步机制,通过这种机制防止了死锁的产生。要使这种方式可以工作,所有的人都必须遵守规则。
基本的准则是:如果使用的数据库没有其他连接,用 begin 就足够了。但是,如果使用的数据库有其他也会对数据库进行写操作的连接,就得使用 begin immediate 或 begin exclusive 开启事务。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号