Linux资源分析工具杂谈(长文慎入)
Linux资源分析工具杂谈
开篇之前请大家先思考一个问题:
磁盘的平均I/O响应时间是1 ms,这个指标是好,还是差?
众所周知,计算机科学是客观的,也就是说对于一个给定的问题,我们总是能给出明确的答案,比如我们网上购物买了两件100元的衣服,我们应该付款200元,但是系统给我们计算出的金额确是300元,我们可以明确的告诉商家,结果算错了。与此不同,性能却常常是主观的,甚至对性能问题的判断都可能是不准确的,比如我们刚刚提到的1ms,一定有人认为是好的,也有人认为是差的,要客观的回答这个问题,可能是一项系统性的工作,必须需要首先定义基准(基准定义本身相对复杂,内容可以写一本书,在此不做深入讨论),有了基准指标,通过比较才能得出合理的结论。表1列出了一些数值,期望可以使大家对计算机科学的一些延时有一个粗略的概念,表中以一个3.3GHZ主频的CPU一次访问寄存器为基准进行说明,比如如果我们认为计算机世界中一次寄存器访问的时间0.3纳秒是现实生活中的1秒,那么访问一次内存的相对时间就是6分钟,表1中参考数据源自互联网。
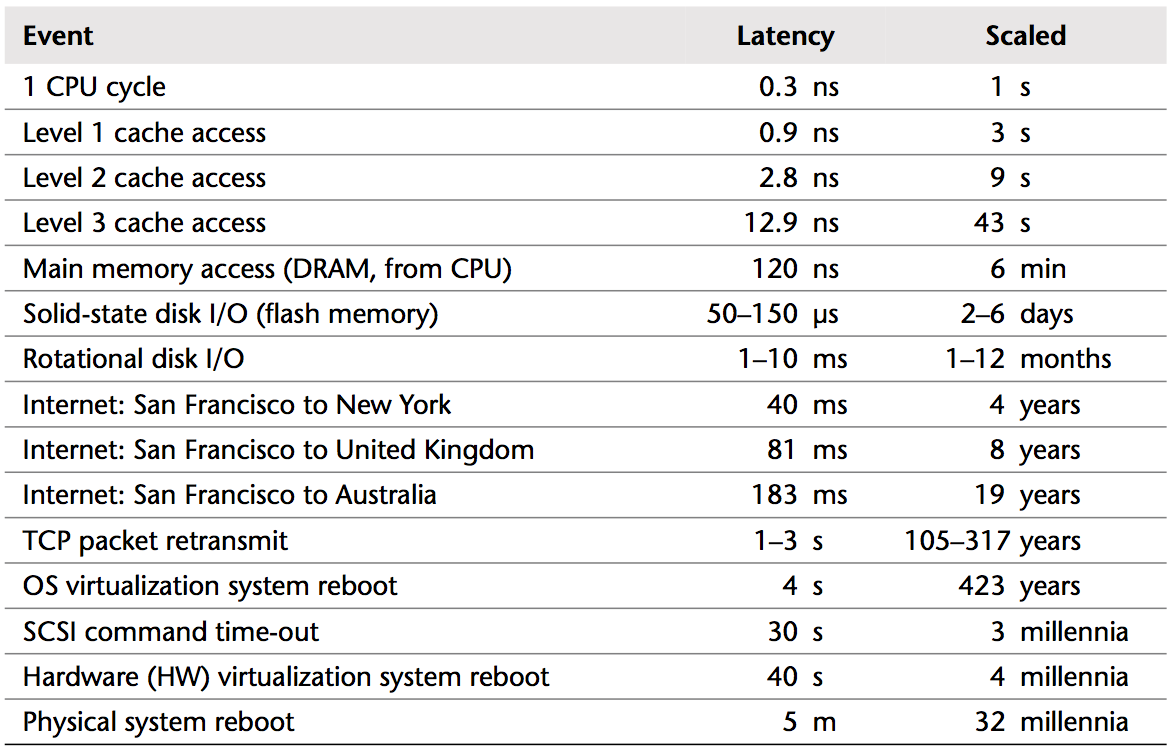
表1. 计算机科学中的延时
软件发展到今天可谓日新月异,短短的几十年中极大的提高了人类的生产力。伴随着软件功能的发展,软件的复杂度也在几何级的增长,从经济性的角度来讲,人们总是希望投入更少的硬件资源,更少的电力,更少的时间来完成更多的生产任务,人们期望自己的每一度电,每一分钟时间都在用在有意义的生产活动中。面对复杂的软件,我们如何知道软件在做有意义的事情而不是在无意义的阻塞,或者系统的哪一部分确实存在性能瓶颈,比如内存太小,硬盘太慢,CPU太慢等等。系统性能分析可以在不同的维度进行审视,常用的维度有负载分析和资源分析,本文希望从资源分析的角度对相关的工具进行讨论。
中国有句古话,工欲善其事,必先利其器,人类文明进步的最重要的标志就是可以在对的时候使用对的工具。但是问题来了,什么是对的时候使用对的工具?前人对问题总结后分成了三类,第一种是理解问题,也知道如何解决问题,第二种是理解问题,但是以个人的能力无法解决问题,第三类问题是不知道问题的存在,更不知道如何解决问题。第一种问题和第二种问题我们称之为基础问题,因为我们可以通过个人能力或者团队合作解决这类问题,第三种问题未知的未知才是我们需要重点关注的问题,理论上来说,在一个成熟的软件开发周期中,不允许存在未知的未知,我们需要对系统的各个层次都有透彻的理解和深入的把握。
当今世界的三大主流操作系统Linux, Windows NT, Mac OS都提供了系统的工具集来监控,排查各类性能问题,比如Windows平台上Mark Russinovich的Sysinternals工具集,Windbg工具集,Linux 平台上的Sysstat工具集, Brendan Gregg力推的DTrace工具集。为了解决已知和未知的问题,我们首先需要对操作系统和硬件的相关指标有一个基础的认识,否则即使有了适合的工具,统计出了详尽的结果,我们仍然无法透彻的理解软件和系统发生了什么。如图1所示是性能分析大神Brendan Gregg对常用的性能分析工具进行的详尽总结。

图1. Linux Performance Tools
基础篇
下面我们对图1中的一些常用基础分析工具以及应用场景进行简单的分析。常用的性能分析工具包括:uptime, vmstat, mpstat, sar, ps, top, pidstat等等,这些命令的简单描述请见表2。
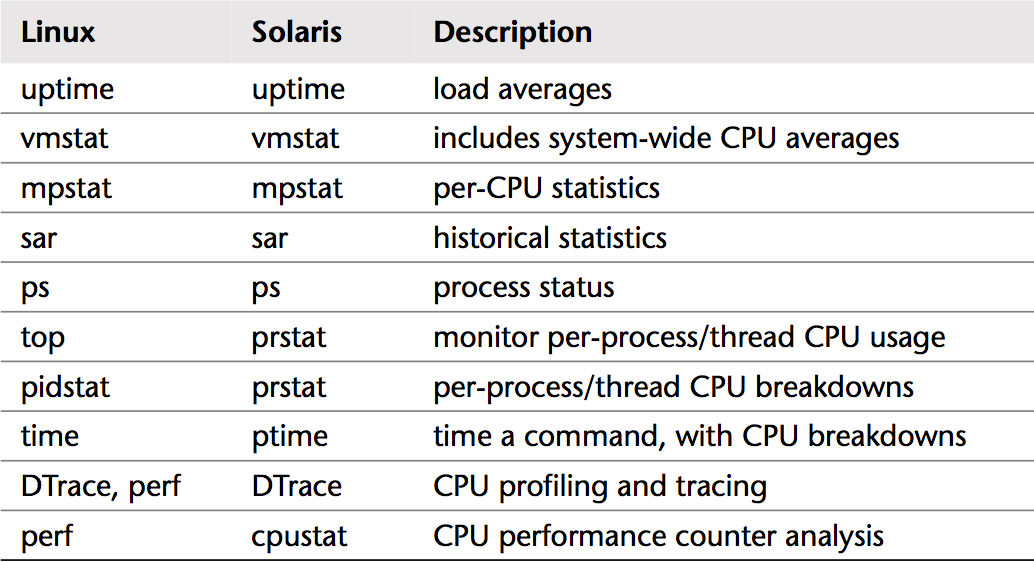
表2. 常用性能分析工具简单描述
系统发生CPU性能问题时通常第一个使用的命令是uptime和top,uptime命令输出系统过去1分钟,5分钟和15分钟的平均负载,通过这三个数值可以粗略的分析出系统过去15分钟内负载是降低了,升高了,或者是持平,uptime运行结果如图2所示。

图2. uptime运行结果
多核系统分析中接下来要使用的命令通常是mpstat,我们可以通过mpstat对CPU的每个核的使用情况都进行监控,mpstat不仅可以对每个核心的数据进行分别统计,还可以对所有核心的平均使用情况进行统计,mpstat运行结果如图3所示。

图3. mpstat运行结果
当我们使用top发现某一个进程的CPU或者其他资源使用异常的时候,我们可能需要引入第三个命令pidstat,我们甚至可以将这一统计数据精确到具体的线程。Top和pidstat运行结果见图4和图5。
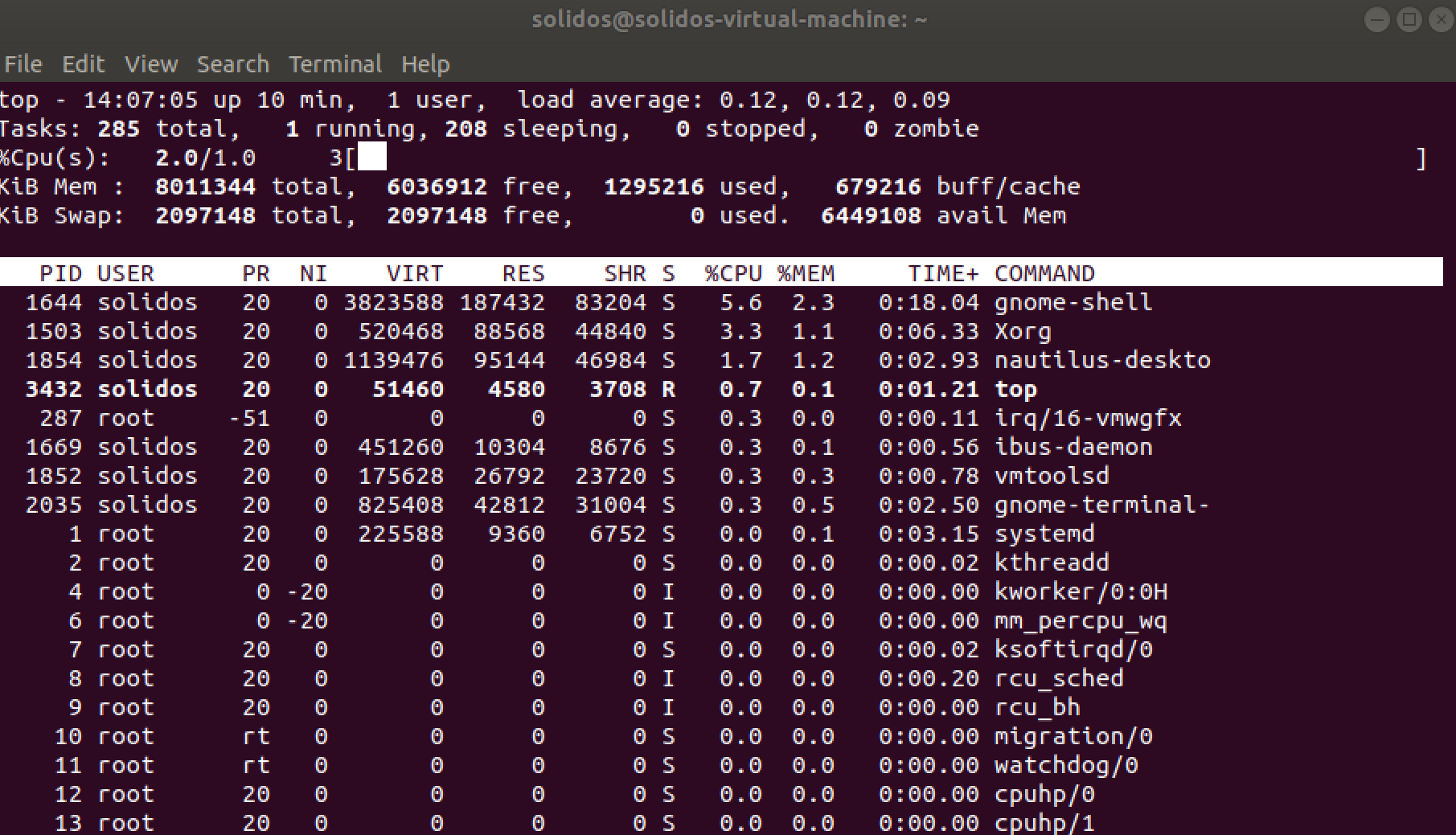
图4. Top运行结果

图5. Pidstat分线程运行结果
当我们需要对tcp流量进行简单统计,又不愿意要引入更复杂的tcpdump网络监控的时候,sar命令是个不错的选择,当然,统计网络流量只是sar的一个功能而已,更多功能可以参考sar man page, 使用sar命令统计tcp流量运行结果如图6所示。
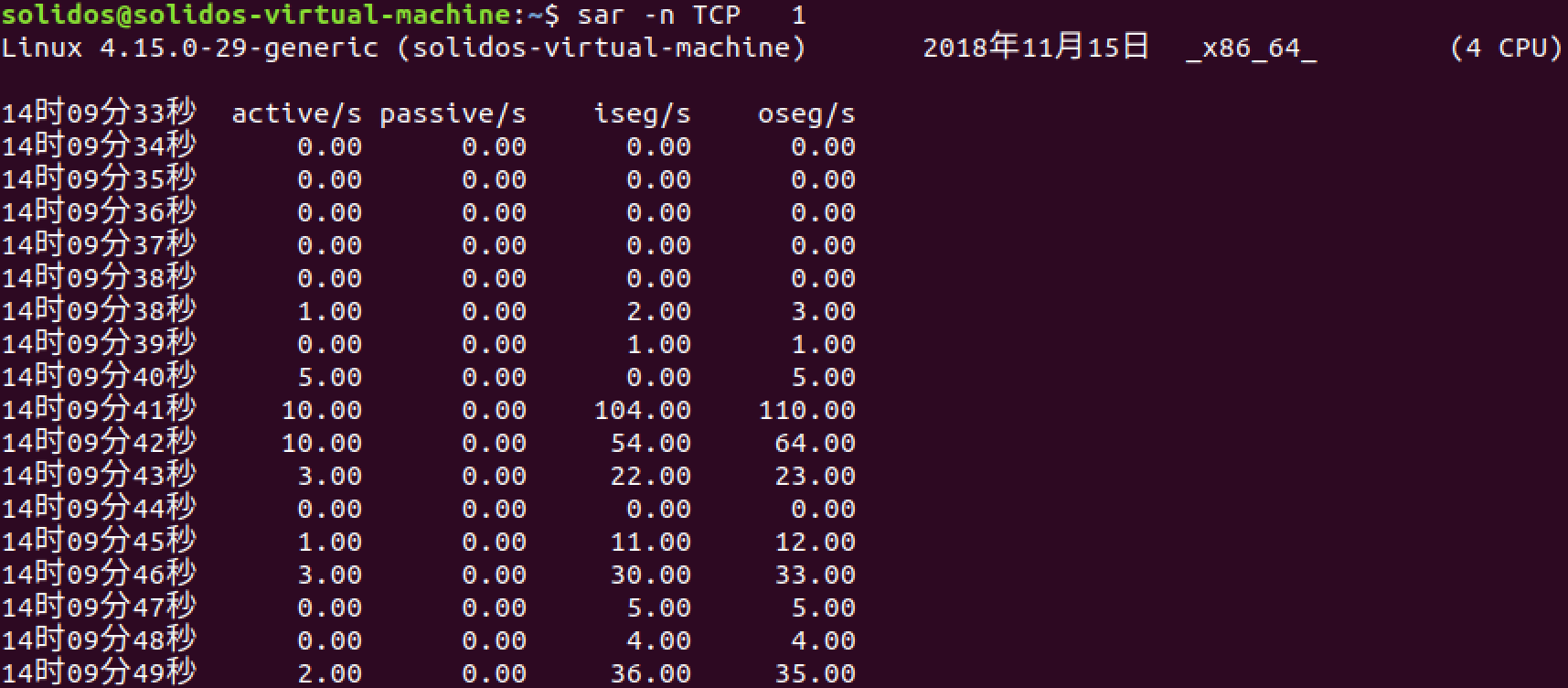
图6. sar命令统计tcp流量运行结果
限于篇幅的原因,此处不再一一讨论图1中的每一个命令。
进阶篇
动态追踪是一种高级调试技术可以帮助开发人员以非常低的成本快速排查和解决软件性能问题。当今世界软件面临的问题一是规模,二是复杂度。随着 BPF 追踪系统(基于时间采样)最后一个主要功能被合并至 Linux 4.9-rc1 版本的内核中,Linux内核拥有了类似DTrace的原生追踪功能。DTrace是Solaris系统中的高级追踪器,功能强大,对于长期使用 DTrace 的用户,这是一个振奋人心的消息,现在Linux系统上可以在生产环境中使用安全的、低负载的定制追踪系统,通过执行时间的柱状图和频率统计等信息,分析应用的性能以及内核。最初用于Linux的追踪项目有很多,但是这个最终被合并进Linux内核的技术从一开始就根本不是一个追踪项目:它最开始是用于伯克利包过滤器 Berkeley Packet Filter(BPF)的一个增强功能。这些补丁允许BPF重定向数据包,从而创建软件定义网络。久而久之,对事件追踪的支持就被添加进来了,使得程序追踪可用于Linux系统。BPF Compiler Collection (BCC), PLY 和 BPFTRACE都是正在开发的BPF前端,BCC架构如图7所示,下面以BCC为例对Linux动态追踪技术进行简单说明,

图7. Linux BCC/BPF Tracing Tools
假设我们有这样一个场景,系统中偶尔会运行新的进程,这些新的进程可能会消耗大量系统资源,从而对我们生产上运行的环境产生干扰,但是这种进程可能运行时间极为短暂,我们怎样才能知道发生了这种情况呢?top?可能不行,时间太短了,可能top还没来得及统计,进程已经退出了。这种情况下最适合使用的工具之一就是BCC工具集中的execsnoop,图8中可以看出,每一个新启动的进程都会被记录在案。
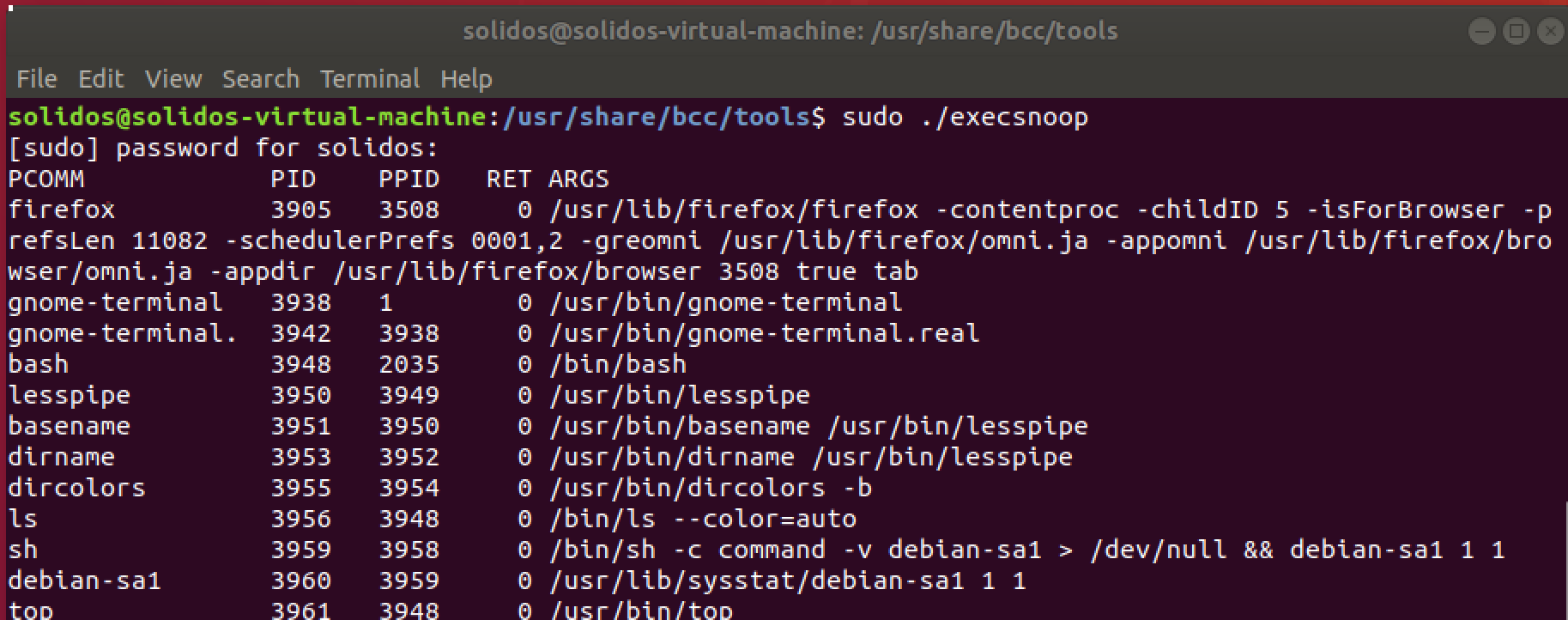
图8. Execsnoop命令运行结果
网络程序开发中我们可能想要按照TCP连接来统计一下通信两端的吞吐量和生命周期,这个时候tcplife就派上用场了,tcplife对TCP会话的生命周期和吞吐量统计如图9所示。
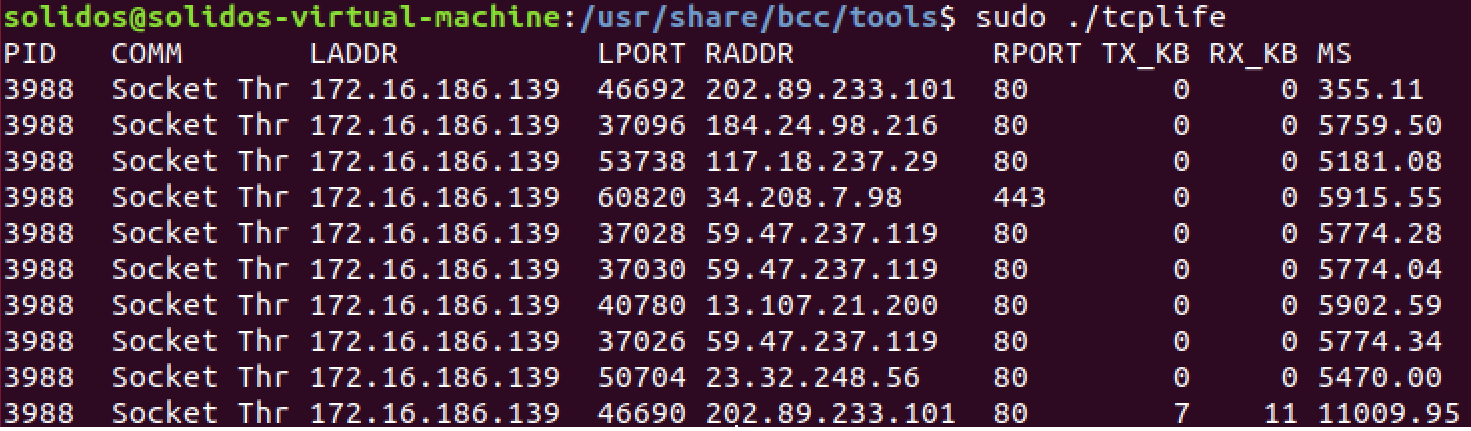
图9. Tcplife命令运行结果
对于一个给定的进程,我们甚至可以要求内核通过BPF统计CPU处理之外时间的内核和用户堆栈,具体使用方法和示例请见图10。
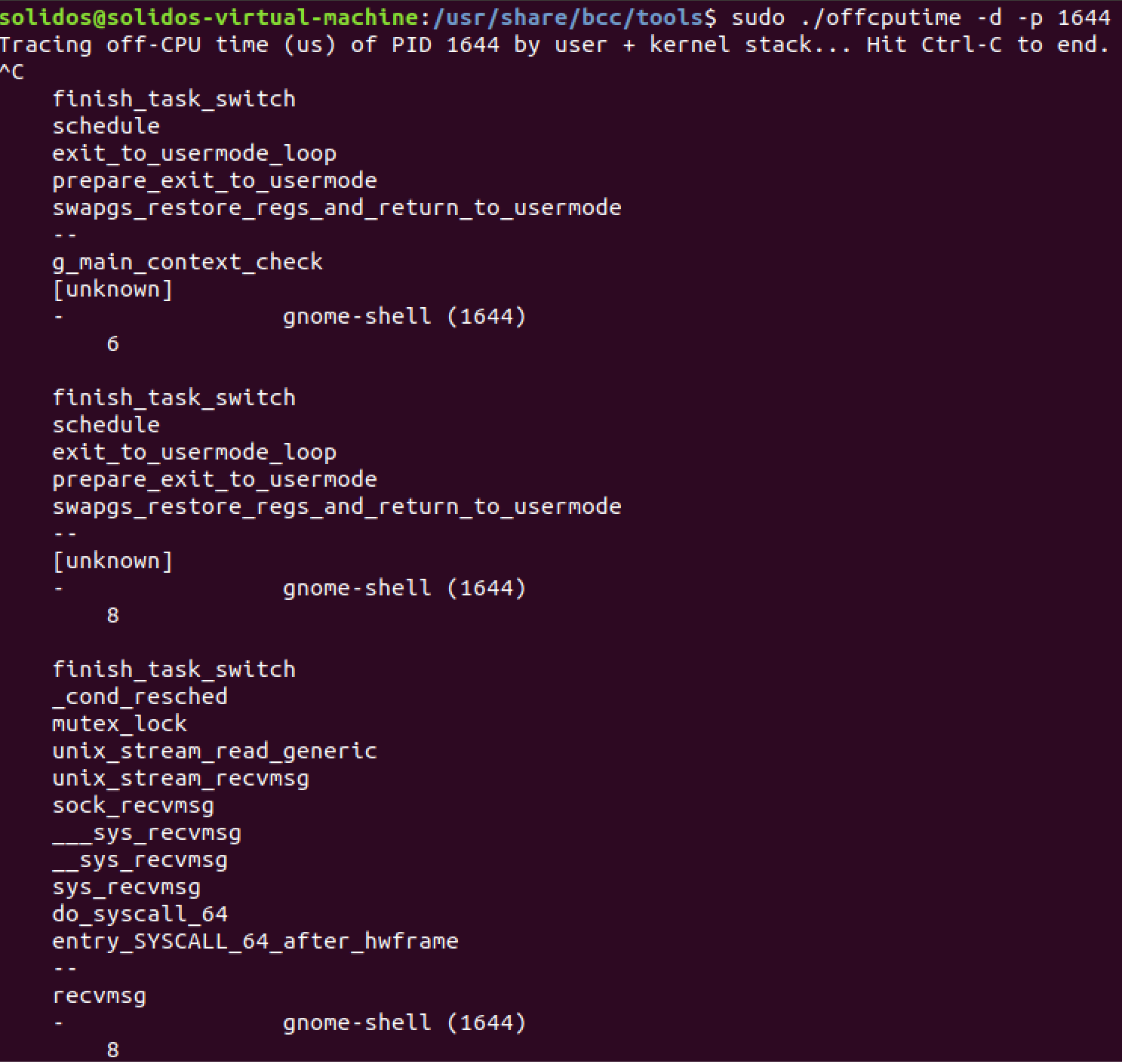
图10 offcputime命令运行结果
总结
本文对Linux资源分析相关的基础工具、高级工具以及典型应用场景进行了简单的总结,算是抛砖引玉,希望对大家有所帮助。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号