MySQL 分页查询优化——延迟关联优化
目录
1. InnoDB表的索引的几个概念
2. 覆盖索引和回表
3. 分页查询
4. 延迟关联优化
写在前面
下面的介绍均是在选用MySQL数据库和Innodb引擎的基础开展。我们先来学习索引的几个概念,帮助我们理解延迟关联优化的加快分页查询速度的原因。
一、Innodb表的索引的几个概念
InnoDB表是基于聚簇索引建立的。
索引一般分为主键索引和普通索引(辅助索引),聚簇索引并不是主键索引这样的单独的索引类型,而是一种数据存储方式。通俗的来说,单独的索引是存储了索引信息的B+Tree,而聚簇索引是在同一个结构中保存了B+Tree和数据行,即通过主键索引B+Tree的结构建立数据文件(网上的说法是索引和数据存储在同一个文件中),因此聚簇索引是一种数据存储方式。
如果对于索引的概念不是很熟悉,建议去查阅相关资料学习,索引是一个很庞大的知识结构。
Innodb表以主键索引建立后缀名为.MYD表存储文件,普通索引亦以B+Tree实现,并保存在后缀名为.MYI的文件中,具体结构图如下所示:

在查询时选用主键索引和普通索引有什么不一样呢?
以下面语句为例:
· select * from table where id = 5;(id为主键索引) 检索过程如上图绿色箭头所示,直接在主索引树上根据主键检索
· select * from table where name = "Gates"; (name为普通索引)检索过程如上图红色箭头所示,先根据普通索引检索普通索引树得到id为5,然后再拿得到的id到主索引树检索得到结果。在这个过程中,回到主键索引树搜索的过程,我们称为回表。
从这里可以看出,基于非主键索引的查询需要多扫描一棵索引树。因此,我们在应用中应该尽量使用主键查询。
解释完普通索引和主键索引的检索过程,让我们来看看什么是覆盖索引。
二、覆盖索引和回表。
什么是“覆盖索引”?
查询的列被所建的辅助索引所覆盖,无需回表。用大白话解释就是,要查的数据直接可以从索引树上就能取得,无需回表查找。
注意:不是所有类型的索引都可以成为覆盖索引。覆盖索引必须要存储索引的列,而哈希索引、空间索引和全文索引等都不存储索引列的值,所以MySQL只能使用B-Tree索引做覆盖索引
结合上图的例子:
· select id from table where name = "Gates"; 即为一个覆盖索引。
三、分页查询使用场景
需求:查询最近 7 天的订单,并做分页。订单表数据量:3000W。
未经优化的SQL:
select * from t_trade_order
where create_time between '2019-10-17' and '2019-10-25'
limit 1000000, 10;
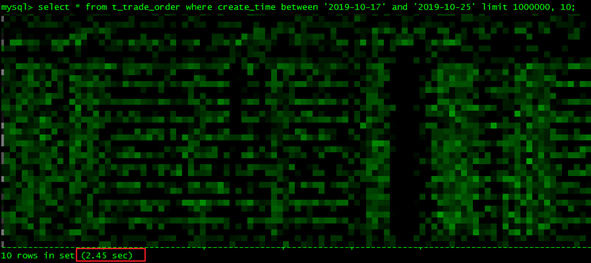

根据explain输出的结果可知,这是一条慢查询,在业务环境中不允许出现这样的慢查询。
我们都知道在做分页时会用到Limit关键字去筛选所需数据,limit接受1个或者2个参数,接受两个参数时第一个参数表示偏移量,即从哪一行开始取数据,第二个参数表示要取的行数。 如果只有一个参数,相当于偏移量为0。当偏移量很大时,如limit 100000,10 取第100001-100010条记录,mysql会取出100010条记录然后将前100000条记录丢弃,这无疑是一种巨大的性能浪费。
终于转入正题了,那我们应该怎样优化呢?
四、延迟关联优化
《高性能MySQL》书中其实也讨论这个情况:

延迟关联优化:通过使用覆盖索引查询返回需要的主键,再根据主键关联原表获得需要的数据。
select * from t_trade_order t
inner join (
select id from t_trade_order
where create_time between '2019-10-17' and '2019-10-25'
limit 1000000, 10
) e
on t.id = e.id;

根据explain分析,查询时间仅为0.31,比普通的分页查询快了一个数量级。
想必大家会想知道,为什么延迟关联对比普通分页查询可以起到这样的优化效果呢?
这就涉及到上面所讲的覆盖索引和回表这两个重要概念了!
我们来看看这两条语句的执行流程就很清楚了。
优化前:
select * from t_trade_order
where create_time between '2019-10-17' and '2019-10-25'
limit 1000000, 10;
(create_time建表时被设置为普通索引)
1.在create_time索引树上找到create_time=‘2019-10-17’的记录,取得其id。
2.再到主索引树查到对于id的记录
3.如数量小于10,更新时间,循环步骤1、2
4. 。。。
5.在create_time索引树取下一个值create_time='2019-10-25',不满足条件,循环结束。
6.查询结果放弃前1000000行,返回10行
显然,普通的分页查询是逐一通过普通索引获得id然后回表查询,每次回表进行一次IO,造成相当大的性能浪费。
优化后
select * from t_trade_order t
inner join (
select id from t_trade_order
where create_time between '2019-10-17' and '2019-10-25'
limit 1000000, 10
) e
on t.id = e.id;
1.使用覆盖索引,select id from t_trade_order where create_time between '2019-10-17' and '2019-10-25' limit 1000000, 10,查询结果放弃前1000000行,返回10行,查询出符合查询范围的id
2、回表关联,根据获得的id关联主索引表,批量匹配得到结果。(只需回到主索引表一次)
由此可知,通过使用覆盖索引查询返回需要的主键,再根据这些主键关联原表获得需要的行,这可以减少MySQL回表的次数,也避免了MySQL直接在原表上扫描那些需要丢弃的行数(实则在普通索引树上扫描,速度快很多)。
文章写到这里,希望对大家理解延迟关联优化有些许帮助。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号