





es7.+(四)--分词,ik分词器的安装
1.概念
一个 tokenizer(分词器)接收一个字符流,将之割为独立的 tokens(词元,通常是独立的单词),然后输出 tokens流。
例如,whitespace tokenizer遇到空白字符时分割文。它会将文本 "Quick brown fox!“ 分割为 [Quick, brown, fox]。该 tokenizer(分词器)还负责记录各个term(词条)的顺序或 position 位置(用于 phrase短语和 word proximity 词近邻查询),以及term(词条)所代表的原始word(单词)的 start(起始)和end(结束)的 character offsets(字符偏移量)(用于高亮显示搜索的内容)。
ElasticSearch 提供了很多内置的分词器,可以用来构建 custom analyzers(自定义分词器)
2.安装IK分词器
(https://blog.csdn.net/WoAiShuiGeGe/article/details/106792560)
注意:不能用默认elasticsearch-plugin install xxx.zip进行安装
进入es容器内部 plugins目录
docker exec -it 容器id /bin/bash
在线安装ik
elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.6.2/elasticsearch-analysis-ik-7.6.2.zip
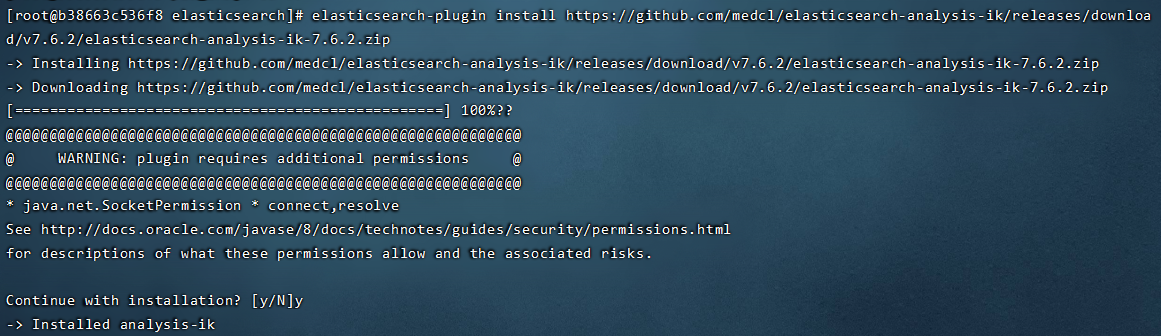
进入plugins文件夹可以看到解压安装完成

3.分词器_analyze
es自带的分词器
POST _analyze
{
"analyzer":"standard",
"text":"你好世界"
}
结果:
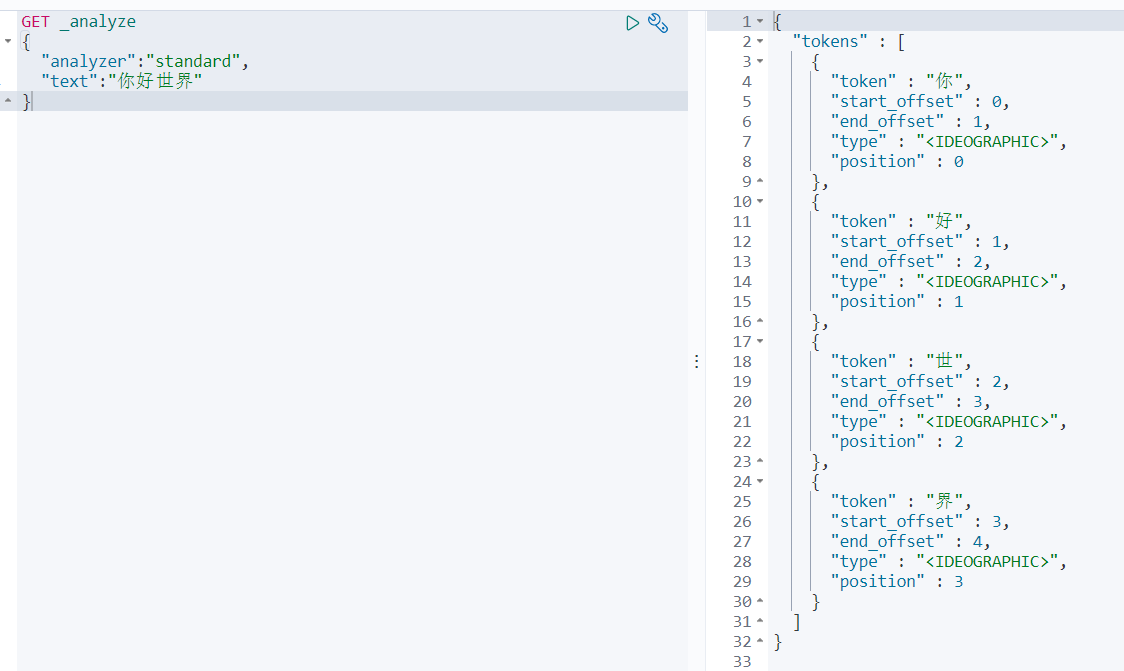
会将吧每一个字分开,达不到分词的效果
需要用到ik分词器
使用ik分词器
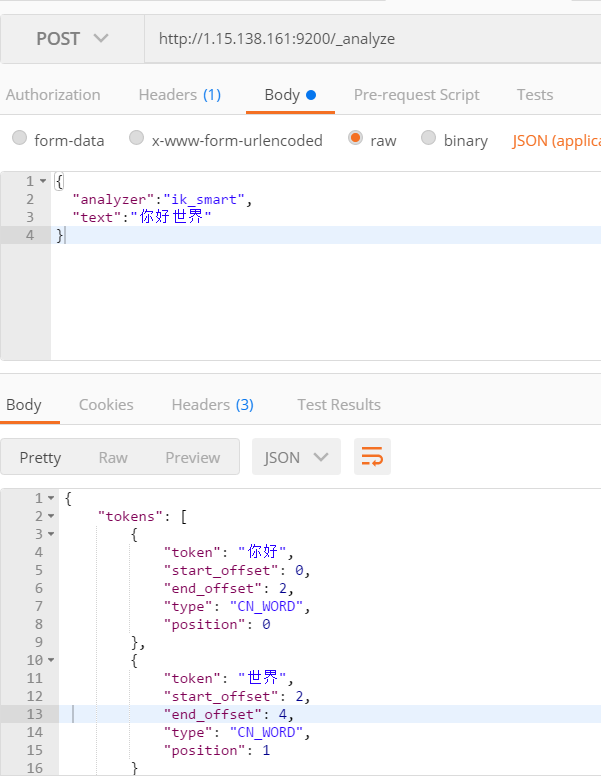
自定义扩展词库
ik分词器不能识别流行网络用于,新生词汇,人名等
需要安装nginx
- 随便启动一个nginx实例,只是为了复制出配置
- 运行一个nginx容器
- 创建一个存放文件夹
我的为/home/docker/nginx - 在创建出的文件夹下复制出nginx的conf文件夹
docker container cp nginx-test:/etc/nginx . - 删除该nginx容器
- 修改复制出的文件夹为conf
mv nginx conf
- 再创建一个新的nginx容器,并挂载
docker run -p 80:80 --name nginx -v /home/docker/nginx/html:/usr/share/nginx/html -v /home/docker/nginx/logs:/var/log/nginx -v /home/docker/nginx/conf:/etc/nginx -d f6d0b4767a6c
- 在html文件夹下创建一个es文件夹,专门用来存储自定义分词文件
- 创建分词文件fenci.txt

访问:fenci.txt
修改ik分词器的配置
- 修改/user/share/elasticsearch/plugins/ik/config/中的IKAnalyzer.cfg.xml
- 进入IKAnalyzer.cfg.xml
docker exec -it es7 /bin/bash
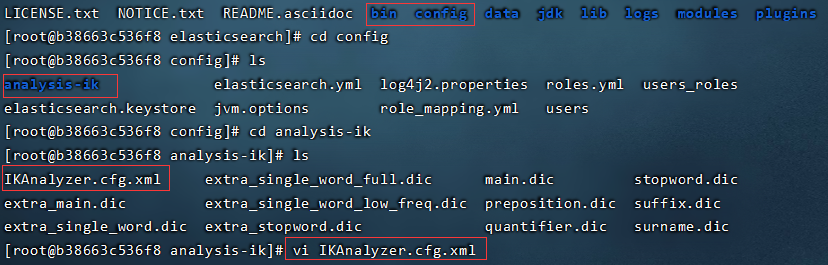
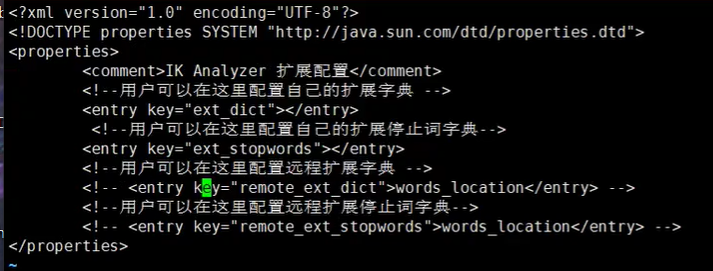
-
打开注释,输入分词字典的地址
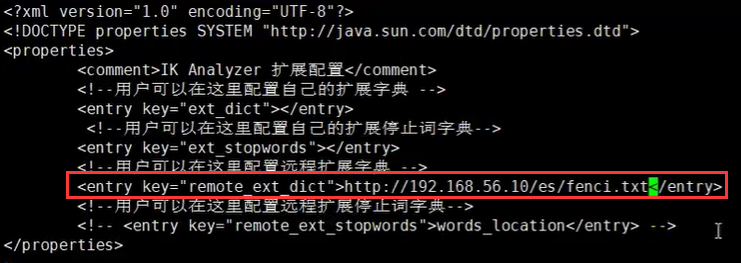
-
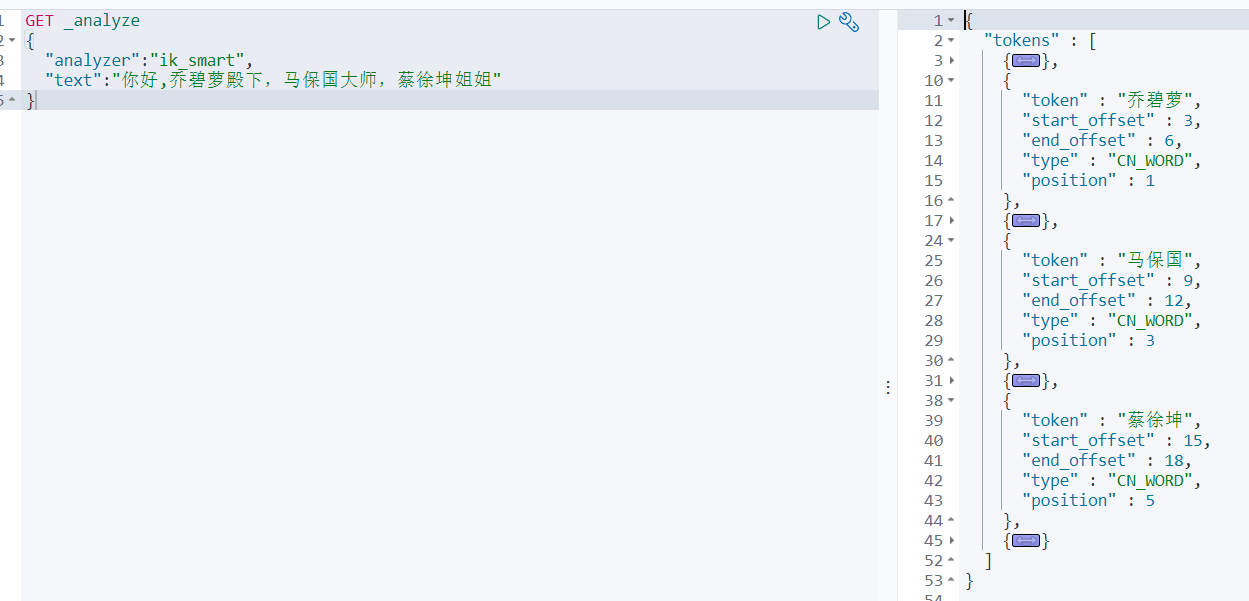
然后重启es
docker restart es7 -
再次分词查询:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号