寒假学习进度7
配置Job History Server【Standalone】
进入到Spark安装目录 cd /opt/modules/spark-2.1.1-bin-hadoop2.7/conf

将spark-default.conf.template复制为spark-default.conf
修改spark-default.conf文件,开启Log:

【注意:HDFS上的目录需要提前存在】
修改spark-env.sh文件,添加如下配置:
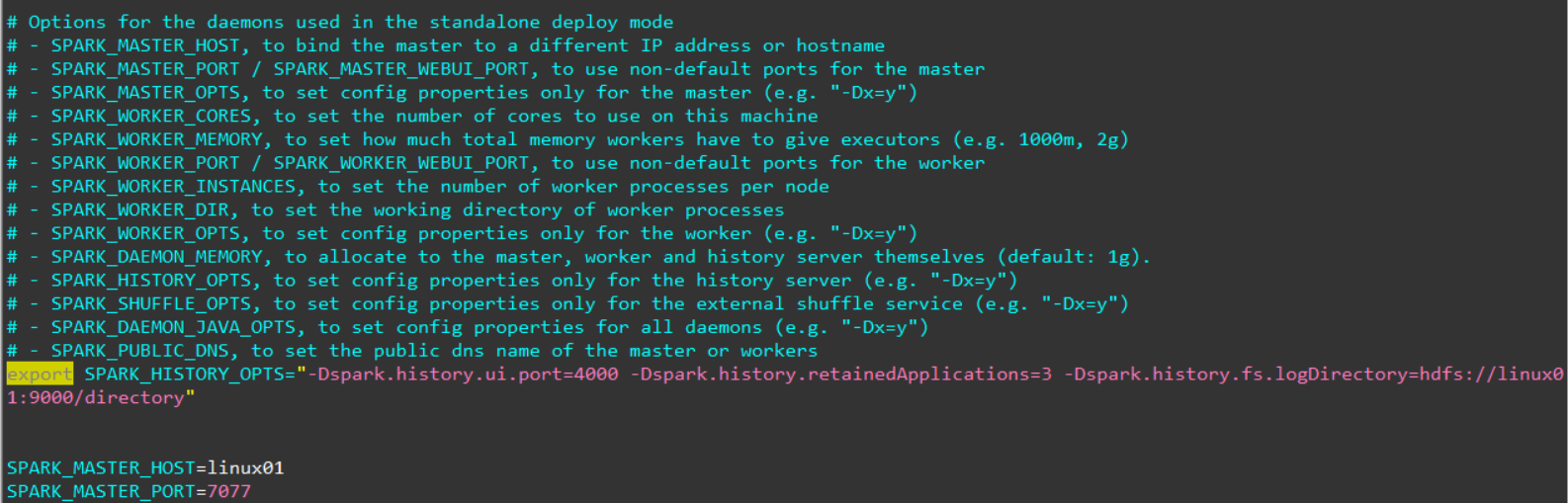
在HDFS上创建好你所指定的eventLog日志目录。
spark-defaults.conf
启动后执行:【别忘了启动HDFS】
/opt/modules/spark-2.1.1-bin-hadoop2.7/sbin/start-history-server.sh
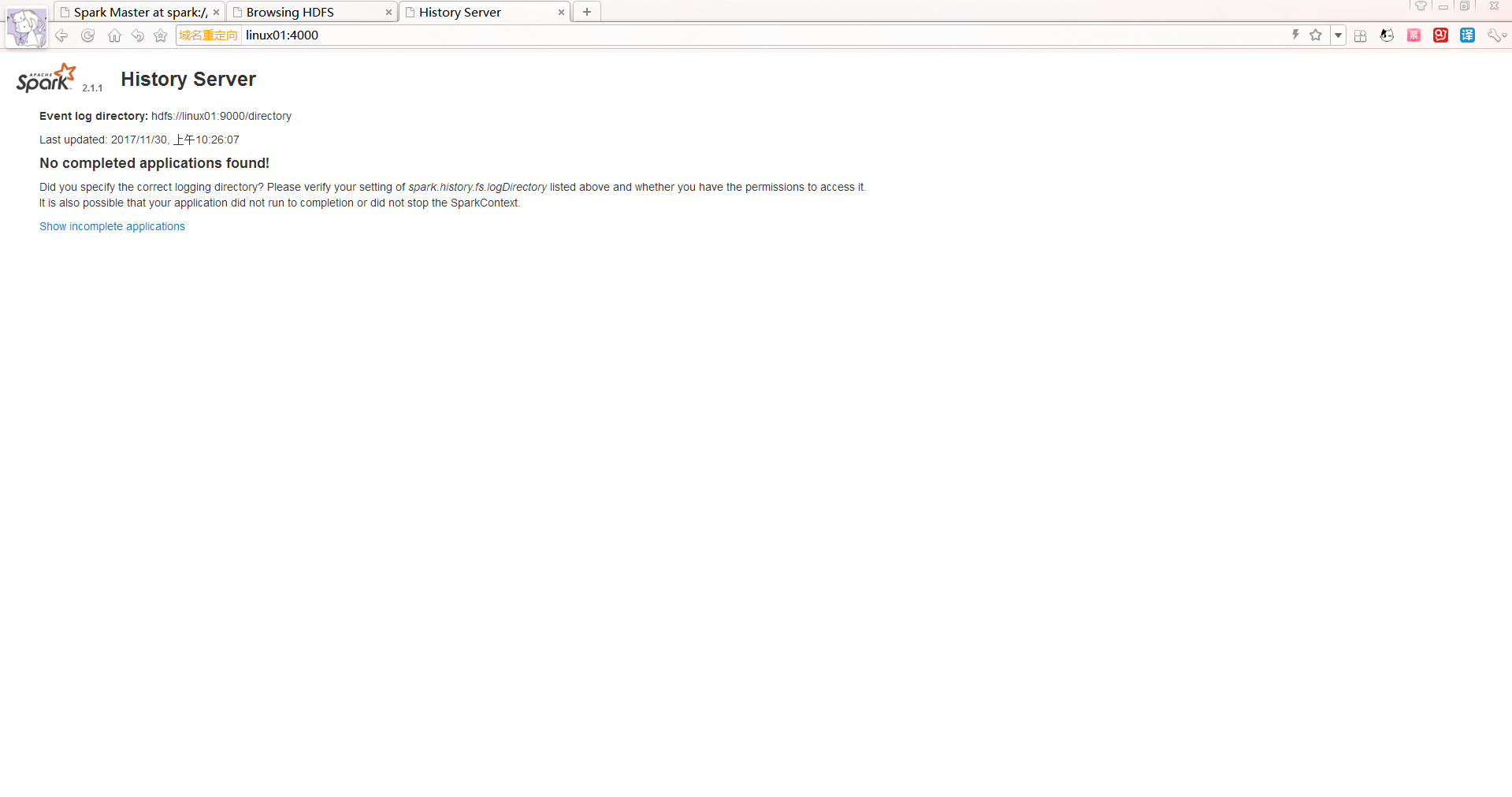
到此为止,Spark History Server安装完毕.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号