Discriminative Learning of Deep Convolutional Feature Point Descriptors 论文阅读笔记
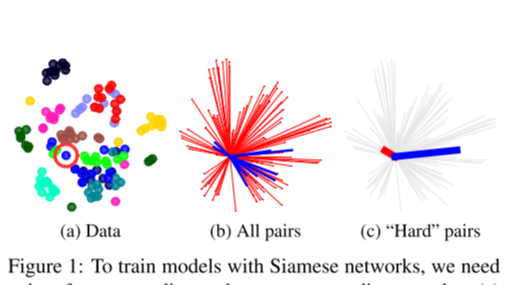 Siamese network 与 图像特征描述符
Siamese network 与 图像特征描述符
介绍
该文提出一种基于深度学习的特征描述方法,并且对尺度变化、图像旋转、透射变换、非刚性变形、光照变化等具有很好的鲁棒性。该算法的整体思想并不复杂,使用孪生网络从图块中提取特征信息(得到一个128维的特征向量),并且使用L2距离来描述特征之间的差异,目标是让匹配图块特征之间的距离缩短,让不匹配图块特征之间的距离增大。
数据集及模型结构
-
数据集
论文使用的是一个叫做MVS的建筑物数据集,包含了1.5M张\(64 \times 64\)张的灰度图来自500K个3D points。
-
网络的结构:
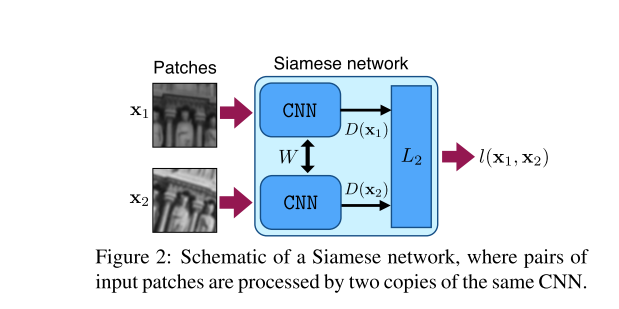
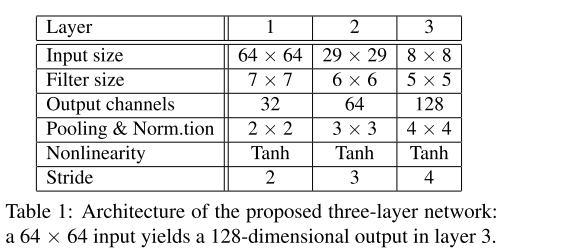
3.损失函数:
解释一下,C是一个最小距离阈值;两个图像块$ x_1, x_2$,如果它们来自同一个3D point \(pi\),则使用(1)的上半部分计算损失函数,否则使用下半部分计算损失函数。
- Mining
论文作者提出了一个训练模型的创新方法:

随着训练的进行,随机选择的负向样本之间的距离很容易就超过阈值C,使得损失变成0,无法有效的对网络进行训练了。也就是说,随机选择的负向样本太简单了,他们本身之间的距离就很大,无法有效的训练网络。因此作者希望能够从数据集中寻找到“困难”的样本,什么才算是困难样本呢,对于负向样本而言,就是他们之间的距离很小,非常相似,但却不属于一个3D点;对于正向样本而言,就是他们属于同一个3D点,但特征之间的距离却很大。这样的样本对模型训练有很好的促进作用。为了实现这个目标,作者先随机采样了一个包含\(s_n\) 个点的负样本集,然后经过一次正向的运算(网络正向传播)并计算损失,然后仅保留其中\(s_n^H\)个点构成的困难样本子集,并将这部分的损失反向传播回去,对网络参数进行训练。对于正向样本也采用同样的策略,来挖掘困难样本。
结果:
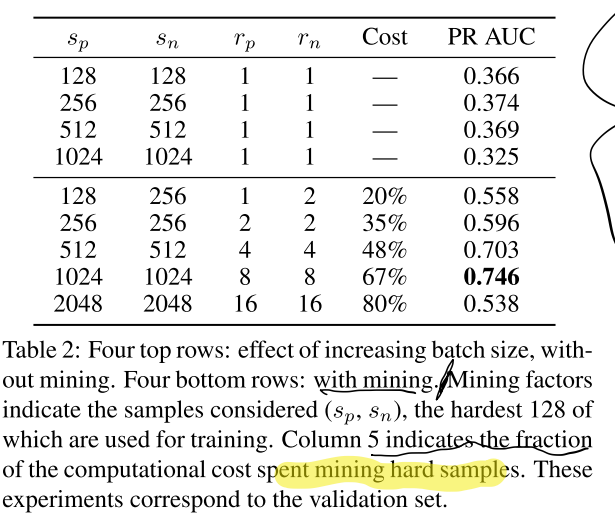
Last
 |
 |
这个PR curves应该与是某个指标有关,以后遇到了再查阅。 |
|---|
本文来自博客园,作者:CuriosityWang,转载请注明原文链接:https://www.cnblogs.com/curiositywang/p/15675671.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号