循序渐进nginx(三):日志管理、http限流、https配置,http_rewrite模块,第三方模块安装,结语
前置知识章节:
1.介绍、安装、hello world、location匹配✅
2.反向代理、负载均衡、缓存服务、静态资源访问✅
3.当前章节👉:日志管理、http限流、https配置,http_rewrite模块,第三方模块安装,结语。✅
日志管理
nginx里面有访问日志和错误日志,访问日志记录记录客户端访问nginx的每一个请求;错误日志记录发生错误的请求。
access_log
access_log用于配置访问日志,日志的格式可以根据log_format指令来进行自定义。
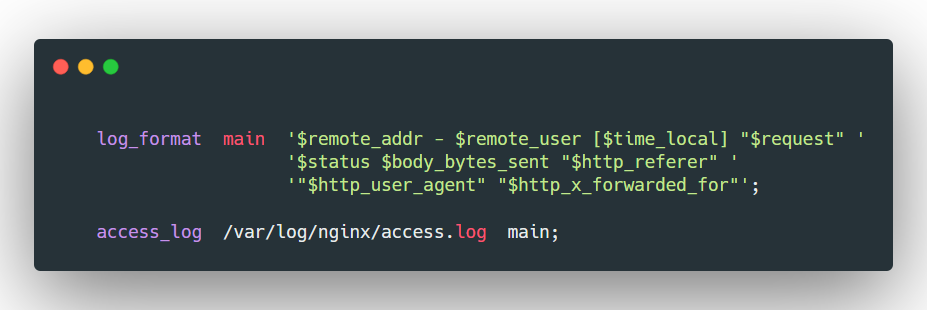
💡log_format用于定义访问日志的格式。log_format指令的第一个参数是格式名,可以给当前格式定义一个名字,第二个参数是格式字符串,支持一些内部变量语法,比如$remote_addr会获取到请求的客户端的IP地址。log_format只可以配置在http块中。
log_format示例:
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';
log_format mylog '[client_ip:] $remote_addr [time:] $time_local [user_agent:] "$http_user_agent"';
log_format语法说明:
- 整个字符串使用
''包裹,内部可以使用$开头的变量,比如$remote_addr会获取到请求的客户端的IP地址,其他字符都作为显示效果,比如上面使用的""只是用于包裹数据而已。[],-,:也是这样的。
💡access_log指令可以用来指定访问日志的存储位置和日志格式。access_log指令的第一个参数是访问日志的存储路径,第二个参数是使用的格式的格式名.access_log可以使用在http, server, location, location的if, limit_except等块中。
语法格式:
access_log path [format [buffer=size] [gzip[=level]] [flush=time] [if=condition]];
* path是日志存储路径
* format用于定义格式,是log_formate的名字,
* buffer=size 为存放日志的缓冲区大小
* flush=time 为将缓冲区的日志刷到磁盘的时间
* gzip[=level] 表示压缩级别
* if一般不配置
access_log off; # 关闭访问日志记录
💡默认在nginx.conf中配置了access_log的默认配置:
nginx日志常见可用变量:(更多变量可以参考:英文文档,某CSDN博客)
| 内置变量 | 说明 |
|---|---|
| $remote_addr | 客户端的IP地址 |
| $remote_user | 客户端用户名,用于记录浏览者进行身份验证时提供的名称,如果没有登录则为空 |
| $time_local | 访问的时间与时区 |
| $request | 请求的URI和HTTP协议 |
| $status | 记录请求返回的HTTP状态码 |
| $body_bytes_sent | 发送给客户端的文件主体 |
| $http_referer | 请求来源的URL地址 |
| $http_user_agent | 客户端浏览器信息 |
| $http_x_forwarded_for | 经过的客户端IP地址列表,如果请求是代理转发的,那么原始的客户端IP应该在这个字段里面 |
error_log
- error_log是错误日志,只有访问错误的时候才会记录下来。不支持格式定义。
- error_log的语法是:
error_log file [level];- error_log指令的第一个参数是错误日志存储路径,第二个参数是日志级别。
- 日志级别有debug,info,notice,warn,error,crit几个等级。debug的日志记录是最完善的,crit只记录“致命”级别的错误。
- error_log可以设置在http、server、location、location的if块中配置。
- 指令
error_log /dev/null用于关闭错误日志。/dev/null在linux中可以认为是一个无底洞,可以把它当作垃圾桶。
日志文件切割
对于日志文件有些版本会自动切割,有些版本不会,也就是说,如果你的服务端跑了一年,那么一年的访问日志都存储在access.log中,很明显,这不是一个好的处理,这样不方便我们在发生错误时分析日志。所以通常都会对日志文件进行切割,根据业务需求可能按天、按周来进行切割。
💡自动切割:如果你的nginx能够自动切割日志,那么你就不需要看了,怎么判断有没有自动切割功能呢,查看一下/etc/logrotate.d下是否有nginx文件,logrotate用于日志切割,linux自带的,但内置的除了切割还有一些其他的操作,比如定时清除,有需要的可以自行看一下vim /etc/logrotate.d/nginx
😓下面教的是使用定时任务自动切割日志文件,当然如果你喜欢手动也没问题。
我们只需要定义一个定时任务即可。
1.先提一下crontab的语法,用示例来简单讲解语法:
示例:0 * * * * /root/nginx-cut-log.sh>/dev/null 2>&1
crontab语法:
第一个参数:分(取值0-59,*代表每一个),对应上面第一个0
第二个参数:时(取值0-23),对应上面第二个0
第三个参数:日(取值1-31)
第四个参数:月(取值1-12)
第五个参数:星期(取值0-6,0代表星期日)
第六个参数:要运行的命令
额外的说明:
上面的命令中`>/dev/null 2>&1`用于把定时任务的标准输出和错误输出都重定向到“垃圾桶/黑洞”中。
2.然后编写一个切割日志文件的脚本文件nginx-cut-log.sh(命名随意):
#!/bin/bash
#定义日志目录变量
logs_path="/var/log/nginx/"
#切割日志,其实就是拷贝与新建而已。
#`date -d yes +"%Y%m%d"`中``可以用来获取linux命令的执行结果,可以参考https://www.cnblogs.com/asxe/p/9317811.html
mv $logs_path/access.log $logs_path/access-`date +"%Y-%m-%d-%H-%M"`.log # 测试的时候请打开这一个关闭下面的,这个用于每分钟执行一次。
#下面的这个应该用于每天执行的情况,因为以日期命名了文件
#mv $logs_path/access.log $logs_path/access-`date -d "1 day ago" +"%Y-%m-%d"`.log
#上面的操作类似于重命名,所以原本的access.log会没了,使用下面的命令让nginx重新生成一个access.log.
/nginx -s reopen;
3.记得给脚本文件增加执行权限:
chmod +x nginx-cut-log.sh
4.然后定义一个定时任务:
执行命令crontab -e,并在那里附加下述命令:
* * * * * /root/nginx-cut-log.sh>/dev/null 2>&1
上面的用于每分钟都创建新的日志文件的测试,正式使用应该前面两个是一个准确的值,比如0 0 * * * /root/nginx-cut-log.sh>/dev/null 2>&1代表每天零点零分执行。
5.然后重启crond:执行命令crond restart
6.然后你在/var/log/nginx/目录下等一分钟看是否会创建新的access.log文件。如果创建了,就说明我们的日志切割成功运行了。当然,记得测试完后清除我们上面在crontab -e中输入的命令,因为那个代表了每分钟都运行。
自定义错误页
- 自定义错误页其实是一个非常小的内容。用于定义nginx的http请求发生错误的时候显示的页面
- 语法:
error_page code ... [=[response]] uri; - 示例:
error_page 500 502 503 504 /50x.html;:代表http响应码为500,502,503,504时,返回各自location的root下的/50x.htmlerror_page 400 http://xxxx.html:代表http响应码为400时,返回http://xxxx.htmlerror_page 404 = @fallback;还支持内部重定向,@fallback是自定义的一个内部重定向location.error_page 400=200 http://xxxx.html:发生400错误时,返回http://xxxx.html,并修改返回的响应码为200.
http访问限流
💡访问限流依靠ngx_http_limit_conn_module模块,ngx_http_limit_req_module模块。ngx_http_limit_conn_module用来限制连接数。ngx_http_limit_req_module用来限制请求数。
💡为什么需要限流呢?那是为了防止过量的请求给服务端带来过大的压力。
❓连接跟请求的区别:
- http也是应用层协议,也是tcp的一种,http请求其实是使用tcp来连接请求的。在HTTP/1.0中,大多是一次连接,一次请求的。但它其实也支持
Connection: keep-alive,如果在响应的Header中有这Connection: keep-alive,那么就会维持连接,直到响应/请求的Header中有Connection: close才断开连接(超时也会,keep-alive也是有时效的)。在Connection: keep-alive的时候一个连接可以发起多个请求。
如下图,我连续请求一张图片,第一次的时候initial connection初始化了tcp连接,而第二次请求的时候没initial connection,这代表连接没用端口:
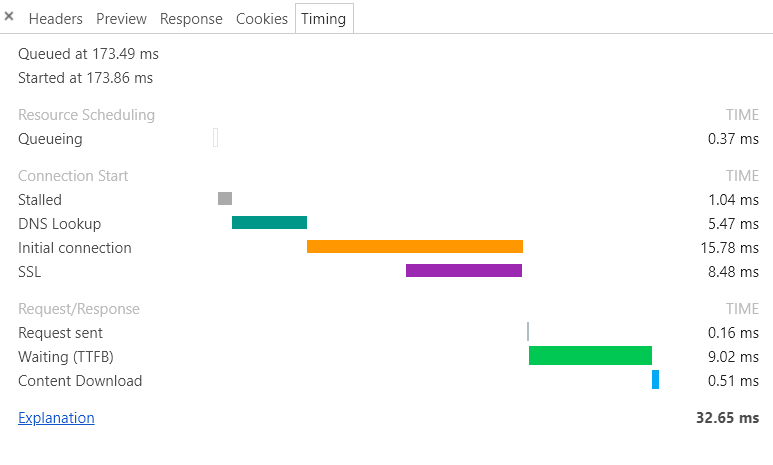
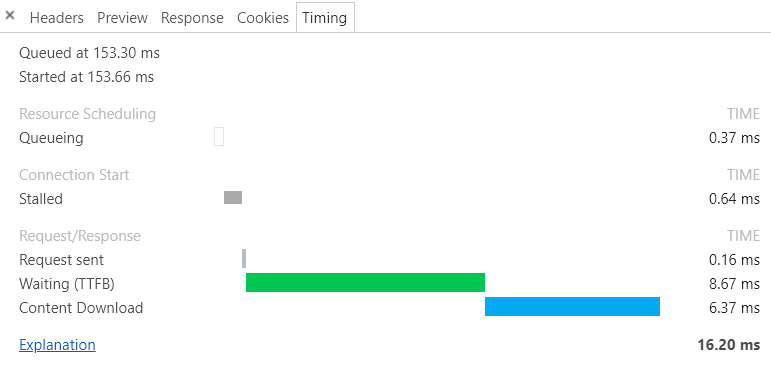
百度的请求是支持Connection: keep-alive的,你可以尝试在谷歌浏览器中打开百度的一张图,并打开它的请求Timing来查看是否每一次都initial connection(初始化连接,这代表建立新的tcp连接,而stalled代表检测是否有旧的可用的tcp连接,所以上面的第二种图中没用initial,只有stalled,stalled使用了没断开的tcp连接)中测试。
限制请求数
语法
💡limit_req_zone:用来设置请求限制规则,
- 语法
limit_req_zone key zone=name:size rate=rate;- key用于定义请求限制的对象,比如为
$server_name的时候,代表限制虚拟主机的请求次数,为$binary_remote_addr或$remote_addr时代表限制同一个IP的客户端的请求次数。 - zone=name:size中,name是当前这个请求限制规则空间的名字,size是这个空间的大小。
- key用于定义请求限制的对象,比如为
- 使用位置 : limit_req_zone只能配置在Http块。
- 示例:
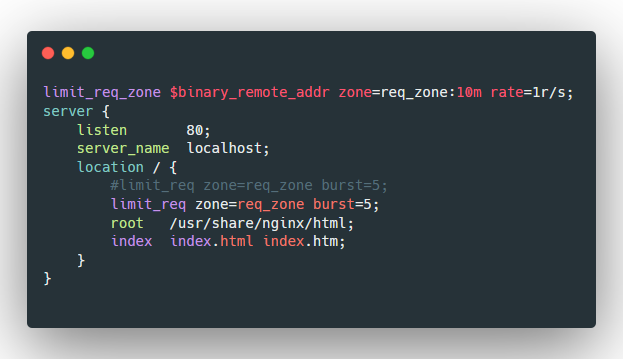
limit_req_zone $binary_remote_addr zone=req_zone:10m rate=1r/s;
💡limit_req:与limit_req_zone配合,用来定义限制请求次数。
- 语法:
limit_req zone=name [burst=number] [nodelay | delay=number];- zone=name中name式limit_req_zone的名字
- burst用来定义突发大小,例如在
limit_req zone=req_zone burst=3中,限制请求次数是1,那么突发的2个请求会放到下一秒再执行。
- 使用位置 :limit_req可以用在http, server, location
- 🔴超出请求限制的请求,会返回503.
- 示例:
limit_req zone=req_zone burst=3 nodelay;
使用
1.配置nginx:
2.重启之后测试:你可以在一秒内连续在浏览器中刷新,如果刷新多次之后突然响应503,那说明请求被限制了。或者你可以在/var/log/nginx/error.log中看到limiting requests
限制连接数
语法
💡limit_conn_zone:用来设置连接限制规则,语法limit_conn_zone key zone=name:size;
- key用于定义连接限制的对象,比如为
$server_name的时候,代表限制虚拟主机的连接次数,为$binary_remote_addr或$remote_addr时代表限制同一个IP的客户端的连接次数。 - zone=name:size中,name是当前这个连接限制规则空间的名字,size是这个空间的大小。
- limit_conn_zone只能配置在Http块。
- 例如:
limit_conn_zone $binary_remote_addr zone=addr:10m;
💡limit_conn:与limit_conn_zone配合,用来定义限制连接次数。语法limit_conn zone number;
- number是限制的次数。
- limit_conn可以用在http, server, location。
- 例如:
limit_conn addr 1;,假如addr是一个限制同一个IP的客户端的连接次数的规则,代表同一个IP的客户端的并发连接为1.
💡补充:并不是所有的连接都会被计算,只有并发压力的连接才计算,比如上面的limit_conn addr 1;代表每个IP只能有一个连接,但如果你给不了nginx请求压力的话,那么假设你发起两个连接,nginx马上处理完第一连接之后,后面来的第二个连接此时并不算并发连接(这时候就限制失败了),所以如果你下面测试的话,可以访问处理比较慢的资源,让nginx持续地持有这个连接,然后我们再发起另外一个连接,这样才能测试成功。下面是官网文档的一段话:
Not all connections are counted. A connection is counted only if it has a request being processed by the server and the whole request header has already been read.
测试
上面说了, 要使用一个响应比较慢的资源,所以我们这里使用反向代理来作为响应。
1.新建一个后端服务端接口:(下面示例基于spring boot,我让它sleep了10秒,也就相当于要处理十秒才能响应数据。此时有充足的时间来让我们发起第二次数据)
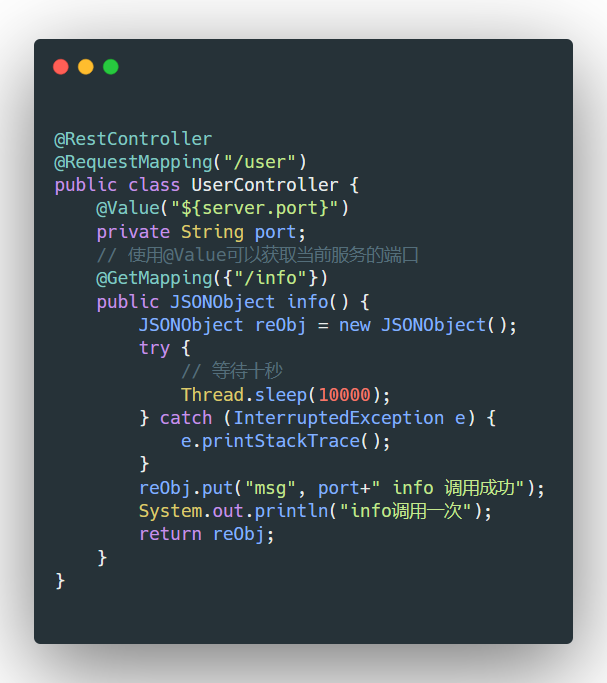
2.配置default.conf:
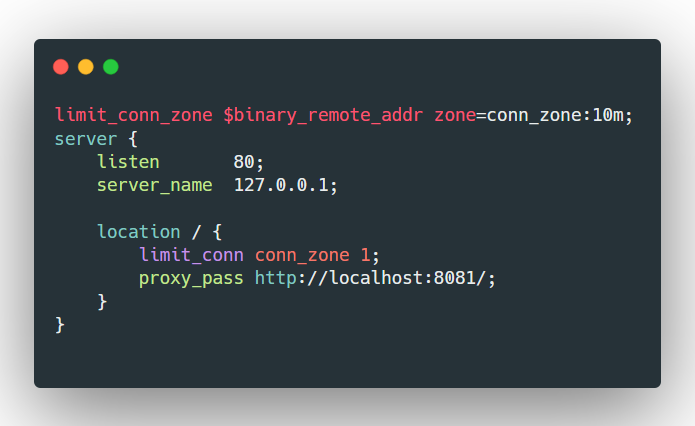
3.测试访问:
- 首先访问一下
http://192.168.31.128/user/info,这个是我的代理后的请求接口,响应时间至少需要十秒 - 在上面响应的十秒内,用另外一个窗口访问一下
http://192.168.31.128/user/info,这个会直接得到503,而不是等待十秒的响应。
补充:
limit_rate可以用来限制响应的传输速度,这里没讲。
https配置
💡注意,此时的https配置并没有太多实战意义,因为证书都是正规机构发的话,浏览器才能够识别成安全的。这里的教学只是做个认知,就是知道怎么配置,证书什么的是都是应该从正规机构申请的。
- 使用
nginx -V查看编译参数,如果有--with-http_ssl_module,那么就代表启用了ngx_http_ssl_module模块。默认的YUM方式安装是携带这个模块的。如果你是使用了编译安装的,那么自行去加上吧。
Https有什么好处,处理什么情况,这些自己查吧。
Https会使用几种加密方式,非对称加密用于身份验证和密钥协商,对称加密用于采用协商的密钥来对数据进行加密。另外散列算法用于检验数据完整性。
对称加密使用同一个密钥。
非对称加密,公钥用于加密,私钥用于解密
Https简单流程:首先发起非对称加密,服务端将公钥发送给客户端(此时发送的是证书,证书客户端是需要校验的),如果证书合法,那么客户端使用伪随机数来生成一个会话密钥,使用证书加密会话密钥并传输给服务端。服务端使用私钥来解密得到会话密钥。然后后面传输的数据使用此时两端都知道的会话密钥来加密数据。💡从这个简单流程,应该我们只需要关心两条🔑,一个是证书,一个是私钥。
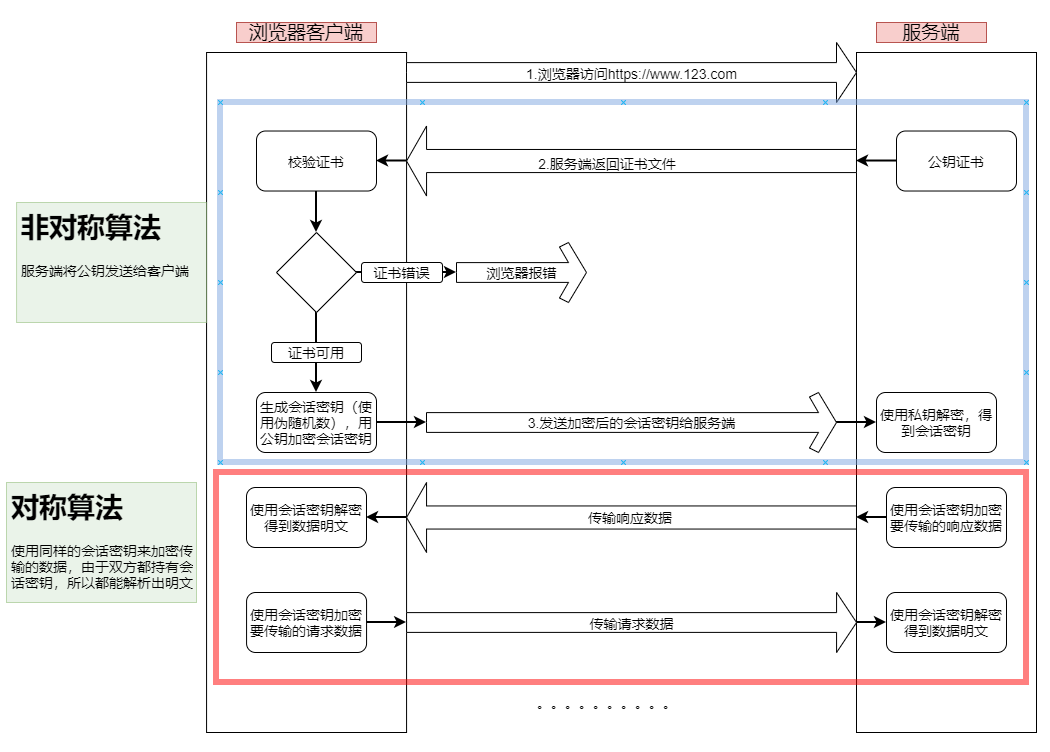
使用
生成证书
1.生成证书私钥:此处生成的私钥用于提交给CA来生成证书认证签名文件。
openssl genrsa -out server.key 2048用于生成密钥Key,执行这个命令后需要输入一个密码,会基于这个密码来生成私钥。
genrsa代表使用RSA来生成私钥,openssl rsa代表从私钥中获取公钥。- 可选的
-des3:指定生成的密钥使用des3方式进行加密,这样的话每次使用都需要输出密码来解密。 - out 文件路径:用于指定生成的key的位置。2048是密钥的长度,长度越长,安全性越强,一般推荐使用2048。
2.创建服务器证书的申请文件server.csr。CSR文件是您的公钥证书原始文件,包含了您的服务器信息和您的单位信息,需要提交给CA认证中心审核。
openssl req -new -key server.key -out server.csr
会提示输入几个内容:
- 如果你上面使用了-des3来生成证书私钥,那么第一行会是要求你输入私钥的解密密码
server.key:生成密钥时输入的密码 Country Name (2 letter code) [XX]:国家代码,如CN,可以不填,直接回车跳过即可。State or Province Name (full name) []:省份名称,可以不填,直接回车跳过即可。Locality Name (eg, city) [Default City]:城市名称,可以不填,直接回车跳过即可。Organization Name (eg, company) [Default Company Ltd]:机构名称,可以不填,直接回车跳过即可。Organizational Unit Name (eg, section) []:组织单位名称,可以不填,直接回车跳过即可。Common Name (eg, your name or your server's hostname) []:使用SSL加密的域名。注意这里要配成你的网站的域名,不然在访问的时候会说"这个证书不属于这个网站(😓英文我忘记是什么了)",如果你看到这样的错误的话,你就应该知道是你的证书绑定错了域名。比如可以输入www.123.com。Email Address []:邮件地址,可以省略A challenge password []:有些认证机构需要这个密码,一般为空An optional company name []:可选的公司名称,省略即可。
💡其实上面这个创建证书文件也就是自己用用而已,正式的时候都会去证书机构中申请,比如在阿里云或者腾讯云中申请一个免费的证书,个人用的话申请一个免费的就可以了。【PS:证书也是有区别的,一些证书只会加密数据,不能用于认证,比如说有些网站访问的时候就会显示XXX公司,其实这就是在证书中做了企业认证。】
3.生成CRT证书认证文件:
openssl x509 -req -days 365 -in server.csr -signkey server.key -out server.crt
* X509用于自签名
* -req:x509工具默认以证书文件做为inputfile(-in file),指定该选项将使得input file的file为证书请求文件。
* -days 30 用于设置证书的有效期
* -in:用于指定CSR证书申请文件
* -signkey:用于指定签名的私钥
* -out:用于指定输出的CRT证书认证文件的路径。
4.完成:
那么此时生成了一个.crt文件和.key文件。
配置nginx
简单配置一个新的server:
server {
server_name www.123.com;
listen 443 ssl;
ssl_certificate /etc/nginx/ssl_key/server.crt;
ssl_certificate_key /etc/nginx/ssl_key/server.key;
location / {
root /usr/share/nginx/html;
}
}
- ssl_certificate用于配置服务端上CA证书的位置
- ssl_certificate_key用于配置服务端上CA私钥的位置
- 在旧版本中
ssl on用来开启ssl,现在可以使用listen 443 ssl来代替。 - 更多配置可以自行参考ngx_http_ssl_module
测试
为了尽量达到仿真,所以我们手动配置一个dns,这样的话我们就相当于有一个虚假的域名了。

访问我们的虚假网站www.123.com:

但由于我们是本地环境,它始终会报错,它还是会在浏览器中显示不安全,但https是已经配置成功了的。我们选择强行访问的话,链接栏仍热会报红:

只是因为我们是自己生成证书,导致证书颁发机构不可信而已,如果我们是从网上申请的证书,那么此时证书颁发机构应该是可信的。

补充
💡正规域名的https配置可以稍微参考阿里云nginx配置https文档
HttpRewrite模块
if
if在nginx文档中
💡if属于ngx_http_rewrite_module模块。
💡if可以做一些的判断,根据条件来进行不同的处理,可以使用在server和location中。
💡if的使用场景:
- 场景一:假如你想让没有携带指定header的请求返回403的话,这样的请求判断需要借助if。
- 场景二:如果浏览器是IE浏览器,返回指定数据
- 。。。
下面是一个例子,就是如果浏览器是谷歌浏览器,就返回503。
#禁止chrome访问:如果$http_user_agent`如果包含Chrome,就禁止访问。
if ($http_user_agent ~ Chrome) {
return 503;
}
if的语法:
- 判断条件:
=用于判断两个值是否相等,例如if ($request_method = POST)!=用于判断两个值是否不相等~:大小写敏感的正则匹配,与后面的正则搭配使用,例如:if ($http_user_agent ~ MSIE)代表$http_user_agent如果包含MSIE,就为true。~*:对大小写不敏感的正则匹配,与后面的正则搭配使用。!~:如果~结果为true,则!~为false!~*:如果~*结果为true,则!~*为false-f:如果文件存在,为true。例如:if (-f $request_filename)!-f:如果目录存在,文件不存在,为ture;目录和文件都不存在,为false。例如:if (!-f $request_filename)-d:如果请求的目录存在,则为true!-d:如果请求目录的上级目录存在,目录不存在,为true;如果上级目录和目录都不存在,为false.
- if可以使用变量来判断,可用变量有全局变量和自定义变量。
下面是可以用作if判断的全局变量
全局变量
| 参数名 | 说明 |
|---|---|
| `$arg_PARAMETER | PARAMETER是变量名,可以根据不同的PARAMETER获取请求行中的指定参数,也就是URL中的参数。 |
$args |
URL中的查询参数。,比如https://www.baidu.com/baidu?wd=nginx&tn=monline_4_dg&ie=utf-8中的wd=nginx&tn=monline_4_dg&ie=utf-8 |
$binary_remote_addr |
二进制的客户端IP地址。 |
$content_type |
请求头中的Content-Type字段。 |
$cookie_COOKIE |
客户端cookie信息 |
$document_root |
当前请求在root指令中指定的值。 |
$document_uri |
包含请求参数的原始URI |
$host |
请求头中的Host字段 |
$http_HEADER |
HEADER是一个变量,可以用于获取请求头中的参数值。 |
$http_user_agent |
客户端agent信息,客户端浏览器信息 |
$http_cookie |
客户端cookie信息 |
$is_args |
如果有url参数,则为?;无则为空。 |
$limit_rate |
nginx配置的limit_conn的数值。 |
$query_string | 与$args功能一致 |
|
$remote_addr |
客户端的IP地址 |
$remote_port |
客户端的端口 |
$request_filename |
当前请求的资源文件的路径名 |
$request_method |
请求的方法,GET、POST之类的。 |
$request_uri |
包含请求参数的原始URI,不包含主机名 |
$scheme |
http还是https |
$server_addr |
服务端地址 |
$server_name |
服务端名称(域名) |
$server_port |
服务端接收请求的端口 |
$server_protocol |
http协议版本,1.0,1.1,HTTP/2? |
$uri | 与$document_uri相同 |
自定义变量:
除了使用全局变量来判断,还可以自己通过set $变量名 值设置变量,例如:
location / {
root /usr/share/nginx/html;
default_type text/html;
set $flag "";
if ($http_user_agent ~ Chrome) {
set $flag "Chrome";
}
# 这里绕了一圈只是为了说明,可以使用我们自己设置的变量
if ($flag = 'Chrome') {
return 200 "hello";
}
}
set的值除了是一个字面值,还可以是一个全局变量,比如set $web_agent "${http_user_agent}";。set的使用应该是面向场景的,所以这里只做个开头,当你想要某个值来做判断的时候,你可以自己去探究一下这个值该怎么设置。
重定向rewrite
💡rewrite属于ngx_http_rewrite_module模块。
💡rewrite用于重写url和重定向,一个比较常见的用途是,比如用于http重定向https,你原本访问http://example.com,我帮你强制跳转到https://example.com;比如某文件位置迁移了,访问旧的位置,重写成迁移后的位置;比如根据不同浏览器重定向到不同页面你是IE浏览器,我就帮你转到一个特定的页面;这就是rewrite干的活,做一些重定向的活。
💡语法是:rewrite regex replacement [flag],可以使用在server, location, if中。
- regex是正则,注意传入的数据是uri,不包括域名,只包含访问的资源路径。
- replacement是重定向的路径。可以使用 ($1,$2)来获取正则中的匹配结果或使用全局变量来拼接URL。
- flag可以是以下几个:
- last:会内部重新发起一个重定向目录的请求,可以匹配到nginx的location。
- beak:匹配后,会内部从root目录查找重定向的目录,不会匹配location。
- redirect:会返回302给浏览器,让浏览器发起新的请求,代表临时重定向,浏览器不会缓存。
- permanent:会返回301给浏览器,让浏览器发起新的请求,代表永久重定向,浏览器会进行缓存,下次访问这个地址的时候,浏览器直接重定向,不需要访问nginx再重定向。
实验一:测试regex匹配对象的是什么:
server {
listen 80;
server_name 127.0.0.1;
location / {
rewrite (.*) http://192.168.48.129$1 redirect;
}
}
当访问nginx所在机器192.168.31.128/aaa/bbb的时候,由于上面的规则是重定向到http://192.168.48.129$1,所以得出结论,regex对应的部分就是有/开头的uri部分。
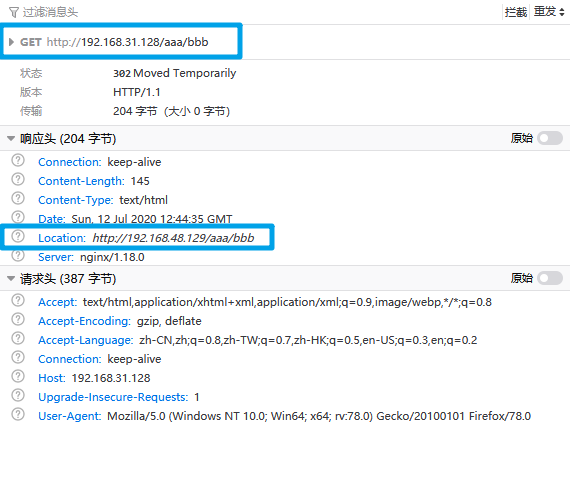
实验二:重定向到指定的页面:
server {
listen 80;
server_name 127.0.0.1;
location / {
#只有匹配成功的时候才重定向,访问/rewrite/aaa时重定向,访问/aaa时不重定向
rewrite ^/rewrite/(.*) http://192.168.48.129/$1 redirect;
#访问http://192.168.31.128/rewrite时,重定向到http://192.168.48.129
#访问http://192.168.31.128/rewriteaaa,重定向到http://192.168.48.129
#rewrite ^/rewrite http://192.168.48.129 redirect;
#访问http://192.168.31.128/rewrite,内部重定向到http://192.168.31.128/hello
#root /usr/share/nginx/html;
#rewrite ^/rewrite /hello last;
#访问http://192.168.31.128/rewrite,返回"root"+/hello.html资源
#root /usr/share/nginx/html;
#rewrite ^/rewrite /hello.html break;
}
location /hello{
default_type text/html;
return 200 "hello";
}
}
实验三:与if配合重定向,假如浏览器是IE的,跳转到指定页面:
server {
listen 80;
server_name 127.0.0.1;
location / {
#访问http://192.168.31.128/rewrite,返回"root"+/hello.html资源
root /usr/share/nginx/html;
# 如果http_user_agent中包含了chrome,那么就重定向
if ($http_user_agent ~ Chrome) {
rewrite ^(.*)$ /chrome/$1 break;
}
rewrite ^/rewrite /hello.html break;
}
}
第三方模块
上面的例子中都是内置模块的内容,但也稍微提了一下第三方模块,比如在负载均衡中提到了fair和url_hash。对于需要使用第三方模块的,还是建议使用编译安装的方式,那样添加第三方模块比较方便。
前置知识(编译安装)
1.先到官网下载编译安装用的tar包,或者wget http://nginx.org/download/nginx-1.12.1.tar.gz【因为下面的演示的echo模块最高兼容1.16,所以这里安装1.16】
2.解压tar包:tar -zxvf nginx-1.12.1.tar.gz
3.cd nginx-1.12.1/
4../configure --prefix=/etc/nginx,注意,编译方式安装,文件目录布局与yum安装方式的不太一样。
5.make && make install
6.进入/etc/nginx/sbin目录下执行./nginx -v,如果能够正常输出nginx版本,那么就代表编译安装成功了。
💡--prefix 用于指定nginx编译后的安装目录
【docker内部的nginx也是编译安装的,如果你懂docker,那么你可以通过修改docker的dockerfile来添加第三方模块】
【如果你是覆盖安装的,注意保存之前的配置信息。】
安装第三方模块
安装第三方模块需要我们重新编译安装,所以下面的过程是以编译安装为基础的。
下面的安装模块我们以echo模块为例。echo模块可以返回变量,比如echo $remote_addr;代表把客户端的IP作为响应数据。
1.从github上下载echo模块的源代码:echo-nginx-module
或者直接在nginx所在的机器上wget https://github.com/openresty/echo-nginx-module/archive/v0.61.tar.gz
2.上传到nginx所在的机器上。
3.解压第三方模块echo模块:tar -zxvf v0.61.tar.gz
4.我们进入到之前的nginx源代码目录:cd nginx-1.12.1/
5.重新编译安装:./configure --prefix=/etc/nginx --add-module=/root/temp/echo-nginx-module-0.61
6.make && make install
7.进入/etc/nginx/sbin目录下执行./nginx -V,如果能看到configure arguments: --prefix=/etc/nginx --add-module=/root/temp/echo-nginx-module-0.61,那么就代表编译安装成功了。除了这样,你还可以尝试在代码中添加echo指令来测试。
在还没安装之前:如果你在代码中使用echo的话,重启nginx会报如下的错误: 
nginx: [emerg] unknown directive "echo" in /etc/nginx/conf.d/default.conf:5
nginx: configuration file /etc/nginx/nginx.conf test failed
那么如果我们安装了之后,不报错,并且访问nginx服务端之后,返回的是客户端的IP地址的话,那么就说明第三方模块安装成功了。
知识补充:
--add-module=第三方模块源代码路径用于添加第三方模块,--add-module=/usr/local/nginx/third_module/echo-nginx-module-0.60代表添加了echo模块。--with-模块名表示启用的nginx模块,如--with-http_ssl_module代表启用了http_ssl_module模块
没有讲到的内容
没有讲到的内容其实挺多的,但上面的应该是常见的内容了,学会了应该就够日常使用了,后面有需要你自己去百度的时候应该就能看懂别人的配置了。
其他的内容由于优先级不是很高,而且考虑篇幅问题,所以这里没有讲解,下面列举一下我觉得可能
🔶nginx还支持邮件服务,但可能比较少用。
🔶nginx与Keepalived搭配的高可用。【其实挺重要,大家可以自己搜索学习一下】
🔶nginx也支持NFS(网络文件系统),但有一些替代方案,比如对于Java来说的话,比较常见的是FastDFS(也依托nginx)了。
🔶网页压缩,可以使用GZIP来进行网页压缩,来减少传输的数据,但压缩是需要系统去处理的,所以可能需要消耗一些CPU资源。自己有需求就去找找看吧。
🔶nginx与其他服务器的比较,因为这篇文章重点不是这个,所以不讲。
🔶如果你关心文件传输方面的知识,那么可以了解下send_file 和tcp_nopush对于数据传输的处理。
🔶sub_status模块,用来查看nginx自上次启动以来的工作状态。包括处理的连接数、请求数等。
🔶geoip可以用于地区识别,比如基于IP判断用户的地区。
🔶http_slice_module模块可以用于大文件分片的处理。
🔶如果你想拿来当面试谈资,那么IO多路复用模型可以了解一下,nginx.conf的events块中其实可以修改nginx对于请求处理的IO模型,当问nginx为什么那么厉害的时候,IO多路复用模型也可以谈一下。
😀我这篇文章讲了一些例如负载均衡的内容,但这并不代表你不需要额外学习nginx的内容了,因为我只是讲了普通情况,如果你的业务复杂的话,那么你最好仔细的看一下官方文档了。
😀请认清,这只是一篇用于基础理论了解的文章而已。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号