
k8s指令部署各个常用功能
k8s之所以这么火,主要是提供了许多功能,比如服务的快速部署、服务的滚动升级、自动扩缩容、service下的服务负载均衡等功能。下面来动手实操下几个主要的功能。
2.1、K8s基本指令介绍
1、查询pod服务信息: kubectl get pod
2、查询pod服务详细信息: kubectl get pod -o wide
3、查询deployment服务部署对象信息: kubectl get deployment
4、查询rs副本控制器对象信息: kubectl get rs
5、查询pod描述信息: kubectl describe pod podName
6、查询pod服务日志: kubectl logs podName (pod内部只有一个容器) kubectl logs podName -c cname
7、登录pod服务内容容器: kubectl exec -it podName – sh (pod内部只有一个容器) kubectl exec -it podName -c cname – sh
8、删除服务: kubectl delete xxName
查询帮助文档:
1、kubectl –help # 查询k8s所有的指令
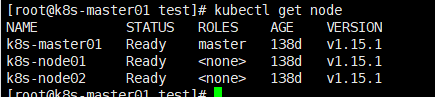
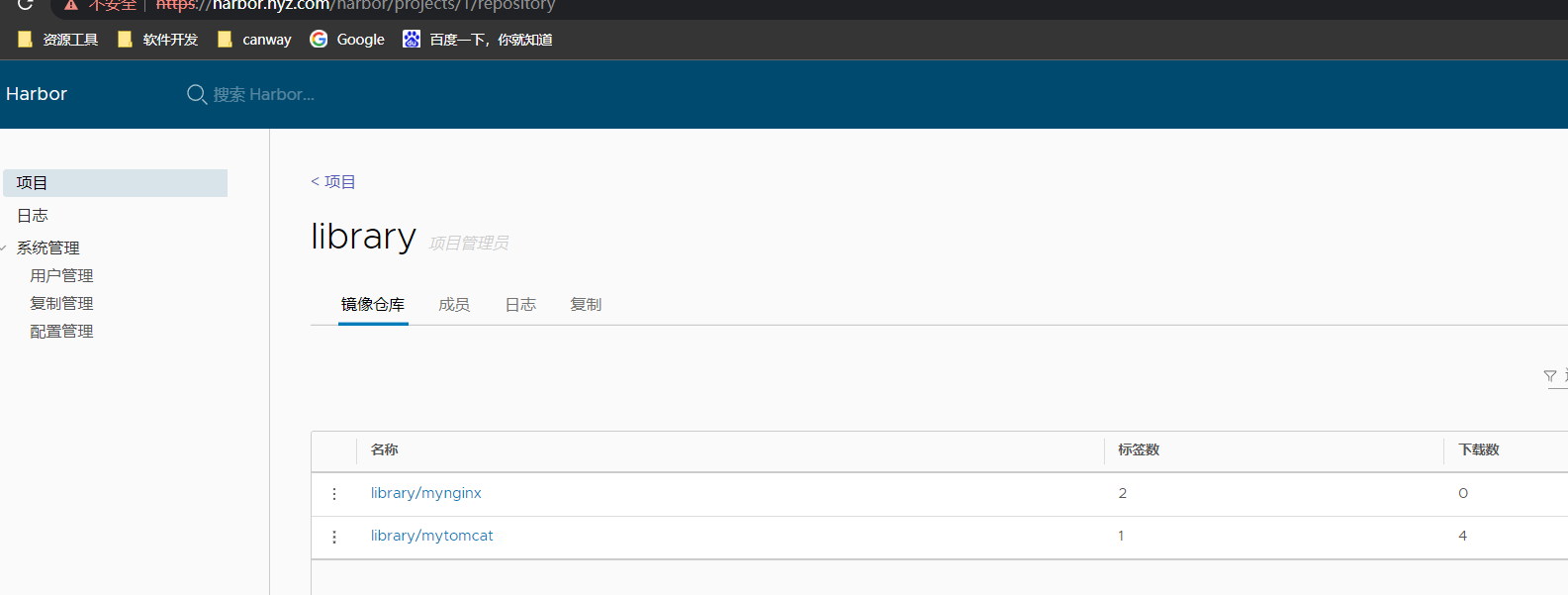
2.2、查看k8s本地集群及harbor仓库
kubectl get node
harbor仓库
2.3、服务部署
需求: 部署一个my-app服务(内部是nginx服务程序,nginx放入一个静态资源页面)
部署指令:kubectl run my-app --image=harbor.hyz.com/library/mynginx:v1 --port=80
说明:通过指令部署服务,默认是部署一个Deployment,Deployment下有一个ReplicaSet,ReplicaSet控制了需要部署多少个Pod服务。
如下图所示:
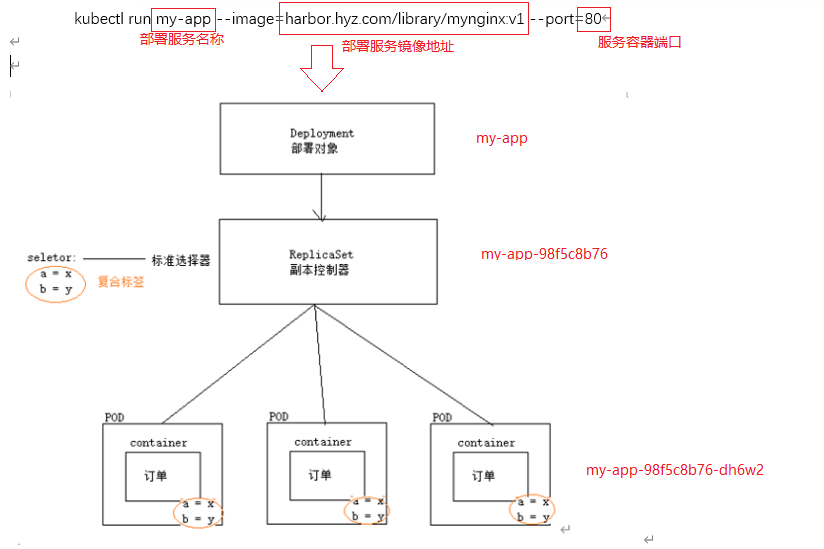
执行后告诉我们这种方式将会被后面的2种方式替换掉,通过kubectl get pod -o wide查看到该服务已经启动成功。
访问方式:curl PODIP:PORT

2.4、服务扩缩容
这里的扩容指的是服务实例个数的扩缩容,而不是内存!
服务扩缩容指令:kubectl scale deployment my-app --replicas=2
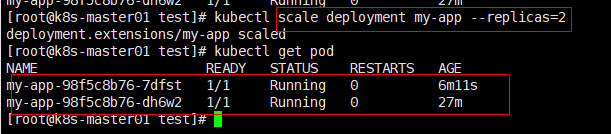
对扩容后的服务进行访问测试:

服务调度问题:扩容后,pod被调度到哪些节点进行部署呢?会是在同一个节点上吗?

可以发现pod服务会被调度到不同的节点继续部署,这个调度工作是由scheduler来实现的,Kubectl实现最终部署。
2.5、服务自愈功能
Pod宕机了,副本控制器就会立马对Pod服务进行重建,保证Pod服务副本数量永远等于预期所设定的数量,从而保证了服务的高可用性。所以有了k8s这个特性,服务就能一直处于高可用状态。
试验1:删除pod,查询pod数量与预期设定的数量是否一致?(replicas=3)
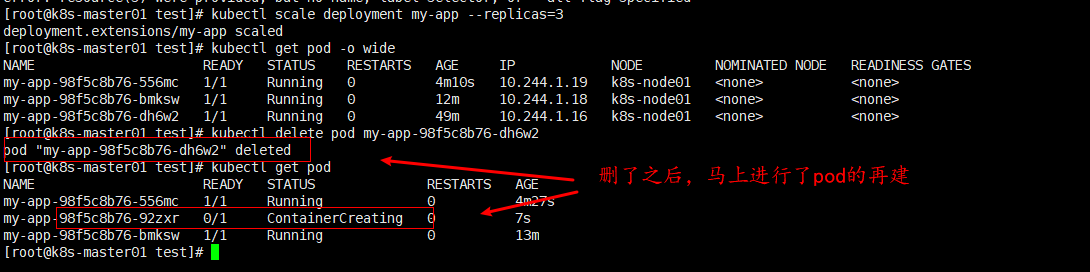
试验2:删除所有的pod,查询pod副本数量是否与预期设定的数量一致?
答案:删除所有的pod副本之后,依旧会创建符合副本数量的Pod.
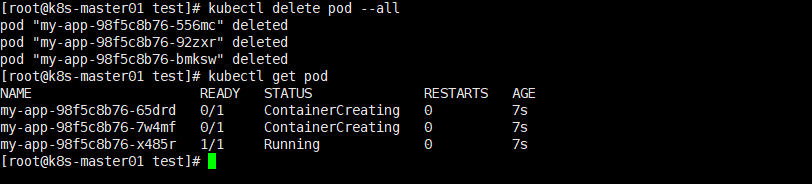
问题:如果确实想要删除pod,如何实现呢?
答案:1、通过kubectl scale deployment my-app --replicas=2 修改副本的数量
** 2、删除deployment或者replicaset对象**
2.6、服务更新/升级
产品发布了新的版本:v1->v2版本,服务部署就需要进行更新。
服务更新/升级指令:kubectl set image deployment my-app=harbor.hyz.com/library/mynginx:v2

可以看出,当服务更新后,该服务对应的所有pod副本都会进行更新,每个pod的IP都进行了重新分配。
2.7、服务回滚
回滚指令:kubectl rollout undo deployment my-app
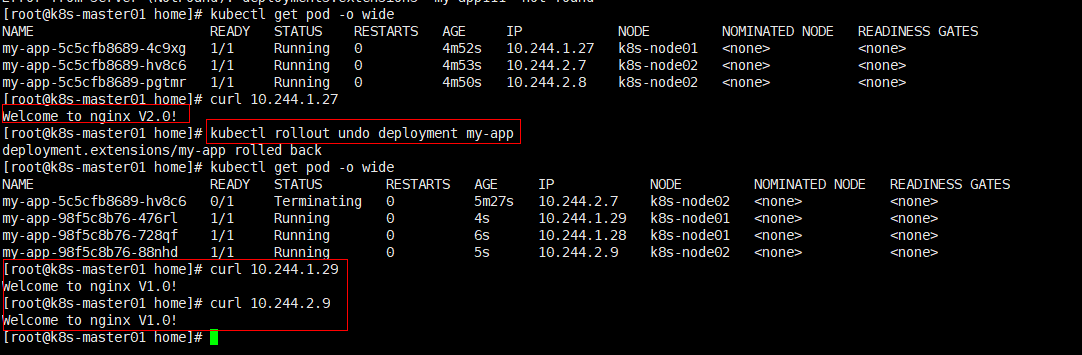
查看历史版本:kubectl rollout hisotry deployment my-app
指定特定历史版本进行回滚:kubectl rollout history deployment my-app --to-revision=3
2.8、自动扩缩容
如果集群支持HPA,就可以为deployment/stateful资源对象设置自动扩缩容的操作。
指令:kubectl autoscale deployment my-app --min=5 --max=8 --cpu-percent=50 #监控pod服务cpu资源率超过50%,进行扩容
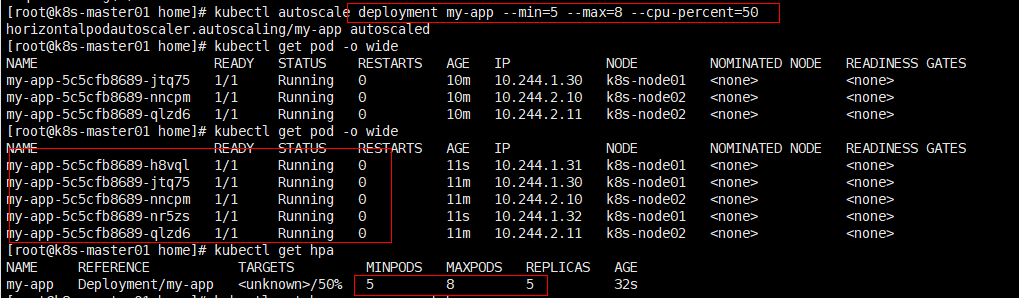
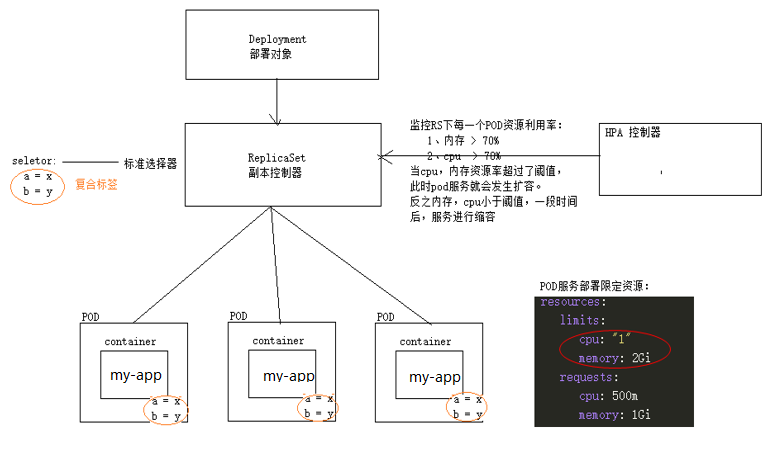
对HPA资源对象不了解的童鞋可以参考:https://kubernetes.io/zh-cn/docs/tasks/run-application/horizontal-pod-autoscale/
2.9、负载均衡
在k8s服务部署中,一个服务会部署多个Pod副本(服务实例集群),在访问pod服务的时候如何实现负载均衡呢?
以上4个服务组合的集群,当用户访问的时候,我们的服务内部到底会访问哪个pod服务呢?这里就涉及到一个负载均衡的访问方式,好比微服务中的ribbon组件中就可以设置负载均衡方式。
问题:如何实现负载均衡?
答案:kuberneteds引入了一个新的对象,虚拟Service VIP服务,k8s利用service服务来实现pod访问的负载均衡。
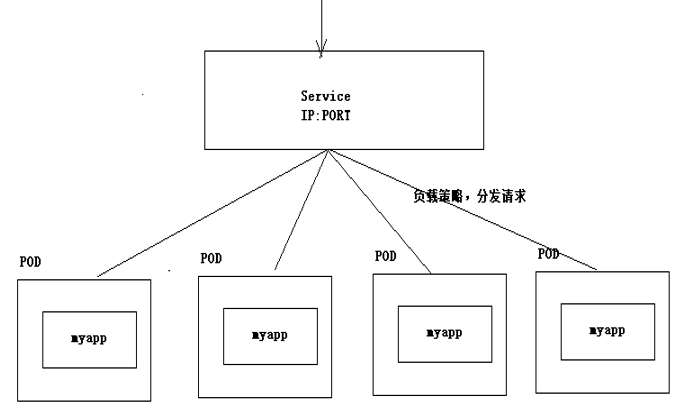
建立Service资源对象,统一对用户提供服务(Service其实这几个pod服务统一入口)
创建Service对象指令: kubectl expose deployment my-app –target-port=80 –port=80
查看service将会负载哪些endpoint: kubectl describe service my-app
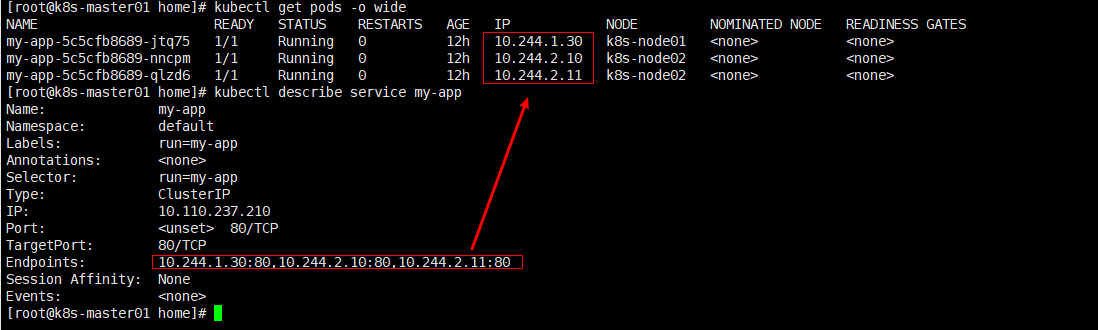
2.10、DNS服务发现
kubernetes在服务部署过程中,通过域名解析出服务的service IP地址,再通过SERVICE的负载均衡到具体的Pod服务(微服务架构服务发现:通过nacos注册中心发现服务的ip地址)。
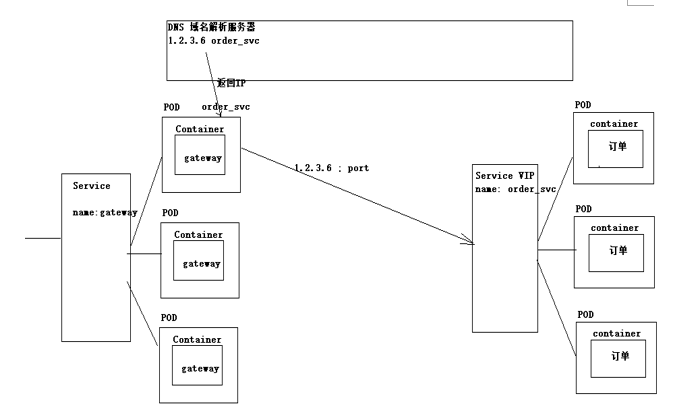
验证: 验证DNS域名解析服务器是否能解析出 service IP地址?
查看DNF服务:kubectl get pod -n kube-system

解析方案: 登录一个pod内部容器中,通过service 名称解析出ip地址,查询是否能够解析?

这里可能会出现ping不同的情况,有这个情况的童鞋可以参考这篇文章:
https://blog.csdn.net/xjjj064/article/details/123526381
2.11、外网访问
根据service统一入口访问pod服务的情况,service服务是否可以在外网直接访问呢?

直接通过Service VIP 无法对外提供服务。因为Service资源对象仅仅是一个虚拟的服务,有自己的IP地址,有自己端口,但是他仅仅是操作系统内部一个虚拟的服务。没有与之对应的物理实体。

计算机之间的通信,是需要建立在网卡基础上的,所有的信息都通过网卡传播出去。那对于kubernetes的服务来说,如何实现对外网的通信呢?
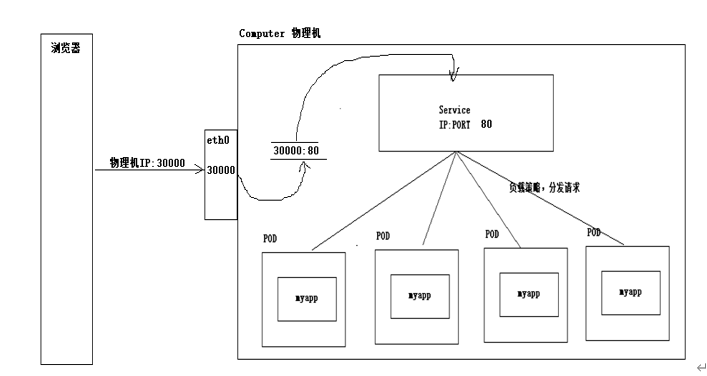
因此如果需要实现外网访问,必须打通内外的端口映射关系(Service端口和物理机端口),此时外网访问物理机端口,然后把数据通过端口映射转发给内部service,从而实现外部通信。
需要开通端口映射,本身kubernetes提供几种ip的类型,其中nodeport类型自动开辟映射关系。
Serviceip类型:
1、cluseterIp : 局域网ip类型,只能在局域网进行访问,无法对外提供服务。这是默认ip类型
2、NodePort : 会在每一个节点上开辟一个端口,且这些端口大小都相同。
3、Loadbanlancer : 第三方服务商提供对外访问入口,收费。
修改Service配置文件,修改IP类型:(创建服务对象,实际上在内部生成配置文件)
或者在创建service的时候就指定IP类型:
kubectl expose deployment my-app --target-port=80 --port=80 --type=NodePort

外网访问: http://物理机IP:31846

到这里kubernetes的主要常用功能demo就都演示差不多了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号