count查询优化
这里讨论的count查询优化是针对INNODB存储引擎的!
首先抛出一个问题
count(*)、count(主键)、count(1)、count(字段)它们四者之间的效率如何排序?
在我们以往的工作经验中,总是听到说不要使用count(*),因为 * 号代表了所有列,计算会更慢,然后就推荐了使用count(主键)。但事实真的是这样吗?
笔者在最近的学习中也才认识到这个错误。
这四者正确的排序应该是这样的:
count(1) > count(*) > count(主键) > count(字段)
笔者特意在一张只有主键索引的1千万条数据的表中做了测试,以下是测试的结果:
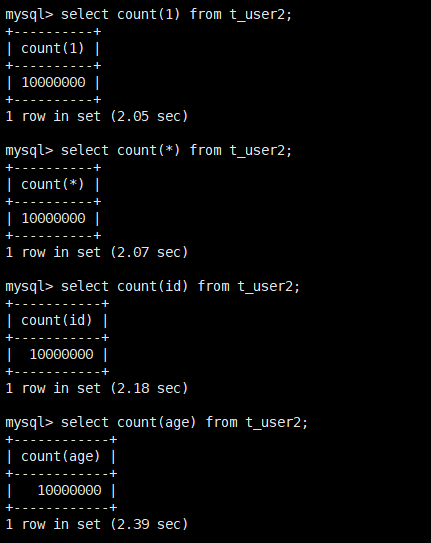
这张图的数据不是偶然的,笔者针对每种查询执行了多次,结果不会有太大的变化,验证了以上排序的正确性。
count()的作用
count()是一个特殊的函数,有两种非常不同的作用:它可以统计某个列值的数量,也可以统计行数。在统计列值时要求列值
是非空的(不统计NULL)。如果在count()的括号中指定了列或者列的表达式,则统计的就是这个表达式有值的结果数,而不是NULL。
count()的另一个作用是统计结果集的行数。当MYSQL确认括号内的表达式值不可能为空时,实际上就是在统计行数。最简单的就
是当我们使用count(*)的时候,这种情况下通配符 * 并不会像我们猜想的那样扩展成所有的列,实际上,它会忽略所有的列而直接统计
所有的行数。
最常见的一个错误就是,在括号内指定了一个列却希望统计结果集的行数。如果希望知道的是结果集的行数,最好使用COUNT(*),
这样写意义清晰,性能也会很好。
count()的另一个优化
业务代码中,有这样一个需求,需要根据一个或多个条件,查询是否存在记录,不关心有多少条记录。普遍的SQL及代码写法如下:
SELECT count(*) FROM T WHERE a = 1 AND b = 2
java写法如下
Integer exist = xxDao.existXxxxByXxx(params);
if ( exist != NULL ) {
//当存在时,执行这里的代码
} else {
//当不存在时,执行这里的代码
}
对于此处的select count(*),并不需求将符合条件的条数都统计出来,可以优化成如下的SQL:
SELECT count(*) FROM T WHERE a = 1 AND b = 2 LIMIT 1
这里相比上面的SQL多了LIMIT关键字,在MYSQL中,执行器执行到LIMIT关键字,只要满足LIMIT的条数,存储引擎就不会再对数据文件
进行检索,直接返回,所以这里只需要检索到1条之后就返回结果,效率可想而知快了不少!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号