
OOBeiHang Unit3 Report
前言
JML是美好的东西,已经写好的JML更是最美好的东西。
目录
一、架构设计
二、性能优化
-
选择合适的数据结构(容器)
-
选择合适的算法
-
一些其他优化方法
三、bug分析 与 测试分析
-
bug分析
-
测试分析
四、拓展规格
-
类的拓展
-
核心业务规格
五、反思总结
-
完备的设计可以为实现节省大量时间
-
拓展中的变与不变
六、结语
一、架构设计
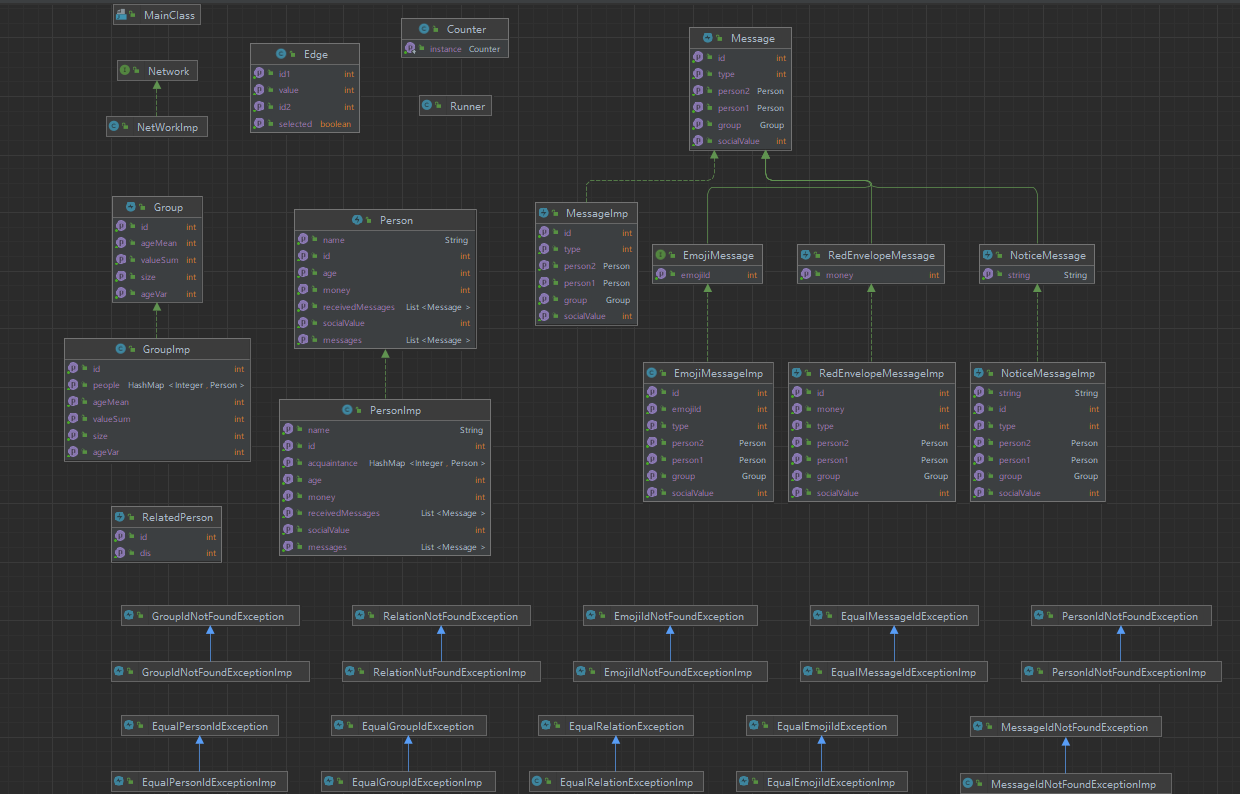
架构依照JML规格而来,新建的类主要是 Counter 和 Edge ,Counter采用单例模式,用以计数各个异常的个数。Edge用以存储人之间的关系,在算法中作为边使用。
二、性能优化
1. 选择合适的数据结构(容器)
(1)HashMap:适用于无顺序且有唯一识别量的数据。
(2)ArrayList:适用于有顺序且操作多为尾部操作的数据。
(3)LinkedList:适用于有顺序且操作多为头部操作的数据。
2. 选择合适的算法
(1)可达查询:DFS算法 与 并查集算法
在方法isCircled()中,要判断两个点是否可达。此处常见的有两种方法:DFS深度优先遍历以及并查集算法:
DFS:深度优先遍历,每次查询利用层层递归查询,偏向于过程。在查询较少改变较多时性能更适用。
并查集:可以分为find、merge两部分,偏向于过程,每次更新时(例如增加关系)会相应跟新森林数据结构。在查询数量极多时更为适用。此外,并查集算法可以进一步优化,有路径压缩、按秩合并等优化方法。
(2)最小生成树:Prim算法 与 Kruskal算法
Prim:从点的方面考虑,每次寻找已选择点到未选择点间的权值最小的边。在稠密图中更为适用。复杂度为 O(n^2),利用堆优化后复杂度可降为 O(n log n) 或 O(n log n)。
Kruskal:从边的方面考虑,每次寻找未选择且不会成圈的权值最小的边。在稀疏图中更为适用。复杂度为 O(e^2),利用堆优化与并查集优化后可降为 O(e log e)。
(3)最短路径:Dijkstra算法
Dijkstra:计算最短路径的经典算法,时间复杂度为 O(n^2)。常见的优化有堆优化、线段树优化,可将复杂度降为 O(m log n) 。
3. 一些其他优化方法
(1)维护对象状态变量解决多次查询问题
查询次数多,复杂度高,且表征的是类的性质或状态的量,可以通过设一个对象成员变量,在过程中不断维护以解决多次查询的问题。比如 queryGroupPeopleSum()方法,其实查询的是Group的状态,可以通过设立状态变量sumEdge来记录。
更普遍的讲,初始化其实决定于对象本身的实际情况,而不是决定于我们所需要的方法,而查询实际上是在对象状态变量与我们需要的返回值之间建立起一个映射。
(2)通过缓存机制解决重复查询问题
这里参照了计算机组成中缓存的思想,这里脏位flag,在更改后置为1,值更新后置为0,每次查询时检查flag,若为0可直接返回,为1则更新。这样可以解决重复多次查询同一个的问题,不过确实有一些面向评测的成分在里面。
三、bug分析 与 测试分析
1. bug分析:
本单元共出现了两个bug(准确的说是CTLE)。
(1)第一次强测没有测到bug,在互测中发起 hack: 1/28 受到 hack: 3/15
bug出现在Network类中的queryBlockSum()方法,原本采用的是二重循环调用isCircle方法来计算独立分支的数目。改进后采用的是增加了专门记录独立分支的数目的量size,每次在更新时维护该量。
攻击点是主要关注isCircle方法的复杂度。
(2)第二次强测出现了一个bug,在互测中发起 hack: 14/42 受到 hack: 0/20
强测的bug在于Network类中的queryLestConnect()方法没有先进行排序,导致复杂度涨到了O(n^2)。主要是由于对算法记忆不足。
攻击点主要是两点,即关于Group增加Person数量1111的限制以及Prim算法在稀疏图下的性能下降。
(3)第三次强测没有测到bug,在互测中发起 hack: 0/6 受到 hack: 0/11
此次可能由于回家热潮以及活动较多,互测房间里比较平静。
2. 测试分析:
在构造测试数据时,随机数据与边界数据都需要,边界数据用于测试一些可能忽略考虑的地方,主要包括范围边界、顺序搭配(即不同指令的搭配与顺序)、性能测试等,但是由于边界数据是通过自己构造产生的,往往难以测试到自己的深层次bug所在,所以需要随机数据的补充。通过足够数量的随机数据,基本可以保证程序的正确性。
在本单元,几乎每一次作业我都测试了十万行以上的随机数据,所以一直没有出现正确性上的bug。不过却忽略了性能问题,专门针对性能的数据往往与其他不同,测试时也需要关注。
四、拓展规格:
1. 类的拓展:
几种不同的Person都继承于PersonImp类,其中:
Advertiser类增加sendAdvertise()方法,用以发布广告,内有adProducts。
Producer类增加makeAdvertise()方法,用以推销产品,
Custormer类增加readAdvertise()方法,用以阅读广告, 以及sendBuyMessage()方法,用以购买产品。
Message增加实现类BuyMessage和AdvertiseMessage。
新增Product类用以刻画产品,具有id、saleNum、money、heat、producters等信息, products用以存储product信息。
2. 核心业务规格:
发布广告:参数product为所宣传产品,money为宣传费用,产品product热度增加money,Advertiser钱数增加money,但socialValue减少money。
/*@ public normal_behavior
@ requires containsMessage(id)
@ && getMessage(id).getType() == 1
@ && getMessage(id).getGroup()
@ .hasPerson(getMessage(id).getPerson1())
@ && getMessage(id).getPerson1() instanceof Advertiser
@ && ProductList.contain(product);
@ assaignable product;
@ assaignable people[*]
@ ensures !containsMessage(id) && messages.length == \old(messages.length) - 1 &&
@ (\forall int i; 0 <= i && i < \old(messages.length) && \old(messages[i].getId()) != id;
@ (\exists int j; 0 <= j && j < messages.length; messages[j].equals(\old(messages[i]))));
@ ensures (\forall Person p; \old(getMessage(id)).getGroup().hasPerson(p); p.getSocialValue() ==
@ \old(p.getSocialValue()) + \old(getMessage(id)).getSocialValue());
@ ensures (\forall int i; 0 <= i && i < people.length && !\old(getMessage(id)).getGroup().hasPerson(people[i]);
@ \old(people[i].getSocialValue()) == people[i].getSocialValue());
@ ensures product.heat = \old(product.heat) + money
@ ensures money = \old(money) + money
@ ensures socialValue = \old(socialValue) - money
@ also
@ public exceptional_behavior
@ signals (MessageIdNotFoundException e) !containsMessage(id);
@ signals (PersonIdNotFoundException e) containsMessage(id) && getMessage(id).getType() == 1 &&
@ !(getMessage(id).getGroup().hasPerson(getMessage(id).getPerson1()));
@*/
public void sendAdvertise(Product product, int money, int id) throws MessageIdNotFoundException;
查询销售额:
/*@ public normal_behavior
@ requires (\exists int i; 0 <= i && i < products.length; products[i].getId() == productId)
@ ensures \result==getProduct(productId).getSaleNum();
@ also
@ public exceptional_behavior
@ signals (ProductIdNotFoundException)
@ !(\exists int i; 0 <= i && i < products.length; products[i].getId() == productId)
@*/
public int querySaleNum(int productId);
查询销售路径:销售路径即选择Advertiser 发送购物消息
/*@ public normal_behavior
@ requires (\exists int i; 0 <= i && i < products.length; products[i].getId() == productId)
@ requires (\exists int i; 0 <= i && i < advertisers.length; (\exists int i; 0 <= i && i < advertisers.adProducts.length; adProducts[i].getId() == productId))
@ ensures (\exists int i; 0 <= i && i < advertisers.length; \result == advertisers && (\exists int i; 0 <= i && i < advertisers.adProducts.length; adProducts[i].getId() == productId))
@ also
@ public exceptional_behavior
@ signals (ProductIdNotFoundException)
@ !(\exists int i; 0 <= i && i < products.length; products[i].getId() == productId)
@ siganl (NoAdvertiserException)
@ !(\exists int i; 0 <= i && i < advertisers.length; (\exists int i; 0 <= i && i < advertisers.adProducts.length; adProducts[i].getId() == productId))
@*/
public Advertiser queryBuyPath(int productId);
五、反思总结:
1. 完备的设计可以为实现节省大量时间
本单元花在OO完成程序的时间被之前几乎减少了百分之七十,从而可以进行了大量的测试,也有明显的成果——bug减少了许多。时间减少的主要时间主要是由于不需要花时间去整体架构,只需要完成实现与一小部分的设计,以及算法的学习。 这种设计方式的坏处是在设计阶段会消耗过多的时间去写规格。好处在于可以完全将工作分开为两部分,利于合作。
2. 拓展要分析变与不变
在本单元中好处在于通过对比JML可以看出哪些方法需要改变,哪些不需改变。在第一单元因为拓展中改动过多,导致破坏了原有机制引发bug,所以提出拓展要尽量不改变原有部分;在第二单元中,我又由于坚持不改动原有机制,导致新加机制不足产生bug,所以提出应当仔细分析变与不变的地方;在本单元我的疑惑得到了进一步的解决,在寻找变与不变的地方时,可以以类为单元,以方法为单元,在完成新部分的设计架构之后,通过修改原有方法或新增方法来完成新增部分。
可是在平常若没有JML,则需要谨慎的分析方法是否需要变化。事实上,在第三次作业的测试时,我也发现了忘记修改sendMessage里RedEnvelopmessage的Group类型的部分出现的bug。事实说明,即便是有JML,有时对比的都不甚仔细,如果没有JML,怕是需要强迫自己花费精力与时间去研究。
所以方法与实施方法的能力同样重要,都需要总结提升。
3. 对算法的学习不能仅局限于实现
从本单元的作业中尤其可以看出,对于算法的学习,绝不仅仅是知道如何实现这么简单。具体来说,应当包括且不限于 算法目的、实现方法、复杂度分析、适用情况、同类算法、优化方法 等各个部分。全部掌握后,在选择算法时,才会做出更好的选择与优化。此外,要明白算法的逻辑,这样才能应对不同的要求不同的数据形式以及不同的情况要求,进行合适的修改与优化。当然,算法没有准确的好坏之分,一个自己熟悉的算法,固然慢,但是在优化与实现的过程中却能保证较好的正确性;性能与准确也需要折衷的选择。
六、结语
“不要用战术上的勤奋,掩盖战略上的懒惰。”

 浙公网安备 33010602011771号
浙公网安备 33010602011771号