CPU Cache模型与JMM
一、CPU Cache模型
1.1 产生原因
在计算机中,所有的运算操作都是由CPU的寄存器完成的,CPU指令的执行过程需要涉及数据的读取和写入操作,CPU访问的所有数据都来自主存。随着技术进步,CPU的处理速度与内存的访问速度之间的差距越来越大,此时CPU直连内存的访问方式会限制CPU,降低CPU整体的吞吐量,于是就产生了缓存的设计。
1.2 模型结构

CPU Cache的读写速度远高于内存的速度,缓解了CPU直接访问内存效率低下的问题,极大提高了CPU吞吐能力。在程序运行过程中,会将运算所需要的数据从主存复制一份到CPU Cache中,CPU进行计算时直接对Cache中的数据进行读写,当运算结束后,再将Cache中的最新数据刷新到主内存中。

1.3 CPU缓存一致性问题
在执行num++操作时,会有以下具体过程:
(1) 读取主内存的num到CPU Cache中
(2) 对num进行加一操作
(3) 将结果写回到CPU Cache中
(4) 将数据刷新到主内存中
多线程向下,每个线程都有自己的工作内存(本地内存,对应于CPU中的Cache),则变量num会在多个线程下都存在一个副本。假设现有两个线程在执行num++,都从主存中取得num=0存入CPU Cache中,线程一计算后num=1写入主存,线程二计算后也写入主存,则经过两次自增后结果仍为1,这就是缓存不一致问题。

1.4 解决缓存不一致问题
1.4.1 总线加锁方式

CPU和其他组件通信是通过各种总线进行的,采用总线加锁,每次只有一个CPU访问这个变量的内存,从并行退化为串行执行。即每次只有一个线程获取到num(read主存),并进行自增操作,写回主存后(write主存),完成这一过程后,下一个线程才能获取num执行操作。这种方式效率低下。
1.4.2 缓存一致性协议
其大致思想是,当CPU在操作Cache中的数据时,如果发现该变量是一个共享变量,也就是在其他CPU Cache中也存在一个副本,那么执行以下操作:
(1) 读取操作,不做任何处理,只是将Cache中的数据读取到寄存器
(2) 写入操作,发出信号通知其他CPU将该变量的Cache line置为无效状态,写入成功后,此时其他CPU通过总线嗅探机制得知写入成功,就再次从主存中获取该共享变量。
缓存一致性协议内容很复杂,以上只是大致过程。
二、Java内存模型
2.1 主内存与工作内存
JVM虚拟机规范中定义了Java内存模型来屏蔽掉各种硬件和操作系统的内存访问差异,以实现让Java程序在各种平台下都能达到一致的内存访问效果。Java内存模型M指定了Java虚拟机如何与计算机的主存进行工作。Java内存模型决定了一个线程对共享变量的写入何时对其他线程可见,Java内存模型定义了线程和主存之间的抽象关系,具体如下:
(1) 共享变量存储于主存之中,每个线程都可以访问
(2) 每个线程都有私有的工作内存或者称为本地内存
(3) 工作内存只存储该线程对共享变量的副本
(4) 线程不能直接操作主内存,只有先操作了工作内存之后才能写入主内存
(5) 工作内存和Java内存模型一样也是一个抽象概念,其实并不存在,它涵盖了缓存、寄存器、编译器优化以及硬件等
![clip_image006_thumb[1]](https://img2020.cnblogs.com/blog/1550970/202005/1550970-20200515232056695-1866489849.png "clip_image006_thumb[1]")
注:JMM是一个抽象到的概念,主存、工作内存与堆栈、方法区等是两个概念,没什么关系,若要建立联系,对应起来,堆区主要对应主存,栈主要对应工作内存。
2.2 内存间的交互
主内存和工作内存之间的交互协议,即一个变量如何从主内存拷贝到工作内存、如何从工作内存同步回主内存之类的实现细节,java内存模型中定义了以下8种操作来完成,JVM实现时必须保证下面的每种操作都是原子的、不可再分的。
- lock:锁定,作用于主内存变量,它把一个变量标识为一条线程独占的状态。
- unlock:解锁,作用于主内存变量,它把一个处于锁定状态的变脸释放出来,释放后的变量才可以被其他线程锁定。
- read:读取,作用于主内存变量,它把一个变量的值从主内存传输到线程的工作内存中,以便随后的load操作执行。
- load:载入,作用于工作内存的变量,它把read操作从主内存得到的变量值放入工作内存的变量副本中。
- use:使用,作用于工作内存的变量,它把工作内存中一个变量的值传递给执行引擎,每当JVM遇到一个需要使用到变量的值的字节码指令时将会执行这个操作。
- assign:赋值,作用于工作内存的变量,它把一个从执行引擎接收到的值赋给工作内存的变量,每当虚拟机遇到一个给变量赋值的字节码指令时执行这个操作。
- store:存储,作用于工作内存的变量,它把工作内存中一个变量的值传送到主内存中,以便随后的write操作使用。
- write:写入,作用于主内存的变量,它把store操作从工作内存中得到的变量的值放入主内存的变量中。
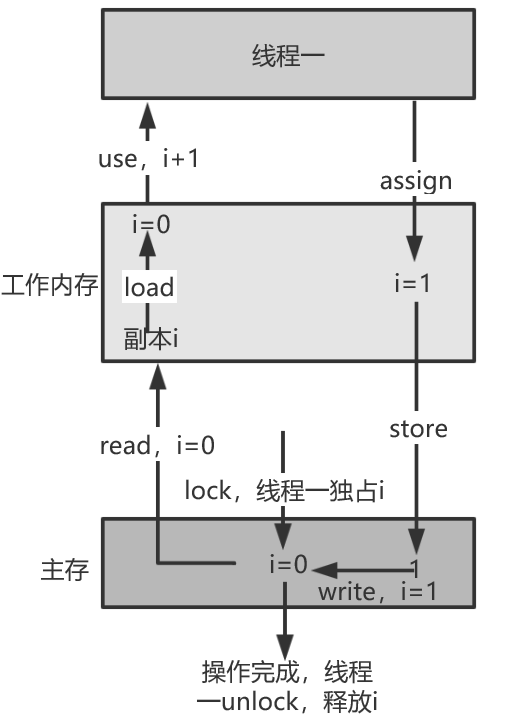
如上图就是多线程环境下,通过总线加锁方式实现多线程安全。多个线程竞争i,某线程一得到i所在内存,并进行加锁,其他线程阻塞,线程一完成一系列操作后释放锁,其他线程继续竞争i。
上述六种操作(通过lock和unlock能保证对内存多线程下的安全性,一般不看)每种单独都是原子性操作,但组合在一起就不是原子操作。
如果要把一个变量从主内存复制到工作内存,那就要顺序地执行read和load操作,如果要把变量从工作内存同步回主内存,就要顺序地执行store和write操作。但java内存模型只要求上述两个操作必须按顺序执行,而没有保证是连续执行。java内存模型还规定了在执行上述八种操作时必须遵循如下规则:
1)不允许read和load、store和write操作之一单独出现,即不允许一个变量从主内存读取了但工作内存不接受,或者从工作内存发起了回写但主内存不接受的情况出现。
2)不允许一个线程丢弃它的最近的assign操作,即变量在工作内存中改变了之后必须把该变化同步回主内存。
3)不允许一个线程无原因地(没有发生过任何assign操作)把数据从线程的工作内存同步回主内存中。
4)一个新的变量只能在主内存中“诞生”,不允许在工作内存中直接使用一个未被初始化(load或assign)的变量,换句话说,就是对一个变量实施use、store操作之前,必须先执行过了assign和load操作。
5)一个变量在同一时刻只允许一条线程对其执行lock操作,但lock操作可以被同一条线程重复执行多次,多次执行lock之后,只有执行相同次数的unlock操作,变量才会被解锁。
6)如果对一个变量执行lock操作,那将会清空工作内存中该变量的值,在执行引擎使用这个变量前,需要重新执行load或assign操作初始化变量的值。
7)如果一个变量事先没有被lock操作锁定,那就不允许对它执行unlock操作,也不允许去unlock一个被其他线程锁定住的变量。
8)对一个变量执行unlock操作之前,必须先把此变量同步回主存中。
注:在内存交互过程中,存在针对于volatile的特殊的访问规则,volatile变量在各个线程的工作内存中不存在一致性问题。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号