

CNN学习中一些有用的函数记录
文件处理函数
1.os.listdir()函数
该函数可以用于获取所有二级目录,并返回一个列表
例如: 
配合for函数还能直接获取二级目录的路径
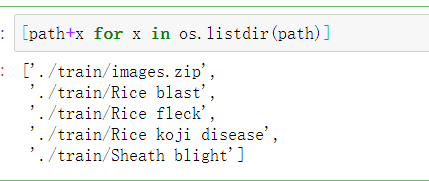
应用场景:
修改子文件夹下的文件名(批量重命名)
import os
# 数据集的地址 改为你自己的
path = './images'
#获取所有二级目录,存入列表中
cList=os.listdir(path)
# 遍历所有二级目录,修改其图片名称
for catalog in cList:
#输出当前文件夹名
print(">>>>>>>>>>>>>>>>>>>>>>>>>"+catalog)
#拼凑获得子文件夹路径
s_path = path+'/'+catalog
#获取子文件夹下的文件名 返回的是一个列表
imgs = os.listdir(s_path)
print(imgs)
#计数器
n = 0
for i in imgs:
#设置旧文件名(就是路径+文件名)
oldname = s_path + '/' + imgs[n]
#设置新文件名---拼凑
newname= s_path + '/' +catalog+str(n+1)+'.jpg'
os.rename(oldname,newname) #用os模块中的rename方法对文件改名
n+=1
# print(newname)
2.glob.glob()函数
该函数属于一个文件搜索函数。利用glob.glob函数可以搜索每个层级文件下面符合特定格式(例如“/*.jpg”)进行遍历
返回值为list
应用:可以对文件进行模糊遍历操作
import glob
import cv2
# 测试图像的地址 (改为自己的)
path_test = './test/'
test_list=[]
# 创建保存图像的空列表
imgs=[] # glob.glob(path_test+'/*.jpg')
for im in glob.glob(path_test+'/*.jpg'): # 利用glob.glob函数搜索每个层级文件下面符合特定格式“/*.jpg”进行遍历
print(im)
img=cv2.imread(im)
img=cv2.resize(img,(w,h))
imgs.append(img) # 将每张经过处理的图像数据保存在之前创建的imgs空列表当中
imgs = np.asarray(imgs,np.float32)
print("shape of data:",imgs.shape)
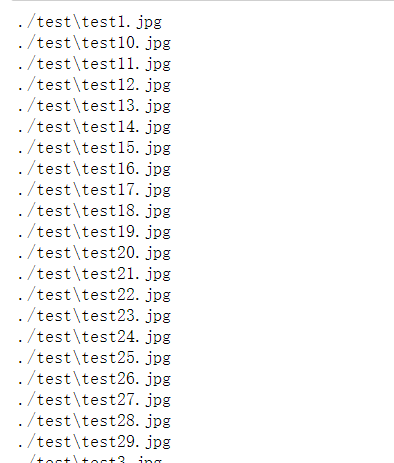
由上图可以看出,该函数是按照字典顺序进行遍历的,而不是按自然数大小顺序遍历的,所以在使用过程中需要注意。
数据增强函数
由于在进行模型训练的时候,会存在数据集达不到一定的数量集,就会对CNN模型训练的准确率产生影响,所以就需要进行数据增强。
下面是我参考过的一个好用并且易上手的数据增强的函数
ImageDataGenerator是keras提供的一种方法。
详细参数介绍可以看 https://keras.io/preprocessing/image/
import os
from keras.preprocessing.image import ImageDataGenerator, array_to_img, img_to_array, load_img
Datagen = ImageDataGenerator(rotation_range=40,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
vertical_flip = True,
fill_mode='nearest')
#还有其他一些参数,具体请看:https://keras.io/preprocessing/image/ ,如去均值,标准化,ZCA白化,旋转,
#偏移,翻转,缩放等
def max_img(path,name):
img = load_img(path+name)#获取一个PIL图像
x_img = img_to_array(img)
x_img = x_img.reshape((1,)+ x_img.shape)
i = 0
for img_batch in Datagen.flow(x_img,
batch_size=1,
save_to_dir='./images/纹枯病生成/',#'./images/pre_Data/'
save_prefix=name,
save_format='jpg'):
i +=1
if i > 20:
break
path = './images/纹枯病/'
list_name = [x for x in os.listdir(path)]
list_img = [path+x for x in os.listdir(path)]
#扫描文件夹的内容
# [x for x in os.listdir(path)]
# list_img[0]
# max_img()
# list_name[0]
for i in list_name:
print(i)
max_img(path,i)

经验总结
当有不懂的时候,还是得学着去看下TensorFlow的官方示例和官方文档。相比网上的博客,官方的示例讲解的更为详细。
或者去https://www.kaggle.com/下载相关的模型进行学习,都是很好的办法。
后续
以后在学习过程中,碰见有用的函数,都会记录在此。
